阿里巴巴Arthas详解
Arthas 官方文档十分详细,详见:https://alibaba.github.io/arthas
Arthas使用场景
得益于 Arthas 强大且丰富的功能,让 Arthas 能做的事情超乎想象。下面仅仅列举几项常见的使用情况,更多的使用场景可以在熟悉了 Arthas 之后自行探索。
是否有一个全局视角来查看系统的运行状况?
为什么 CPU 又升高了,到底是哪里占用了 CPU ?
运行的多线程有死锁吗?有阻塞吗?
程序运行耗时很长,是哪里耗时比较长呢?如何监测呢?
这个类从哪个 jar 包加载的?为什么会报各种类相关的 Exception?
我改的代码为什么没有执行到?难道是我没 commit?分支搞错了?
遇到问题无法在线上 debug,难道只能通过加日志再重新发布吗?
有什么办法可以监控到 JVM 的实时运行状态?
Arthas使用
# github下载arthas 2 wget https://alibaba.github.io/arthas/arthas‐boot.jar 3 # 或者 Gitee 下载 4 wget https://arthas.gitee.io/arthas‐boot.jar
用java -jar运行即可,可以识别机器上所有Java进程(我们这里之前已经运行了一个Arthas测试程序,代码见下方)

package com.tuling.jvm; import java.util.HashSet; public class Arthas { private static HashSet hashSet = new HashSet(); public static void main(String[] args) { // 模拟 CPU 过高 cpuHigh(); // 模拟线程死锁 deadThread(); // 不断的向 hashSet 集合增加数据 addHashSetThread(); } /** * 不断的向 hashSet 集合添加数据 */ public static void addHashSetThread() { // 初始化常量 new Thread(() -> { int count = 0; while (true) { try { hashSet.add("count" + count); Thread.sleep(1000); count++; } catch (InterruptedException e) { e.printStackTrace(); } } }).start(); } public