
ASE——第一次结对作业
ASE——第一次结对作业
问题定义
很早就听说了MSRA的黄金点游戏,让大家写Bot来参加比赛看谁的AI比较聪明可以操盘割韭菜。深感ASE课程老师设计的任务太用心了,各种接口都准备好了,大家只用专注于算法部分。方便上手然后也挺好玩(最后玩自闭了)
问题定义
黄金点游戏里所有玩家出两个数,平均值乘0.618就是这局的Golden Number,出的数字离Golden Number最近的玩家得分,最远的玩家扣分。不过每次得分等于玩家数,扣分固定是只有两分。游戏规则相当于鼓励大家骚操作,扣点分没关系重要的是怎么更好地预测出下次的黄金点,高概率的得分是制胜法宝。老师鼓励大家使用RL的方法来参加比赛,那么从RL的角度来看黄金点游戏的话:某个玩家的bot就是agent(因为不考虑bot间合作的情况),其他bot和之前的对局情况对于这个bot来说就是enviroment。很显然这个environment是相当复杂的,并且是动态变化的,agent需要不断地采集environment的信息来调整自己的policy以获得最终的胜利。
问题的难点
-
黄金点游戏的environment的描述很难
我们可以拿到数据有各个玩家当前的得分,所有玩家历史数据。怎么用这些数据有效的表示出现在的state是一个比较麻烦的问题。老师的demo里仅仅使用最近10次黄金点上升和下降的次数作为当前state的描述,可以想到加入更多的信息来表示当前state当然会更加准确,不过模型也就更难训练的较好。还有就是state有无穷多种,这里采用tabular的方法不太合适,除非强行把state给减少到有限多种(RLdemo中就是这么做的),那么就需要function approximation的办法来使得访问到的一些数据更新后能有足够的泛化能力让agent在没有见过的state也能给出不错的策略。
-
action的选择
我和同伴商量了很久也没有想好在博弈的情况下考虑什么action能获得比较好的收益,RLDemo中给出了一些例子,都是对最近的黄金点进行一定的操作。如果其他玩家采取一些扰动策略,那么对最近几轮黄金点进行操作作为下一次的输出就不合理了。由于没法得到别人的策略和action,想了很久也没有一个好的办法,所以最后还是退而求其次选取固定的一些action。
方法建模
第一版
