List/Set/CurrnetHashMap
ArrayList:
List特点:元素有放入顺序,元素可重复 。
存储结构:底层采用数组来实现的。
Cloneable(此处理解有些问题,到时候需要再看下)
支持拷贝:实现Cloneable接口,重写clone方法、方法内容默认调用父类的clone方法。
2.1、浅拷贝 基础类型的变量拷贝之后是独立的,不会随着源变量变动而变 String类型拷贝之后也是独立的 引用类型拷贝的是引用地址,拷贝前后的变量引用同一个堆中的对象 public Object clone() throws CloneNotSupportedException { Study s = (Study) super.clone(); return s; }
基本类型、引用类型。 浅拷贝 基本类型(int类型)是独立的(改了值会生效),引用类型不独立的(同一份数据,string也是同样的)
2.2、深拷贝
变量的所有引用类型变量(除了String)都需要实现Cloneable(数组可以直接调用clone方法),clone方法中,引用类型需要各 自调用clone,重新赋值 public Object clone() throws CloneNotSupportedException { Study s = (Study) super.clone(); s.setScore(this.score.clone()); return s; }
java的传参,基本类型和引用类型传参
java在方法传递参数时,是将变量复制一份,然后传入方法体去执行。复制的是栈中的内容 所以基本类型是复制的变量名和值,值变了不影响源变量 引用类型复制的是变量名和值(引用地址),对象变了,会影响源变量(引用地址是一样的) String:是不可变对象,重新赋值时,会在常量表新生成字符串(如果已有,直接取他的引用地址),将新字符串的引用地址赋值给栈中的新变量,因此源变量不会受影响
LinkedList:
存储结构:底层采用链表来实现的。
HashSet(Set)
元素无放入顺序,元素不可重复(注意:元素虽然无放入顺序,但是元素在set中的位置是有该元素的HashCode决定的,其位置其实是固定的)