static void cpuHigh() { new Thread(() -> { while (true) { } }).start(); } /** * 死锁 */ private static void deadThread() { /** 创建资源 */ Object resourceA = new Object(); Object resourceB = new Object(); // 创建线程 Thread threadA = new Thread(() -> { synchronized (resourceA) { System.out.println(Thread.currentThread() + " get ResourceA"); try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(Thread.currentThread() + "waiting get resourceB"); synchronized (resourceB) { System.out.println(Thread.currentThread() + " get resourceB"); } } }); Thread threadB = new Thread(() -> { synchronized (resourceB) { System.out.println(Thread.currentThread() + " get ResourceB"); try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(Thread.currentThread() + "waiting get resourceA"); synchronized (resourceA) { System.out.println(Thread.currentThread() + " get resourceA"); } } }); threadA.start(); threadB.start(); } }
选择进程序号1,进入进程信息操作
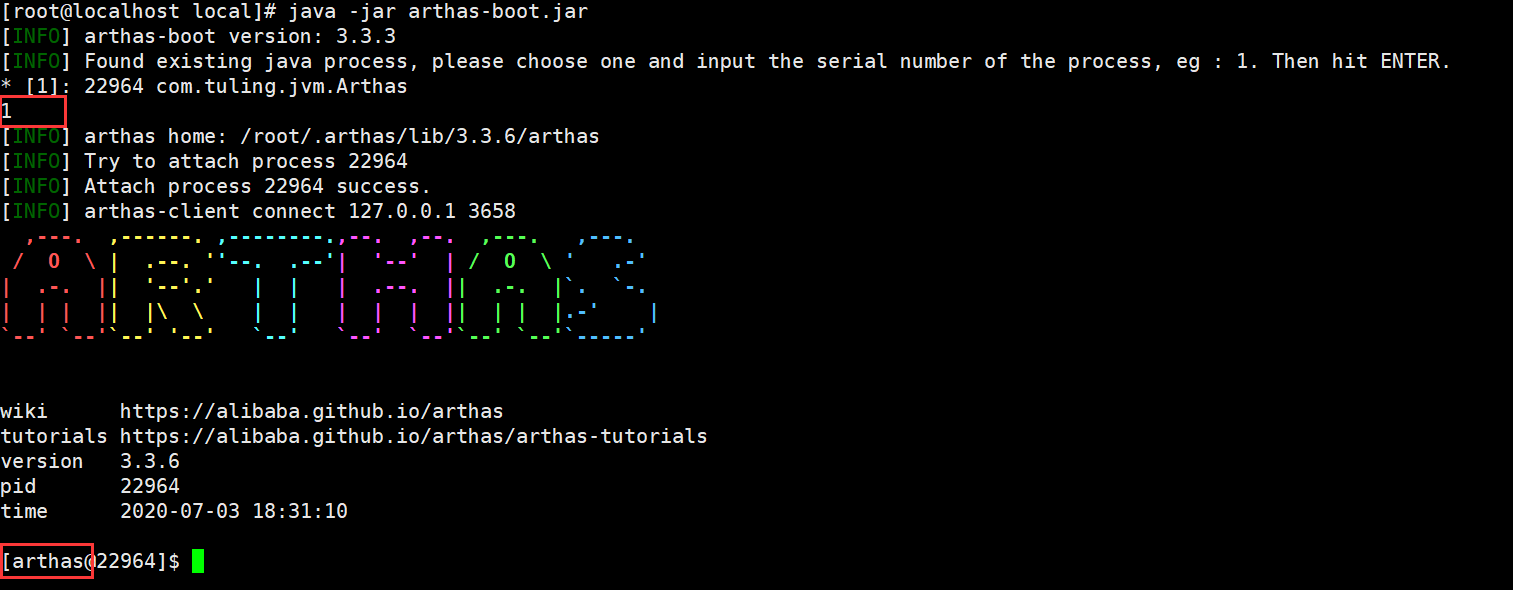
输入dashboard可以查看整个进程的运行情况,线程、内存、GC、运行环境信息:
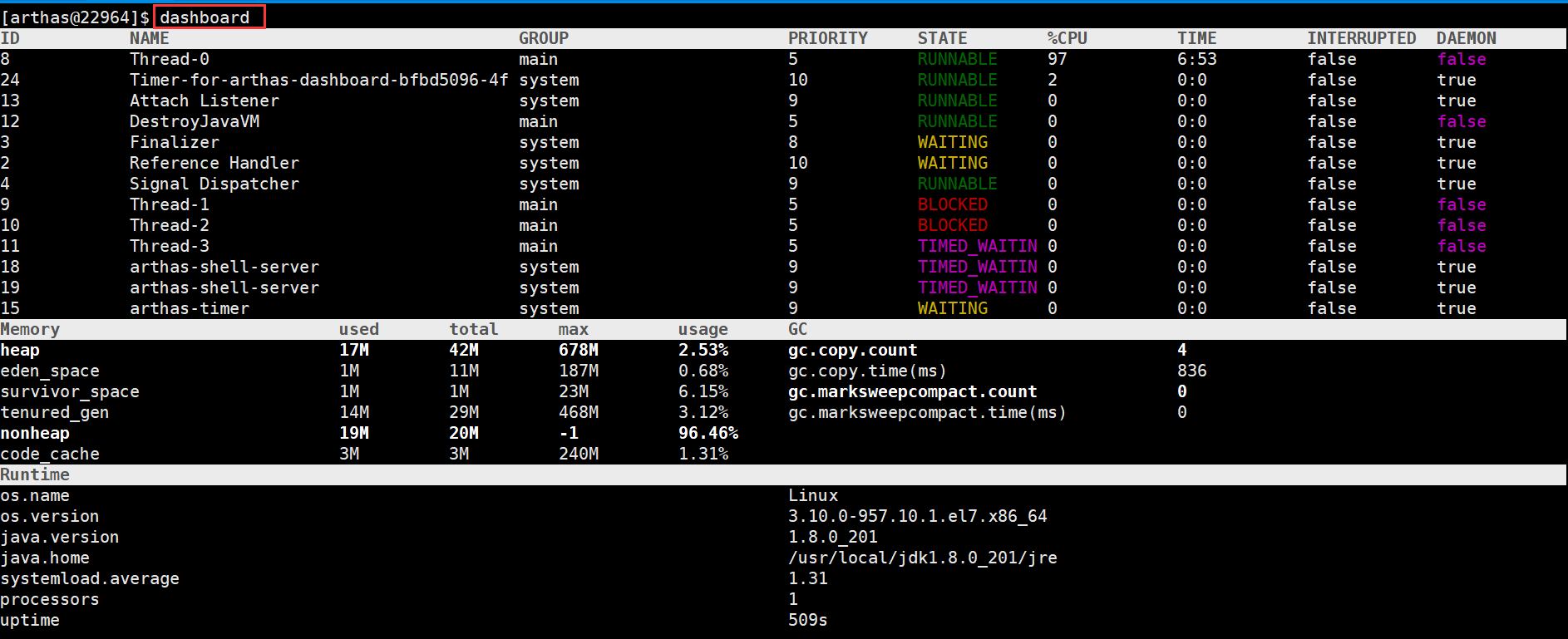
输入thread可以查看线程详细情况
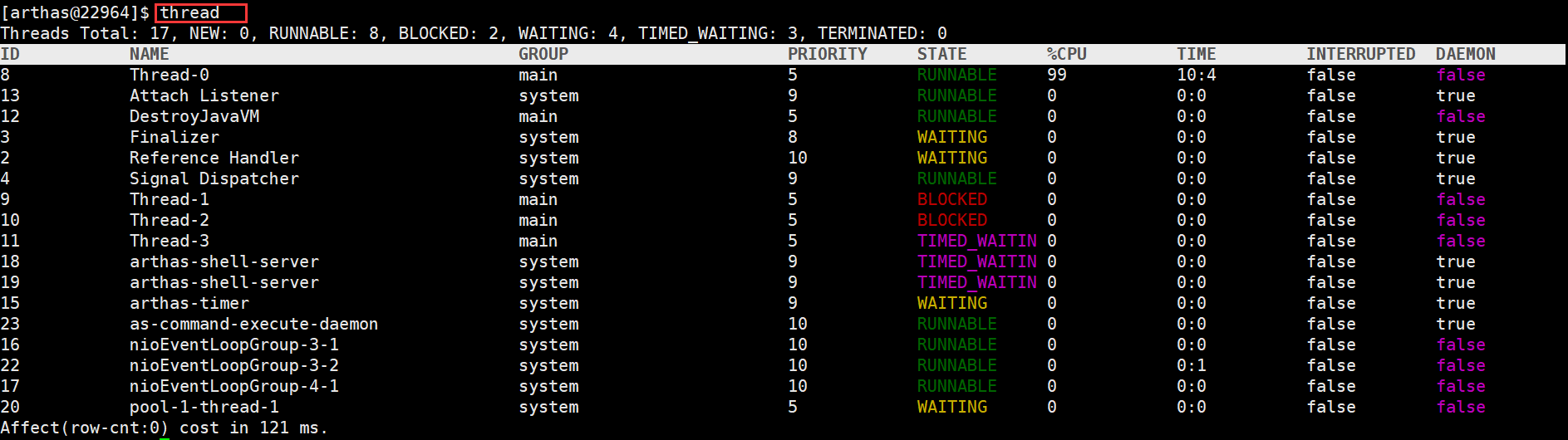
