Hive、Inceptor数据倾斜详解及解决
一、倾斜造成的原因
正常的数据分布理论上都是倾斜的,就是我们所说的20-80原理:80%的财富集中在20%的人手中, 80%的用户只使用20%的功能 , 20%的用户贡献了80%的访问量。
俗话是,一个人累死,其他人闲死的局面
这也违背了并行计算的初衷,首先一个节点要承受着巨大的压力,而其他节点计算完毕后要一直等待这个忙碌的节点,也拖累了整体的计算时间,可以说效率是十分低下的。
下面举个简单的例子:

举个 word count 的入门例子:
它的map 阶段就是形成 (“aaa”,1)的形式,然后在reduce 阶段进行 value 相加,得出 “aaa” 出现的次数。
若进行 word count 的文本有100G,其中 80G 全部是 “aaa” 剩下 20G 是其余单词,那就会形成 80G 的数据量交给一个 reduce 进行相加,其余 20G 根据 key 不同分散到不同 reduce 进行相加的情况。如此就造成了数据倾斜,临床反应就是 reduce 跑到 99%然后一直在原地等着 那80G 的reduce 跑完。
表现如下:
有一个多几个reduce卡住
各种container报错OOM
读写的数据量极大,至少远远超过其它正常的reduce
伴随着数据倾斜,会出现任务被kill等各种诡异的表现。
二、倾斜原理
原理剖析
在进行shuffle的时候,必须将各个节点上相同的Key拉取到某个节点上的一个task来进行处理,比如按照key进行聚合或者join操作。如果某个key对应的数据量特别大的话,会发生数据倾斜。
三、倾斜解决
- 将reduce join 转为map join-----一般用于直接sql查询的场景
什么是MapJoin?
MapJoin顾名思义,就是在Map阶段进行表之间的连接。而不需要进入到Reduce阶段才进行连接。这样就节省了在Shuffle阶段时要进行的大量数据传输。从而起到了优化作业的作用。
MapJoin的原理:
通常情况下,要连接的各个表里面的数据会分布在不同的Map中进行处理。即同一个Key对应的Value可能存在不同的Map中。这样就必须等到Reduce中去连接。
要使MapJoin能够顺利进行,那就必须满足这样的条件:除了一份表的数据分布在不同的Map中外,其他连接的表的数据必须在每个Map中有完整的拷贝。
MapJoin适用的场景:
通过上面分析你会发现,并不是所有的场景都适合用MapJoin. 它通常会用在如下的一些情景:在二个要连接的表中,有一个很大,有一个很小,这个小表可以存放在内存中而不影响性能。
这样我们就把小表文件复制到每一个Map任务的本地,再让Map把文件读到内存中待用。
MapJoin的实现方法:
