
第一次个人编程作业
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/CSGrade22-34/ |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/CSGrade22-34/homework/13229 |
| 这个作业的目标 | 开发自己的第一个项目,熟悉软件开发流程 |
一、Github连接
源代码链接:https://github.com/vvvvv19/vvvvv19/tree/master/3122004754
release链接:https://github.com/vvvvv19/vvvvv19/releases/tag/homework2v1.0.0
二、PSP表格
| PSP2.1 | Personal Software ProcessStages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 40 | 30 |
| Estimate | 估计这个任务需要多少时间 | 5 | 5 |
| Development | 开发 | 150 | 180 |
| Analysis | 需求分析(包括学习新技术) | 60 | 40 |
| Design Spec | 生成设计文档 | 30 | 50 |
| Design Review | 设计复审 | 20 | 15 |
| Coding Standard | 代码规范(为目前的开发制定合适的规范) | 10 | 15 |
| Design | 具体设计 | 80 | 60 |
| Coding | 具体编码 | 100 | 150 |
| Code Review | 代码复审 | 15 | 10 |
| Test | 测试(自我测试,修改代码,提交修改) | 40 | 30 |
| Reporting | 报告 | 80 | 60 |
| Test Repor | 测试报告 | 60 | 40 |
| Size Measurement | 计算工作量 | 5 | 5 |
| Postmortem & Process Improvement Plan | 事后总结,并提出过程改进计划 | 20 | 20 |
| 合计 | 715 | 710 |
三、计算模块接口设计与实现过程
1、引用的库函数