输入 thread加上线程ID 可以查看线程堆栈

输入 thread -b 可以查看线程死锁

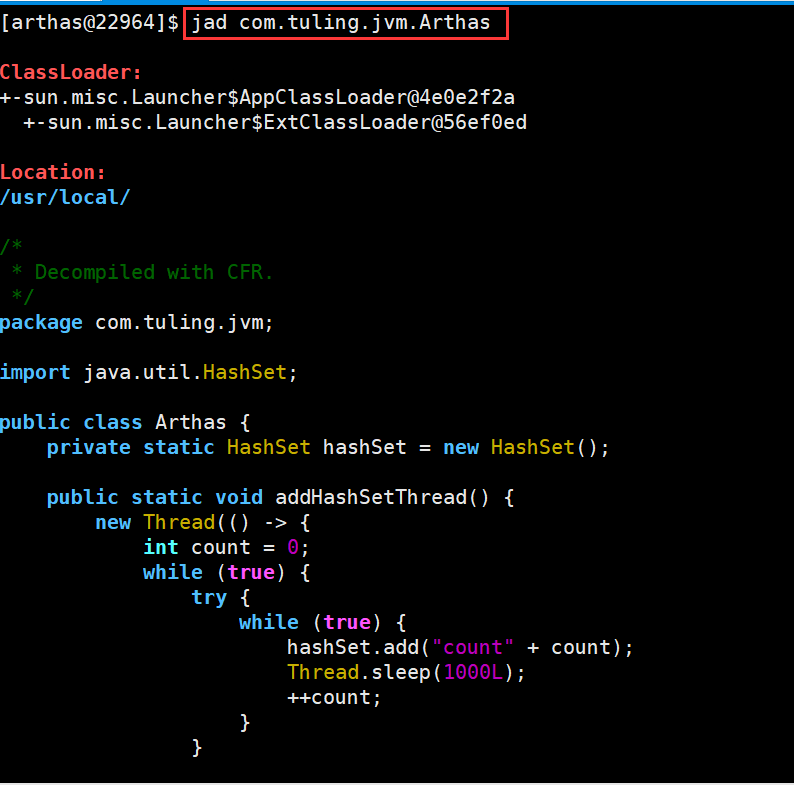
输入 jad加类的全名 可以反编译,这样可以方便我们查看线上代码是否是正确的版本
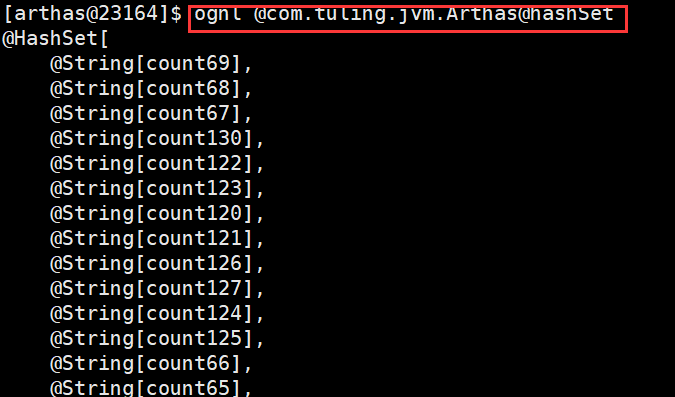
使用 ognl 命令可以
更多命令使用可以用help命令查看,或查看文档:https://alibaba.github.io/arthas/commands.html#arthas
String常量池问题的几个例子
String s0="zhuge"; String s1="zhuge"; String s2="zhu" + "ge"; System.out.println( s0==s1 ); //true System.out.println( s0==s2 ); //true
分析:因为例子中的 s0和s1中的”zhuge”都是字符串常量,它们在编译期就被确定了,所以s0==s1为true;而”zhu”和”ge”也都是字符串常量,当一个字 符串由多个字符串常量连接而成时,它自己肯定也是字符串常
量,所以s2也同样在编译期就被优化为一个字符串常量"zhuge",所以s2也是常量池中” zhuge”的一个引用。所以我们得出s0==s1==s2;
String s0="zhuge"; String s1=new String("zhuge"); String s2="zhu" + new String("ge"); System.out.println( s0==s1 ); // false System.out.println( s0==s2 ); // false System.out.println( s1==s2 ); // false
分析:用new String() 创建的字符串不是常量,不能在编译期就确定,所以new String() 创建的字符串不放入常量池中,它们有自己的地址空间。 s0还是常量池 中"zhuge”的引用,s1因为无法在编译期确定,所以是运行时创建的新对象”zhuge”的引用,s2因为有后半部分 new String(”ge”)所以也无法在编译期确定,所以也是一个新创建对象”zhuge”的引用;
明白了这些也就知道为何得出此结果了。
