数据建模
1、案例:设计一个用户document数据类型,其中包含一个地址数据的数组,这种设计方式相对复杂,但是在管理数据时,更加的灵活(推荐nest方式建模)。
PUT /user_index { "mappings": { "properties": { "login_name" : { "type" : "keyword" }, "age " : { "type" : "short" }, "address" : { "properties": { "province" : { "type" : "keyword" }, "city" : { "type" : "keyword" }, "street" : { "type" : "keyword" } } } } } }
但是上述的数据建模有其明显的缺陷,就是针对地址数据做数据搜索的时候,经常会搜索出不必要的数据,如:在下述数据环境中,搜索一个province为北京,city为天津的用户。
PUT /user_index/_doc/1 { "login_name" : "jack", "age" : 25, "address" : [ { "province" : "北京", "city" : "北京", "street" : "枫林三路" }, { "province" : "天津", "city" : "天津", "street" : "华夏路" } ] } PUT /user_index/_doc/2 { "login_name" : "rose", "age" : 21, "address" : [ { "province" : "河北", "city" : "廊坊", "street" : "燕郊经济开发区" }, { "province" : "天津", "city" : "天津", "street" : "华夏路" } ] }
执行的搜索应该如下:
GET /user_index/_search { "query": { "bool": { "must": [ { "match": { "address.province": "北京" } }, { "match": { "address.city": "天津" } } ] } } }
但是得到的结果并不准确,这个时候就需要使用nested object来定义数据建模。
2、nested object
使用nested object作为地址数组的集体类型,可以解决上述问题,document模型如下:
PUT /user_index { "mappings": { "properties": { "login_name" : { "type" : "keyword" }, "age" : { "type" : "short" }, "address" : { "type": "nested", "properties": { "province" : { "type" : "keyword" }, "city" : { "type" : "keyword" }, "street" : { "type" : "keyword" } } } } } }
这个时候就需要使用nested对应的搜索语法来执行搜索了,语法如下:
GET /user_index/_search { "query": { "bool": { "must": [ { "nested": { "path": "address", "query": { "bool": { "must": [ { "match": { "address.province": "北京" } }, { "match": { "address.city": "天津" } } ] } } } } ] } } }
虽然语法变的复杂了,但是在数据的读写操作上都不会有错误发生,是推荐的设计方式。
其原因是:
普通的数组数据在ES中会被扁平化处理,处理方式如下:(如果字段需要分词,会将分词数据保存在对应的字段位置,当然应该是一个倒排索引,这里只是一个直观的案例)
