yolov3结构详细讲解
在整个YOLO系列中,YOLOv3是早期YOLO技术的集大成者,又为后续版本(如YOLOv4/v5等)奠定了基础,YOLOv3(You Only Look Once version 3)是Joseph Redmon等人于2018年提出的实时目标检测算法,属于YOLO系列的第三代模型。它以高效和速度著称,同时在精度上取得了显著提升,尤其在小目标检测和多尺度预测方面有重要改进。所以本文打算对官方的yolov3结构作较详细的分析。本文根据结构图与配置文件进行详解。
1. YOLOv3的整体结构
YOLOv3的整体结构主要由主干网络(Backbone),特征金字塔网络(FPN),输出层组成。
- 主干网络(Backbone):Darknet-53
Darknet-53是一个深度残差网络,包含52个卷积层(最初用来分类,最后有一个全连接层,所以最初是53,yolov3中没有全连接层),用于提取图像特征。
- 金字塔网络(FPN, Feature Pyramid Network)
FPN通过上采样和特征融合的方式生成多尺度特征图。
- 输出层(Output Layers)
YOLOv3在三个不同尺度的特征图上进行预测,分别对应大、中、小目标的检测。
2.YOLOv3每层参数详解
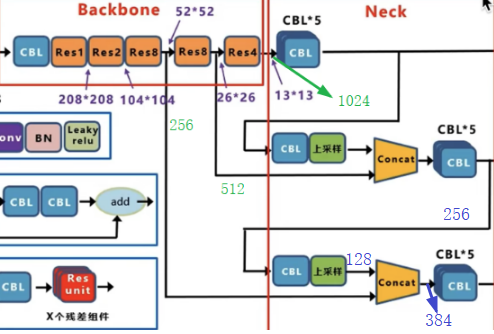
看下面结构图,红色框框起来的分别是输入端,主干网络Backbone,Neck,输出层。这里要注意在原始论文中只提到了Backbone,后面的Neck没有这样命名,从yolov4后,才区分Neck,Head。所以有时候看到的名称不一样,比如主流的ultrayltics中的yolov3配置文件结构中只能看到Backbone与Head。
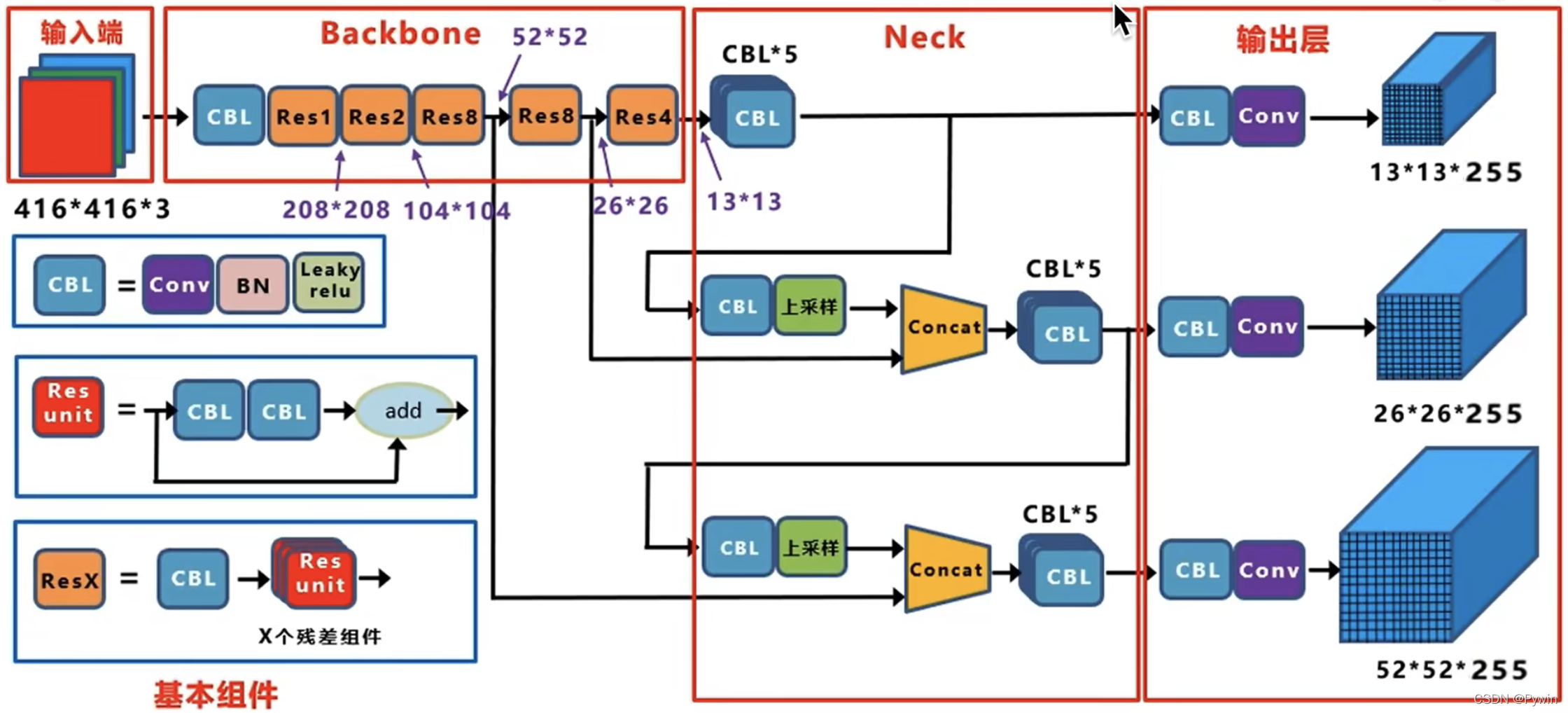
在结构图的左侧有一个CBL(有些地方叫DBL,都是同一个东西),CBL卷积层由卷积Conv(卷积),批量归一化BN,及激活函数Leaky relu组成,CBL结构用来特征提取或降维(使用1x1的卷积降通道数) 。Resunit(残差单元)由两个CBL与一个跳跃链接组成,这里的连接为shortcut(通道值直接相加),与后面的concat(融合)通道拼接不同。Resunit中这里需要注意一点,一般来说,第一个CBL中conv的卷积核长宽尺寸为1x1,步幅stride为1,填充为0,核通道数与核个数与位置有关,但是,其通道数是相对于输入通道来说是减半的。第二个CBL的卷积长宽尺寸为3x3,通道数与个数与位置有关,但是该CBL在第一个CBL降维(减少一半通道数)之后,特征提取的同时,进行通道的升维,也就是通道还原了。还有一个ResX由一个CBL与X个Rexunit组成,这里的CBL中卷积长宽尺寸一般为3x3,stride为2,填充为1,核个数为输入一半,用来特征提取与降低特征图尺寸(宽高都降低一半)。
在具体分析每层参数前,先给出Backbone的参数组成图,如图所示:
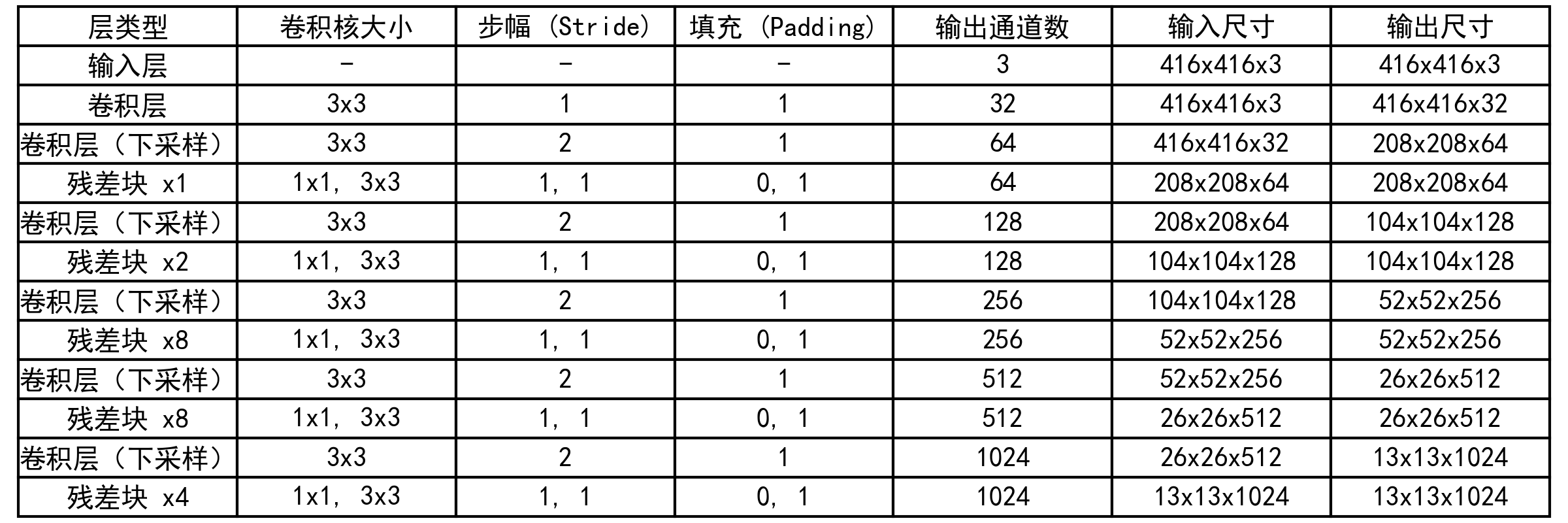
Backbone部分:结合上表与前面的结构得知该部分由CBL,Res1,Res2,Res8,Res8,Res4组成,第一个CBL的中卷积使用3x3大小,步幅为1,填充为1,每个核通道数3,核个数对原始的416x416图进行运算,最后得到了416x416x32的输出特征图,也就是说第一个CBL没有改变输入的尺寸大小,仅仅特征提取与改变了通道数。然后是Res1,这里通过表中知道,Res1由卷积层(下采样)与残差块组成,卷积层也是3x3,填充为1,但是步幅为2,所以输出尺寸变为之前的二分之一,核的个数变为两倍,所以通道数变为原来的两倍。Res1的残差块中,前面提到过,第一个CBL中的卷积核为1x1,核个数32(表中没有显示)是为了降维,也就是改变通道数,将其减半,Res1的残差块中第二个CBL卷积核为3x3,核个数又恢复到了前面的卷积层的输入通道数,也就是64,也就说第一个卷积层负责降维,通道数减半,第二个卷积层负责特征提取,然后恢复通道数。Res2中的卷积层的CBL也就是表中的卷积层(下采样),然后后面是紧跟两个残差块,第一个残差块第一个CBL也是负责降维,通道数减半,第二个CBL负责特征提取。这里注意第二个残差块,依然是对第一个残差块的输出先降维,通道数减半,再特征提取,然后恢复通道数。后面的残差组件Res8,Res8,Res4依此类推。