(1)sys;(2)jieba;(3)string;(4)sklearn
2、模块接口
(1)rw_file.py:读写文件
read_file:读取原文件和待查重文件的内容,并转化为字符串
write_file:输出查重结果,结果保留两位小数
(2)preprocess_text.py:文本预处理
preprocess_text:去除标点符号,分词,去除停用词,最后返回空格分隔的词汇字符串
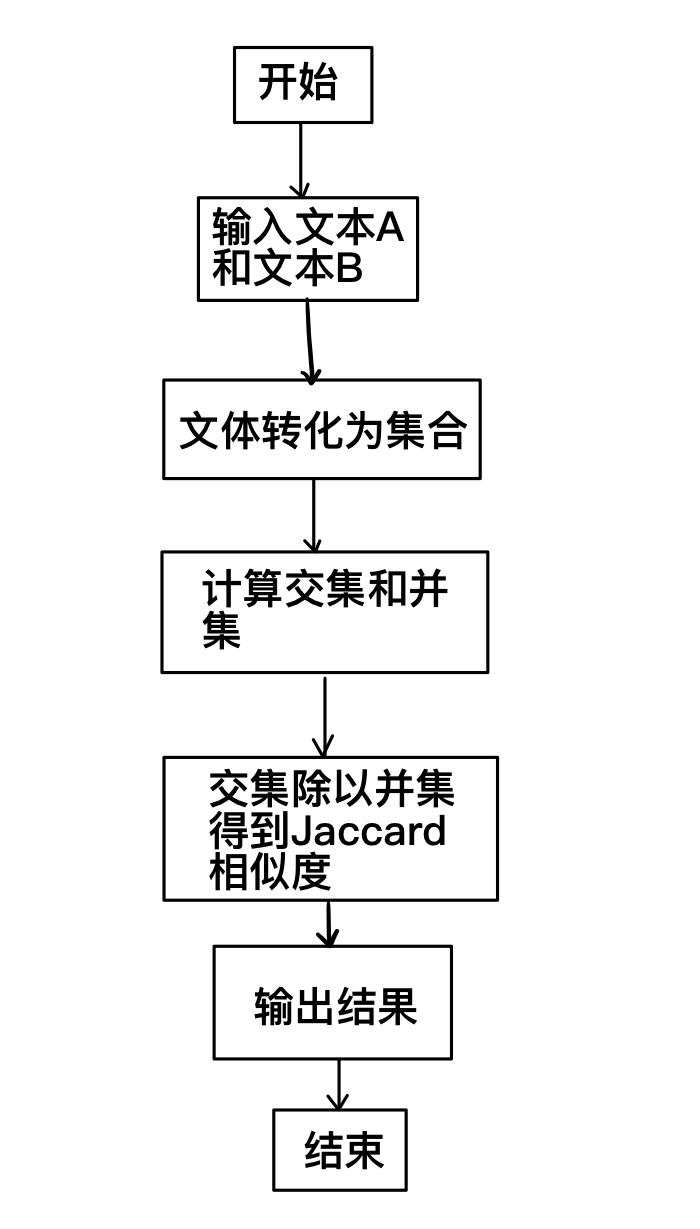
(3)calculate_jaccard_similarity.py:计算两个文本的jaccard相似度
calculate_jaccard_similarity:
首先从处理好的文本中提取出所有的单词,
并将这些单词存储在两个集合set1、set2中,
计算两个集合的交集和并集,
计算交集除以并集得出jaccard相似度
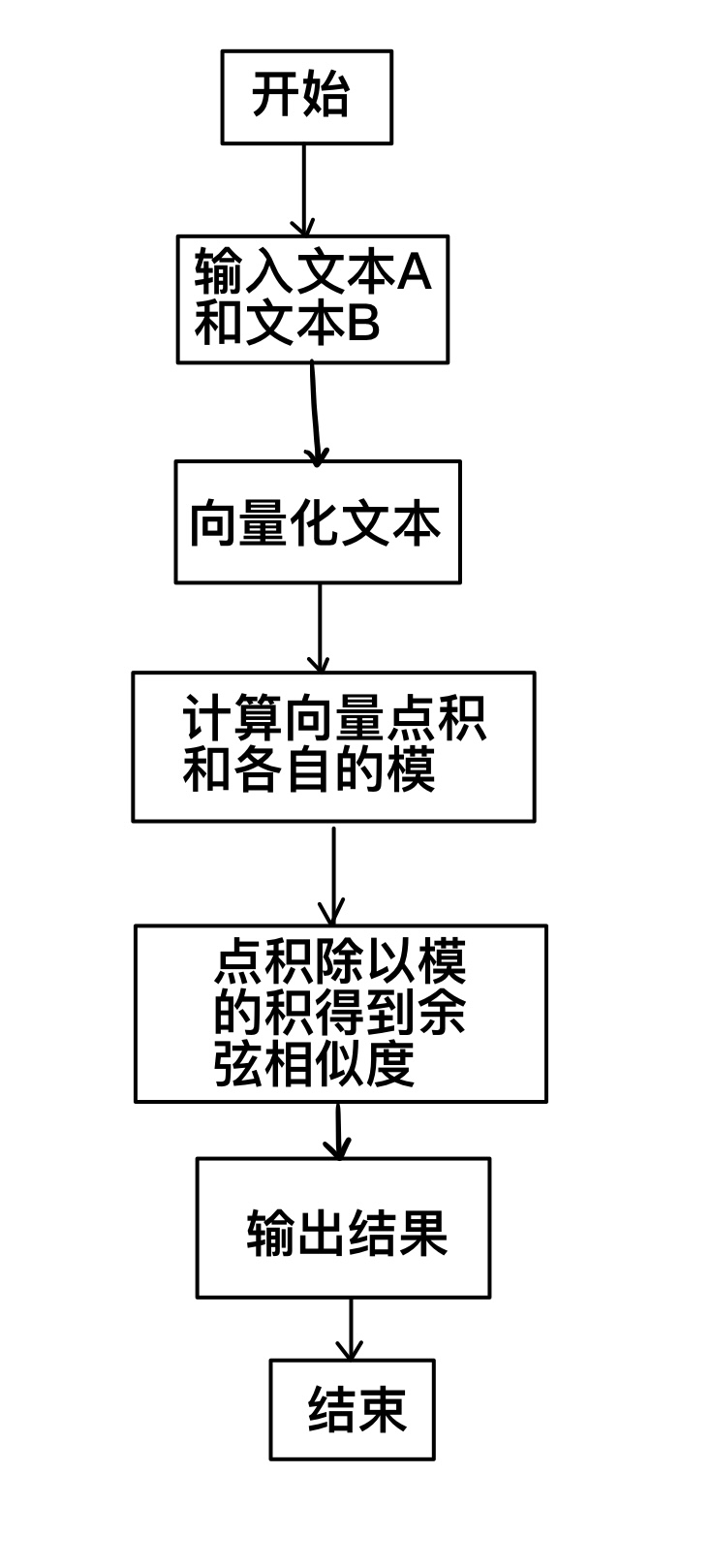
(4)calculate_cosine_similarity.py:计算两个文本的余弦相似度
calculate_cosine_similarity:
先将文本转化成TD-IDF矩阵
接受两个矩阵作为输入
计算两个文本之间的余弦相似度值
输出[0][0] 提取相似值
(5)main.py:主函数
输入文本文件后,读取文件内容
文本预处理,转化为特定的字符串
特定方法计算相似度
3、核心算法
jaccard相似度算法:
余弦相似度算法:
独到之处:
使用加权方法,结合两个相似度算法得到更加精确的查重率。
三、性能分析
1.消除所有的警告
通过PyCharm的Inspect Code代码静态审查功检测出语法错误和警告,可以把错误和警告等全部清除。
2.性能改进
在pycharm编译器中,利用line_profiler插件和line_profiler来检测每一个函数每一段代码所用的时间,已便于改进性能。
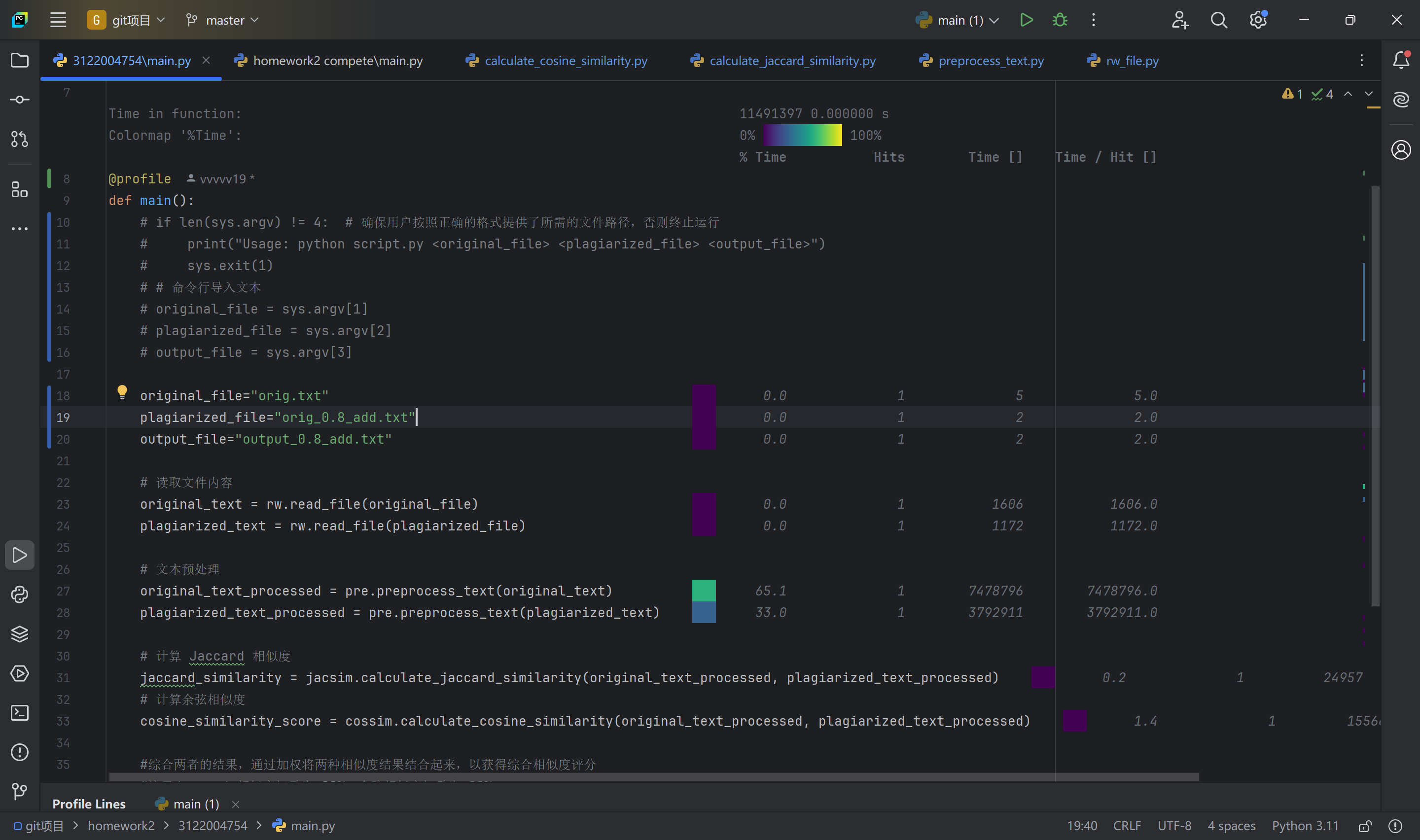
如上图所示,可以看到在main函数中,预处理模块所占用的时间是最多的,总共占了98.1%,占用时间为1。12705850s,所以要改进性能应该在文本预处理中改进代码。
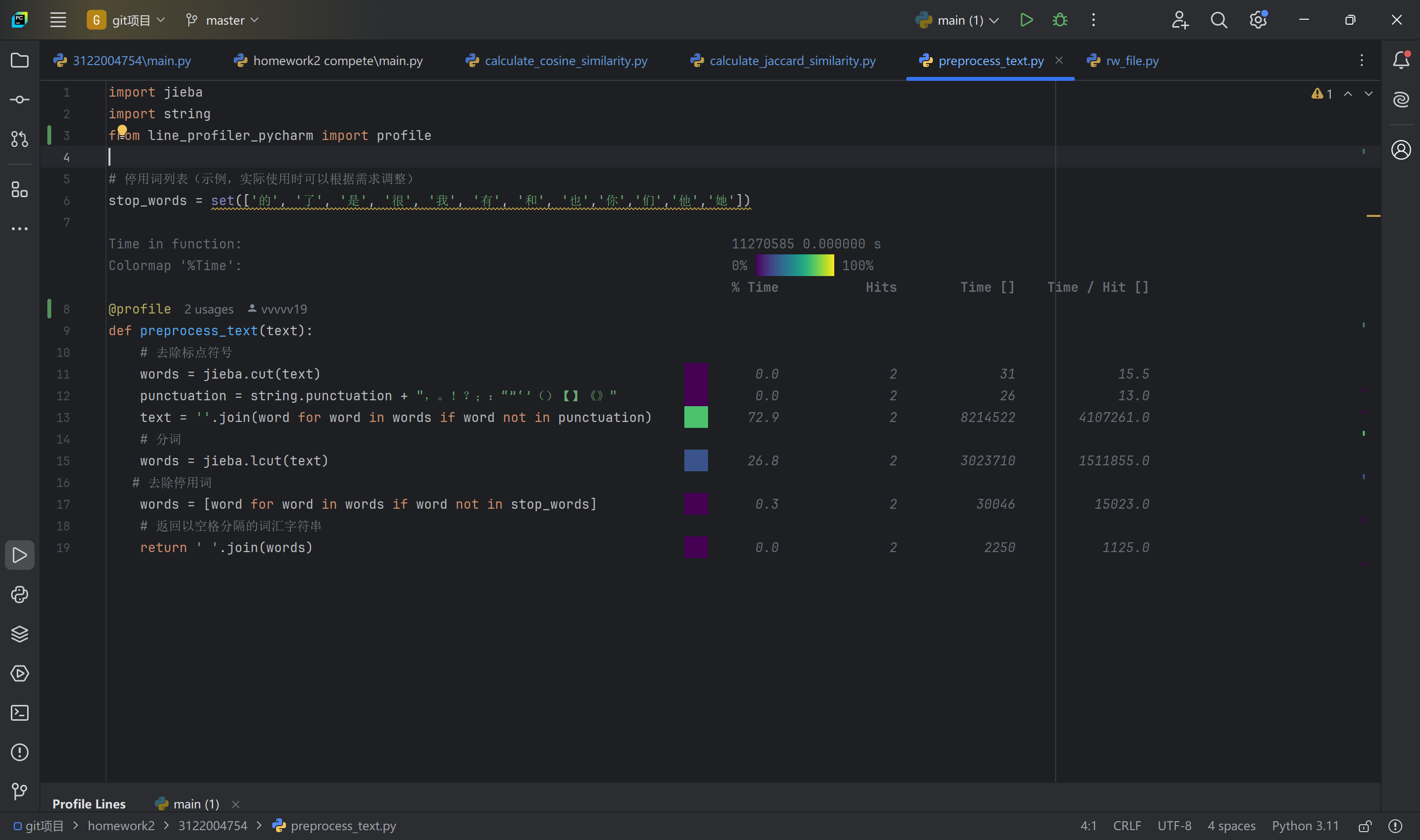
