软工实践:第二次作业
1、Fork仓库的Githup地址:https://github.com/371091997/PersonProject-Java
2、PSP表格记录估计将在程序的各个模块的开发上耗费的时间
|
PSP2.1 |
Personal Software Process Stages |
预估耗时(分钟) |
实际耗时(分钟) |
|
Planning |
计划 |
45 |
10 |
|
• Estimate |
• 估计这个任务需要多少时间 |
30 |
15 |
|
Development |
开发 |
300 |
100 |
|
• Analysis |
• 需求分析 (包括学习新技术) |
480 |
400 |
|
• Design Spec |
• 生成设计文档 |
30 |
20 |
|
• Design Review |
• 设计复审 |
10 |
3 |
|
• Coding Standard |
• 代码规范 (为目前的开发制定合适的规范) |
10 |
5 |
|
• Design |
• 具体设计 |
20 |
30 |
|
• Coding |
• 具体编码 |
540 |
600 |
|
• Code Review |
• 代码复审 |
60 |
10 |
|
• Test |
• 测试(自我测试,修改代码,提交修改) |
120 |
20 |
|
Reporting |
报告 |
120 |
30 |
|
• Test Repor |
• 测试报告 |
60 |
15 |
|
• Size Measurement |
• 计算工作量 |
30 |
5 |
|
• Postmortem & Process Improvement Plan |
• 事后总结, 并提出过程改进计划 |
30 |
10 |
|
|
合计 |
1885 |
1273 |
3.解题思路:拿到题目之后,大概直到题目对我们的几个要求,首先是先要实现几个功能,一个功能是读取文件,然后再实现计算字符数,计算行数,计算单词数,计算前十个出现频率的单词,再实现这些之后再将代码封装;
首先,我看java书的时候看到过读取文件内容的知识,我翻书并且按照书中的内容打出了读取文件的代码,然后要实现几个功能,这些功能再曾经学C++的时候是使用一些自己写的算法来实现的,但是我知道Java提供了很多的接口和类方法,因此通过网络和书籍,找到几个常用类并且加上自己写的一些算法实现了这些方法;
读取文件内容不再赘述,就是通过File和FileInputStream类实现的;然后是计算字符数,这个同样的很简单,只要通过FileReader和BufferedReader按行读取文件之中的内容,然后判断所读取出的字符串中的字符的ASCII码就能计算字符数了;
计算行数的话,同样的使用FileReader和BufferedReader按行读取,自然可以计算行数;
计算单词数,就是使用正则式,然后通过正则式分割字符串,然后判断是否是需要的单词就可以了;
最后一个要计算单词出现次数并且按照频率和字典序进行排序,这个我感觉有点儿困难,一开始我是想使用三个数组来实现,其中两个字符串数组,一个计算出现频率的数组,通过对频率的计算,然后将整型数组按照其值从大到小进行排序,并且同时,整型数组对应的字符串数组同样的进行排序,然后将相同频率的字符串数组中的元素加入到另一个字符串中,将另一个字符串按照字典序进行排序,再将排序完的字符串数组返回原本的字符串,这个工作一样就 会很大,因此虽然有思路,但是我不想这么做,通过查询课本和网络,使用了HashMap和List类来代替了上述的数组的功能,减少了操作,通过HashMap统计其中的单词机器频率,然后转换为List类,调用sort方法,重写compare方法,实现按照value从大到小的排序,然后就通过字符串数组将相同频率的字符串给进行字典排序,输出到最终的字符串和整型数组之中最后就是实现封装了,这个没什么好说的,就是将实现几个功能的函数方法放到不同的class之中,然后使用统一的接口,需要的时候调用接口,然后重写接口方法,就实现了封装。
4.计算模块接口的设计与实现过程
①代码的设计过程
实现功能:统计文件中的字符数;
统计文件中的行数;
统计文件中的单词数;
统计文件中的出现频率最高的10个单词数并且将相同频率的单词按照单词的字典序排序;
封装要求:统计字符数
统计单词数
统计最多的10个单词及其词频
这三个功能独立出来,成为一个独立的模块(class library, DLL, 或其它),称之为计算核心"Core模块",这个模块至少可以在几个地方使用:命令行测试程序使用;在单元测试框架下使用;与数据可视化部分结合使用,并且设计API接口,然后使用Core封装接口
代码组织:
| 实现功能 | 实现方式 | 函数名/类名 |
| 统计字符 | 类实现 | charactersnumber |
| 统计行数 | 函数实现 | lines |
| 统计单词 | 类实现 | wordsnumber |
| 统计10个单词及其频率 | 类实现 | flequentwords |
算法关键:
| 实现功能 | 算法关键 |
| 统计字符 | 通过从统计文件中所读出来的每一行字符串中符合ASCII码表中的字符,加到count之中,从而统计字符数 |
| 统计行数 | 通过BufferedReader接口来按行读取文件之中的文本,从而统计文件文本之中的行数 |
| 统计单词 | 通过设置正则表达式来分隔字符串之中的单词,并且设置判定条件判断是否是符合条件的单词,从而统计单词数 |
| 统计10个单词及其频率 | 先统计单词,通过HashMap来计算各个单词出现次数,然后将HashMap转换为List,再通过Entry的getvalue方法得到value值遍历前十个单词,若是value值相同的放在一起用Arrays.sort()方法字典排序通过getkey得到的键值,从而得到了按照字典排序的频率最高的十个单词 |
②单元测试
测试方法:我是用eclipse自带的junit4进行测试,使用了四组比较复杂的数据,测试均成功,测试数据如下,这是其中一组数据,四组数据均此规模

