Karmada多集群方案
Karmada 是由华为开源的多云容器编排项目,项目是 Kubernetes Federation v1 和 v2 的延续。
架构
控制平面组件
一个完整且可工作的 Karmada 控制平面由以下组件组成。karmada-agent 可以是可选的, 这取决于集群注册模式。
-
karmada-apiserver
API 服务器是 Karmada 控制平面的一个组件,对外暴露 Karmada API 以及 Kubernetes 原生API,API 服务器是 Karmada 控制平面的前端。 -
Karmada API 服务器是直接使用 Kubernetes 的 kube-apiserver 实现的,因此 Karmada 与 Kubernetes API 自然兼容。 这也使得 Karmada 更容易实现与 Kubernetes 生态系统的集成,例如允许用户使用 kubectl 来操作 Karmada、 与 ArgoCD 集成、与 Flux 集成等等。
-
karmada-aggregated-apiserver
聚合 API 服务器是使用 Kubernetes API 聚合层技术实现的扩展 API 服务器。 它提供了集群 API 以及相应的子资源, 例如 cluster/status 和 cluster/proxy,实现了聚合 Kubernetes API Endpoint 等可以通过 karmada-apiserver 访问成员集群的高级功能。 -
kube-controller-manager
kube-controller-manager 由一组控制器组成,Karmada 只是从 Kubernetes 的官方版本中挑选了一些控制器,以保持与原生控制器一致的用户体验和行为。值得注意的是,并非所有的原生控制器都是 Karmada 所需要的, 推荐的控制器请参阅 推荐的控制器。
注意:当用户向 Karmada API 服务器提交 Deployment 或其他 Kubernetes 标准资源时,它们只记录在 Karmada 控制平面的 etcd 中。 随后,这些资源会向成员集群同步。然而,这些部署资源不会在 Karmada 控制平面集群中进行 reconcile 过程(例如创建Pod)。
-
karmada-controller-manager
Karmada 控制器管理器运行了各种自定义控制器进程。控制器负责监视Karmada对象,并与底层集群的API服务器通信,以创建原生的 Kubernetes 资源。
-
karmada-scheduler
karmada-scheduler 负责将 Kubernetes 原生API资源对象(以及CRD资源)调度到成员集群。调度器依据策略约束和可用资源来确定哪些集群对调度队列中的资源是可用的,然后调度器对每个可用集群进行打分排序,并将资源绑定到最合适的集群。
-
karmada-webhook
karmada-webhook 是用于接收 karmada/Kubernetes API 请求的 HTTP 回调,并对请求进行处理。你可以定义两种类型的 karmada-webhook,即验证性质的 webhook 和修改性质的 webhook。 修改性质的准入 webhook 会先被调用。它们可以更改发送到 Karmada API 服务器的对象以执行自定义的设置默认值操作。在完成了所有对象修改并且 Karmada API 服务器也验证了所传入的对象之后,验证性质的 webhook 会被调用,并通过拒绝请求的方式来强制实施自定义的策略。
-
etcd
一致且高可用的键值存储,用作 Karmada 的所有 Karmada/Kubernetes 资源对象数据的后台数据库。 -
karmada-agent
Karmada 有 Push 和 Pull 两种集群注册模式,karmada-agent 应部署在每个 Pull 模式的成员集群上。 它可以将特定集群注册到 Karmada 控制平面,并将工作负载清单从 Karmada 控制平面同步到成员集群。 此外,它也负责将成员集群及其资源的状态同步到 Karmada 控制平面。

CLI 工具
-
karmadactl
Karmada 提供了一个命令行工具 karmadactl,用于使用 Karmada API 与 Karmada 的控制平面进行通信。可以使用 karmadactl 执行成员集群的添加/剔除,将成员集群标记/取消标记为不可调度,等等。 有关包括 karmadactl 操作完整列表在内的更多信息,请参阅 karmadactl。
-
kubectl karmada
kubectl karmada 以 kubectl 插件的形式提供功能,但它的实现与 karmadactl 完全相同。
核心概念
-
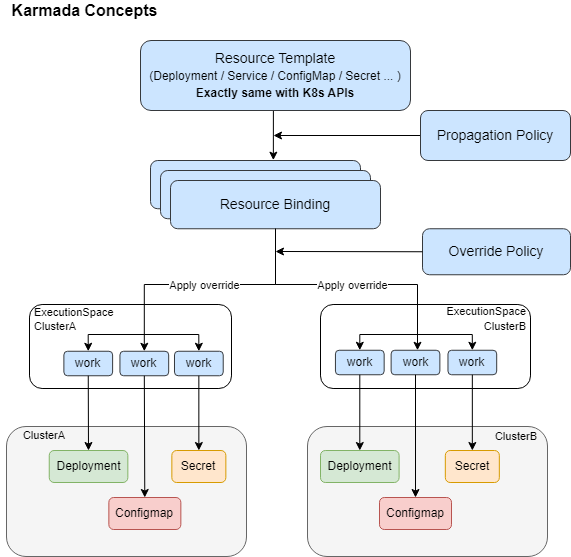
资源模板
Karmada 使用 Kubernetes 原生 API 定义联邦资源模板,以便轻松与现有 Kubernetes 采用的工具进行集成。 -
调度策略
Karmada 提供了一个独立的 Propagation(placement) Policy API 来定义多集群的调度要求。支持 1:N 的策略映射机制。用户无需每次创建联邦应用时都标明调度约束。
在使用默认策略的情况下,用户可以直接与 Kubernetes API 交互。
-
差异化策略
Karmada 为不同的集群提供了一个可自动化生产独立配置的 Override Policy API。例如:基于成员集群所在区域自动配置不同镜像仓库地址。