存储结构:
底层采用HashMap来实现
HashMap(Map):
特点:
key,value存储,key可以为null,同样的key会被覆盖掉
存储结构:
底层采用数组、链表、红黑树来实现的。
原理讲解:
哈希算法(也叫散列),就是把任意长度值(Key)通过散列算法变换成固定长度的key(地址)通过这个地址进行访问的数据结构它通过把关键码值映射到表中一个。位置来访问记录,以加快查找的速度
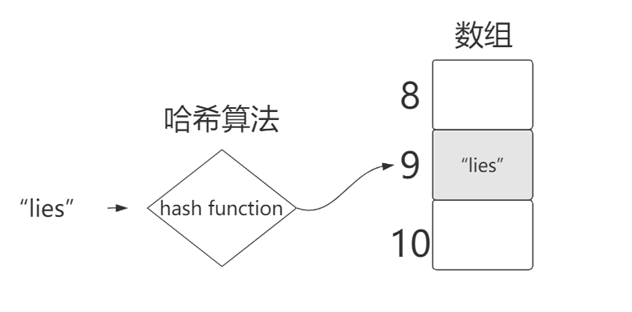
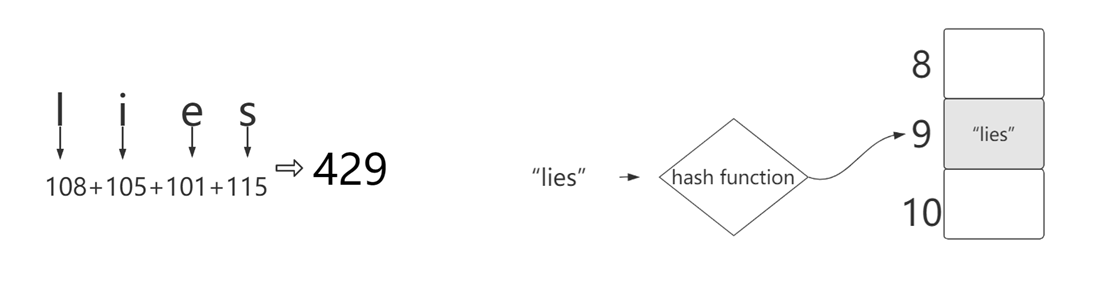
Hashcode:通过字符串算出它的ascii码,进行mod(取模),算出哈希表中的下标
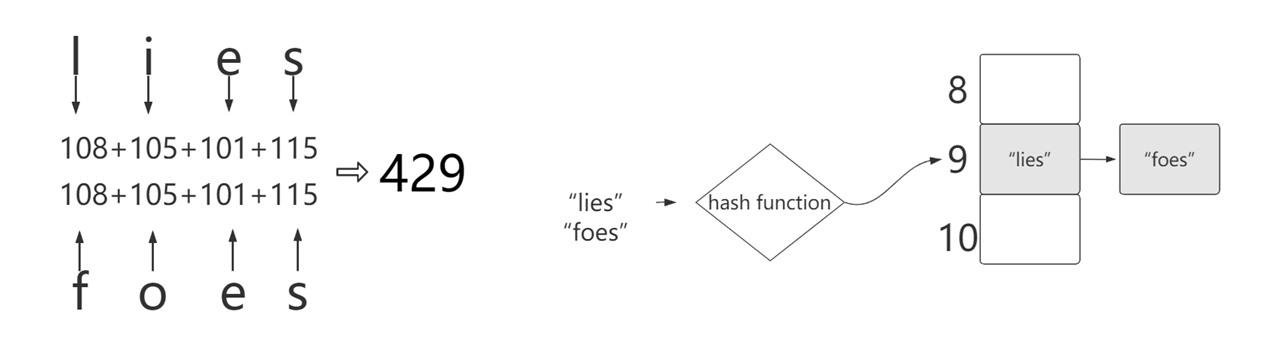
用链表是来解决数组下标会覆盖的问题,冲突的问题。为什么hashmap 用两个数据结构。两个数据结构。JDK8 红黑树???