所以,最后每层的输出尺寸大小就如图中所示(具体看表中)。这里强调以下,主干部分是Darknet-53,但是并没有53个卷积层,只有52,最前面解释过了。这里计算一下52个卷积(或卷积层)是怎么计算的。我们知道backbone部分由CBL,Res1,Res2,Res8,Res8,Res4组成。一个CBL包含有1个卷积Conv,X个rRes包括的卷积个数(或卷积层CBL个数)为1+2X,这里1代表ResX最前面有个CBL,2代表每个Res包含有两个CBL,X代表残差单元重复的次数。这里计算为1(CBL)+3(Res1)+5(Res2)+17(Res8)+17(Res8)+9(Res4)=52。故yolov3中Darknet-53包括52个卷积;
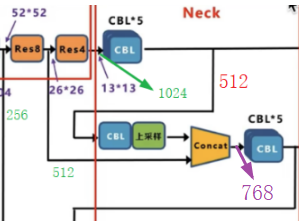
Neck部分:如图中所示,在 YOLOv3 中,Neck 层 的功能由特征金字塔网络(FPN)与上采样(原文为最近邻插值法,相对于双线性插值而言,不会引入新值,且速度快)和特征融合组成。具体来说,YOLOv3 在三个不同尺度(13x13、26x26、52x52)上进行预测,分别对应大、中、小目标的检测,这些特征图通过上采样和横向连接的方式生成。较大的特征图(如 26x26 和 52x52)是通过对较小的特征图(如 13x13 和 26x26)进行上采样,并与来自主干网络的特征图进行融合生成的。看下图中,这里我使用绿色标注了需要融合的Res8,Res8与Res4层输出的通道数,分别是256,512,1024,后面计算会用到。先看Res4后面连接的CBL*5,这里其实是串联的5个CBL,图中为了节省位置这样绘制的。
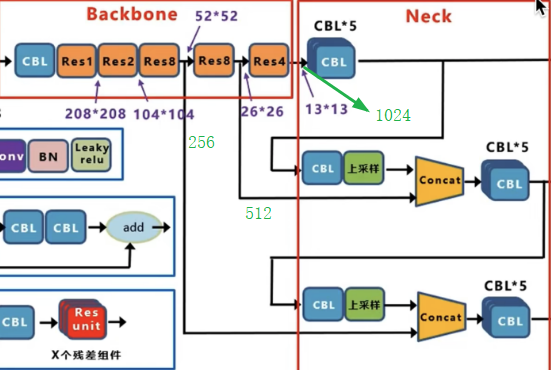
这里给出CBL*5详解结构组成(省略了B,L),如下图所示,也就是卷集核个数512的size为1的时候为降维,为1024,size为3的时候为特征提取,但是都没有改变特征图的长宽尺寸。

所以经过5个CBL输出后特征图通道数为512了。
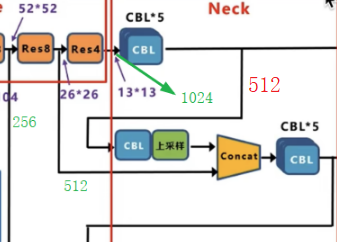
然后再看融合13x23与26x26的那个上采样旁边的CBL,他的卷积结构参数结构如下:

再经过2倍最近邻上采样后,其输出为尺寸大小为26x26,通道数为256,然后就能与来自26x26x512的特征图进行融合了(注意,这里融合是指concat,就是通道数叠加起来,增加通道数,与前面的shortcut不同),所以融合后的的输出如下(图中紫色标记,通道数为768,尺寸为26x26):
然后回到原图,我们发现融合后的26x26x768特征图经过5个CBL后,再经过1个CBL,上采样后再与52x52x256的特征图融合,这里还是给出其CBL*5中的卷积参数结构:

然后是再经过一个CBL,再经过上采样后就变为了52x52x128了,该处的CBL的作用前面的差不多,降维,减半通道数。

所以最后融合后的输出如图所示:(图中蓝色标记的通道数):
最后还有一个CBL*5,其卷积的参数结构如下:

所以最后输出到输出层的结构为52x52x128。
到这里,Neck层就结束了,下面给出该层每个节点的输出图(图中使用橙色标记了通道数)。
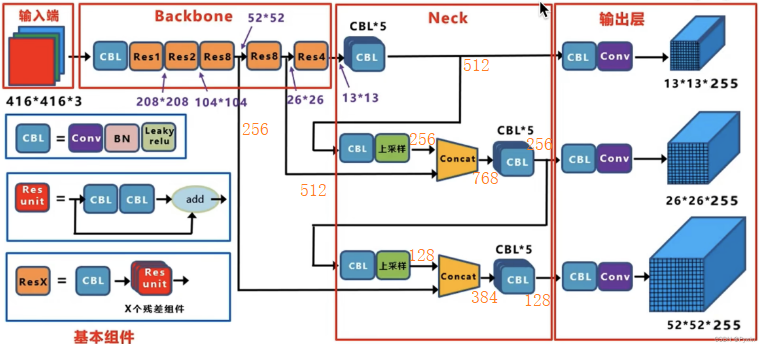