{ "login_name" : "jack", "address.province" : [ "北京", "天津" ], "address.city" : [ "北京", "天津" ] "address.street" : [ "枫林三路", "华夏路" ] }
那么nested object数据类型ES在保存的时候不会有扁平化处理,保存方式如下:所以在搜索的时候一定会有需要的搜索结果。
{ "login_name" : "jack" } { "address.province" : "北京", "address.city" : "北京", "address.street" : "枫林三路" } { "address.province" : "天津", "address.city" : "天津", "address.street" : "华夏路", }
三、父子关系数据建模
nested object的建模,有个不好的地方,就是采取的是类似冗余数据的方式,将多个数据都放在一起了,维护成本就比较高 每次更新,需要重新索引整个对象(包括跟对象和嵌套对象) ES 提供了类似关系型数据库中 Join 的实现。使用 Join 数据类型实现,可以通过 Parent / Child 的关系,从而分离两个对象 父文档和子文档是两个独立的文档 更新父文档无需重新索引整个子文档。子文档被新增,更改和删除也不会影响到父文档和其他子文档。 要点:父子关系元数据映射,用于确保查询时候的高性能,但是有一个限制,就是父子数据必须存在于一个shard中 父子关系数据存在一个shard中,而且还有映射其关联关系的元数据,那么搜索父子关系数据的时候,不用跨分片,一个分片本地自己就搞定了,性能当然高
父子关系
定义父子关系的几个步骤
设置索引的 Mapping
索引父文档
索引子文档
按需查询文档
设置 Mapping

DELETE my_blogs # 设定 Parent/Child Mapping PUT my_blogs { "mappings": { "properties": { "blog_comments_relation": { "type": "join", "relations": { "blog": "comment" } }, "content": { "type": "text" }, "title": { "type": "keyword" } } } }
索引父文档
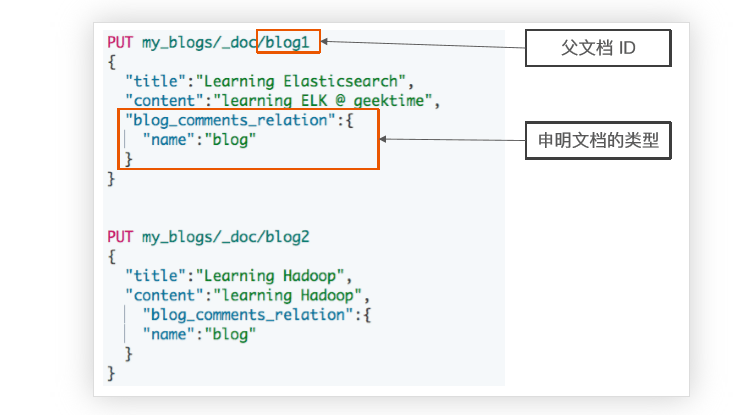
PUT my_blogs/_doc/blog1 { "title":"Learning Elasticsearch", "content":"learning ELK is happy", "blog_comments_relation":{ "name":"blog" } } PUT my_blogs/_doc/blog2 { "title":"Learning Hadoop", "content":"learning Hadoop", "blog_comments_relation":{ "name":"blog" } }
索引子文档
父文档和子文档必须存在相同的分片上
确保查询 join 的性能
当指定文档时候,必须指定它的父文档 ID
使用 route 参数来保证,分配到相同的分片
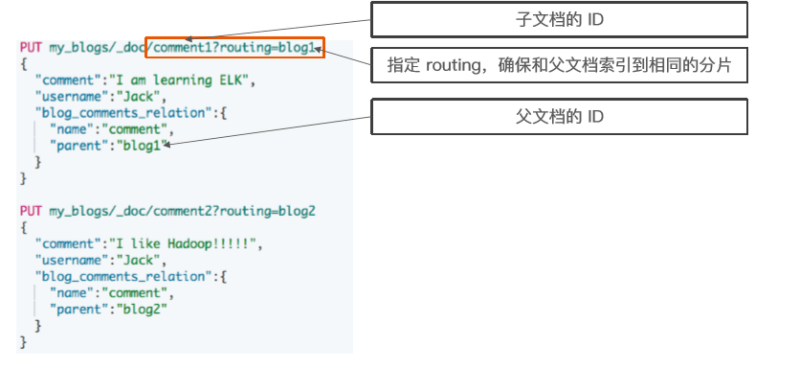
#索引子文档
