
4.作业
1.用图与自己的话,简要描述Hadoop起源与发展阶段。
Hadoop是道格·卡丁(Doug Cutting)创建的。
2003-2004年,Google公布了部分GFS和MapReduce思想的细节,受此启发的Doug Cutting等人用2年的业余时间实现了DFS和MapReduce机制,使Nutch性能飙升。然后Yahoo招安Doug Gutting及其项目。
2005年,Hadoop作为Lucene的子项目Nutch的一部分正式引入Apache基金会。
2006年2月被分离出来,成为一套完整独立的软件,起名为Hadoop

从与谷歌系统的关系,关键时间节点,1.x,2.x与3.x的区别,不同公司发行版本等方面来讲。
Hadoop起源于Nutch,是Lucene的子项目。以谷歌发表的为解决数十亿网页的存储和索引问题提供了可行的解决方案的论文为基础,Nutch的开发人员完成了相应的开源实现谷歌分布式文件系统(GFS)的架构(03年)、MapReduce系统(04年)、HDFS(04年),并从Nutch中剥离成为独立项目Hadoop。06年Google发表了关于BigTable的论文,促使了后来的Hbase的发展。因此,Hadoop及其生态圈的发展离不开Google的贡献。
1.不同版本的区别
- 1.x版本系列:hadoop版本当中的第二代开源版本,主要修复0.x版本的一些bug等,该版本已被淘汰
- 2.x版本系列:架构产生重大变化,引入了yarn平台等许多新特性,是现在使用的主流版本。
- 3.x版本系列:对HDFS、MapReduce、YARN都有较大升级,还新增了Ozone key-value存储。
2.用图与自己的话,简要描述名称节点、数据节点的主要功能及相互关系、名称节点的工作机制。


1、HDFS 采用主/从架构,主节点即NameNode 从节点即:DataNode
2、NameNode即是模式, 并完成外模式和模式之间的映像,模式和内模式之间的映像。
3、NameNode存放HDFS全局命名空间,充当全局数据目录;存储全局文件系统树,目录-文件-文件块信息
NameNode存放的数据块信息是在启动时扫描所有数据节点重构;
在运行过程中周期性受到数据节点发送的数据块列表信息重构而得;
4、在客户端读取数据过程中,将数据块和数据节点映射按远近排序列表发送给客户端;
5、在客户端写数据过程中,检查文件是否存在、是否有权限;将待写入文件分成若干文件块,并根据数据节点的繁忙和磁盘容量程度,分配数据块和数据节点对应关系列表反馈给客户端
4.简述HBase与传统数据库的主要区别
数据类型:Hbase只有简单的数据类型,只保留字符串;传统数据库有丰富的数据类型。数据库.数据操做:Hbase只有简单的插入、查询、删除、清空等操做,表和表之间是分离的,没有复杂的表和表之间的关系;传统数据库一般有各式各样的函数和链接操做。缓存