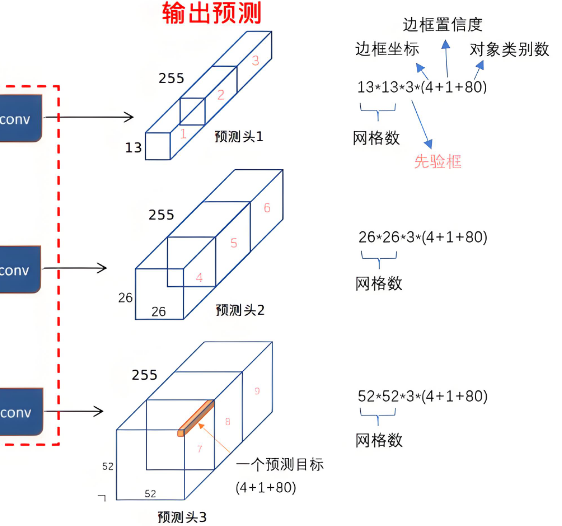
输出层(Head):通过上图得知输入到输出层的三个分支分别是13x13x512、26x26x256、52x52x128。然后每个分支分别经过一个CBL与一个1x1卷积Conv得到最后的输出特征图。最后经过sigmoid(logsitc)(这里不是softmax,可能一个目标既属于一个类,又属于另一个类情况)判断每个目标属于每个类别的概率,其概率之和必然不为1.除了类别之外,还有中心点相对于格子左上角的偏移量,也是用sigmoid激活固定其范围0~1。然后是对输出的宽高经过指数运算得到真正的宽高。文本后面会详细讲解这个问题。
最后一个CBL分别是对各自的输入进行特征提取(卷集核采用3x3,stride=1,pad=1),并增加通道数。经过CBL后,三个分支分别是13x13x1024,26x26x512,52x52x256。最后都经过1x1,stride=1,pad=0,核个数=255(因为是80个类别,计算公式为3*(4+1+80)),具体细节文章后面再给出,最后输出为13x13x255,26x26x255,52x52x255。对于具体的输出结构看下面的图(网图)。
不同特征图的适用情况如下:
- 深层特征图(如52×52)分辨率高,保留更多细节,适合检测小目标,使用的锚框为尺寸最小的三个;
- 中层特征图(如26×26)平衡细节与语义,检测中等尺寸物体,使用的锚框为尺寸中等的三个;
- 浅层特征图(如13×13)具有强语义信息,擅长定位大目标,使用的锚框为尺寸最大的三个;
这里以一张图片(左侧网图,右侧自己绘制)为例,来说明预测的结果信息是怎么来的。
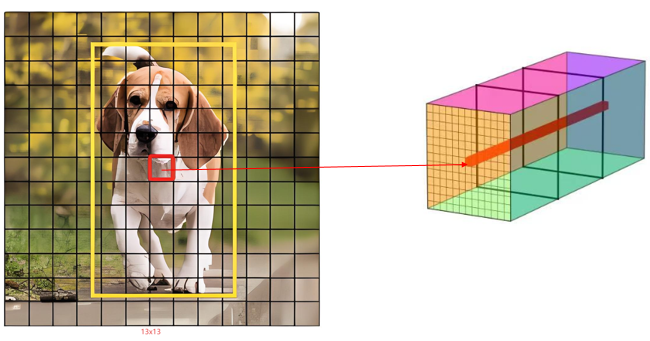
上图中对于13x13的分支检测头(图中右侧矩形体),其第7行7列对应左图的7行7列,右侧的为使用大锚框输出的结果图。YOLOv3中有这样一条规则,对于左图而言,如果目标的中心点在该格子中,那么这个格子对应的检测头对应的位置就负责预测该目标,这句话是什么意思?这样做其实是为了方便构造损失函数,用于损失函数里,后面会看损失函数。也就是周围的格子,是否预测到目标不参与到损失函数中,这里还有一点要注意,左侧图中狗的格子与右侧格子是对应关系,并不是说右侧的格子就是左侧的格子特征提取而来,具体来说:在深度卷积网络里,随着网络层的堆叠,后面特征图的每个点的感受野就越大。在YOLOv3里,13×13的检测头并不是只看到了原图对应网格区域的内容,而是通过特征提取网络的感受野,间接地看到了整个目标甚至更大范围的信息,检测头的每个位置负责预测该格子中心落在原图对应区域的物体,但特征图上该位置的神经元的感受野远大于32×32像素(13x13,26x26,52x52分别对应32倍,16倍,8倍采样),13×13的检测头的任何一点,都远比32x32要大得多(这里计算较繁琐,不去计算了)。将上图中的右侧的深红色的拿出来放在下方如下:

这里我们发现其长度为(4+1+class_nums)*3,当类别为80类时,其通道数,也就是最后1x1卷积核数量为(4+1+80)*3=255个了。
真实的中心点位置与宽高 计算公式如下,先看中心点:
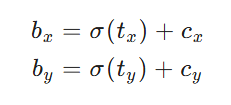
-
其中σ(tₓ), σ(tᵧ) 把偏移限制在 [0,1],加到该网格左上角坐标 cₓ, cᵧ 上。
再看宽高,etw 和 eth以 anchor 为基准做指数缩放,可得到任意比例,Pw与为Ph锚框的宽高。
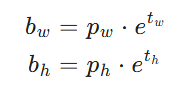
具体可以看下面这张图(来自网络),如图所示预测的其中一个结果经过激活函数sigmoid激活后加上了该格子的左上角的顶点坐标就得到了预测的中心点坐标,宽高使用指数运算得到。
3.损失函数
看下图,由三部分组成,分别是边界框坐标损失,置信度损失与类别损失。