如上图所示,可以看到在preprocess_text函数中语句text = ''.join(word for word in words if word not in punctuation)和words = jieba.lcut(text)占用时间最多。
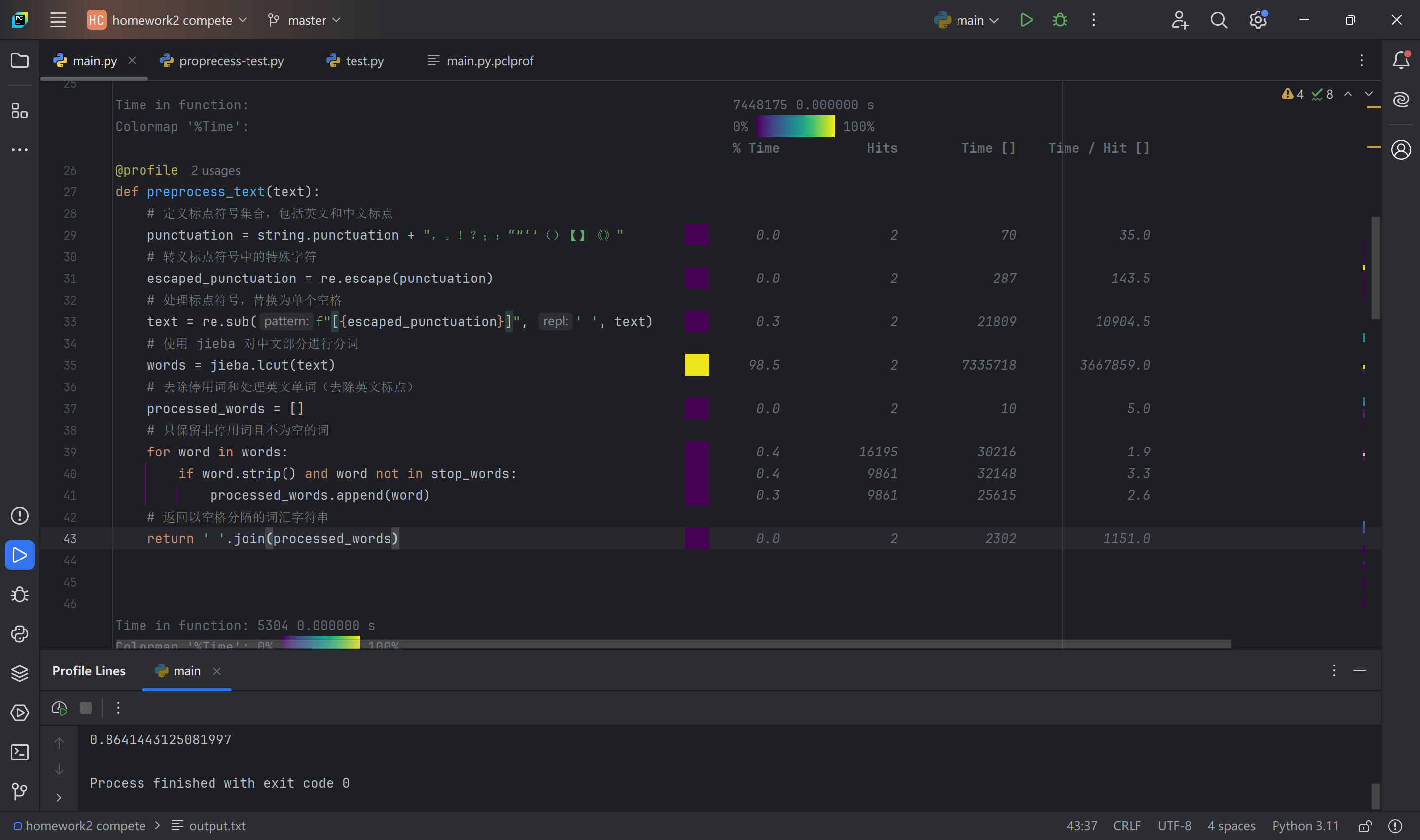
改进措施:改进preprocess_text函数,把去除停用词和标点符号,再对改进后的代码做一次性能测试,可以看到改进后时间缩短到了0.74481750s
四、单元测试
1、文件读取模块rw_file单元测试
1、代码:
import unittest
import rw_file as rw
import os
class TestRWFile(unittest.TestCase):
def setUp(self):
self.test_input_file = 'test_input.txt'
self.test_output_file = 'test_output.txt'
# Create a test input file with known content
with open(self.test_input_file, 'w', encoding='utf-8') as f:
f.write("This is a test.")
def test_read_file(self):
# Test reading from the file
content = rw.read_file(self.test_input_file)
self.assertEqual(content, "This is a test.")
def test_write_result(self):
# Test writing to the file
rw.write_result(self.test_output_file, 0.85)
with open(self.test_output_file, 'r', encoding='utf-8') as f:
content = f.read()
self.assertEqual(content, "0.85\n")
def tearDown(self):
# Clean up files after tests
if os.path.isfile(self.test_input_file):
os.remove(self.test_input_file)
