
Hadoop学习笔记一
Hadoop学习笔记一(我的第一次博客)
自我介绍:
很高兴能开始第一次的博客写作开始,这里我就简单的自我介绍,我叫王进,主要之前学习的专业方向为大数据,因此接下来我的第一篇博客会给大家介绍一下Hadoop平台的简单搭建与使用,因为这是第一次编写博客,因此可能文字性描述没那么多,而我会在后面的编辑一个专门书写关于大数据相关知识的博客发布栏目。
1.实验环境与相关软件:
三台虚拟机:master slave1 slave2
虚拟机账户:root
虚拟机密码:123456
系统:Wondow10系统
软件:Vmvare 15.5Pro Xshell5 Xftp5
Jar包:hadoop-2.7.1.tar.gz jdk-8u152-linux-x64.tar.gz
软件存放位置:/opt/software/
软件安装位置:/usr/local/src/
2.基础环境配置
实验任务一:Linux基础环境配置
(1)查看IP
ip addr
(2)设置静态IP
1.网络配置文件设置
(1)进入网络配置文件目录
cd /etc/sysconfig/network-scripts
(2)修改配置文件
vim ifcfg-ens33
(3)修改与添加配置以下
修改配置如下:
BOOTPROTO="static" dhnp改为static
ONBOOT="yes" no改为yes
添加配置如下:
IPADDR=192.168.38.10
GATEWAY=192.168.38.2
NETMASK=255.255.255.0
DNS1=192.168.38.2
DNS2=8.8.8.8
DNS3=114.114.114.114
(4)保存修改网络配置文件,重启网卡服务
service network restart
(5)验证网络配置结果
ping www.baidu.com
(6)查看ip
[root@VM-M-01594949483071 ~]# ip a
ip应该为192.168.255.10
(2)修改主机名
[root@01 ~]# hostnamectl set-hostname master
[root@01~]# bash
[root@02 ~]# hostnamectl set-hostname slave1
[root@02 ~]# bash
[root@03 ~]# hostnamectl set-hostname slave2
[root@03 ~]# bash
(3)主机映射
[root@master ~]# vi /etc/hosts
[root@slave1 ~]# vi /etc/hosts
[root@slave2 ~]# vi /etc/hosts
添加配置如下:
192.168.38.10
192.168.38.11
192.168.38.12
(4)关闭防火墙与防火墙自启
1.关闭防火墙
[root@master ~]# systemctl stop firewalld
[root@slave1 ~]# systemctl stop firewalld
[root@slave2 ~]# systemctl stop firewalld
2.防火墙自启
[root@master ~]# systemctl disable firewalld
[root@slave1 ~]# systemctl disable firewalld
[root@slave2 ~]# systemctl disable firewalld
3.查看防火墙状态
[root@master ~]# systemctl status firewalld
[root@slave1 ~]# systemctl status firewalld
[root@slave2 ~]# systemctl status firewalld
实验任务二:ssh免密
(1)创建免密(三个主机同时进行)
[root@master ~]$ ssh-keygen -t rsa -P ""
[root@slave1 ~]$ ssh-keygen -t rsa -P ""
[root@slave2~]$ ssh-keygen -t rsa -P ""
(2)发送密钥
master:
[root@master ~]$ ssh-copy-id master
[root@slave1 ~]$ ssh-copy-id slave1
[root@slave2~]$ ssh-copy-id slave2
slave1:
[root@master ~]$ ssh-copy-id master
[root@slave1 ~]$ ssh-copy-id slave1
[root@slave2~]$ ssh-copy-id slave2
slave2:
[root@master ~]$ ssh-copy-id master
[root@slave1 ~]$ ssh-copy-id slave1
[root@slave2~]$ ssh-copy-id slave2
(3)登录测试
[root@master ~]$ ssh slave1
[root@master ~]$ ssh slave2
[root@slave1~]$ ssh slave2
实验三:Hadoop集群部署
(1)Hadoop软件安装
[root@master ~]# tar -zxvf /opt/software/hadoop-2.7.1.tar.gz -C /usr/local/src/
(2)重命名文件名
[root@master ~]# mv /usr/local/src/hadoop-2.7.1 /usr/local/src/hadoop
(3)配置全局环境变量
[root@master ~]# vi /etc/profile
进行如下配置
export HADOOP_HOME=/usr/local/src/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
[root@master ~]# source /etc/profile
注意:一定需要刷新/etc/profile文件
实验四:安装JAVA环境
(1)安装jdk
[root@master ~]# tar -zxvf /opt/software/jdk-8u152-linux-x64.tar.gz -C /usr/local/src
(2)重名名jdk文件夹
[root@master ~]# tar -zxvf /opt/software/jdk-8u152-linux-x64.tar.gz -C /usr/local/src
(3)配置java全局环境配置
[root@master ~]# vi /etc/profile
#添加如下
export JAVA_HOME=/usr/local/src/java #JAVA_HOME指向JAVA安装目录
export PATH=$PATH:$JAVA_HOME/bin #将JAVA安装目录加入PATH路径
(4)生效环境变量
[root@master ~]# source /etc/profile
一定要执行下面命令,应为配置虚拟机为桌面时会自带java,所以需要更新与自己安装的jdk版本一致.
[root@master ~]# update-alternatives --install /usr/bin/java java /usr/local/src/java/bin/java 200
[root@master ~]# update-alternatives --set java /usr/local/src/java/bin/java
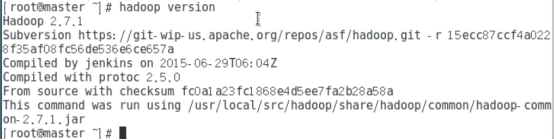
(5)查看java与hadoop是否安装成功
[root@master ~]# java -version