因为链表查询的时候链表过长了查询效率非常低,所以需要用红黑树
当链表长度大于8的时候,链表转换为红黑树;当节点少于6的时候,红黑树转换为链表结构
源码分析:
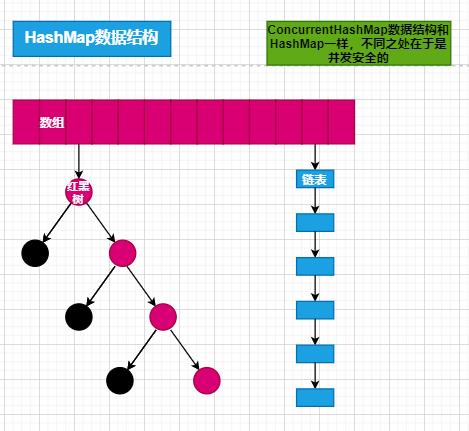
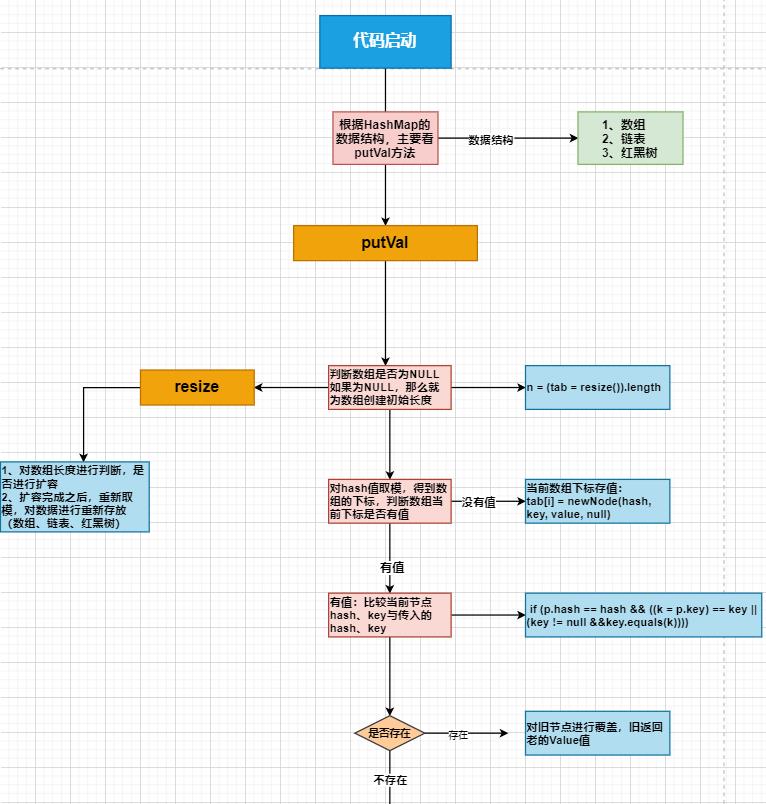
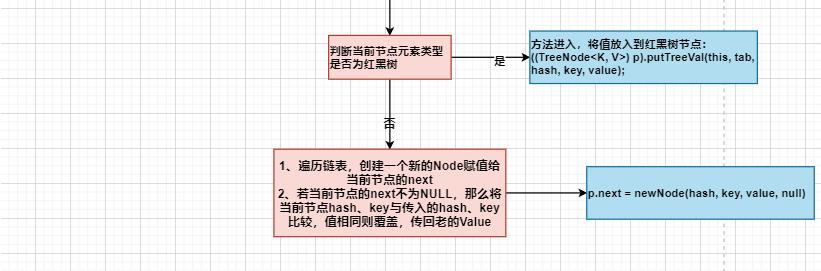
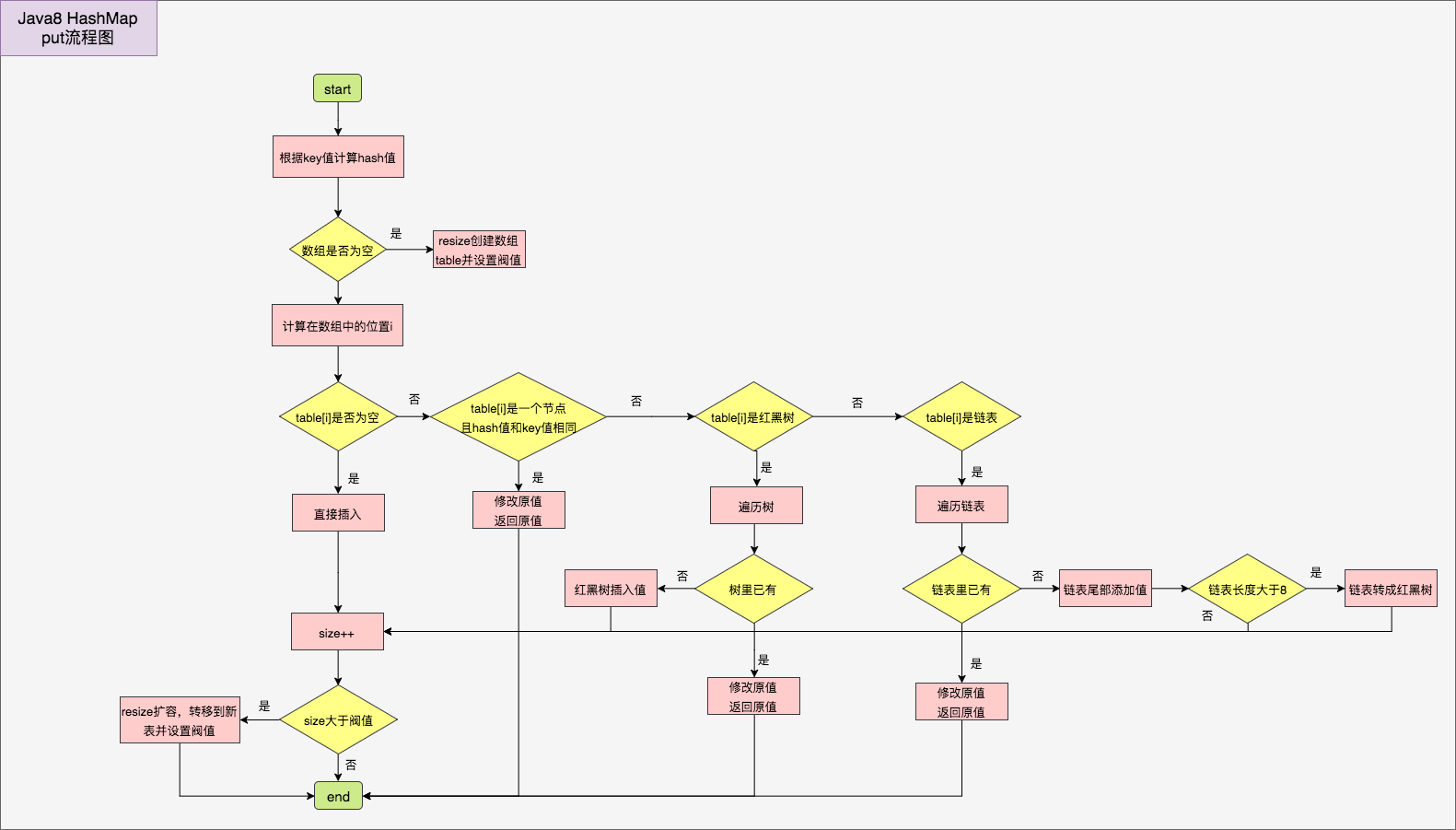
ConcurrentHashMap(并发安全map):
特点:
并发安全的HashMap ,比Hashtable效率更高
存储结构:
底层采用数组、链表、红黑树 内部大量采用CAS操作。并发控制使⽤synchronized 和 CAS 来操作来实现的。
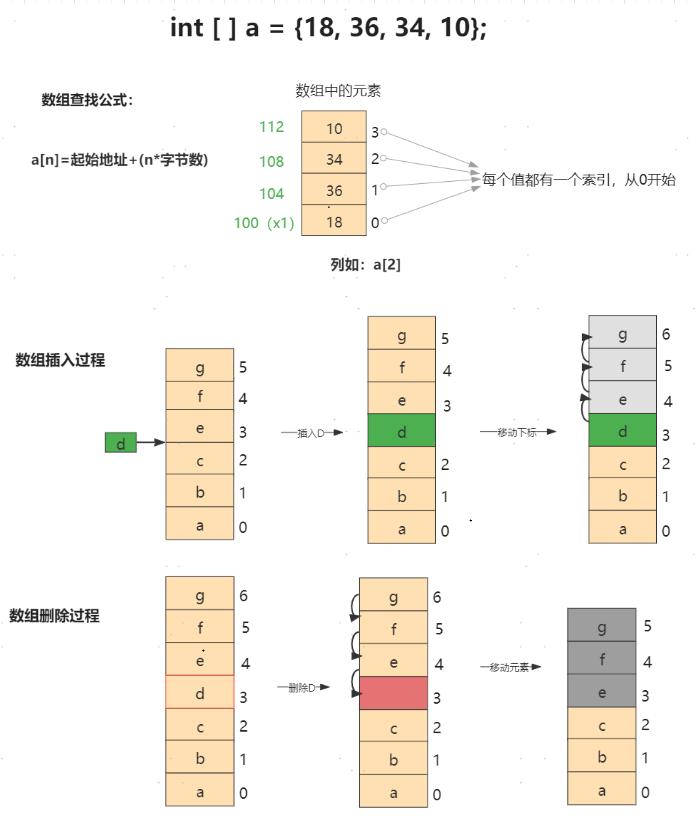
下图解释为何List查询效率高,插入、删除效率低

 浙公网安备 33010602011771号
浙公网安备 33010602011771号