根据集群不同的云厂商,可以使用不同的存储类。
部署
部署Karmada依赖K8S,提前准备两个K8S集群,可以通过Sealos一键快速部署。
安装CLI工具
karmada 提供了 kubectl 插件,通过该插件可以很轻松的安装 Karmada。
wget https://github.com/karmada-io/karmada/releases/download/v1.5.0/kubectl-karmada-linux-amd64.tgz
tar -zxvf kubectl-karmada-linux-amd64.tgz
cp kubectl-karmada /usr/local/bin
kubectl-karmada version
初始化karmada
先手动下载 crd,实际上里面就是一些 crd 的 yaml 文件.(因为国内网络限制,如果在外网可以直接kubectl karmada init)
wget https://github.com/karmada-io/karmada/releases/download/v1.5.0/crds.tar.gz
然后 init 时指定 crd 地址以及镜像仓库。
kubectl karmada init \
--kube-image-registry registry.cn-hangzhou.aliyuncs.com/google_containers \
--crds crds.tar.gz
安装完成后结果如下
------------------------------------------------------------------------------------------------------
█████ ████ █████████ ███████████ ██████ ██████ █████████ ██████████ █████████
░░███ ███░ ███░░░░░███ ░░███░░░░░███ ░░██████ ██████ ███░░░░░███ ░░███░░░░███ ███░░░░░███
░███ ███ ░███ ░███ ░███ ░███ ░███░█████░███ ░███ ░███ ░███ ░░███ ░███ ░███
░███████ ░███████████ ░██████████ ░███░░███ ░███ ░███████████ ░███ ░███ ░███████████
░███░░███ ░███░░░░░███ ░███░░░░░███ ░███ ░░░ ░███ ░███░░░░░███ ░███ ░███ ░███░░░░░███
░███ ░░███ ░███ ░███ ░███ ░███ ░███ ░███ ░███ ░███ ░███ ███ ░███ ░███
█████ ░░████ █████ █████ █████ █████ █████ █████ █████ █████ ██████████ █████ █████
░░░░░ ░░░░ ░░░░░ ░░░░░ ░░░░░ ░░░░░ ░░░░░ ░░░░░ ░░░░░ ░░░░░ ░░░░░░░░░░ ░░░░░ ░░░░░
------------------------------------------------------------------------------------------------------
Karmada is installed successfully.
Register Kubernetes cluster to Karmada control plane.
Register cluster with 'Push' mode
Step 1: Use "kubectl karmada join" command to register the cluster to Karmada control plane. --cluster-kubeconfig is kubeconfig of the member cluster.
(In karmada)~# MEMBER_CLUSTER_NAME=$(cat ~/.kube/config | grep current-context | sed 's/: /\n/g'| sed '1d')
(In karmada)~# kubectl karmada --kubeconfig /etc/karmada/karmada-apiserver.config join ${MEMBER_CLUSTER_NAME} --cluster-kubeconfig=$HOME/.kube/config
Step 2: Show members of karmada
(In karmada)~# kubectl --kubeconfig /etc/karmada/karmada-apiserver.config get clusters
Register cluster with 'Pull' mode
Step 1: Use "kubectl karmada register" command to register the cluster to Karmada control plane. "--cluster-name" is set to cluster of current-context by default.
