Linux设备驱动故障定位指引与实例
Linux设备驱动故障定位指引
Linux设备驱动种类繁多,涉及的知识点多,想写一个通用的故障定位方法指引,是个难度颇大且不容易做好的工作。限于笔者的经验,难以避免存在疏漏之处,欢迎大家留言指正补充。
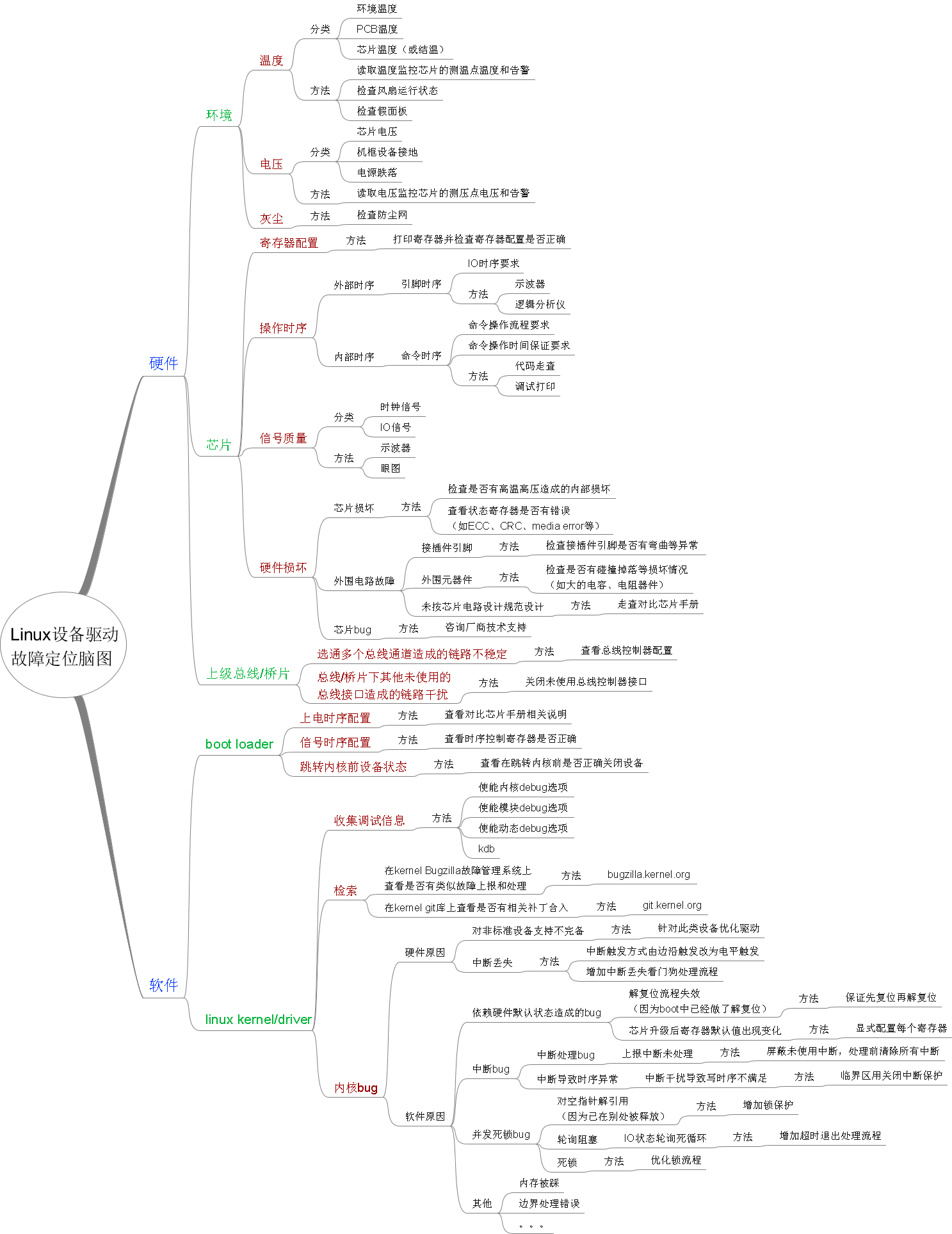
Linux设备驱动的知识点涉及硬件和软件,其故障原因也各种各样。不过从笔者多年的维护经验来看,与内核驱动相比,硬件相关问题导致的设备驱动故障还是占了较大的比例,而且大部分的硬件问题特别是环境问题也是相对来说较容易排查的。下图是Linux设备驱动故障定位脑图(大图),图中按硬件和软件分为两类,硬件分类又细分为环境、芯片和上级总线/桥片,软件分类又细分为bootloader和内核驱动。每个检查点给出检查项和检查方法。
MTD设备驱动故障定位示例
故障描述
某一块单板上有一块型号S29GL01GT11TFIV10的NOR flash,其上使用UBIFS文件系统,用于储存3.10内核镜像。测试中发现单板上电过程中,大概有10%的概率会偶现如下内核异常,并且此后所有flash命令操作都失败,flash无法正常访问:
MTD get_chip(): chip not ready after erase suspend
UBI error: ubi_io_write: error -5 while writing 512 bytes to PEB 932:36992, written 0 bytes
notice(4295011711): cpu0 max interrupt interval is 112812200ns
sCall Trace: [jiffies: 0x10000ad9b]
[<ffffffffc0be76cc>] dump_stack+0x8/0x34
[<ffffffffc0a0b624>] ubi_io_write+0x52c/0x670
[<ffffffffc0a079e8>] ubi_eba_write_leb+0xd8/0x758
[<ffffffffc0897470>] ubifs_leb_write+0xd0/0x178
[<ffffffffc0898cd0>] ubifs_wbuf_write_nolock+0x430/0x798
[<ffffffffc088b16c>] ubifs_jnl_write_data+0x1e4/0x348
[<ffffffffc088e5a8>] do_writepage+0xc8/0x258
[<ffffffffc0714d70>] __writepage+0x18/0x78
[<ffffffffc0715ab8>] write_cache_pages+0x1e0/0x4c8
[<ffffffffc0715de0>] generic_writepages+0x40/0x78
[<ffffffffc0784620>] __writeback_single_inode+0x58/0x370
[<ffffffffc0785b84>] writeback_sb_inodes+0x2e4/0x498
[<ffffffffc0785df8>] __writeback_inodes_wb+0xc0/0x118
[<ffffffffc07862fc>] wb_writeback+0x234/0x3c0
[<ffffffffc0786918>] wb_do_writeback+0x230/0x2b0
[<ffffffffc0786a1c>] bdi_writeback_workfn+0x84/0x268
[<ffffffffc0670300>] process_one_work+0x180/0x4d0
[<ffffffffc0671848>] worker_thread+0x158/0x420
[<ffffffffc06786c0>] kthread+0xa8/0xb0
[<ffffffffc06204c8>] ret_from_kernel_thread+0x10/0x18
故障分析及定位步骤
相应代码片段如下(所在位置:drivers/mtd/chips/cfi_cmdset_0002.c:get_chip),其实现功能是如果发现当前flash处在擦除状态,下发erase suspend(CMD(0xB0))命令,暂停块擦除操作,使flash处理就绪状态。