1)在Map-Reduce的驱动程序中使用静态方法DistributedCache.addCacheFile()增加要拷贝的小表文件,。JobTracker在作业启动之前会获取这个URI列表,并将相应的文件拷贝到各个TaskTracker的本地磁盘上。
2)在Map类的setup方法中使用DistributedCache.getLocalCacheFiles()方法获取文件目录,并使用标准的文件读写API读取相应的文件。
Hive内置提供的优化机制之一就包括MapJoin。
在Hive v0.7之前,需要使用hint提示 /*+ mapjoin(table) */才会执行MapJoin 。Hive v0.7之后的版本已经不需要给出MapJoin的指示就进行优化。它是通过如下配置参数来控制的:
hive> set hive.auto.convert.join=true;
否则需要通过sql代码进行修改
select /*+ mapjoin(A)*/ f.a,f.b from A t join B f on ( f.a=t.a and f.ftime=20110802)
Hive还提供另外一个参数--表文件的大小作为开启和关闭MapJoin的阈值。
hive.mapjoin.smalltable.filesize=25000000 即25M
实现原理:
普通的join是会走shuffle过程的,而一旦shuffle,就相当于会将相同key的数据拉取到一个shuffle read task中再进行join,此时就是reduce join。但是如果一个RDD是比较小的,则可以采用广播小RDD全量数据+map算子来实现与join同样的效果,也就是mao join ,而此时不会发生shuffle操作,也就不会发生数据倾斜。
方案优点:
对join操作导致的数据倾斜,效果非常好,因为根本就不会发生shuffle,也就根本不会发生数据倾斜。
方案缺点:
适用场景较少,因为这个方案只适用于一个大表和一个小表的情况。毕竟我们需要将小表进行广播,此时会比较消耗内存资源,driver和每个Executor内存中都会驻留一份小RDD的全量数据。如果我们广播出去的RDD数据比较大,比如10G以上,那么就可能发生内存溢出了。因此并不适合两个都是大表的情况。
2.提高shuffle操作的并行度
方案使用场景:
若我们必须要面对数据倾斜问题,要这么使用。
思路:
在对RDD执行shuffle算子时,给shuffle算子传入一个参数,如reduceByKey(1000),该参数设置了这个shuffle算子执行时shuffle read task 的数量。对于Spark SQL中的shuffle类语句,如 groupBy 、join 等需要设置一个参数,即spark.sql.shuffle.partitions。该参数代表了shuffle read task 的并行度,默认值是200。