(In member cluster)~# kubectl karmada register 10.0.0.58:32443 --token jcbljd.tfotd1ylodf7jtm6 --discovery-token-ca-cert-hash sha256:3bc5b22efbef8470f010f65b68388266e2b8f3ab62a0151900761cd12760d34f
Step 2: Show members of karmada
(In karmada)~# kubectl --kubeconfig /etc/karmada/karmada-apiserver.config get clusters
集群管理
Karmada 初始化完成后就可以将业务集群添加到 Karmada 中进行管理了。
注册方式分为 Push 模式和 Pull 模式,二者的注册方式不相同。
- Push 模式下,karmada 控制面会直接访问 member 集群的 kube-apiserver 以获取集群状态和部署资源
- Pull 模式下,会在 member 集群部署 karmada-agent ,包含以下作用
- 注册集群到 karmada
- 维护集群状态并报告给 karmada
- Watch karmada 集群里对应 namespace 下的资源对象,并将其部署到 member 集群里。
Push模式
push 模式下 join 命令是在 karmada 集群中执行。
kubectl karmada --kubeconfig /etc/karmada/karmada-apiserver.config join cluster1 --cluster-kubeconfig=$HOME/.kube/config
-
--kubeconfig /etc/karmada/karmada-apiserver.config指定 Karmada kubeconfig,表示操作的是 karmada 的 apiserver,实际上 Karmada apiserver 也是基于 kube-apiserver 源码修改的,因此相关操作也基本一致。
-
--cluster-kubeconfig=$HOME/.kube/config则是指定待注册到 karmada 的 member 集群的 kubeconfig。
添加好后可以使用 kubectl 命令进行查看
[root@karmada ~]# kubectl --kubeconfig /etc/karmada/karmada-apiserver.config get clusters
NAME VERSION MODE READY AGE
Cluster1 v1.23.6 Push True 1m24s
[!NOTE]
提前修改k8s集群的kubeconfig文件,保障Server地址可联通,集群名称为有区别度的自定义名称。
Pull模式
pull 模式下的 register 命令需要到 member 集群中执行,并在member集群提前安装CLI工具(不需要初始化Karmada)。
kubectl karmada register <karmada-apiserver> --token <token> --discovery-token-ca-cert-hash <hash>
类似与 kubeadm join 命令,需要提供 token 以及 ca证书的 hash 值作为校验。
仔细观察的话,可以发现在执行 karmada init 之后输出的日志里实际上是有提供该命令的.
当然,我们也可以使用以下命令重新生成 token(有效期 24h):
kubectl karmada token create --print-register-command --kubeconfig /etc/karmada/karmada-apiserver.config
回到 karmada 查看,集群已经注册上了。
[root@lixd-tmp-1 ~]# kubectl --kubeconfig /etc/karmada/karmada-apiserver.config get clusters
NAME VERSION MODE READY AGE
cluster1 v1.23.6 Pull True 72s
cluster2 v1.23.6 Push True 3m
[!NOTE]
最好也提前修改k8s集群的kubeconfig文件,集群名称为有区别度的自定义名称。
使用
应用分发
只需要把平时 apply 到 kube-apiserver 的 资源对象 全部 apply 到 karmada-apiserver,然后搭配上 karmada 中的 CRD 对象 PropagationPolicy 即可完成多集群应用管理,Karmada 就会根据 PropagationPolicy 中指定的规则,将这些资源对象分发到各个集群里。
下面创建一个deployment部署nginx,可以把nginx两个副本分别部署到两个集群。
首先创建propagationpolicy.yaml,propagation为“传播”的意思。
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: nginx-propagation
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: nginx # 对应名为nginx的deployment
placement:
clusterAffinity: # 表示应用待分发的集群
clusterNames:
- member1
- member2