PUT my_blogs/_doc/comment1?routing=blog1 { "comment":"I am learning ELK", "username":"Jack", "blog_comments_relation":{ "name":"comment", "parent":"blog1" } } PUT my_blogs/_doc/comment2?routing=blog2 { "comment":"I like Hadoop!!!!!", "username":"Jack", "blog_comments_relation":{ "name":"comment", "parent":"blog2" } } PUT my_blogs/_doc/comment3?routing=blog2 { "comment":"Hello Hadoop", "username":"Bob", "blog_comments_relation":{ "name":"comment", "parent":"blog2" } }
Parent / Child 所支持的查询
查询所有文档
Parent Id 查询
Has Child 查询
Has Parent 查询
# 查询所有文档 POST my_blogs/_search {} #根据父文档ID查看 GET my_blogs/_doc/blog2 # Parent Id 查询 POST my_blogs/_search { "query": { "parent_id": { "type": "comment", "id": "blog2" } } } # Has Child 查询,返回父文档 POST my_blogs/_search { "query": { "has_child": { "type": "comment", "query" : { "match": { "username" : "Jack" } } } } } # Has Parent 查询,返回相关的子文档 POST my_blogs/_search { "query": { "has_parent": { "parent_type": "blog", "query" : { "match": { "title" : "Learning Hadoop" } } } } }
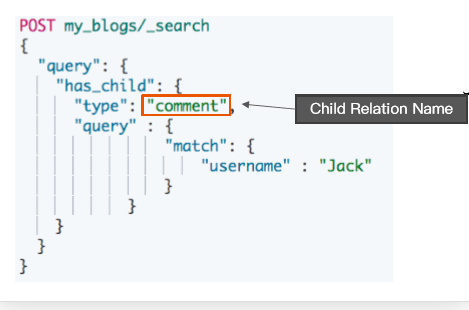
使用 has_child 查询
返回父文档
通过对子文档进行查询
返回具体相关子文档的父文档
父子文档在相同的分片上,因此 Join 效率高
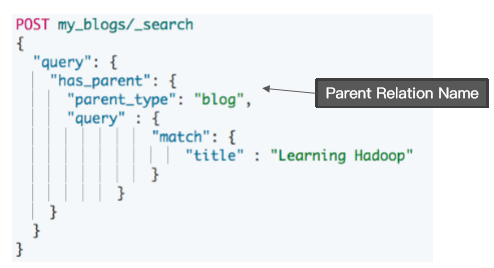
使用 has_parent 查询
返回相关性的子文档
通过对父文档进行查询
返回相关的子文档
使用 parent_id 查询
返回所有相关子文档
通过对付文档 Id 进行查询
返回所有相关的子文档
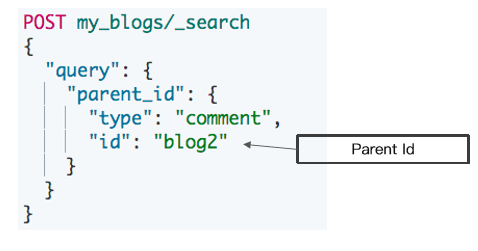
访问子文档
需指定父文档 routing 参数
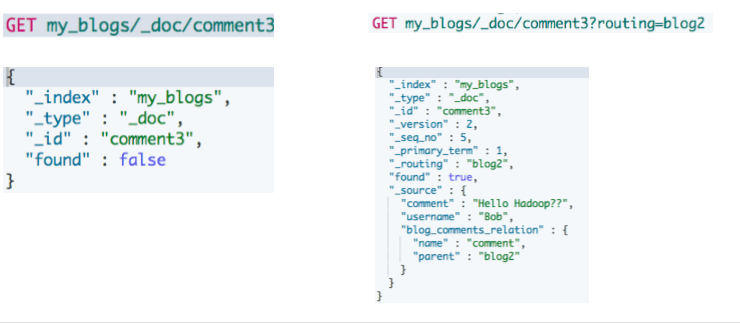
#通过ID ,访问子文档 GET my_blogs/_doc/comment2 #通过ID和routing ,访问子文档 GET my_blogs/_doc/comment3?routing=blog2
更新子文档
更新子文档不会影响到父文档
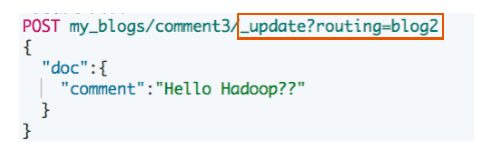
#更新子文档
PUT my_blogs/_doc/comment3?routing=blog2 { "comment": "Hello Hadoop??", "blog_comments_relation": { "name": "comment", "parent": "blog2" } }
嵌套对象 v.s 父子文档
Nested Object Parent / Child
优点:文档存储在一起,读取性能高、父子文档可以独立更新
缺点:更新嵌套的子文档时,需要更新整个文档、需要额外的内存去维护关系。读取性能相对差
适用场景子文档偶尔更新,以查询为主、子文档更新频繁
四、文件系统数据建模
思考一下,github中可以使用代码片段来实现数据搜索。这是如何实现的?