if os.path.isfile(self.test_output_file):
os.remove(self.test_output_file)
if __name__ == '__main__':
unittest.main()
2、测试结果:
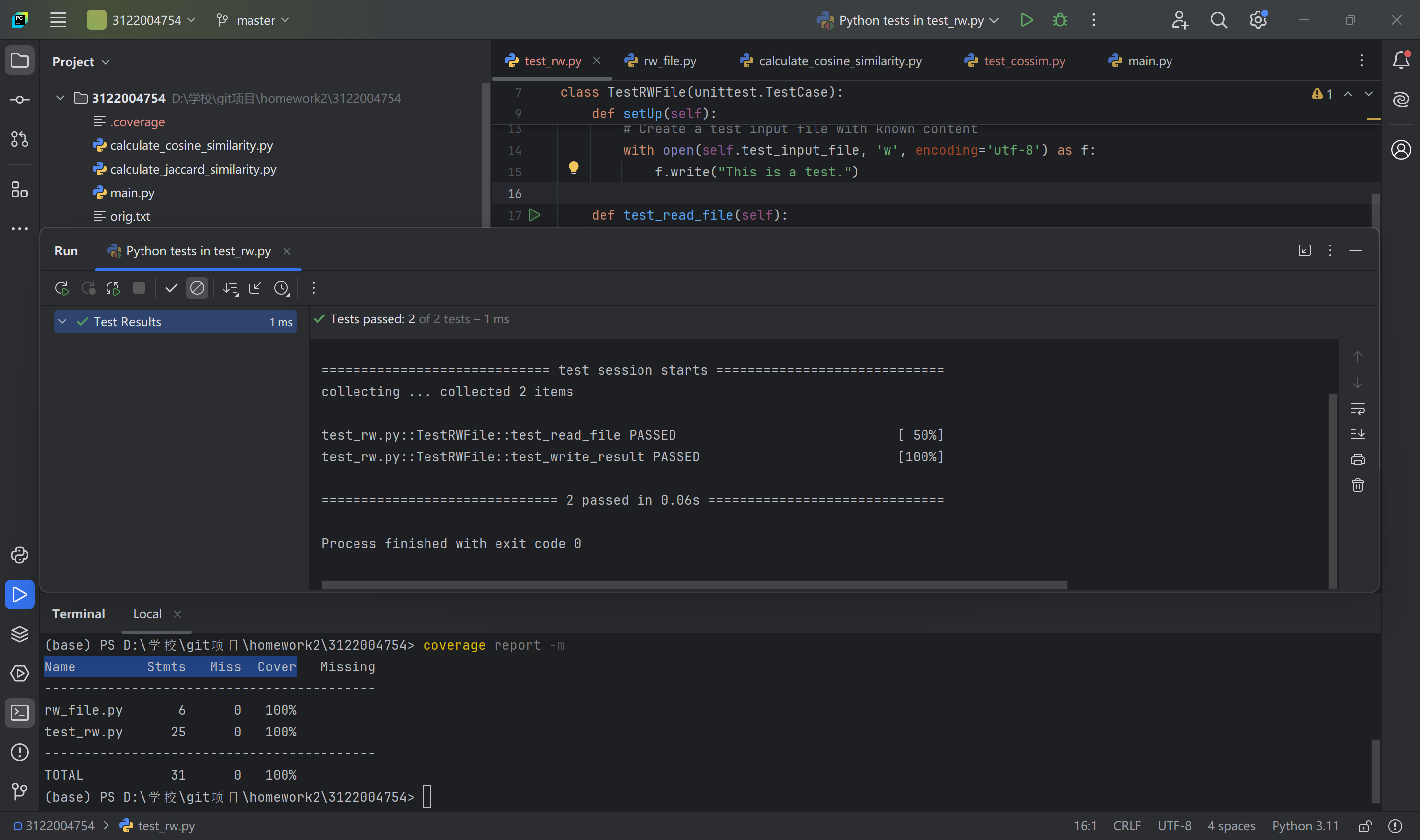
3、测试说明:
该测试程序总共测试了模块rw_file内的文件读取功能和写入功能,
对于读取功能read_file,读取文件self.test_input_file的内容应该与其内容一致,均为"This is a test.",
对于写入功能,写入self.test_output_file的内容应该一致为0.8,
如图可知,模块rw_file通过了测试,代码覆盖率为100%
2、相似度计算模块calculate_cosine_similarity和calculate_jaccard_similarity测试:
1、代码
import unittest
import calculate_cosine_similarity as cossim
import calculate_jaccard_similarity as jacsim
# 使用 unittest 框架进行单元测试
class TestCosineSimilarity(unittest.TestCase):
# 测试两个完全相同的文本
def test_identical_texts(self):
text1 = "明天的天气会很晴朗"
text2 = "明天的天气会很晴朗"
# 相似度应该接近 1
self.assertAlmostEqual(jacsim.calculate_jaccard_similarity(text1, text2), 1.0)
self.assertAlmostEqual(cossim.calculate_cosine_similarity(text1, text2), 1.0)
# 测试两个含有不同但相关的文本
def test_different_texts(self):
text1 = "明天的 天气 会很 晴朗"
text2 = "明天 会有 一个 很晴朗的 天气"
# 相似度应该大于 0,但小于 1
self.assertGreater(jacsim.calculate_jaccard_similarity(text1, text2), 0)