原理:
增加shuffle read task 的数量,可以让原本分配给一个task的多个key分配给多个task,从而让每个task处理比原来更少的数据。举例来说,如果原本有5个key,每个key对应10条数据,这5个key都是分配给一个task的,那么这个task就要处理50条数据。而增加了shuffle read task以后,每个task就分配到一个key,即每个task就处理10条数据,那么自然每个task的执行时间都会变短了。
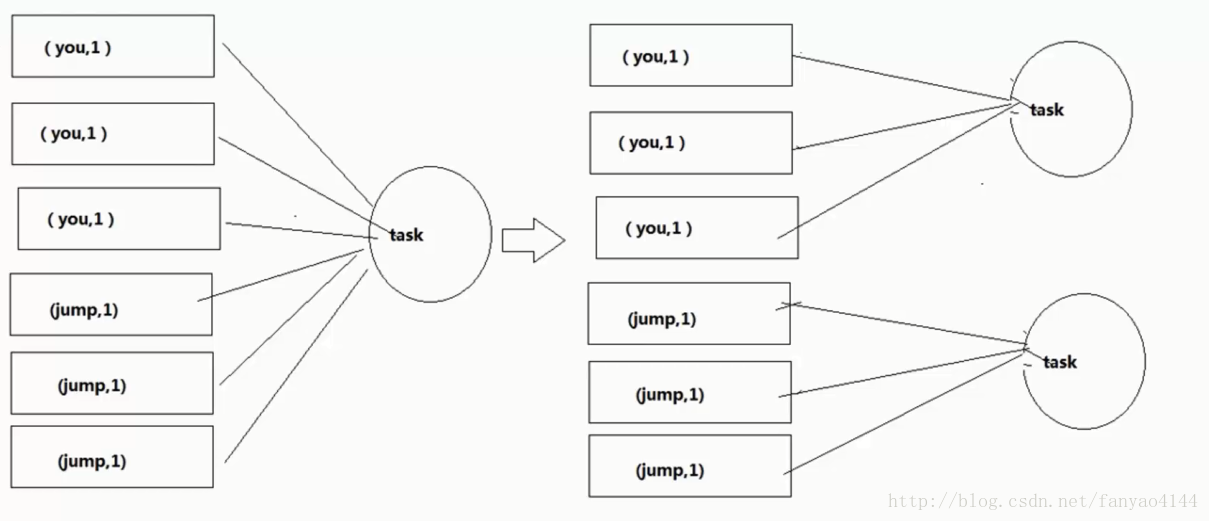
实现起来比较简单,可以有效缓解和减轻数据倾斜的影响。
只是缓解了数据倾斜而已,没有彻底根除问题,根据实践经验来看,其效果有限。
3. 两阶段聚合(局部聚合+全局聚合)
方案使用场景:
对RDD执行reduceByKey等聚合类shuffle算子或者在Spark SQL中使用group by语句进行分组聚合时,比较适用这种方案。
思路:
这个方案的核心实现思路就是进行两阶段聚合。第一次是局部聚合,先给每个key都打上一个随机数,比如10以内的随机数,此时原先一样的key就变成不一样的了,比如(hello, 1) (hello, 1) (hello, 1) (hello, 1),就会变成(1_hello, 1) (1_hello, 1) (2_hello, 1) (2_hello, 1)。接着对打上随机数后的数据,执行reduceByKey等聚合操作,进行局部聚合,那么局部聚合结果,就会变成了(1_hello, 2) (2_hello, 2)。然后将各个key的前缀给去掉,就会变成(hello,2)(hello,2),再次进行全局聚合操作,就可以得到最终结果了,比如(hello, 4)。
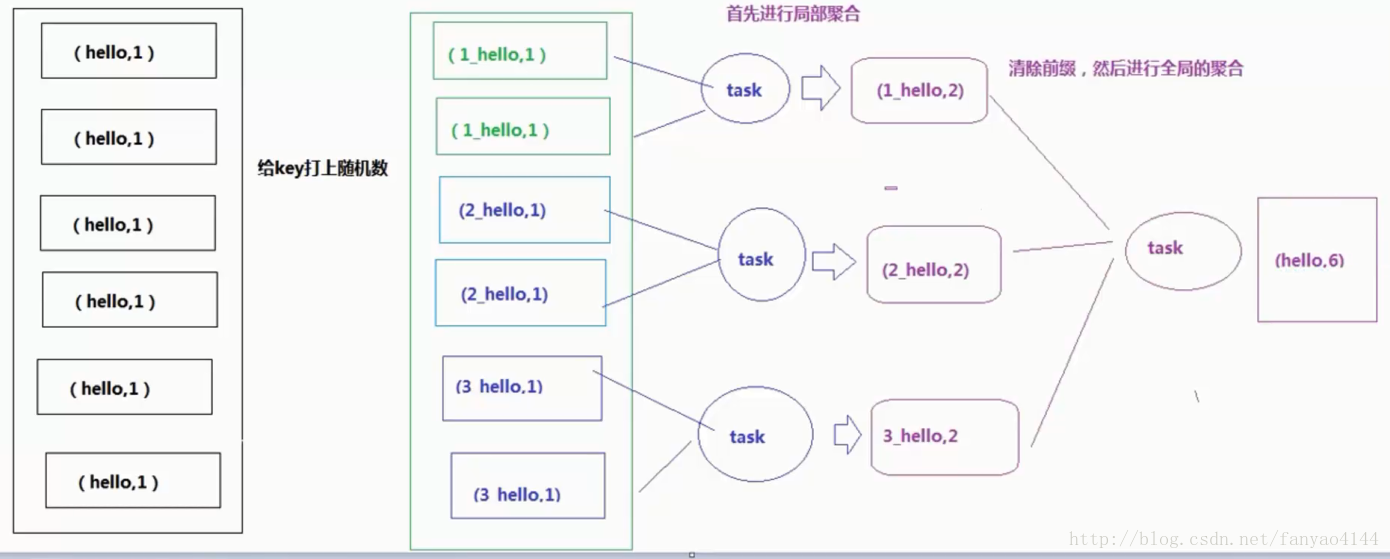
方案优点:
对于聚合类的shuffle操作导致的数据倾斜,效果是非常不错的。通常都可以解决掉数据倾斜,或者至少是大幅度缓解数据倾斜,将Spark作业的性能提升数倍以上。
方案缺点:
仅仅适用于聚合类的shuffle操作,适用范围相对较窄。如果是join类的shuffle操作,还得用其他的解决方案。
作者:少帅
出处:少帅的博客--http://www.cnblogs.com/wang3680
您的支持是对博主最大的鼓励,感谢您的认真阅读。
本文版权归作者所有,欢迎转载,但请保留该声明。
 支付宝
支付宝  微信
微信

 浙公网安备 33010602011771号
浙公网安备 33010602011771号