在github中也使用了ES来实现数据的全文搜索。其ES中有一个记录代码内容的索引,大致数据内容如下:
{ "fileName" : "HelloWorld.java", "authName" : "baiqi", "authID" : 110, "productName" : "first-java", "path" : "/com/baiqi/first", "content" : "package com.baiqi.first; public class HelloWorld { //code... }" }
我们可以在github中通过代码的片段来实现数据的搜索。也可以使用其他条件实现数据搜索。但是,如果需要使用文件路径搜索内容应该如何实现?这个时候需要为其中的字段path定义一个特殊的分词器。具体如下:
PUT /codes { "settings": { "analysis": { "analyzer": { "path_analyzer" : { "tokenizer" : "path_hierarchy" } } } }, "mappings": { "properties": { "fileName" : { "type" : "keyword" }, "authName" : { "type" : "text", "analyzer": "standard", "fields": { "keyword" : { "type" : "keyword" } } }, "authID" : { "type" : "long" }, "productName" : { "type" : "text", "analyzer": "standard", "fields": { "keyword" : { "type" : "keyword" } } }, "path" : { "type" : "text", "analyzer": "path_analyzer", "fields": { "keyword" : { "type" : "keyword" } } }, "content" : { "type" : "text", "analyzer": "standard" } } } } PUT /codes/_doc/1 { "fileName" : "HelloWorld.java", "authName" : "baiqi", "authID" : 110, "productName" : "first-java", "path" : "/com/baiqi/first", "content" : "package com.baiqi.first; public class HelloWorld { // some code... }" } GET /codes/_search { "query": { "match": { "path": "/com" } } } GET /codes/_analyze { "text": "/a/b/c/d", "field": "path" } ############################################################################################################ PUT /codes { "settings": { "analysis": { "analyzer": { "path_analyzer" : { "tokenizer" : "path_hierarchy" } } } }, "mappings": { "properties": { "fileName" : { "type" : "keyword" }, "authName" : { "type" : "text", "analyzer": "standard", "fields": { "keyword" : { "type" : "keyword" } } }, "authID" : { "type" : "long" }, "productName" : { "type" : "text", "analyzer": "standard", "fields": { "keyword" : { "type" : "keyword" } } }, "path" : { "type" : "text", "analyzer": "path_analyzer", "fields": { "keyword" : { "type" : "text", "analyzer": "standard" } } }, "content" : { "type" : "text", "analyzer": "standard" } } } } GET /codes/_search { "query": { "match": { "path.keyword": "/com" } } } GET /codes/_search { "query": { "bool": { "should": [ { "match": { "path": "/com" } }, { "match": { "path.keyword": "/com/baiqi" } } ] } } }
五、根据关键字分页搜索
在存在大量数据时,一般我们进行查询都需要进行分页查询。例如:我们指定页码、并指定每页显示多少条数据,然后Elasticsearch返回对应页码的数据。
1、使用from和size来进行分页
在执行查询时,可以指定from(从第几条数据开始查起)和size(每页返回多少条)数据,就可以轻松完成分页。
l from = (page – 1) * size
POST /es_db/_doc/_search { "from": 0, "size": 2, "query": { "match": { "address": "广州天河" } } }
2、使用scroll方式进行分页
前面使用from和size方式,查询在1W条数据以内都是OK的,但如果数据比较多的时候,会出现性能问题。Elasticsearch做了一个限制,不允许查询的是10000条以后的数据。如果要查询1W条以后的数据,需要使用Elastics
earch中提供的scroll游标来查询。 在进行大量分页时,每次分页都需要将要查询的数据进行重新排序,这样非常浪费性能。使用scroll是将要用的数据一次性排序好,然后分批取出。性能要比from + size好得多。使用scroll查询后,排序后的数据会保持一定
的时间,后续的分页查询都从该快照取数据即可。
2.1、第一次使用scroll分页查询
此处,我们让排序的数据保持1分钟,所以设置scroll为1m
GET /es_db/_search?scroll=1m { "query": { "multi_match":{ "query":"广州长沙张三", "fields":["address","name"] } }, "size":100 }
执行后,我们注意到,在响应结果中有一项: "_scroll_id": "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAAZEWY2VQZXBia1JTVkdhTWkwSl9GaUYtQQ==" 后续,我们需要根据这个_scroll_id来进行查询
2.2、第二次直接使用scroll id进行查询
GET _search/scroll?scroll=1m { "scroll_id":"DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAAZoWY2VQZXBia1JTVkdhTWkwSl9GaUYtQQ==" }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号