和队友最近一直在搞RL,之前讨论的时候想了很多方案。不过由于我们俩在写这个Bot的时候都超级忙,他回去处理保研的事情,我在准备清华的九月推免。讨论的一些不错的idea最后都没有用上(难受)。交的第一个版本是一个常规的DQN,其中approximation用的是densenet。我们把最近10轮的黄金点上升、下降趋势的个数,最近三轮黄金点平均值,最近五轮黄金点平均值,以及最近十轮黄金点的3次多项式拟合的前三个参数做为表征当前状态的输入。(现在想想这个特征工程可能是败笔,也许用网络来提取特征效果更好)。关于DQN的部分的话就是常规的框架:
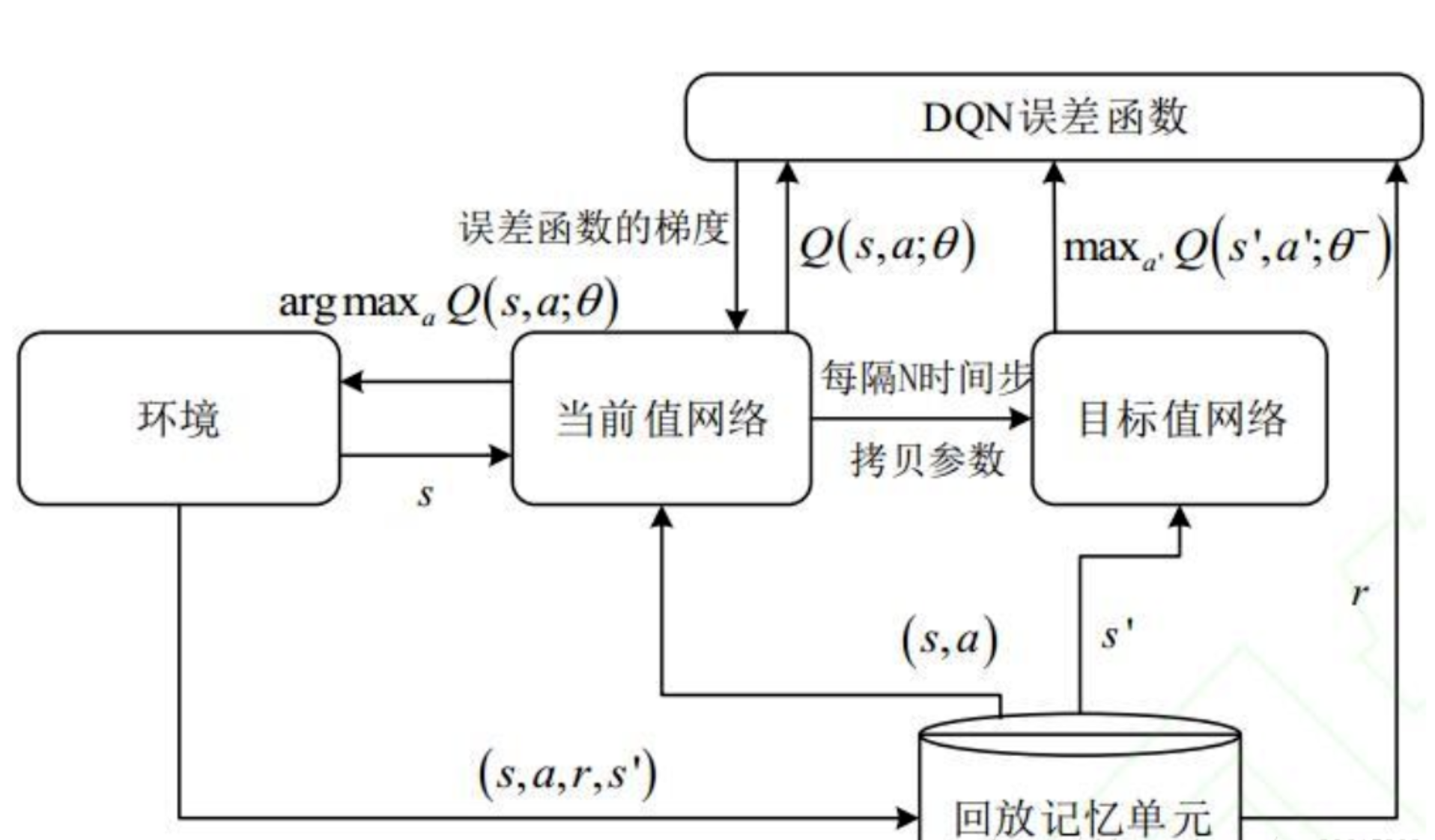
main network和target network之间有一些delay,两个网络的输出差值就是简单Q-learning的Q现实和Q估计(构成TD-error),可以调整的超参数就是更新频率和memory size。中规中矩的DQN算法:(好奇大家都用Sutton介绍的版本23333)

第二版
第一版是匆匆忙忙赶出来的,在经过第一轮测试之后我和队友开始加入一些之前讨论过的思想,由于整个游戏是well-model的,所以我们可以用别人的输入来做planning,每一轮都可以把做每个action的情况模拟出来增加训练数据。也就是说虽然DQN给出了某一个固定的action,但我们同时把DQN没有选到的action也模拟了一遍,这样就大大提高了训练速度,也可以避免一直不得分然后陷入死局的情况。
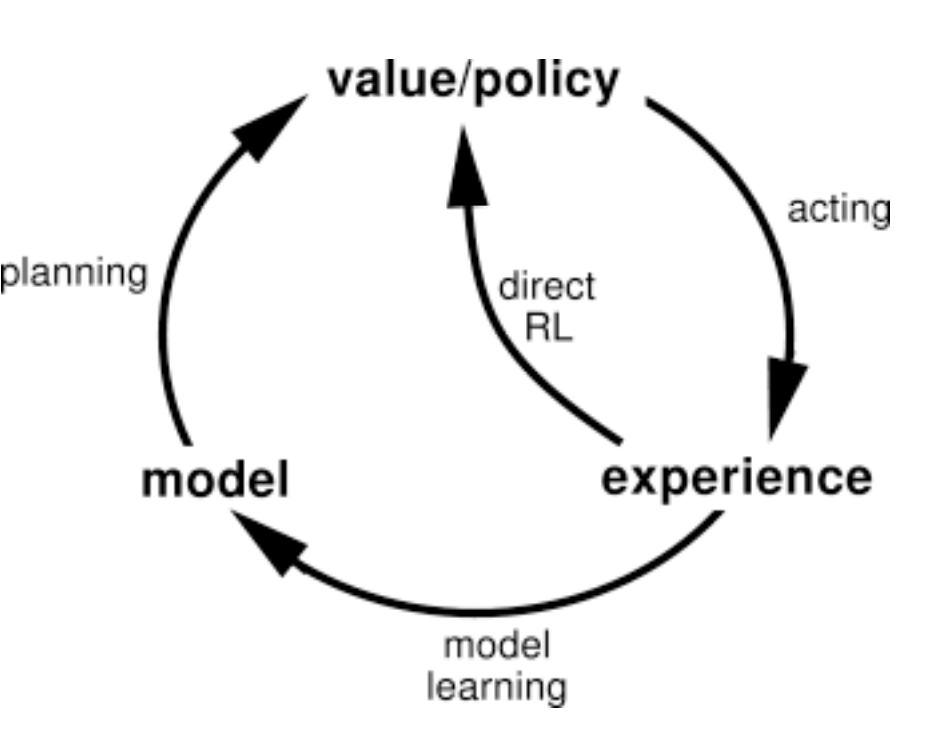
如上图所示,除了真正做了选择,action之后得到的experience来改善我们的model,我们同时还自己维护了一个黄金点平台,尝试了各种action在当前state情况下的reward。(可以看到RL里的所有game几乎都好model,毕竟不是真实问题)
结果分析
第一次完了1000轮,排名第三,但是当时是写了一个裸的DQN,虽然我们设计了一下state的representation,但是还是完全出乎意料。只能说是运气比较好。后来我们加了一些精心设计的policy和planning,第二版在交上去之前,我和前一版的10个bot以及一些tabular的demo放在一个房间里玩作对比。结果!!