(1) 边界框坐标损失(LboxLbox)
采用均方误差(MSE)或二元交叉熵(BCE)计算预测框与真实框的差异,通常包含:
-
中心坐标误差:对 (x,y)(x,y) 使用Sigmoid激活后的BCE损失。
-
宽高误差:对 (w,h)(w,h) 使用平方根变换后的MSE损失(缓解大框和小框的不平衡)。
- 1ijobj1ijobj:如果第 ii 个网格的第 jj 个锚框负责预测目标则为1,否则为0。
- λcoordλcoord:坐标损失的权重
(2) 置信度损失
-
λobjλobj 和 λnoobjλnoobj 是权重(通常 λnoobj=0.5λnoobj=0.5,抑制负样本影响)。
-
使用二元交叉熵(BCE)替代MSE也是常见做法。
(3) 分类损失
采用二元交叉熵(BCE)(支持多标签分类):
- pi(c)pi(c):真实类别概率(0或1)。
- p^i(c)p^i(c):预测类别概率(通过Sigmoid输出)

关于损失这部分简单概述,觉得不够清晰地可以网上看看,很多介绍的。
4.官方配置文件
[net] # Testing batch=1 subdivisions=1 # Training # batch=64 # subdivisions=16 width=416 height=416 channels=3 momentum=0.9 decay=0.0005 angle=0 saturation = 1.5 exposure = 1.5 hue=.1 learning_rate=0.001 burn_in=1000 max_batches = 500200 policy=steps steps=400000,450000 scales=.1,.1 [convolutional] batch_normalize=1 filters=32 size=3 stride=1 pad=1 activation=leaky # Downsample [convolutional] batch_normalize=1 filters=64 size=3 stride=2 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=32 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=64 size=3 stride=1 pad=1 activation=leaky [shortcut] from=-3 activation=linear # Downsample [convolutional] batch_normalize=1 filters=128 size=3 stride=2 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=64 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=128 size=3 stride=1 pad=1 activation=leaky [shortcut] from=-3 activation=linear [convolutional] batch_normalize=1 filters=64 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=128 size=3 stride=1 pad=1 activation=leaky [shortcut] from=-3 activation=linear # Downsample [convolutional] batch_normalize=1 filters=256 size=3 stride=2 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=128 