replicaScheduling: # 表示有副本数资源的调度策略,例如Deployment、StatefulSet。
replicaDivisionPreference: Weighted # 副本拆分策略,包括weighted(按照权重进行副本数的调度)和Aggregated(将副本尽量分布到分数高的集群中)
replicaSchedulingType: Divided # 副本调度策略,包括Duplicated(将应用直接复制到每个集群中)和Divided(将应用副本数按照集群权重进行调度)
weightPreference: # 包括动态权重dynamicWeight和静态权重staticWeightList
staticWeightList:
- targetCluster:
clusterNames:
- member1
weight: 1
- targetCluster:
clusterNames:
- member2
weight: 1
其次创建deployment.yaml,用于nginx部署,该deployment的metadata.name需要为nginx,以与propagationpolicy中的资源对应。
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
labels:
app: nginx
spec:
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: nginx
name: nginx
分别部署propagationpolicy.yaml和deployment.yaml。
kubectl --kubeconfig /etc/karmada/karmada-apiserver.config apply -f propagationpolicy.yaml
kubectl --kubeconfig /etc/karmada/karmada-apiserver.config apply -f deployment.yaml
从 Karmada 查看 Deployment 状态
$ kubectl get deployment --kubeconfig /etc/karmada/karmada-apiserver.config
NAME READY UP-TO-DATE AVAILABLE AGE
nginx 2/2 2 2 20s
从单个成员集群内部获取deployment
kubectl get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
nginx 1/1 1 1 23s
差异化策略
通过定义差异化策略(OverridePolicy)选择需要差异化部署的集群以及资源。创建差异化策略后会将相应的资源进行定制化修改后再部署到选中的集群中。
创建一个 OverridePolicy,把 cluster1 的镜像 tag 替换为 1.20。
apiVersion: policy.karmada.io/v1alpha1
kind: OverridePolicy
metadata:
name: example
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: nginx
labelSelector:
matchLabels:
app: nginx
overrideRules:
- targetCluster:
clusterNames:
- cluster1
overriders:
imageOverrider:
- component: Tag # 在Registry、Repository、Tag三种类型选择一种方式对镜像进行修改,镜像格式为[registry/]repository[:tag]
operator: replace # 支持选择remove、add、replace
value: '1.20'
执行该OverridePolicy,
kubectl --kubeconfig /etc/karmada/karmada-apiserver.config apply -f overridepolicy.yaml
然后去 cluster 查看,已经替换成功:
[root@cluster-1 ~]# kubecyl get deploy -oyaml|grep image
- image: nginx:1.20
imagePullPolicy: Always
动态分发和重调度
如果某个集群故障或没有足够的资源调度应用,需要将该集群运行的应用副本调度到其他集群,这是多集群方案为应对集群故障应具备的能力,可以通过动态分发和重调度实现。
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: nginx-propagation
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: nginx
placement:
clusterAffinity:
clusterNames:
- member1
- member2
replicaScheduling:
replicaDivisionPreference: Weighted
replicaSchedulingType: Divided
weightPreference:
dynamicWeight: AvailableReplicas # 使用动态分发
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: nginx
name: nginx
每个集群调度一个副本,然后关闭集群,模拟故障;或者使用官方的污染节点并驱逐副本