self.assertGreater(cossim.calculate_cosine_similarity(text1, text2), 0)
# 测试两个完全不同的文本
def test_completely_different_texts(self):
text1 = "苹果 是 水果"
text2 = "电影 是 娱乐"
# 相似度应该接近 0
self.assertAlmostEqual(jacsim.calculate_jaccard_similarity(text1, text2), 0.0)
self.assertAlmostEqual(cossim.calculate_cosine_similarity(text1, text2), 0.0)
if __name__ == "__main__":
# 运行测试
unittest.main()
2、测试结果:
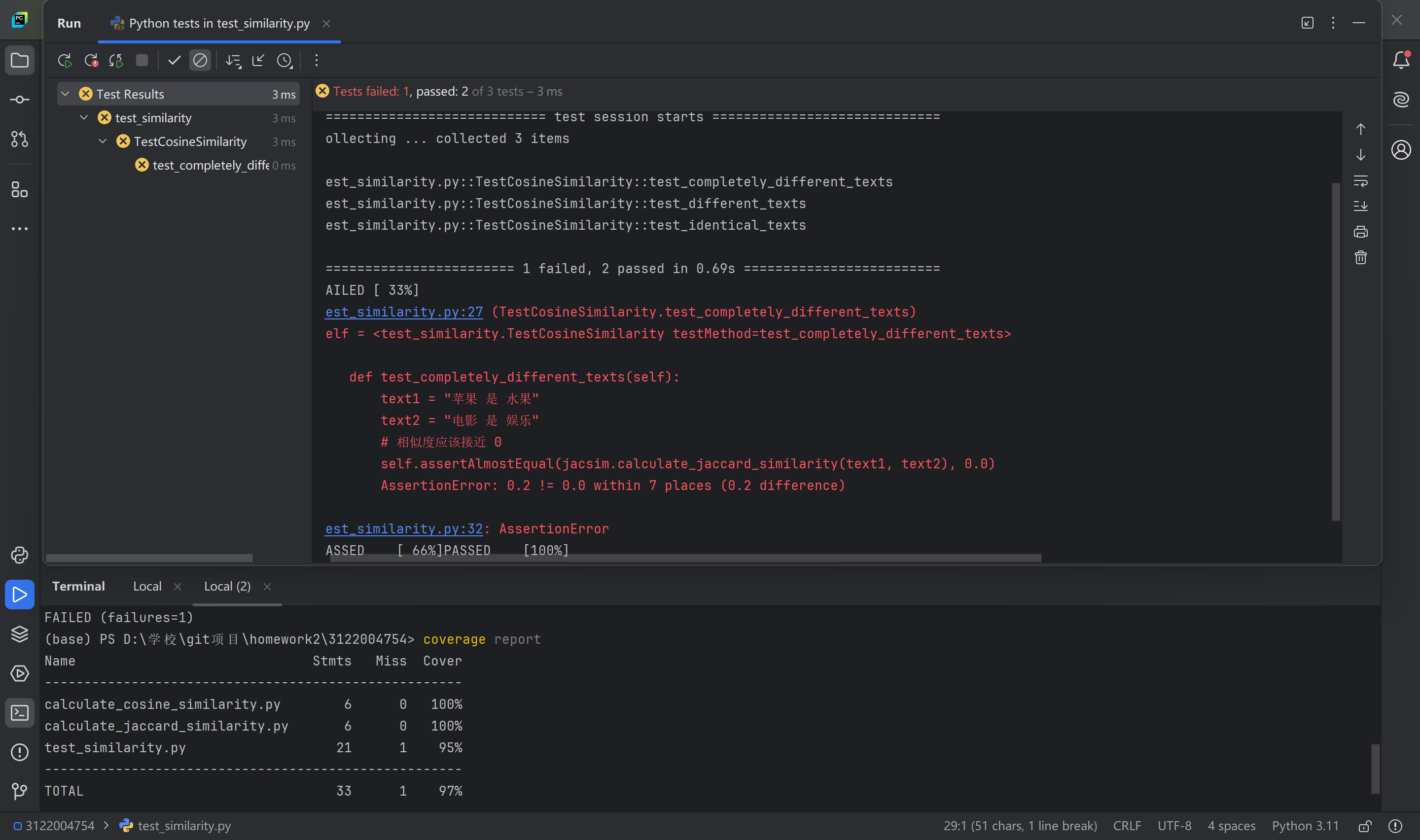
3、测试说明:
该测试测试时jaccard相似度和余弦相似度的计算方法,
测试了两个完全一样的文本、两个相关的文本和两个不同的文本三种情况下,
余弦相似度通过了测试,
jaccard相似度在两个不同的文本测试出现了错误,这是因为在Jaccard相似度计算基于词汇的交集。如果两个文本有共同的词汇,即使它们的其他部分完全不同,相似度也不会是 0,也就是说明停用词的重要性,可以去除掉文本里过分常见的词
如图所示,calculate_cosine_similarity和calculate_jaccard_similarity的代码覆盖率都达到了100%
3.文本预处理模块preprocess_text.py测试
1、代码:
import unittest
import preprocess_text as pre
class TestPreprocessText(unittest.TestCase):
def test_only_chinese(self):
text = "我喜欢学习编程。"
expected = "喜欢 学习 编程"
self.assertEqual(pre.preprocess_text(text), expected)
def test_only_english(self):
text = "I love programming."