Junit4的测试结果:
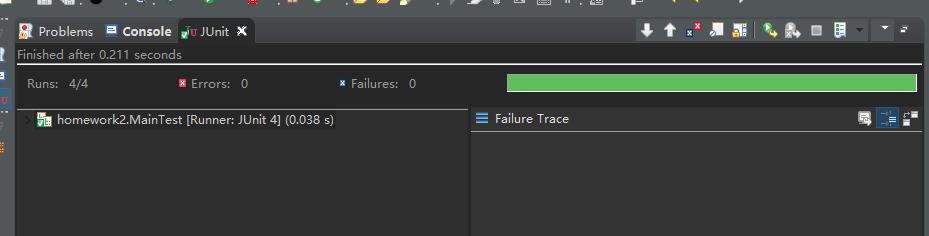
上面数据的运行结果:

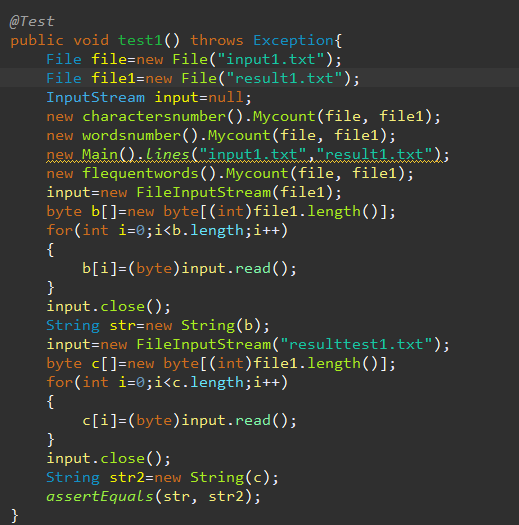
junit4测试代码(其一,共四组)
代码覆盖率测试(我是用java自带的Eclemma,我感觉覆盖率还阔以):


5.计算模块接口部分的功能改进:
计算模块wordsnumber思路及其改进:
思路一:将文件中的字符转换为字符串,然后判断其是否前四个是字母,若是则单词计数加一,若是遇到非数字并且非字母的字符,则跳过;若是遇到连续四个字母,则继续判断直到遇到非字母和数字的字符,开始重新判断字母
思路二(改进):由于一个个的判断字符太过麻烦,通过正则式将字符串分隔开来,然后判断每一个的字符串数组之中的元素是否前四个字符是字母,若是,则单词计数器加一
计算模块flequentwords思路及其改进:
思路一:通过判断是否是单词,然后将单词加入字符串数组,并且在加入之前判断该单词是否在字符串数组之中,若是,则同该单词在字符串数组中的位置i,在整数数组中的位置i上加一,直到判断完,然后将整型数组排序,在排序的过程中同时的对字符串数组进行相同的排序操作,于是就得到了按照出现频率排序的字符串数组,然后通过判断相同的出现频率的字符串数组并且将其放到另一个字符串数组中按照字典顺序进行排序,然后将排序好的数组返回整体的字符串数组之中,就得到了按照字典序和出现频率排序的字符串数组,就能够输出得到需要的答案
思路二:由于需要对两个数组进行操作,然后再对一个字符串数组进行操作,因此操作复杂,这时候引入了HashMap,在判断完是单词之后将其放入HashMap之中,若是已经存在于HashMap,则将其value值加一,若是不在则将key和value值加入HashMap之中,然后再HashMap转为List将其按照value值进行排序,然后就输出到数组之中,将其出现频率相同的字符串按照字典序进行排序,就得到了所需要的答案
6.代码说明
1 //接口代码 2 public interface Core { 3 void Mycount(File file1,File file2); 4 }
//统计单词频率并且排序 class flequentwords implements Core { //重写排序方法 private static class ValueComparator implements Comparator<Map.Entry<String,Integer>> { public int compare(Map.Entry<String,Integer> m,Map.Entry<String,Integer> n) { return n.getValue()-m.getValue(); } } private File file1; private File file2; public void Mycount(File file3,File file4) { file1=file3; file2=file4; try { Map<String,Integer> map=new HashMap<>(); //读取文件内容 InputStream input=null; input=new FileInputStream(file1); byte b[]=new byte[(int)file1.length()]; for(int i=0;i<b.length;i++) { b[i]=(byte)input.read(); } input.close(); String str=new String(b); //分割读取的字符串 String regex="[\\s\\p{Punct}]+"; String words[]=str.split(regex); //判断分割的字符串是否是单词 for(int i=0;i<words.length;i++) { if(words[i].length()<4) continue; boolean judge=true; for(int j=0;j<=3;j++) { if(words[i].charAt(j)<'A'||words[i].charAt(j)>'z') judge=false; } //如果是单词,就判断是否已经再HashMap之中 if(judge) { if(map.containsKey(words[i]))//如果再HashMap之中,则将其频率,也就是value加1 { map.put(words[i], map.get(words[i])+1); } else//若是不再HashMap之中,则加入到其中,并且value为1 { map.put(words[i], 1); } } } //将HashMap转换为List List<Map.Entry<String,Integer>> list=new ArrayList<>(); list.addAll(map.entrySet()); //将list按照value值进行排序 ValueComparator vc=new ValueComparator(); Collections.sort(list,vc); Entry<String, Integer> te=list.get(0); int count=te.getValue(); String[] change=new String[list.size()]; int[] intchange=new int[list.size()]; //将排序之后的list放入数组,一个是字符串数组,一个是整型数组 for(int i=0;i<list.size();i++) { te=list.get(i); change[i]=te.getKey().toLowerCase(); intchange[i]=te.getValue(); } //将频率相同的字符串进行字典排序 for(int i=1,jet=0;i<list.size()&&i<10;i++) { te=list.get(i); if(count!