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=256 size=3 stride=1 pad=1 activation=leaky [shortcut] from=-3 activation=linear [convolutional] batch_normalize=1 filters=128 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=256 size=3 stride=1 pad=1 activation=leaky [shortcut] from=-3 activation=linear [convolutional] batch_normalize=1 filters=128 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=256 size=3 stride=1 pad=1 activation=leaky [shortcut] from=-3 activation=linear [convolutional] batch_normalize=1 filters=128 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=256 size=3 stride=1 pad=1 activation=leaky [shortcut] from=-3 activation=linear [convolutional] batch_normalize=1 filters=128 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=256 size=3 stride=1 pad=1 activation=leaky [shortcut] from=-3 activation=linear [convolutional] batch_normalize=1 filters=128 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=256 size=3 stride=1 pad=1 activation=leaky [shortcut] from=-3 activation=linear [convolutional] batch_normalize=1 filters=128 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=256 size=3 stride=1 pad=1 activation=leaky [shortcut] from=-3 activation=linear [convolutional] batch_normalize=1 filters=128 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=256 size=3 stride=1 pad=1 activation=leaky [shortcut] from=-3 activation=linear # Downsample [convolutional] batch_normalize=1 filters=512 size=3 stride=2 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=256 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=512 size=3 stride=1 pad=1 activation=leaky [shortcut] from=-3 activation=linear [convolutional] batch_normalize=1 filters=256 