改过的bot并没有像我们想的那样大杀四方,而是比之前的还要烂。。。那10个简单DQN调整了一些参数,有些DQN在刚开始就表现的不错,有些DQN刚开始就表现的很烂比tabular的方法还要烂。然后我和队友比较慌,没有想到把两个模型综合一下,简单DQN交第一个数,planning版本交第二个数。本着实践是检验真理的唯一标准,把改了一点参数的第一个DQN交了上去。(不知道是不是我们被wellmodel了,开始游戏之后就表现的异常的烂,然后正常游戏被吊锤),后来我们分析了一下,由于游戏里很多bot加入了扰动因素,特别是冠军bot,日常靠大数扰动稳定得分,非常的主动。而我们开局不利,一直处于没有怎么得分的情况,而且又没有planning,只能靠着epsilon greedy的办法去试到一些能得分的action。。。相当于没有逆风翻盘的能力,所以就跪了。之后自己可以试一试把加了planning的版本以及用网络抽取特征的版本结合起来,加上扰动策略能不能稳定的solo赢一些比较菜的bot。被虐的体无完肤,太弟弟了。
问题
-
黄金点结果符合预期吗
基本符合预期把,因为加了planning的版本最后又没用上。相当于裸的DQN和大家的bot玩,比较菜也是情理之中。由于我们俩个人原因没能把设计好的一些思路用上和大家大战一场有点可惜。
-
在正式的比赛前,你们采取了怎样的策略来评价模型的好坏?
我们用写好的bot和改进的bot还有一些简单的bot开房间互相打,然后通过判断在足够轮数里正确预测黄金点的比例(不能光是排名)来判断模型的好坏。比如1w轮,如果有3000轮都得了分,而且扣分比例很低,那就是个很好的模型。
-
如果将每轮可提交的数字变成 3个,或者找更多的参赛者来参加比赛,你们的方法还适用吗?
用RL的好处就在这里啦,参赛者更多数字更多我们就比传统方法更加强,毕竟是和环境交互学习嘛。
-
请评价合作伙伴的工作,评价方式请参考书中关于三明治方法的论述。并提出结对伙伴可以改进的地方。
我的队友非常认真的对待这次比赛,我们俩也进行了很多关于策略的讨论。很可惜是由于保研推免的事情耽误了没有时间充分实现。尤其是我,在交作业ddl前一天还要去清华机试面试,对不住队友啦。不过后来我们俩合作赶紧写好了基本的DQN并且也完成了相关的测试,大赞!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号