
记一次 CGroup 小实验
前言
之前遇到一个需求:解决 cephfs 的 csi-node 插件,在 csi-node 重启以后,ceph-fuse 进程也随之终止,导致已挂在的目录挂载点丢失。
最终通过 cgexec 命令,在执行 ceph-fuse 命令时,修改了 ceph-use 进程的 cgroup,避免了 pod 重启之后随着 pod 之前的 cgroup 被删除而终止。
近期,遇到了类似的问题,又重新回顾并模拟了主要操作,并在本文中做了记录。
实验原因
kubelet 有一个参数:cgroups-per-qos(布尔类型),启用后会为每个 pod 以及 pod 对应的 Qos 创建 cgroups 层级树,默认启用。
启用后,pod 退出时,会清理 cgroup 下所有进程,详情参考:https://github.com/kubernetes/kubernetes/blob/release-1.22/pkg/kubelet/cm/pod_container_manager_linux.go#L144
// Scan through the whole cgroup directory and kill all processes either // attached to the pod cgroup or to a container cgroup under the pod cgroup func (m *podContainerManagerImpl) tryKillingCgroupProcesses(podCgroup CgroupName) error { pidsToKill := m.cgroupManager.Pids(podCgroup) // No pids charged to the terminated pod cgroup return if len(pidsToKill) == 0 { return nil } var errlist []error // os.Kill often errors out, // We try killing all the pids multiple times removed := map[int]bool{} for i := 0; i < 5; i++ { if i != 0 { klog.V(3).InfoS("Attempt failed to kill all unwanted process from cgroup, retrying", "attempt", i, "cgroupName", podCgroup) } errlist = []error{} for _, pid := range pidsToKill { if _, ok := removed[pid]; ok { continue } klog.V(3).InfoS("Attempting to kill process from cgroup", "pid", pid, "cgroupName", podCgroup) if err := m.killOnePid(pid); err != nil { klog.V(3).InfoS("Failed to kill process from cgroup", "pid", pid, "cgroupName", podCgroup, "err", err) errlist = append(errlist, err) } else { removed[pid] = true } } if len(errlist) == 0 { klog.V(3).InfoS("Successfully killed all unwanted processes from cgroup", "cgroupName", podCgroup) return nil } } return utilerrors.NewAggregate(errlist) }
由此,我们也受到启发,如果能把进程从 pod 自身的 cgroup 移出,是不是就可以实现 ceph-fuse 进程不会再 pod 终止时随之被清理。
主要操作
首先,在一个 linux 测试机上,启动一个单节点的 kubernetes 测试集群。
向集群提交如下 pod 准备测试:
apiVersion: v1
kind: Pod
metadata:
name: my-centos
labels:
app: centos
spec:
hostPID: true
hostNetwork: true
containers:
- name: my-centos
image: centos:7
imagePullPolicy: IfNotPresent
command: ["top","-b"]
volumeMounts:
- mountPath: /sys
name: host-sys
securityContext:
privileged: true
volumes:
- hostPath:
path: /sys
type: ""
name: host-sys
注意上述 pod 共享了 /sys 目录,启用了特权容器,和宿主机共享了 PID。
执行:kubectl exec -it my-centos bash,进入容器内部,并执行:cd ~,回到用户目录。
执行如下命令,创建一个脚本:
cat << EOF > test-cgroup.sh #!/bin/bash sleep 1234s EOF chmod +x test-cgroup.sh
执行:./test-cgroup.sh &,启动这个脚本,然后再新开一个连接宿主机的窗口,通过执行:ps aux | grep test-cgroup | grep -v test-cgroup,查看 PID:

然后执行:pstree -ps ${PID},查看进程的依赖关系。
接下来,我们删除之前创建的 Pod,再查看进程是否存在:

很明显,子进程随着 Pod 被删除而被清理。
接下来,我们试一下 cgexec 工具,重新提交一下上述的 my-centos 的 pod,并进入容器。
默认 centos 镜像没有 cgexec 命令,我们执行:yum install -y wget gcc-c++ byacc flex pam-devel gcc automake autoconf libtool make,先安装依赖。
安装一下默认的 libcgroup:yum install libcgroup libcgroup-tools -y。

回到用户目录,再次创建脚本:
cd ~ cat << EOF > test-cgroup.sh #!/bin/bash sleep 1234s EOF chmod +x test-cgroup.sh
执行:cgexec -g *:/ ./test-cgroup.sh &(cgexec 的作用在于在指定子系统的 cgroup 执行命令,* 表示所有子系统),然后再另一个窗口查看进程 PID,以及该进程所在各个 cgroup(cat /proc/${PID}/cgroup):

我们发现,默认的 cgexec 命令,没有办法修改 name=systemd 子系统的 cgroup,其余的子系统的 cgroup 都改为了 root cgroup。
然后我们尝试删除 my-centos 的 pod,由于无法更改 name=systemd 的子系统的 cgroup,果不其然,子进程随 pod 删除而被回收:

我们看下 libcgroup 源码的一段说明:https://github.com/libcgroup/libcgroup/blob/v0.41/README_systemd
Compilation =========== As stated in [2], libcgroup should not interact with the 'name=systemd' hierarchy. Compile libcgroup with the --enable-opaque-hierarchy configure option to do so: ./configure --enable-opaque-hierarchy=name=systemd Consequently, the 'name=systemd' hierarchy will not be visible to libcgroup and all of its tools. For example, the lscgroup command will not list systemd cgroups and the cgclear command will not remove them. Start-up and services ====================
大意是,libcgroup 的工具默认不会操作 name=systemd 的层级,默认情况也是如此。
既然是开源的代码,我们就可以自己编译一个 cgexec 命令。
再次,启动测试的 pod,进入容器内部,回到用户目录。
执行:yum install -y wget gcc-c++ byacc flex pam-devel gcc automake autoconf libtool make,安装依赖。
执行:wget https://github.com/libcgroup/libcgroup/releases/download/v0.41/libcgroup-0.41.tar.gz,下载源码(使用 0.41 版是对应上文,默认依赖的 libcgroup 版本)。
执行:tar -zxvf libcgroup-0.41.tar.gz && cd libcgroup-0.41,解压并进入代码目录。
执行:./configure --enable-opaque-hierarchy=none && make && make install,编译并安装 cgexec,这次,我们没有采用默认方式,将参数设为 --enable-opaque-hierarchy=none。
再次创建脚本:
cd ~ cat << EOF > test-cgroup.sh #!/bin/bash sleep 1234s EOF chmod +x test-cgroup.sh
执行:cgexec -g *:/ ./test-cgroup.sh &,然后再另一个窗口查看进程 PID,以及该进程所在各个 cgroup(cat /proc/${PID}/cgroup):
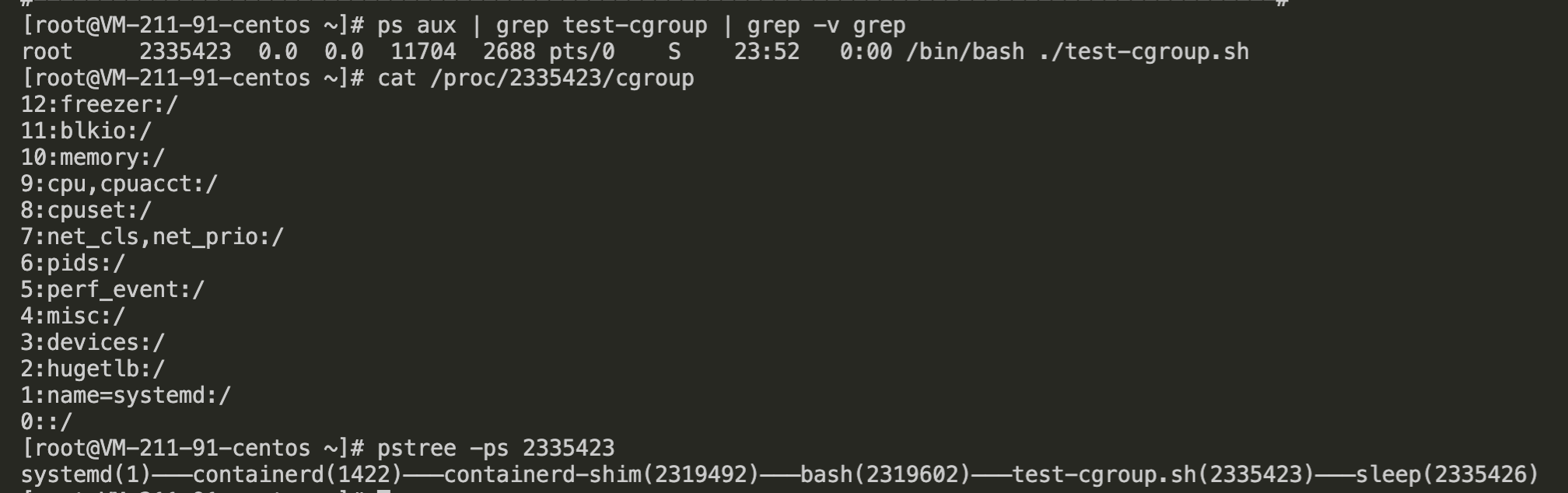
此时,我们发现,所有子系统的 cgroup 都被修改为了 root cgroup。
我们再次删除测试 pod,再观察子进程:

成功了,子进程成功“越狱”!符合了预期。
不过这种方式并不是一个安全的方式,需要根据需求使用。
简单汇总一下,我们在容器内安装 cgexec 的命令:
cd ~ yum install -y wget gcc-c++ byacc flex pam-devel gcc automake autoconf libtool make wget https://github.com/libcgroup/libcgroup/releases/download/v0.41/libcgroup-0.41.tar.gz tar -zxvf libcgroup-0.41.tar.gz cd libcgroup-0.41 ./configure --enable-opaque-hierarchy=name=systemd make make install
我的博客即将同步至腾讯云开发者社区,邀请大家一同入驻:https://cloud.tencent.com/developer/support-plan?invite_code=241jlzbblj7oc

 浙公网安备 33010602011771号
浙公网安备 33010602011771号