[root@master ~]#hadoop version
实验五:Hadoop集群配置
(1)进入到hadoop配置文件的目录下hadoop
[root@master ~]# cd /usr/local/src/hadoop/etc/hadoop
(2)配置core-site.xml文件
[root@master hadoop]# vi core-site.xml
#在<configuration>与</configuration>中添加如下配置:
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/src/hadoop/</value>
</property>
(3)配置hadoop-env.sh文件
[root@master hadoop]# vi hadoop-env.sh
只需修改JAVA_HOME
export JAVA_HOME=/usr/local/src/java
保存退出
(4)配置mapred-site.xml文件
将副本拷贝成mapred-site.xml
[root@master hadoop]# cp mapred-site.xml.template mapred-site.xml
[root@master hadoop]# vi mapred-site.xml
#在<configuration>与</configuration>中添加如下配置:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
(5)配置yarn-site.xml
[root@master hadoop]# vi yarn-site.xml
#在<configuration>与</configuration>中添加如下配置:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
(6)配置masters文件
[root@master hadoop]# vi masters
master
slave1
slave2
保存退出
实验六:主从节点文件的分发
(1)分发hadoop与java目录
[root@master hadoop]# scp -r /usr/local/src/hadoop/ root@slave1:/usr/local/src/
[root@master hadoop]# scp -r /usr/local/src/hadoop/ root@slave2:/usr/local/src/
[root@master hadoop]# scp -r /usr/local/src/java/ root@slave1:/usr/local/src/
[root@master hadoop]# scp -r /usr/local/src/java/ root@slave2:/usr/local/src/
(2)分发环境配置
[root@master hadoop]# scp -r /etc/profile root@slave1:/etc/
[root@master hadoop]# scp -r /etc/profile root@slave2:/etc/
(3)生效环境变量
slave1:
[root@slave1]# source /etc/profile
[root@slave1 ~]# update-alternatives --install /usr/bin/java java /usr/local/src/java/bin/java 200
[root@slave1 ~]# update-alternatives --set java /usr/local/src/java/bin/java
slave2:
[root@slave2]# source /etc/profile
[root@slave2 ~]# update-alternatives --install /usr/bin/java java /usr/local/src/java/bin/java 200
[root@slave2 ~]# update-alternatives --set java /usr/local/src/java/bin/java
实验六:Hadoop集群启动测试
(1)hadoop启动
1.格式化元数据
[root@master ~]$ hdfs namenode -format
状态为0显示的是成功

2.启动hdfs
[root@master ~]$ start-dfs.sh
3.启动yarn
[root@master ~]$ start-yarn.sh
4.查看进程
[root@master ~]$ jps
master:5个
Resourcemanager
NameNode
DataNode
Jps
SecondaryNameNode
slave1: 3个
NodeManager
Jps
DataNode
slave2: 3个
NodeManager
Jps
DataNode
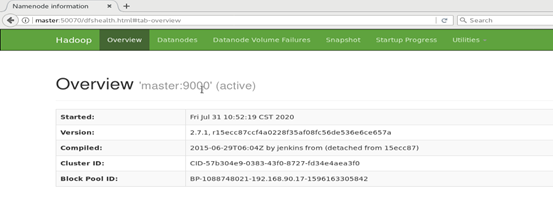
5.进入master(一般为IP地址:192.168.38.10):50070查看
进入到浏览器查看
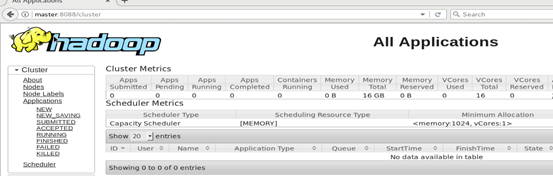
6.查看进入master(一般为IP地址:192.168.38.10):8088查看
7.查看进入master(一般为IP地址:192.168.38.10):9000查看

实验七:Mapreduce测试
(1)创建一个测试文件
[root@master ~]$ vi a.txt
添加一下配置:
hello world
hello hadoop
hello java
保存退出
(2)在hdfs创建文件夹
[rootp@master ~]$ hadoop fs -mkdir /input
(3)将a.txt传输到input上
[root@master ~]$ hadoop fs -put ~/a.txt /input
(4)进入到jar包测试文件目录下
[root@master hadoop]pwd
/usr/local/src/hadoop/
[root@master hadoop]$ cd share/hadoop/mapreduce/
(5)测试mapreduce
[root@master mapreduce]$ hadoop jar hadoop-mapreduce-examples-2.7.1.jar wordcount /input/a.txt /output

(6)查看文件测试的结果
[root@master mapreduce]# hadoop fs -cat /output/part-r-00000

以上便是简单的Hadoop完全分布式的简单的搭建与测试。希望大家给出一些指导意见,初次书写博客,可能有些不是地完美的地方。
2.短期目标
1.本学期课程:UML面向对象分析建模 Oracle数据库管理与开发 计算机操作系统 Java Web应用开发从入门到实践 计算机网络教程
2.目前困境:以上这五门课程完全时没有学过,而有些同学时在以前学校就开过课程的,因此自己必须付出比他人更加的时间才能不断缩小与他人的差距。做人也需要脚踏实地一步一个脚印,而不能一飞冲天。除去五门必须课程还需要完成五门课程设计以及实验课程的报告实验书写,因此这些对我来说都是一些全新的挑战,教学模式与以前也相差比较大,因此除花费跟多时间更加应该注重的是学习方法与思维的转变。
3.目标:完成所有课程及课程设计,争取所有课程达到优秀。并拓展除课程外的其他知识。
3.总结
这里就送大家和自己一句话语:“没有什么不可能完成不了的事情,关键是你是否有勇气去面对,第一时间付出行动,而不只是计划”。

