实验三:朴素贝叶斯算法实验
| 博客班级 | 班级链接 |
|---|---|
| 作业要求 | 作业链接 |
| 学号 | 181613146 |
【实验目的】
理解朴素贝叶斯算法原理,掌握朴素贝叶斯算法框架。
【实验内容】
- 针对下表中的数据,编写python程序实现朴素贝叶斯算法(不使用sklearn包),对输入数据进行预测;
- 熟悉sklearn库中的朴素贝叶斯算法,使用sklearn包编写朴素贝叶斯算法程序,对输入数据进行预测;
【实验报告要求】
- 对照实验内容,撰写实验过程、算法及测试结果;
- 代码规范化:命名规则、注释;
- 查阅文献,讨论朴素贝叶斯算法的应用场景。
| 色泽 | 根蒂 | 敲声 | 纹理 | 脐部 | 触感 | 好瓜 |
|---|---|---|---|---|---|---|
| 青绿 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 碍滑 | 是 |
| 乌黑 | 蜷缩 | 沉闷 | 清晰 | 凹陷 | 碍滑 | 是 |
| 乌黑 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 碍滑 | 是 |
| 青绿 | 蜷缩 | 沉闷 | 清晰 | 凹陷 | 碍滑 | 是 |
| 浅白 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 碍滑 | 是 |
| 青绿 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 软粘 | 是 |
| 乌黑 | 稍蜷 | 浊响 | 稍糊 | 稍凹 | 软粘 | 是 |
| 乌黑 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 硬滑 | 是 |
| 乌黑 | 稍蜷 | 沉闷 | 稍糊 | 稍凹 | 硬滑 | 否 |
| 青绿 | 硬挺 | 清脆 | 清晰 | 平坦 | 软粘 | 否 |
| 浅白 | 硬挺 | 清脆 | 模糊 | 平坦 | 硬滑 | 否 |
| 浅白 | 蜷缩 | 浊响 | 模糊 | 平坦 | 软粘 | 否 |
| 青绿 | 稍蜷 | 浊响 | 稍糊 | 凹陷 | 硬滑 | 否 |
| 浅白 | 稍蜷 | 沉闷 | 稍糊 | 凹陷 | 硬滑 | 否 |
| 乌黑 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 软粘 | 否 |
| 浅白 | 蜷缩 | 浊响 | 模糊 | 平坦 | 硬滑 | 否 |
| 青绿 | 蜷缩 | 沉闷 | 稍糊 | 稍凹 | 硬滑 | 否 |
【实验过程与步骤】
1. 编写python程序实现朴素贝叶斯算法(不使用sklearn包),对输入数据进行预测
(1)输入数据
# 输入数据
import pandas as pd
data_list = [['青绿', '蜷缩', '浊响', '清晰', '凹陷', '碍滑', '是'],
['乌黑', '蜷缩', '沉闷', '清晰', '凹陷', '碍滑', '是'],
['乌黑', '蜷缩', '浊响', '清晰', '凹陷', '碍滑', '是'],
['青绿', '蜷缩', '沉闷', '清晰', '凹陷', '碍滑', '是'],
['浅白', '蜷缩', '浊响', '清晰', '凹陷', '碍滑', '是'],
['青绿', '稍蜷', '浊响', '清晰', '稍凹', '软粘', '是'],
['乌黑', '稍蜷', '浊响', '稍糊', '稍凹', '软粘', '是'],
['乌黑', '稍蜷', '浊响', '清晰', '稍凹', '硬滑', '是'],
['乌黑', '稍蜷', '沉闷', '稍糊', '稍凹', '硬滑', '否'],
['青绿', '硬挺', '清脆', '清晰', '平坦', '软粘', '否'],
['浅白', '硬挺', '清脆', '模糊', '平坦', '硬滑', '否'],
['浅白', '蜷缩', '浊响', '模糊', '平坦', '软粘', '否'],
['青绿', '稍蜷', '浊响', '稍糊', '凹陷', '硬滑', '否'],
['浅白', '稍蜷', '沉闷', '稍糊', '凹陷', '硬滑', '否'],
['乌黑', '稍蜷', '浊响', '清晰', '稍凹', '软粘', '否'],
['浅白', '蜷缩', '浊响', '模糊', '平坦', '硬滑', '否'],
['青绿', '蜷缩', '沉闷', '稍糊', '稍凹', '硬滑', '否']
]
# 数据集标签特征
labels = ['色泽', '根蒂', '敲声', '纹理', '脐部', '触感', '好瓜']
# 将数据集转换为DataFrame数据
data = pd.DataFrame(data_list, columns=labels)
data