# mark node "member1-control-plane" as unschedulable in cluster member1
kubectl --context member1 cordon member1-control-plane
# delete the pod in cluster member1
kubectl --context member1 delete pod -l app=nginx
大约 5 到 7 分钟后,member1 中的 pod 将被驱逐并调度到其他可用集群。
# get the pod in cluster member1
$ kubectl --context member1 get pod
No resources found in default namespace.
# get a list of pods in cluster member2
$ kubectl --context member2 get pod
NAME READY STATUS RESTARTS AGE
nginx-68b895fcbd-dgd4x 1/1 Running 0 6m3s
nginx-68b895fcbd-nwgjn 1/1 Running 0 4s
Submariner
Submariner是开源的实现 Kubernetes 集群之间网络通信的组件。
主要功能包括:
- 跨集群的 L3 连接
- 跨集群的服务发现
- Globalnet 支持 CIDR 重叠
架构
整体架构
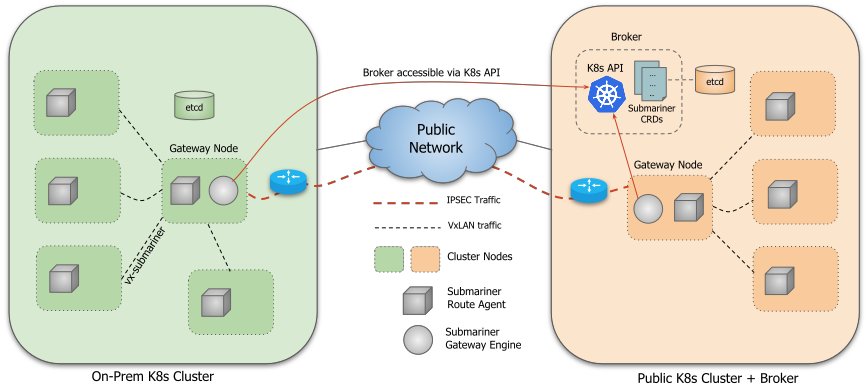
Submariner 由几个主要部分组成:
-
Broker: 本质上是两个用于交换集群信息的 CRD(Endpoint 和 Cluster),我们需要选择一个集群作为 Broker 集群,其他集群连接到 Broker 集群的 API Server 来交换集群信息:
- Endpoint:包含了 Gateway Engine 建立集群间连接需要的信息,例如 Private IP 和 Public IP,NAT 端口等等。
- Cluster:包含原始集群的静态信息,例如其 Service 和 Pod CIDR。
-
Gateway Engine:管理连接到其他集群的隧道。
-
Route Agent:负责将跨集群的流量路由到 active Gateway Node。
-
Service Discovery: 提供跨集群的 DNS 服务发现。
-
Globalnet(可选):处理具有重叠 CIDR 的集群互连。
-
Submariner Operator:负责在 Kubernetes 集群中安装 Submariner 组件,例如 Broker, Gateway Engine, Route Agent 等等。
Submariner 中跨集群的 DNS 服务发现由以下两个组件基于 Kubernetes Multi-Cluster Service APIs 的规范来实现:
Service Discovery

- Lighthouse Agent:访问 Broker 集群的 API Server 与其他集群交换 ServiceImport 元数据信息。
- 对于本地集群中已创建 ServiceExport 的每个 Service,Agent 创建相应的 ServiceImport 资源并将其导出到 Broker 以供其他集群使用。
- 对于从其他集群导出到 Broker 中的 ServiceImport 资源,它会在本集群中创建它的副本。
- Lighthouse DNS Server:
- Lighthouse DNS Server 根据 ServiceImport 资源进行 DNS 解析。
- CoreDNS 配置为将 clusterset.local 域名的解析请求发往 Lighthouse DNS server。
MCS API 是 Kubernetes 社区定义的用于跨集群服务发现的规范,主要包含了 ServiceExport 和 ServiceImport 两个 CRD。
-
ServiceExport 定义了暴露(导出)到其他集群的 Service,由用户在要导出的 Service 所在的集群中创建,与 Service 的名字和 Namespace 一致。
-
ServiceImport:当一个服务被导出后,实现 MCS API 的控制器会在所有集群(包括导出服务的集群)中自动生成一个与之对应的 ServiceImport 资源。
Gateway Engine
Gateway Engine 部署在每个集群中,负责建立到其他集群的隧道。隧道可以由以下方式实现:
-
IPsec,使用 Libreswan 实现。这是当前的默认设置。
-
WireGuard,使用 wgctrl 库实现。
-
VXLAN,不加密。
可以在使用 subctl join 命令加入集群的时候使用 --cable-driver 参数设置隧道的类型。
Gateway Engine 部署为 DaemonSet,只在有 submariner.io/gateway=true Label 的 Node 上运行,当我们使用 subctl join 命令加入集群的时候,如果没有 Node 有该 Label,会提示我们选择一个 Node 作为 Gateway Node。
Submariner 也支持 active/passive 高可用模式的 Gateway Engine,我们可以在多个节点上部署 Gateway Engine。在同一时间内,只能有一个 Gateway Engine 处于 active 状态来处理跨集的流量,Gateway Engine 通过领导者选举的方式确定 active 的实例,其他实例在 passive 模式下等待,准备在 active 实例发生故障时接管。