String a = "a1"; String b = "a" + 1; System.out.println(a == b); // true String a = "atrue"; String b = "a" + "true"; System.out.println(a == b); // true String a = "a3.4"; String b = "a" + 3.4; System.out.println(a == b); // true
分析:JVM对于字符串常量的"+"号连接,将在程序编译期,JVM就将常量字符串的"+"连接优化为连接后的值,拿"a" + 1来说,经编译器优化后在class中就已经是a1。在编译期其字符串常量的值就确定下来,故上面程
序最终的结果都为true。
String a = "ab"; String bb = "b"; String b = "a" + bb; System.out.println(a == b); // false
分析:JVM对于字符串引用,由于在字符串的"+"连接中,有字符串引用存在,而引用的值在程序编译期是无法确定的,即"a" + bb无法被编译器优化,只有在程序运行期来动态分配并将连接后的新地址赋给b。所以上面
程序的结果也就为false。
String a = "ab"; final String bb = "b"; String b = "a" + bb; System.out.println(a == b); // true
分析:和示例4中唯一不同的是bb字符串加了final修饰,对于final修饰的变量,它在编译时被解析为常量值的一个本地拷贝存储到自己的常量池中或嵌入到它的字节码流中。所以此时的"a" + bb和"a" + "b"效果是
一样的。故上面程序的结果为true
String a = "ab"; final String bb = getBB(); String b = "a" + bb; System.out.println(a == b); // false private static String getBB() { return "b"; }
分析:JVM对于字符串引用bb,它的值在编译期无法确定,只有在程序运行期调用方法后,将方法的返回值和"a"来动态连接并分配地址为b,故上面 程序的结果为false。
关于String是不可变的
String s = "a" + "b" + "c"; //就等价于String s = "abc"; String a = "a"; String b = "b"; String c = "c"; String s1 = a + b + c;
