

20200917-2 词频统计
此作业的要求参见:https://edu.cnblogs.com/campus/nenu/2020Fall/homework/11206
词频统计 SPEC
老五在寝室吹牛他熟读过《鲁滨逊漂流记》,在女生面前吹牛热爱《呼啸山庄》《简爱》和《飘》,在你面前说通读了《战争与和平》。但是,他的四级至今没过。你们几个私下商量,这几本大作的单词量怎么可能低于四级,大家听说你学习《构建之法》,一致推举你写个程序名字叫wf,统计英文作品的单词量并给出每个单词出现的次数,准备用于打脸老五。
希望实现以下效果。以下效果中数字纯属编造。
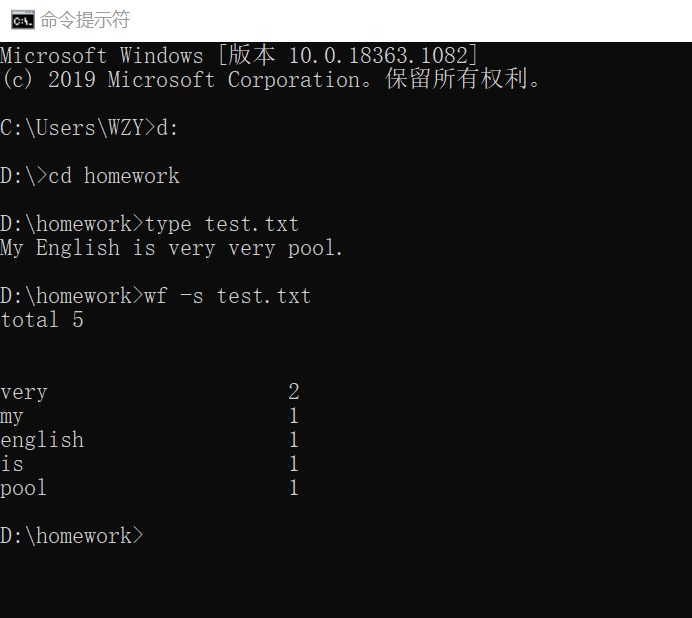
功能1 小文件输入。 为表明程序能跑,结果真实而不是迫害老五,请他亲自键盘在控制台下输入命令。
>type test.txt
My English is very very pool.
>wf -s test.txt
total 5
very 2
my 1
english 1
is 1
pool 1为了评估老五的词汇量而不是阅读量,total一项中相同的单词不重复计数数,出现2次的very计数1次。
因为用过控制台和命令行,你早就知道,上面的">"叫做命令提示符,是操作系统的一部分,而不是你的程序的一部分。
答:
1.重难点:
区分什么是一个单词。
使用open方法打开文件,read方法读取文件。
Python脚本转换为可执行文件
命令行输入功能完成后就要通过命令行参数对程序进行相关的调用
重复单词只记一次,并把重复次数记录下来
2.重要代码片断:
if len(argv) == 2: try: list = file_read(argv[-1]) opts, args = getopt.getopt(argv, "sh", ["ifile", "ofile"]) except getopt.GetoptError: print("test.py -i <inputfile> -o <outputfile>") sys.exit(2) for opt, arg in opts: if opt == "-s": num = len(list) print('total',num) print('\n') for word in list: print('{:20s}{:>5d}'.format(word[0], word[1]))
dict = {}
for str in text:
if str in dict.keys():
dict[str] = dict[str] + 1
else:
dict[str] = 1
word_list=sorted(dict.items(), key=lambda x: x[1], reverse=True)
3.执行效果截图:
功能2 支持命令行输入英文作品的文件名,请老五亲自录入。
>wf gone_with_the_wand
total 1234567 words
the 5023
a 4783
love 4572
fire 4322
run 3822
cheat 3023
girls 2783
girl 2572
slave 1322
buy 822此功能完成后你的经验值+30. 输入文件最大不超过40MB. 如果你的程序中途崩了,会被老五打脸,不增加经验值。
答:
1.重难点
命令行输入功能完成后就要通过命令行参数对程序进行相关的调用
大数据量的处理
2.重要代码片断:
file = argv[-1] + '.txt' is_file = os.path.exists(file) if is_file: list = file_read(file) if len(list) <=10: print('total', len(list), 'words') for item in list: print('{:20s}{:>5d}'.format(item[0], item[1])) else: print('total', len(list), 'words') print('\n') for i in range(10): print('{:20s}{:>5d}'.format(list[i][0], list[i][1]))
3.执行效果截图:

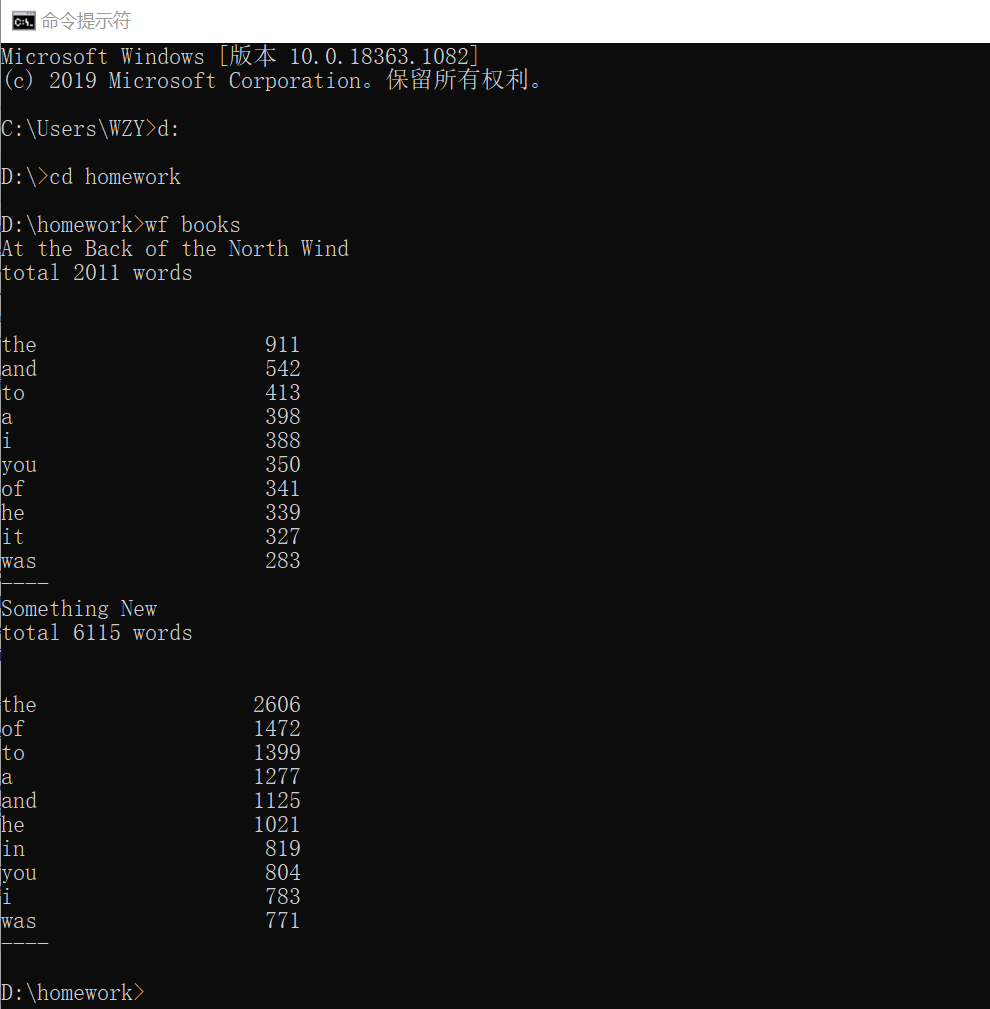
功能3 支持命令行输入存储有英文作品文件的目录名,批量统计。
>dir folder
gone_with_the_wand
runbinson