存储模式:Hbase是基于列存储的,每一个列族都由几个文件保存,不一样列族的文件是分离的,这样的好处是数据便是索引,访问查询涉及的列大量下降系统的I/O,而且每一列由一个线索来处理,能够实现查询的并发处理;传统数据库是基于表格结构和行存储,其没有创建索引将耗费大量的I/O而且创建索引和物化试图须要耗费大量的时间和资源。并发
数据维护:Hbase的更新其实是插入了新的数据;传统数据库只是替换和修改。函数
可伸缩性:Hbase能够轻松的增长或减小硬件的数目,而且对错误的兼容性比较高;传统数据库须要增长中间层才能实现这样的功能。高并发
事务:Hbase只能够实现单行的事务性,意味着行与行之间、表与表以前没必要知足事务性;传统数据库是能够实现跨行的事务性
5.梳理HBase的结构与运行流程,以用图与自己的话进行简要描述,图中包括以下内容:
- Master主服务器的功能
- Region服务器的功能
- Zookeeper协同的功能
- Client客户端的请求流程
- 四者之间的相系关系
- 与HDFS的关联
Master主服务器的功能
主服务器Master主要负责表和Region的管理工作:
管理用户对表的增加、删除、修改、查询等操作
实现不同Region服务器之间的负载均衡
在Region分裂或合并后,负责重新调整Region的分布
对发生故障失效的Region服务器上的Region进行迁移
Region服务器的功能
Region服务器是HBase中最核心的模块,负责维护分配给自己的Region,并响应用户的读写请求
Zookeeper协同的功能
Zookeeper可以帮助选举出一个Master作为集群的总管,并保证在任何时刻总有唯一一个Master在运行,这就避免了Master的“单点失效”问题
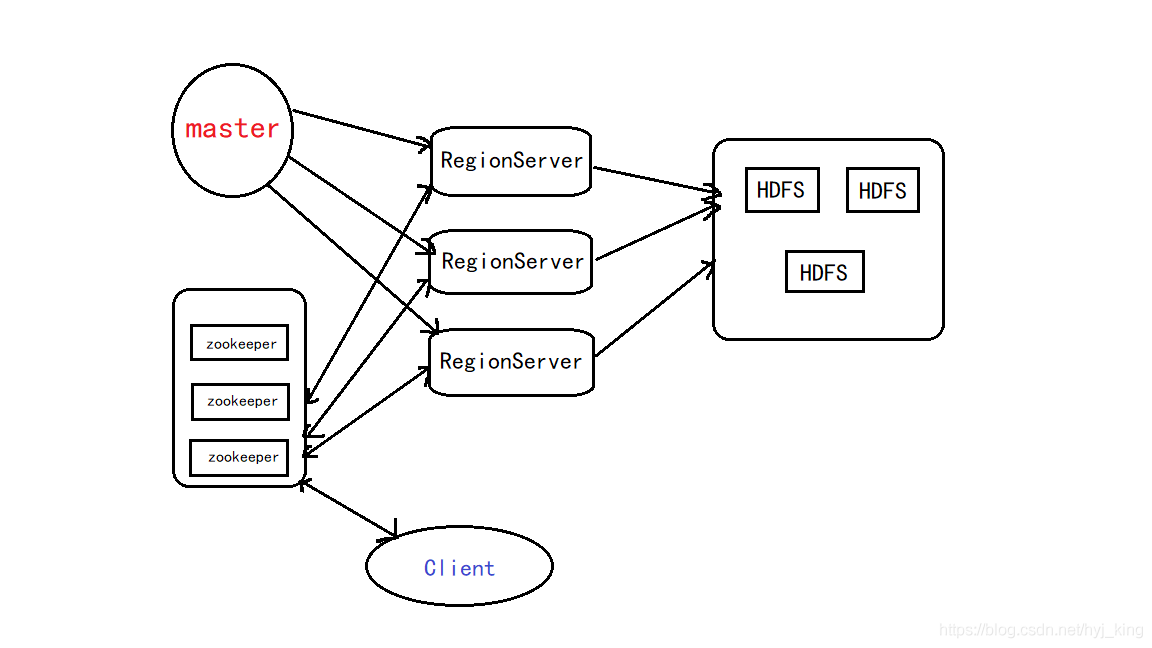
四者之间的相系关系
1、Hbase集群有两种服务器:一个Master服务器和多个RegionServer服务器;
2、Master服务负责维护表结构信息和各种协调工作,比如建表、删表、移动region、合并等操作;
3、客户端获取数据是由客户端直连RegionServer的,所以Master服务挂掉之后依然可以查询、存储、删除数据,就是不能建新表了;
4、RegionServer非常依赖Zookeeper服务,Zookeeper管理Hbase所有的RegionServer信息,包括具体的数据段存放在那个RegionServer上;
5、客户端每次与Hbase连接,其实都是先于Zookeeper通信,查询出哪个RegionServer需要连接,然后再连接RegionServer;客户端从Zookeeper获取了RegionServer的地址后,会直接从RegionServer获取数据;
与HDFS的关联
RegionServer保存的数据直接存储在Hadoop的HDFS上;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号