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=512 size=3 stride=1 pad=1 activation=leaky [shortcut] from=-3 activation=linear [convolutional] batch_normalize=1 filters=256 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=512 size=3 stride=1 pad=1 activation=leaky [shortcut] from=-3 activation=linear [convolutional] batch_normalize=1 filters=256 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=512 size=3 stride=1 pad=1 activation=leaky [shortcut] from=-3 activation=linear [convolutional] batch_normalize=1 filters=256 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=512 size=3 stride=1 pad=1 activation=leaky [shortcut] from=-3 activation=linear [convolutional] batch_normalize=1 filters=256 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=512 size=3 stride=1 pad=1 activation=leaky [shortcut] from=-3 activation=linear [convolutional] batch_normalize=1 filters=256 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=512 size=3 stride=1 pad=1 activation=leaky [shortcut] from=-3 activation=linear [convolutional] batch_normalize=1 filters=256 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=512 size=3 stride=1 pad=1 activation=leaky [shortcut] from=-3 activation=linear # Downsample [convolutional] batch_normalize=1 filters=1024 size=3 stride=2 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=512 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=1024 size=3 stride=1 pad=1 activation=leaky [shortcut] from=-3 activation=linear [convolutional] batch_normalize=1 filters=512 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=1024 size=3 stride=1 pad=1 activation=leaky [shortcut] from=-3 activation=linear [convolutional] batch_normalize=1 