janelove
>wf folder
gone_with_the_wand
total 1234567 words
the 5023
a 4783
love 4572
fire 4322
run 3822
cheat 3023
girls 2783
girl 2572
slave 1322
buy 822
----
runbinson
total 1234567 words
friday 5023
sea 4783
food 4572
dog 4322
run 3822
hot 3023
cood 2783
cool 2572
bible 1322
eat 822
----
janelove
total 1234567 words
love 5023
chat 4783
lie 4572
run 4322
money 3822
inheritance 3023
class 2783
attribute 2572
data 1322
method 822因为单词量巨大,只列出出现次数最多的10个单词。
此功能完成后你的经验值+8.
答:
1.重难点:
需要输入文件名然后批量处理文件内的文本文件
2.重要代码片断:
else: if argv[-1] != '-s': folder_name = argv[-1] os.chdir(folder_name) filename_list = os.listdir() for file_name in filename_list: print(file_name[:-4]) file_list = [file_name[:-4]] get_words(file_list) print('----\n')
3.执行效果截图:
功能4 从控制台读入英文单篇作品,这不是为了打脸老五,而是为了向你女朋
友炫酷,表明你能提供更适合嵌入脚本中的作品(或者如她所说,不过是更灵活
的接口)。如果读不懂需求,请教师兄师姐,或者 bing: linux 重定向,尽管
这个功能在windows下也有,搜索关键词中加入linux有利于迅速找到。
>wf -s < the_show_of_the_ring
total 176
the 6
a 3
festival 2
dead 2
for 2
...或
>wf
A festival for the dead is held once a year in Japan. The festival is
a cheerful occation, for the dead are said to return to their homes
and they are welcomed by the living.
total 176
the 6
a 3
festival 2
dead 2
for 2
...此功能完成后你的经验值+10.
答:没有实现
代码及版本控制
(5分。虽然只有5分,但此题如果做错,因为教师得不到你的代码,所以会导致“功能实现”为负分。)
代码要求在 coding.net 做版本控制。要求push&pull时使用git客户端,不允许使用web页面。
答:
代码地址:https://e.coding.net/yyy11/cp/cp.git
感谢李思源同学指出未开源 ,现已开源
PSP
(8分)
在同一篇博客中,参照教材第35页表2-2和表2-3,为上述“项目”制作PSP阶段表格。
PSP阶段表格第1列分类,如功能1、功能2、测试功能1等。
要求1 估算你对每个功能 (或/和子功能)的预计花费时间,填入PSP阶段表格,时间颗粒度为分钟。
要求2 记录词频统计项目实际花费时间,填入PSP阶段表格,时间颗粒度要求分钟。
要求3 对比要求1和要求2中每项时间花费的差距,分析原因。
答:
| 项目 | 预计花费时间 | 实际花费时间 | 时间花费的差距 | 原因分析 |
| 功能一 | 120min | 396min | 276min | 找思路,找语言,查资料浪费了一些时间 |
| 功能二 | 120min | 141min | 21min | 对知识掌握不熟练有花费了大量的时间修改 |
| 功能三 | 100min | 167min | 67min | 整理代码花费了一些时间 |
| 功能四 | 100min | 246min | 136min | 没有掌握重定向 |
| 测试 | 30min | 132min | 102min | 生成.exe耗费时间 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号