(2)编写函数
"""
求先验概率函数,计算样本数据集分类标签为是/否的概率
data为样本数据和分类结果;categorical_character是分类字符,是/否
"""
def prior_probability(data, categorical_character):
cnt = 0.0
for index, row in data.iterrows():
if row[-1] == categorical_character:
cnt += 1
return cnt/len(data)
"""
计算每种属性的取值
data为样本数据和分类结果;categorical_character是分类字符,是/否;
"""
def statistics(data, categorical_character):
cnt = 0.0
for index, row in data.iterrows():
if row[-1] == categorical_character:
cnt += 1
return (cnt+1)/(len(data)+len(set(data['好瓜'])))
"""
计算条件概率
data为样本数据和分类结果;categorical_character是分类字符,是/否;
attribute_no是属性的序号;attribute_value是属性的取值;
"""
def conditional_probability(data, categorical_character, attribute_no, attribute_value,):
cnt1 = 0.0
cnt2 = 0.0
for index, row in data.iterrows():
if row[-1] == categorical_character:
cnt1 += 1
if row[attribute_no] == attribute_value:
cnt2 += 1
return cnt2/cnt1
"""
拉普拉斯修正
data为样本数据和分类结果;categorical_character是分类字符,是/否;
attribute_no是属性的序号;attribute_value是属性的取值;
characteristics是属性的特征数目
"""
def lapalace(data, categorical_character, attribute_no, attribute_value, characteristics):
cnt1 = 0.0
cnt2 = 0.0
for index, row in data.iterrows():
if row[-1] == categorical_character:
cnt1 += 1
if row[attribute_no] == attribute_value:
cnt2 += 1
return (cnt2+1)/(cnt1+characteristics)
"""
利用后验概率计算先验概率
data为样本数据和分类结果;testlist是新样本数据列表;
categorical_character_y / categorical_character_n是分类字符,是/否;
characteristics是属性的特征数
"""
def posteriori(data, testlist, categorical_character_y, categorical_character_n):
py = prior_probability(data, categorical_character_y)
pn = prior_probability(data, categorical_character_n)
for i, val in enumerate(testlist):
py *= conditional_probability(data, categorical_character_y, i, val)
pn *= conditional_probability(data, categorical_character_n, i, val)
if (py == 0) or (pn == 0):
py = statistics(data, categorical_character_y)
pn = statistics(data, categorical_character_n)
for i, val in enumerate(testlist):
characteristics = len(set(data[data.columns[i]]))
py *= lapalace(data, categorical_character_y,
i, val, characteristics)
pn *= lapalace(data, categorical_character_n,
i, val, characteristics)
if py > pn:
result = categorical_character_y
else:
result = categorical_character_n
return {categorical_character_y: py, categorical_character_n: pn, '好瓜': result}
(3)测试
#测试
tsvec = ['乌黑','蜷缩','沉闷','稍糊','稍凹','硬滑']
prob = posteriori(data,tsvec,'是','否')
print("测试结果:",prob)

2. 使用sklearn包编写朴素贝叶斯算法程序,对输入数据进行预测
(1)数据预处理
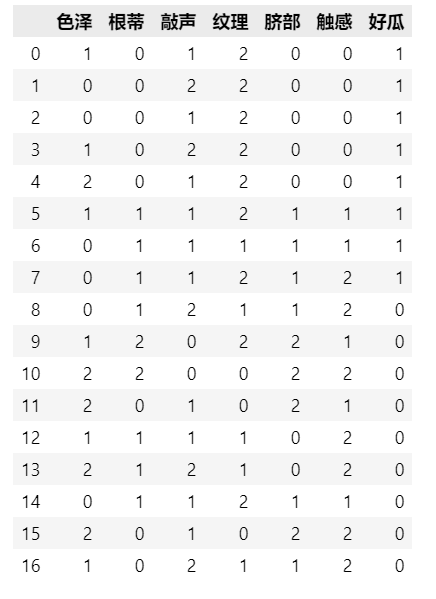
datal = data.replace(
["乌黑", "青绿", "浅白",
"蜷缩", "稍蜷", "硬挺",
"清脆", "浊响", "沉闷",
"模糊", "稍糊", "清晰",
"凹陷", "稍凹", "平坦",
"碍滑", "软粘", "硬滑",
"否", "是"],
[0, 1, 2,
0, 1, 2,
0, 1, 2,
0, 1, 2,
0, 1, 2,
0, 1, 2,
0, 1
])
datal
(2)使用sklearn包对输入数据预测
from sklearn.model_selection import train_test_split #将原始数据划分为数据集与测试集两个部分
from sklearn.naive_bayes import BernoulliNB
x = datal.iloc[:,:-1]
y = datal.iloc[:,-1]
#x_train训练样本, x_test测试样本, y_train训练样本分类, y_test测试样本分类
#x样本数据分类集, y分类结果集, test_size=3测试样本数量
x_train,x_test,y_train,y_test= train_test_split(x,y,test_size=3,random_state=None)
clf = BernoulliNB()
clf.fit(x,y)
clf.score(x_test,y_test)
clf.predict(x_test)
# 测试
t = ['1','0','1','0','0','1']
t= pd.DataFrame(t)
test =t.T
test
clf.predict(test) # 测试结果

3.朴素贝叶斯算法的应用场景
文本分类
分类是数据分析和机器学习领域的一个基本问题。文本分类已广泛应用于网络信息过滤、信息检索和信息推荐等多个方面。数据驱动分类器学习一直是近年来的热点,方法很多,比如神经网络、决策树、支持向量机、朴素贝叶斯等。相对于其他精心设计的更复杂的分类算法,朴素贝叶斯分类算法是学习效率和分类效果较好的分类器之一。直观的文本分类算法,也是最简单的贝叶斯分类器,具有很好的可解释性,朴素贝叶斯算法特点是假设所有特征的出现相互独立互不影响,每一特征同等重要。但事实上这个假设在现实世界中并不成立:首先,相邻的两个词之间的必然联系,不能独立;其次,对一篇文章来说,其中的某一些代表词就确定它的主题,不需要通读整篇文章、查看所有词。所以需要采用合适的方法进行特征选择,这样朴素贝叶斯分类器才能达到更高的分类效率。
其他
朴素贝叶斯算法在文字识别, 图像识别方向有着较为重要的作用。 可以将未知的一种文字或图像,根据其已有的分类规则来进行分类,最终达到分类的目的。
现实生活中朴素贝叶斯算法应用广泛,如文本分类,垃圾邮件的分类,信用评估,钓鱼网站检测等等。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号