图像分类训练集与测试集划分
图片数据集划分的方式与方法有很多,比如先将图片转换为矩阵,再使用scikit-learn包去划分。为了使得数据集更灵活,本文介绍python实现图片分类数据集的划分。
假设现在的数据集文件夹为flower_images,flower_images文件夹中有5类,每个类1000张。
使用自己的python代码:
splitdata.py
import os import numpy as np import shutil import time def split_data(path=None, train_ratio=0.8, new_root=None, pic_split=True, seed=7): if path==None or os.path.exists(path)==False: raise Exception('数据集路径错误') else: #创建文件夹 # 使用os.makedirs()函数递归创建文件夹 os.makedirs(new_root)#如果没有这个目录,会递归创建 os.makedirs(new_root+'\\'+'train')#创建train os.makedirs(new_root + '\\'+'test')#创建test print('文件夹创建成功,分别为',new_root+'\\train'+" "+new_root+'\\test') #构建所有文件名的列表,dir为label filename = [] dirs = os.listdir(root) print(dirs)#['Lilly', 'Lotus', 'Orchid', 'Sunflower', 'Tulip'] for index,dir in enumerate(dirs): dir_path = root + '\\' + dir names = os.listdir(dir_path) for name in names: filename.append(dir_path + '\\' + name + ' ' + str(index)) # 设置随机种子 np.random.seed(seed=seed)#如果随机种子相同,随机的结果也相同 #打乱文件名列表 np.random.shuffle(filename) #划分训练集、测试集,默认比例4:1 train = filename[:int(len(filename)*train_ratio)] test = filename[int(len(filename)*train_ratio):] #分别写入train.txt, test.txt with open('train.txt', 'w') as f1, open('test.txt', 'w') as f2,open('train_split.txt','w') as f1_split,open('test_split.txt','w') as f2_split: for i in train: f1.write(i + '\n')#原始的路径 i_split=i.split(' ') train_img_path=i_split[0] train_img_cls=i_split[1] train_img_name=train_img_path.split('\\')[-1] shutil.copy2(train_img_path, new_root+'\\'+'train'+'\\'+train_img_name) f1_split.write(new_root+'\\'+'train'+'\\'+train_img_name+' '+train_img_cls+'\n') for j in test: f2.write(j + '\n')#原始的路径 j_split = j.split(' ') test_img_path = j_split[0] test_img_cls = j_split[1] test_img_name = test_img_path.split('\\')[-1] shutil.copy2(test_img_path, new_root + '\\' + 'test'+'\\'+test_img_name) f2_split.write(new_root+'\\'+'test'+'\\'+test_img_name+' '+test_img_cls+'\n') if __name__ == '__main__': start=time.time()#开始时间 root = r"D:\BaiduNetdiskDownload\flower_images"#绝对路径,自己的图片数据集路径 train_ratio=0.8#训练集的占比,自己设定 root_list=root.split('\\') print(root_list)#['D:', 'BaiduNetdiskDownload', 'flower_images'] new_root=None new_root='\\'.join(root_list[:-1])+'\\'+root_list[-1]+"_split" print(new_root)#D:\BaiduNetdiskDownload\flower_images_split split_data(root, train_ratio,new_root=new_root) end=time.time()#结束时间 print(end-start)# 输出的结果将是以秒为单位的时间间隔
运行后如下图,自己电脑用时8秒多,多了test.txt、test_split.txt、train.txt、train_split.txt,为什么是四个呢,根据自己的需要选择train.txt、test.txt或者train_split.txt、test_split.txt。

除此之外,还生成了flower_images_split文件夹,里面是对数据分成了两个文件夹train与test。
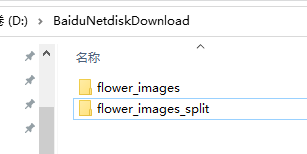
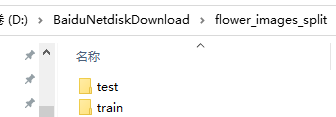
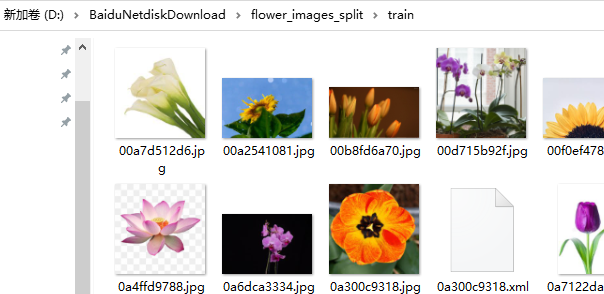
train和test里面是混合的各类图片。
至于 test.txt、test_split.txt、train.txt、train_split.txt这四个文件里面内容格式,这里也给出截图。

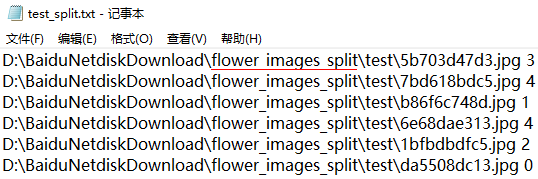

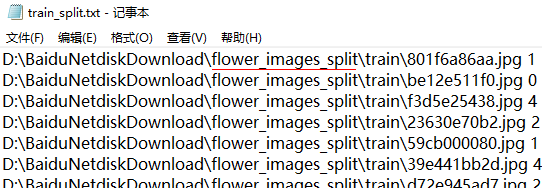
可以看到,内容为路径空格数字表示的类别。所以最后,如果是用原来的图片文件夹flower_images就使用train.txt、test.txt。如果是使用生成的图片文件夹flower_images_split,就使用train_split.txt、test_split.txt。
小结:关于数据集之前已经给出了,网上也可以下载。
若存在不足或者错误之处,欢迎评论与指正!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号