filters=512 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=1024 size=3 stride=1 pad=1 activation=leaky [shortcut] from=-3 activation=linear [convolutional] batch_normalize=1 filters=512 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=1024 size=3 stride=1 pad=1 activation=leaky [shortcut] from=-3 activation=linear ###################### [convolutional] batch_normalize=1 filters=512 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 size=3 stride=1 pad=1 filters=1024 activation=leaky [convolutional] batch_normalize=1 filters=512 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 size=3 stride=1 pad=1 filters=1024 activation=leaky [convolutional] batch_normalize=1 filters=512 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 size=3 stride=1 pad=1 filters=1024 activation=leaky [convolutional] size=1 stride=1 pad=1 filters=255 activation=linear [yolo] mask = 6,7,8 anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326 classes=80 num=9 jitter=.3 ignore_thresh = .7 truth_thresh = 1 random=1 [route] layers = -4 [convolutional] batch_normalize=1 filters=256 size=1 stride=1 pad=1 activation=leaky [upsample] stride=2 [route] layers = -1, 61 [convolutional] batch_normalize=1 filters=256 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 size=3 stride=1 pad=1 filters=512 activation=leaky [convolutional] batch_normalize=1 filters=256 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 size=3 stride=1 pad=1 filters=512 activation=leaky [convolutional] batch_normalize=1 filters=256 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 size=3 stride=1 pad=1 filters=512 activation=leaky [convolutional] size=1 stride=1 pad=1 