隧道打通的实现效果是集群两边的Service CIDR和Pod CIDR两两互通。

Globalnet
Submariner 的一大亮点是支持在不同集群间存在 CIDR 重叠的情况,这有助于减少网络重构的成本。例如,在部署过程中,某些集群可能使用了默认的网段,导致了 CIDR 重叠。在这种情况下,如果后续需要更改集群网段,可能会对集群的运行产生影响。
为了支持集群间重叠 CIDR 的情况,Submariner 通过一个 GlobalCIDR 网段(默认是 242.0.0.0/8)在流量进出集群时进行 NAT 转换,所有的地址转换都发生在 active Gateway Node 上。在 subctl deploy 部署 Broker 的时候可以通过 --globalnet-cidr-range 参数指定所有集群的全局 GlobalCIDR。在 subctl join 加入集群的时候还可以通过 --globalnet-cidr 参数指定该集群的 GlobalCIDR。
导出的 ClusterIP 类型的 Service 会从 GlobalCIDR 分配一个 Global IP 用于入向流量,对于 Headless 类型的 Service,会为每个关联的 Pod 分配一个 Global IP 用于入向和出向流量。

使用
多集群pod和Service CIDR不一致
使用最基础的Submariner方案连接集群即可。
创建容器和集群内服务
在c2集群创建Deployment和Service。
apiVersion: apps/v1
kind: Deployment
metadata:
name: whereami
namespace: sample
spec:
replicas: 3
selector:
matchLabels:
app: whereami
template:
metadata:
labels:
app: whereami
spec:
containers:
- name: whereami
image: cr7258/whereami:v1
imagePullPolicy: Always
ports:
- containerPort: 80
env:
- name: NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
---
apiVersion: v1
kind: Service
metadata:
name: whereami-cs
namespace: sample
spec:
selector:
app: whereami
ports:
- protocol: TCP
port: 80
targetPort: 80
集群中可查看服务
root@seven-demo:~# kubectl --context kind-c2 get pod -n sample -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
whereami-754776cdc9-28kgd 1/1 Running 0 19h 10.9.1.18 c2-control-plane <none> <none>
whereami-754776cdc9-8ccmc 1/1 Running 0 19h 10.9.1.17 c2-control-plane <none> <none>
whereami-754776cdc9-dlp55 1/1 Running 0 19h 10.9.1.16 c2-control-plane <none> <none>
root@seven-demo:~# kubectl --context kind-c2 get svc -n sample -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
whereami-cs ClusterIP 10.99.2.201 <none> 80/TCP 19h app=whereami
服务跨集群发布
在 c2 集群中使用 subctl export 命令将服务导出。
subctl --context kind-c2 export service --namespace sample whereami-cs
该命令会在创建一个和 Service 相同名字和 Namespace 的 ServiceExport 资源。
root@seven-demo:~# kubectl get serviceexports --context kind-c2 -n sample whereami-cs -o yaml
apiVersion: multicluster.x-k8s.io/v1alpha1
kind: ServiceExport
metadata:
creationTimestamp: "2023-04-06T13:04:15Z"
generation: 1
name: whereami-cs
namespace: sample
resourceVersion: "327707"
uid: d1da8953-3fa5-4635-a8bb-6de4cd3c45a9
status:
conditions:
- lastTransitionTime: "2023-04-06T13:04:15Z"
message: ""
reason: ""
status: "True"
type: Valid
- lastTransitionTime: "2023-04-06T13:04:15Z"
message: ServiceImport was successfully synced to the broker