=te.getValue()||i==9||i==list.size()-1) { if(i==9||i==list.size()-1) i++; String[] change2=new String[i-jet]; for(int j=jet,k=0;j<i;j++,k++) { change2[k]=change[j]; } Arrays.sort(change2); for(int j=jet,k=0;j<i;j++,k++) { change[j]=change2[k]; } jet=i; } count=te.getValue(); } FileWriter out=new FileWriter(file2,true); for(int i=0;i<list.size()&&i<10;i++) { String result="<"+change[i]+">: "+String.valueOf(intchange[i])+"\r\n"; if(i==list.size()-1||i==9) result="<"+change[i]+">: "+String.valueOf(intchange[i]); out.write(result); } out.close(); }catch(IOException e) { System.out.println(e); } } }
//单词数统计 public class wordsnumber implements Core { private int count=0; private File file1; private File file2; public void Mycount(File file3,File file4) { file1=file3; file2=file4; try { //读取文件内容 InputStream input=null; input=new FileInputStream(file1); byte b[]=new byte[(int)file1.length()]; for(int i=0;i<b.length;i++) { b[i]=(byte)input.read(); } input.close(); //使用正则式对读取的字符串进行分割 String regex="[\\s\\p{Punct}]+"; String str=new String(b); String words[]=str.split(regex); //判断是否是符合标准的单词,若是则加1 for(int i=0;i<words.length;i++) { if(words[i].length()<4) continue; boolean judge=true; for(int j=0;j<=3;j++) { if(words[i].charAt(j)<'A'||words[i].charAt(j)>'z') judge=false; } if(judge) { count++; } } String wordstring="words: "+String.valueOf(count)+"\r\n"; FileWriter out=new FileWriter(file2,true); out.write(wordstring); out.close(); }catch(IOException e) { System.out.println(e); } } }
//字符数统计 public class charactersnumber implements Core{ private int count=0; private File file1; private File file2; public void Mycount(File file3,File file4) { file1=file3; file2=file4; try { //读取文件中的内容 FileReader inone=new FileReader(file1); BufferedReader buf=new BufferedReader(inone); String str=null; //按行读取 while((str=buf.readLine())!=null) { count++; for(int i=0;i<str.length();i++) { if((int)str.charAt(i)>=0&&(int)str.charAt(i)<128)//若是ASICC表中的字符,则加1 { count++; } } } count--; buf.close(); String characters="characters: "+String.valueOf(count)+"\r\n"; FileWriter out=new FileWriter(file2,true); out.write(characters); out.close(); } catch(IOException e) { System.out.println(e); } } }
7.心路历程和收获
说真的,我之前都是写的都是算法之类的东西,没接触过封装,接口什么的,也是第一次使用Java打代码,因此耗时颇大,但是我相信会越来越好;我之前不知道项目开发什么样子的,虽然这个算不上什么项目开发,但是也让我多多的了解了之前的一些比如封装什么的不知道的东西,然后我凭借自己的想象,大概想象出了那些项目开发人怎么开发项目的,然后我的迷茫就少了一些,软件工程实践虽然有点累,然是吧我觉得是挺好的,希望自己能够再接再厉;我之前听说软件工程实践不好做,我也做好了心理准备了,因此这个算是再我的意料之中吧,就是写博客是真的累,这个博客园没有CSDN的好用,很多功能没有,难受;我感觉自己对程序语言的学习能力又增强了一步,这个很好,单元测试的话,嗯,我其实试过了,并且按照慕课网上的课程一步一步的做,用的是junit4

 浙公网安备 33010602011771号
浙公网安备 33010602011771号