filters=255 activation=linear [yolo] mask = 3,4,5 anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326 classes=80 num=9 jitter=.3 ignore_thresh = .7 truth_thresh = 1 random=1 [route] layers = -4 [convolutional] batch_normalize=1 filters=128 size=1 stride=1 pad=1 activation=leaky [upsample] stride=2 [route] layers = -1, 36 [convolutional] batch_normalize=1 filters=128 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 size=3 stride=1 pad=1 filters=256 activation=leaky [convolutional] batch_normalize=1 filters=128 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 size=3 stride=1 pad=1 filters=256 activation=leaky [convolutional] batch_normalize=1 filters=128 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 size=3 stride=1 pad=1 filters=256 activation=leaky [convolutional] size=1 stride=1 pad=1 filters=255 activation=linear [yolo] mask = 0,1,2 anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326 classes=80 num=9 jitter=.3 ignore_thresh = .7 truth_thresh = 1 random=1
配置文件经过分析后与结构图能一一对应,关于配置文件里,有几点需要注意,activation=linear这里表示线性,我们都知道激活函数是非线性的,所以这里表示不使用激活函数。mask = 0,1,2这里表示使用锚框的第0,1,2个锚框,这里面的[route] layers = -1, 61表示路由层,是为了特征融合。里面的-1表示该层的倒数第一层,61表示第61层,这里的层不是网络结构图的层,是配置文件里的层,比如 [convolutional],[route],[yolo],[upsample],[shortcut]都算作层,每层就是每个[]包括下方的参数,注意层数从0开始计数的。弄清楚结构之后,我们很容易去配置了,根据自己的类别数配置[yolo]前的1x1卷积,若是80类就是(4+1+80)*3=255。另外,我们需要注意由于CBL中包含了BN,BN学习的参数自带偏置项了,所以往往能看到网络结构中不再使用偏置了,但是对于每个分支的最后一个是纯卷积是可以带偏置项的。另外配置里面卷集核大小为1,步幅为1的地方其填充pad应该为0,但是上面给的原始配置文件为pad=1,这个可能与代码实现有关(如代码实现中如果是发现核大小为1,就自动不考虑pad了)。
小结:本文对YOLOV3理论作了详细的讲解,并未讲解训练的方法或步骤,且关于感受野的详细计算并未给出,后期会对训练步骤与文中提到的感受野范围作具体计算与补充。
若有不足或错误之处,欢迎指出与评论!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号