expected = "I love programming"
self.assertEqual(pre.preprocess_text(text), expected)
def test_mixed_chinese_english(self):
text = "我喜欢 coding in Python。"
expected = "喜欢 coding in Python"
self.assertEqual(pre.preprocess_text(text), expected)
def test_punctuation(self):
text = "你好,世界!Hello, world!"
expected = "你好 世界 Hello world"
self.assertEqual(pre.preprocess_text(text), expected)
def test_stop_words(self):
text = "我很喜欢这个产品。"
expected = "喜欢 这个 产品"
self.assertEqual(pre.preprocess_text(text), expected)
def test_empty_string(self):
text = ""
expected = ""
self.assertEqual(pre.preprocess_text(text), expected)
def test_all_stop_words(self):
text = "我 和 他 是 了"
expected = ""
self.assertEqual(pre.preprocess_text(text), expected)
if __name__ == "__main__":
unittest.main()
2、测试结果:
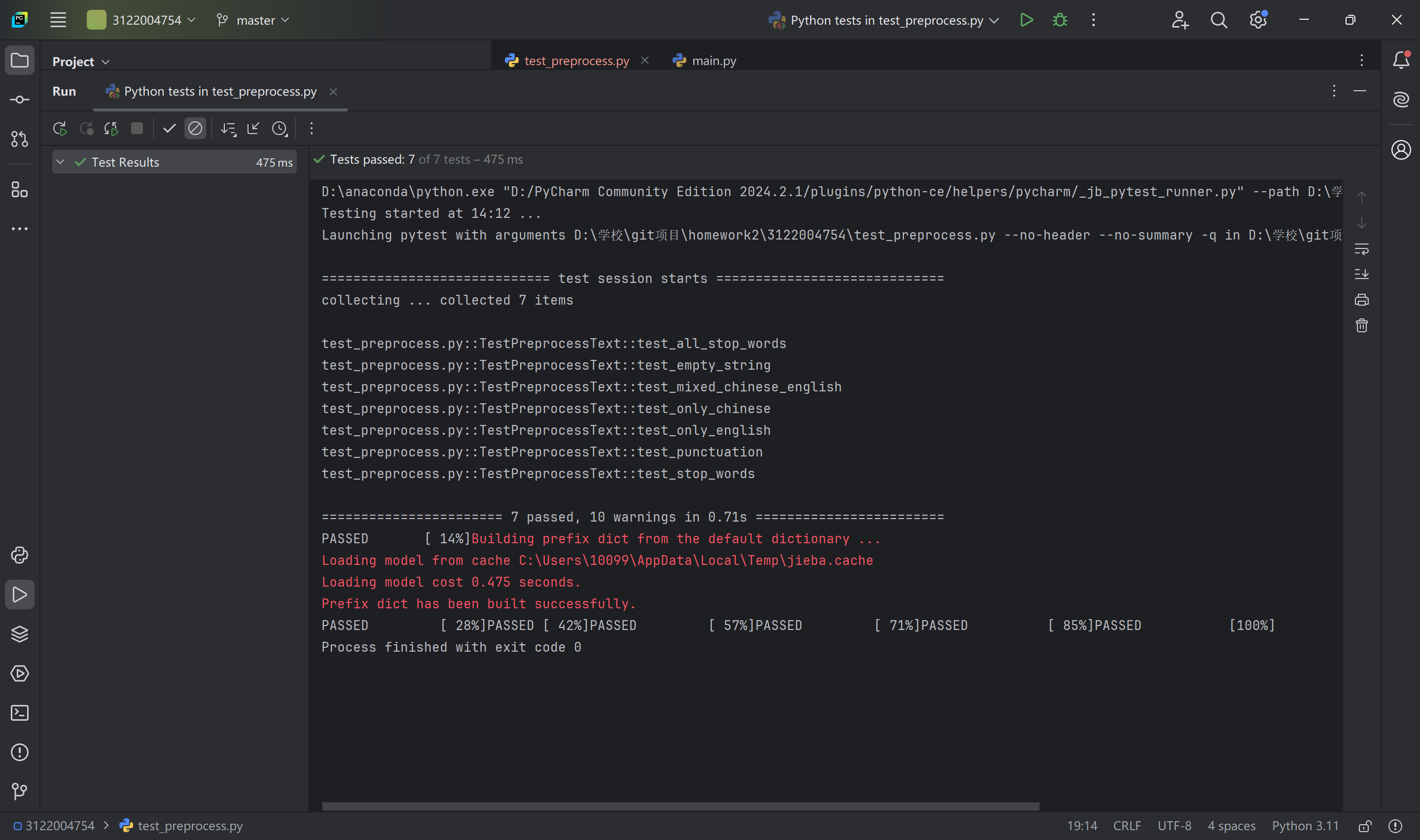
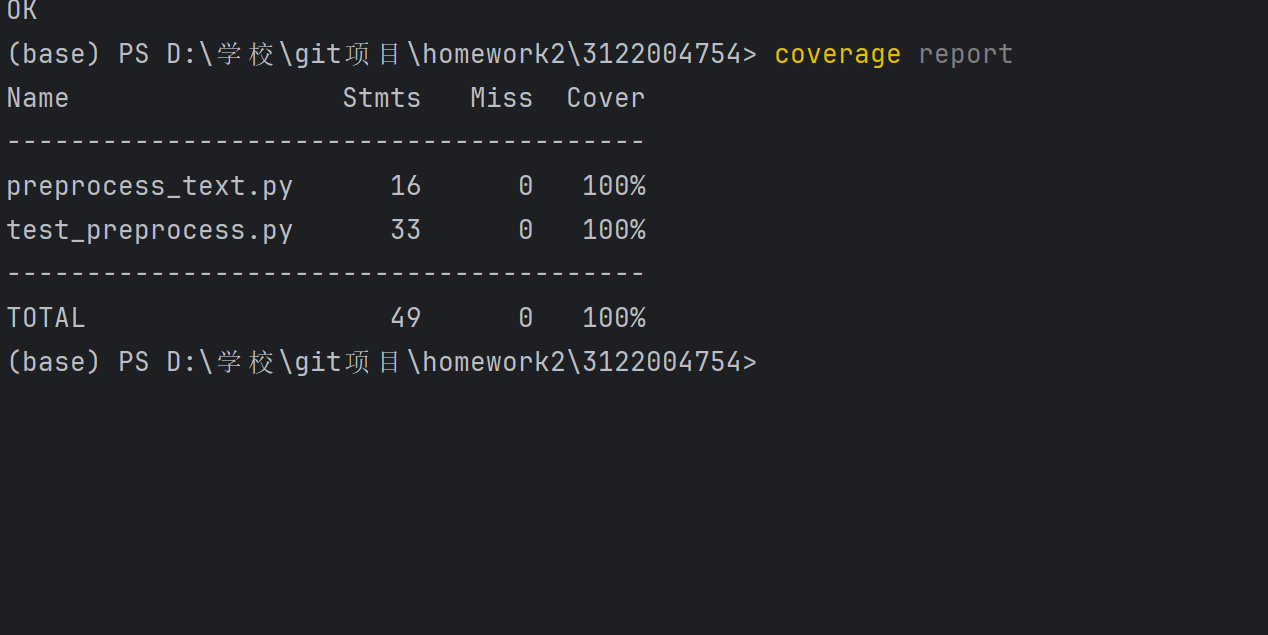
3、测试说明:
该测试程序总共测试了文本预处理模块preprocess_text处理不同文本的能力,
测试了纯中文文本的能力,
测试了纯英文文本的能力,
测试了处理中文英文混合文本的能力,
测试了处理存在停用词的文本的能力,
测试了处理存在中英文标点文本的能力,
测试了处理空文本的能力,
测试了处理纯停用词文本的能力,
如图可知,模块通过了测试,代码覆盖率为100%
4、main函数单元测试
1、代码:
import unittest
import main_for_test as main
class TestMain(unittest.TestCase):
#测试两个相同的文本
def test_identical_file(self):
text1 = "orig.txt"
text2 = "orig.txt"