reason: ""
status: "True"
type: Synced
ServiceImport 资源会由 Submariner 自动在 c1,c2 集群中创建,IP 地址是 Service 的 ClusterIP 地址。

服务跨集群访问
在 c1 集群创建一个 client Pod 来访问 c2 集群的 whereami 服务。
kubectl --context kind-c1 run client --image=cr7258/nettool:v1
kubectl --context kind-c1 exec -it client -- bash
先尝试下 DNS 解析,ClusterIP Service 类型的 Service 可以通过以下格式进行访问 <svc-name>.<namespace>.svc.clusterset.local。
nslookup whereami-cs.sample.svc.clusterset.local
查看一下 CoreDNS 的配置文件,这个 Configmap 会被 Submariner Operator 修改,将 clusterset.local 用于跨集群通信的域名交给 Lighthouse DNS 来解析。
root@seven-demo:~# kubectl get cm -n kube-system coredns -oyaml
apiVersion: v1
data:
Corefile: |+
#lighthouse-start AUTO-GENERATED SECTION. DO NOT EDIT
clusterset.local:53 {
forward . 10.88.78.89
}
#lighthouse-end
.:53 {
errors
health {
lameduck 5s
}
ready
kubernetes cluster.local in-addr.arpa ip6.arpa {
pods insecure
fallthrough in-addr.arpa ip6.arpa
ttl 30
}
prometheus :9153
forward . /etc/resolv.conf {
max_concurrent 1000
}
cache 30
loop
reload
loadbalance
}
kind: ConfigMap
metadata:
creationTimestamp: "2023-04-05T02:47:34Z"
name: coredns
namespace: kube-system
resourceVersion: "1211"
uid: 698f20a5-83ea-4a3e-8a1e-8b9438a6b3f8
Submariner 遵循以下逻辑来进行跨集群集的服务发现:
-
如果导出的服务在本地集群中不可用,Lighthouse DNS 从服务导出的远程集群之一返回 ClusterIP 服务的 IP 地址。
-
如果导出的服务在本地集群中可用,Lighthouse DNS 总是返回本地 ClusterIP 服务的 IP 地址。
-
如果多个集群从同一个命名空间导出具有相同名称的服务,Lighthouse DNS 会以轮询的方式在集群之间进行负载均衡。
-
可以在 DNS 查询前加上 cluster-id 前缀来访问特定集群的服务,
<cluster-id>.<svc-name>.<namespace>.svc.clusterset.local。

获取到DNS解析后的IP就可以访问了。
流量从 c1 集群的 client Pod 发出,首先经过 veth-pair 到达 Node 的 Root Network Namespace,然后经过 Submariner Route Agent 设置的 vx-submariner 这个 VXLAN 隧道将流量发往 Gateway Node 上(c1-worker)。接着经过连接 c1 和 c2 集群的 IPsec 隧道到达对端,c2 集群的 Gateway Node(c2-worker)接收到流量后将,经过 iptables 的反向代理规则(在这过程中根据 ClusterIP 进行了 DNAT)最终发送到后端的 whereami Pod 上。
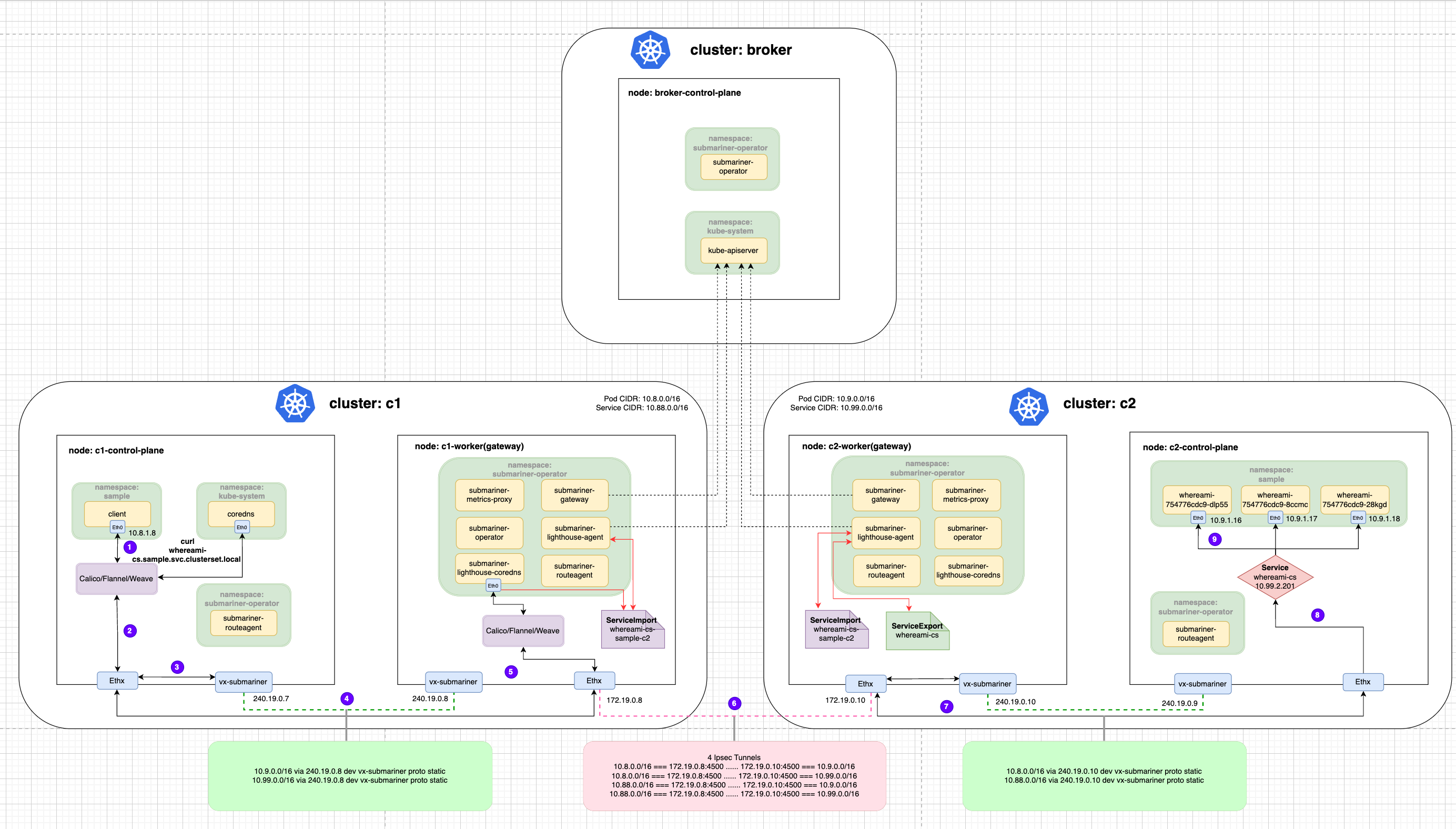
Headless Service跨集群访问
Submariner 还支持带有 StatefulSets 的 Headless Services,从而可以通过稳定的 DNS 名称访问各个 Pod。在单个集群中,Kubernetes 通过引入稳定的 Pod ID 来支持这一点,在单个集群中可以通过 <pod-name>.<svc-name>.<ns>.svc.cluster.local 格式来解析域名。跨集群场景下,Submariner 通过 <pod-name>.<cluster-id>.<svc-name>.<ns>.svc.clusterset.local 的格式来解析域名。
在 c2 集群创建 Headless Service 和 StatefulSet。
apiVersion: v1
kind: Service
metadata:
name: whereami-ss
namespace: sample
labels:
app: whereami-ss
spec:
ports:
- port: 80
name: whereami
clusterIP: None
selector:
app: whereami-ss
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: whereami