之所以需要有erase suspend,是因为UBI有后台进程ubi_bgt0d,此进程功能是对flash块进行垃圾回收、磨损均衡、torture check等,当用户访问flash时,为了立即响应用户,需要立即暂停后台进程的操作,避免因为后台进程长时间占用flash而导致用户请求得不到及时响应的情况。
下发了erase suspend命令后,如果timeo时间内(这里是1s),flash还没有进入就绪状态,则说明flash出现问题,后面所有的flash命令操作都开始失败。flash的就绪检查由chip_ready实现,其实现原理是:同一个地址读两次,如果值相同,则说明flash已就绪。问题出现后,flash出错地址读出的字节的确一直在0x28和0x6c间跳变,无法稳定下来。
case FL_ERASING: if (!cfip || !(cfip->EraseSuspend & (0x1|0x2)) || !(mode == FL_READY || mode == FL_POINT || (mode == FL_WRITING && (cfip->EraseSuspend & 0x2)))) goto sleep; /* We could check to see if we're trying to access the sector * that is currently being erased. However, no user will try * anything like that so we just wait for the timeout. */ /* Erase suspend */ /* It's harmless to issue the Erase-Suspend and Erase-Resume * commands when the erase algorithm isn't in progress. */ map_write(map, CMD(0xB0), chip->in_progress_block_addr); chip->oldstate = FL_ERASING; chip->state = FL_ERASE_SUSPENDING; chip->erase_suspended = 1; for (;;) { if (chip_ready(map, adr)) break; if (time_after(jiffies, timeo)) { /* Should have suspended the erase by now. * Send an Erase-Resume command as either * there was an error (so leave the erase * routine to recover from it) or we trying to * use the erase-in-progress sector. */ put_chip(map, chip, adr); printk(KERN_ERR "MTD %s(): chip not ready after erase suspend\n", __func__); return -EIO; } mutex_unlock(&chip->mutex); cfi_udelay(1); mutex_lock(&chip->mutex); /* Nobody will touch it while it's in state FL_ERASE_SUSPENDING. So we can just loop here. */ } chip->state = FL_READY; return 0;
参照上面的故障定位脑图,排除一些不适用此故障的排查点,我们的故障排查顺序和结果如下:

修复方案及补丁提交
修改方案也很简单,就是针对S29GL01GT/S29GL512T,在Erase Resume命令下发后,延时500μs。
具体实现可查看此补丁提交链接。
--EOF--

 浙公网安备 33010602011771号
浙公网安备 33010602011771号