s1 这个就不一样了,可以通过观察其JVM指令码发现s1的"+"操作会变成如下操作:
StringBuilder temp = new StringBuilder(); temp.append(a).append(b).append(c); String s = temp.toString();
最后再看一个例子: //字符串常量池:"计算机"和"技术" 堆内存:str1引用的对象"计算机技术" //堆内存中还有个StringBuilder的对象,但是会被gc回收,StringBuilder的toString方法会new String(),这个String才是真正返回的对象引用 String str2 = new StringBuilder("计算机").append("技术").toString(); //没有出现"计算机技术"字面量,所以不会在常量池里生成"计算机技术"对象 System.out.println(str2 == str2.intern()); //true //"计算机技术" 在池中没有,但是在heap中存在,则intern时,会直接返回该heap中的引用 //字符串常量池:"ja"和"va" 堆内存:str1引用的对象"java" //堆内存中还有个StringBuilder的对象,但是会被gc回收,StringBuilder的toString方法会new String(),这个String才是真正返回的对象引用 String str1 = new StringBuilder("ja").append("va").toString(); //没有出现"java"字面量,所以不会在常量池里生成"java"对象 System.out.println(str1 == str1.intern()); //false //java是关键字,在JVM初始化的相关类里肯定早就放进字符串常量池了 String s1=new String("test"); System.out.println(s1==s1.intern()); //false //"test"作为字面量,放入了池中,而new时s1指向的是heap中新生成的string对象,s1.intern()指向的是"test"字面量之前在池中生成的字符串对象 String s2=new StringBuilder("abc").toString(); System.out.println(s2==s2.intern()); //false //同上

 浙公网安备 33010602011771号
浙公网安备 33010602011771号