text3 = "textfile.txt"
print("测试两个相同的文本:")
print(main.main(text1, text2,text3))
self.assertAlmostEqual(main.main(text1, text2,text3), 1.0)
def test_partially_similar_texts1(self):
#测试待查重文本字数少于原文本的情况
text1 = "orig.txt"
text2 = "orig_0.8_del.txt"
text3 = "textfile.txt"
print("测试待查重文本字数少于原文本的情况:")
print(main.main(text1, text2, text3))
self.assertGreater(main.main(text1, text2, text3), 0.0) # 预期相似度大于 0.0
self.assertLess(main.main(text1, text2, text3), 1.0) # 预期相似度小于 1.0
def test_partially_similar_texts2(self):
#测试待查重文本字数多于原文本的情况
text1 = "orig.txt"
text2 = "orig_0.8_add.txt"
text3 = "textfile.txt"
print("测试待查重文本字数多于原文本的情况:")
print(main.main(text1, text2, text3))
self.assertGreater(main.main(text1, text2, text3), 0.0) # 预期相似度大于 0.0
self.assertLess(main.main(text1, text2, text3), 1.0) # 预期相似度小于 1.0
def test_partially_similar_texts3(self):
#测试待查重文本不同与原文本的情况
text1 = "orig.txt"
text2 = "orig_0.8_dis_10.txt"
text3 = "textfile.txt"
print("测试待查重文本不同于原文本的情况:")
print(main.main(text1, text2, text3))
self.assertGreater(main.main(text1, text2, text3), 0.0) # 预期相似度大于 0.0
self.assertLess(main.main(text1, text2, text3), 1.0) # 预期相似度小于 1.0
def test_partially_similar_texts4(self):
#测试待查重文本远远少于原文本的情况
text1 = "orig.txt"
text2 = "orig_0.8_short.txt"