namespace: sample
spec:
serviceName: "whereami-ss"
replicas: 3
selector:
matchLabels:
app: whereami-ss
template:
metadata:
labels:
app: whereami-ss
spec:
containers:
- name: whereami-ss
image: cr7258/whereami:v1
ports:
- containerPort: 80
name: whereami
env:
- name: NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
在 c2 集群查看服务。
root@seven-demo:~# kubectl get pod -n sample --context kind-c2 -o wide -l app=whereami-ss
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
whereami-0 1/1 Running 0 38s 10.9.1.20 c2-control-plane <none> <none>
whereami-1 1/1 Running 0 36s 10.9.1.21 c2-control-plane <none> <none>
whereami-2 1/1 Running 0 31s 10.9.1.22 c2-control-plane <none> <none>
root@seven-demo:~# kubectl get svc -n sample --context kind-c2 -l app=whereami-ss
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
whereami-ss ClusterIP None <none> 80/TCP 4m58s
在 c2 集群导出服务。
subctl --context kind-c2 export service whereami-ss --namespace sample
查看 ServiceImport,在 IP 地址的一栏是空的,因为导出的服务类型是 Headless。

解析 Headless Service 的域名可以得到所有 Pod 的 IP。
kubectl --context kind-c1 exec -it client -- bash
nslookup whereami-ss.sample.svc.clusterset.local
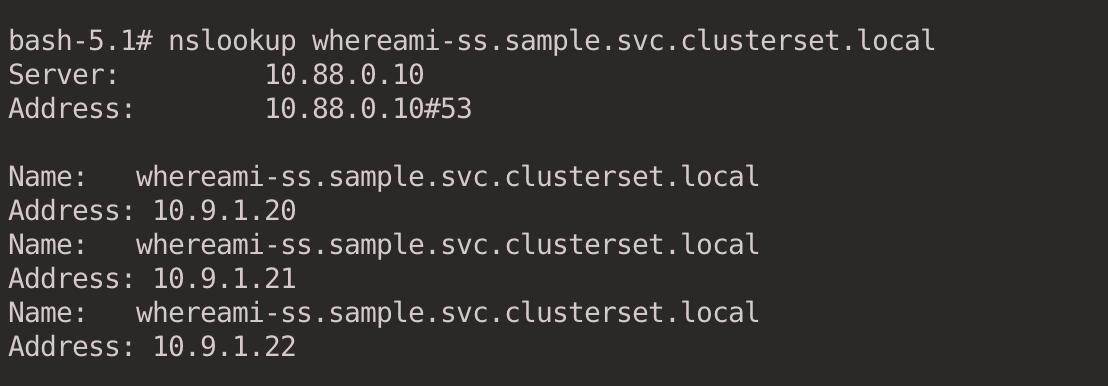
也可以指定单个 Pod 进行解析。
nslookup whereami-0.c2.whereami-ss.sample.svc.clusterset.local

多集群pod和Service CIDR一致
当多个集群CIDR一致时,需要启用Globalnet 功能。使用 --globalnet=true 参数启用 Globalnet 功能,使用 --globalnet-cidr-range 参数指定所有集群的全局 GlobalCIDR(默认 242.0.0.0/8)。
subctl --context kind-broker-globalnet deploy-broker --globalnet=true --globalnet-cidr-range 120.0.0.0/8
随后将g1/g2两个集群加入Submariner管理即可。
按正常流程创建应用容器和服务,利用subctl导出服务。
导出服务后,我们再查看一下 g2 集群的 Service,会发现 Submariner 自动在与导出的服务相同的命名空间中创建了一个额外的服务,并且设置 externalIPs 为分配给相应服务的 Global IP。

在另一个集群解析服务名,DNS 将会解析到分配给 c2 集群 whereami 服务的 Global IP 地址,而不是服务的 ClusterIP IP 地址。
用 curl 命令发起 HTTP 请求,从输出的结果可以发现,在 g2 集群的 whereami 看来,请求的源 IP 是 120.1.0.5,也就是说当流量从 g1 发往 g2 集群时,在 g1 集群的 Gateway Node 上对流量进行了 SNAT 源地址转换。

流量从 c1 集群的 client Pod 发出,经过 DNS 解析后应该请求 IP 120.2.0.253。首先经过 veth-pair 到达 Node 的 Root Network Namespace,然后经过 Submariner Route Agent 设置的 vx-submariner 这个 VXLAN 隧道将流量发往 Gateway Node 上(c1-worker)。在 Gateway Node 上将源 IP 10.7.1.7 转换成了 120.1.0.5, 然后通过 c1 和 c2 集群的 IPsec 隧道发送到对端,c2 集群的 Gateway Node(c2-worker)接收到流量后,经过 iptables 的反向代理规则(在这过程中根据 Global IP 进行了 DNAT)最终发送到后端的 whereami Pod 上。
如果是 Headless Service + StatefulSet,将Headless Service导出后,Globalnet 会为每一个 Headless Service 关联的 Pod 分配一个 Global IP,用于出向和入向的流量。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号