text3 = "textfile.txt"
print("测试待查重文本远远少于原文本的情况:")
print(main.main(text1, text2, text3))
self.assertGreater(main.main(text1, text2, text3), 0.0) # 预期相似度大于 0.0
self.assertLess(main.main(text1, text2, text3), 1.0) # 预期相似度小于 1.0
def test_empty_text(self):
#测试空文本
text1 = "empty.txt"
text2 = "orig.txt"
text3 = "textfile.txt"
print("测试空文本:")
print(main.main(text1, text2, text3))
self.assertEqual(main.main(text1, text2, text3), 0.0) # 预期相似度为 0.0
if __name__ == '__main__':
unittest.main()
2、测试结果:
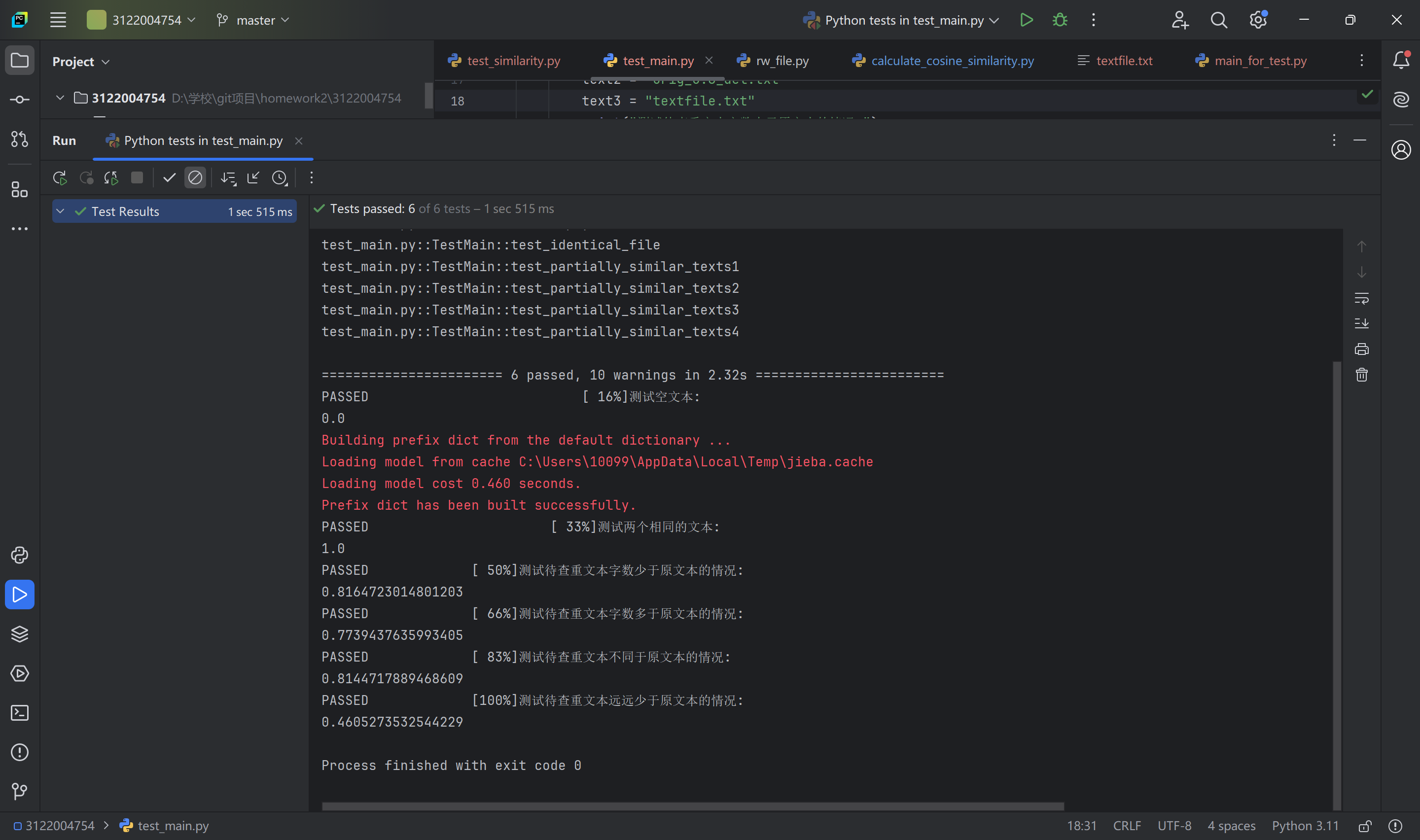
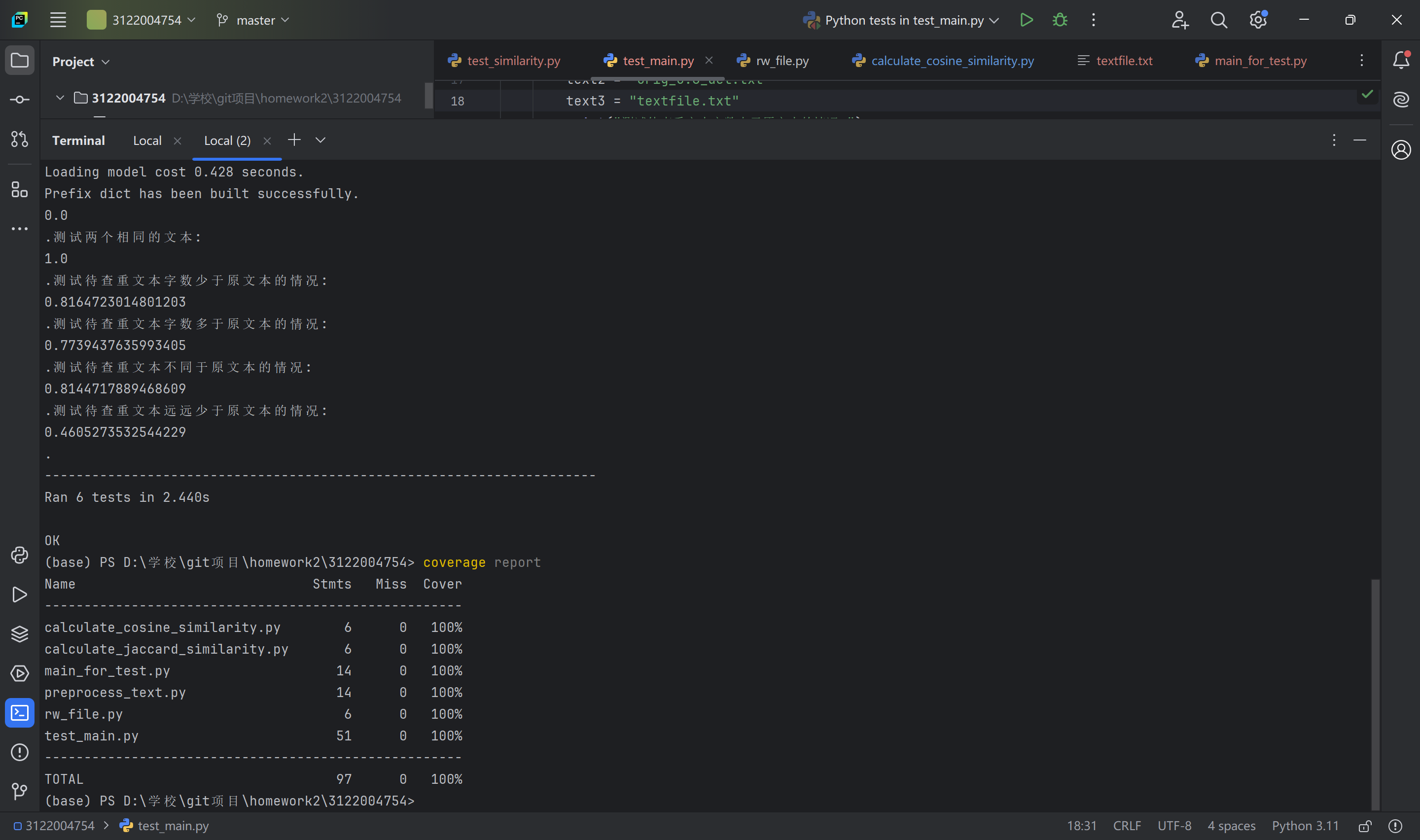
3、测试结果:
该测试程序总共测试了main函数计算不同待查重文本的能力,
测试了相同文本之间的查重率,结果为100%
测试了少一部字数和少大部分字数文本对于原文本的查重率,可以看到差异越大查重率越小,符合实际
测试了相似文本的查重率,结果符合实际
测试了空文本的查重率,结果为0
如图可知,模块通过了测试,代码覆盖率为100%
五、异常处理
1、命令行参数检查:
在 main 函数中检查了命令行参数的数量,确保用户按照正确的格式提供了文件路径。如果参数数量不对,则提示用法并终止程序。这可以避免由于参数错误导致的崩溃。
2、rw_file模块异常处理:
在读入文件时,如果要读取的文件不存在或者读取时出现错误,则终止程序。在写入文件时,如果要写入的文件不存在,则创建文件再写入;如果写入文件出现错误则终止程序。
3、计算余弦相似度异常处理:
在计算相似度时,TfidfVectorizer 和 cosine_similarity 的使用可能会遇到数据问题或内存问题,添加异常处理可以帮助捕获意外情况。
4、超时异常处理:
设置一个计时器,程序执行超过五秒的时间终止程序,可能是因为程序占用过多内存或文本量过大等,该异常处理可以监测这些情况。
5、文本预处理异常处理:
使用 try...except 语句来实现异常处理,可以处理输入类型错误、正则表达式错误、jieba分词库异常、内存问题等问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号