淘宝某商品数据分析
 惊了,一小伙对淘宝文胸数据进行一顿操作后,居然发现...
惊了,一小伙对淘宝文胸数据进行一顿操作后,居然发现...
前言
先说好,这是一篇正能量的科普文章,还有我不是变态!!!🐶
先唠一唠
我相信不光是之前的我,正在看这篇文章的老绅士们对于文胸也只知道A,B,C吧,知识相当之贫乏(不过好像知道这些,在现实生活中也并没有什么卵用。。。)
但是!!!我今天还是要来给大家科普一下这方面的知识。🐶
第一步
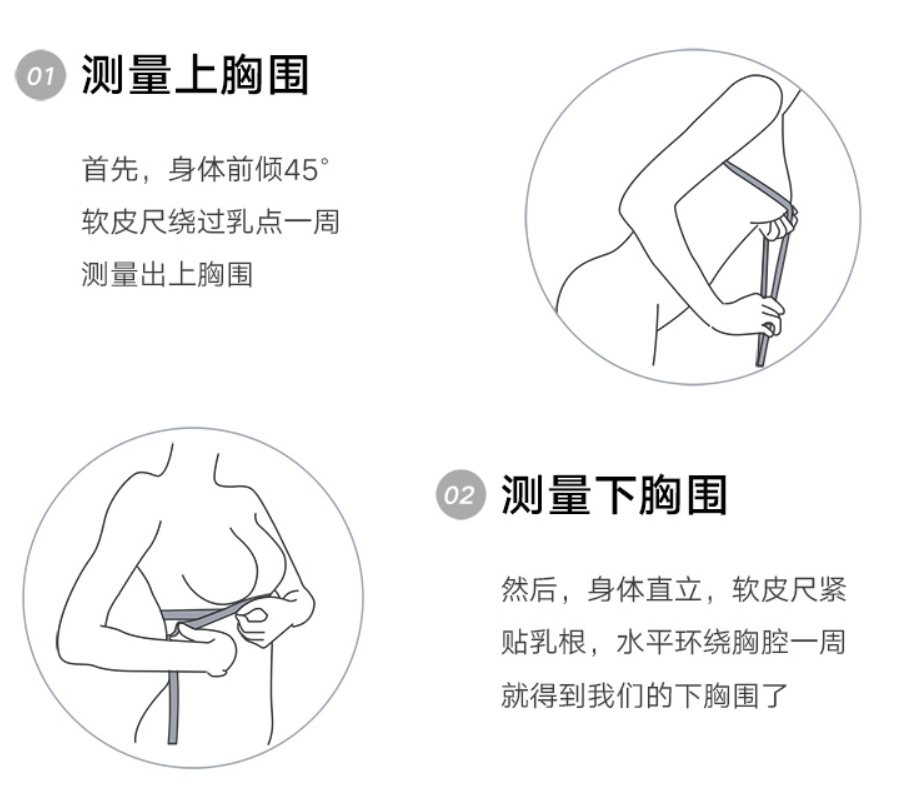
第二步
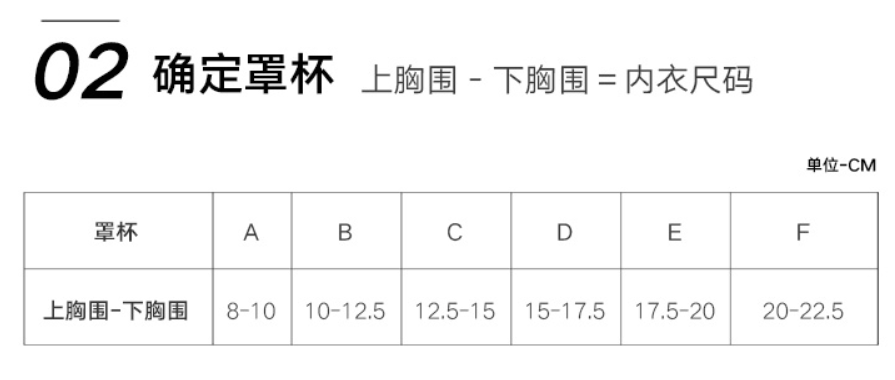
第三步
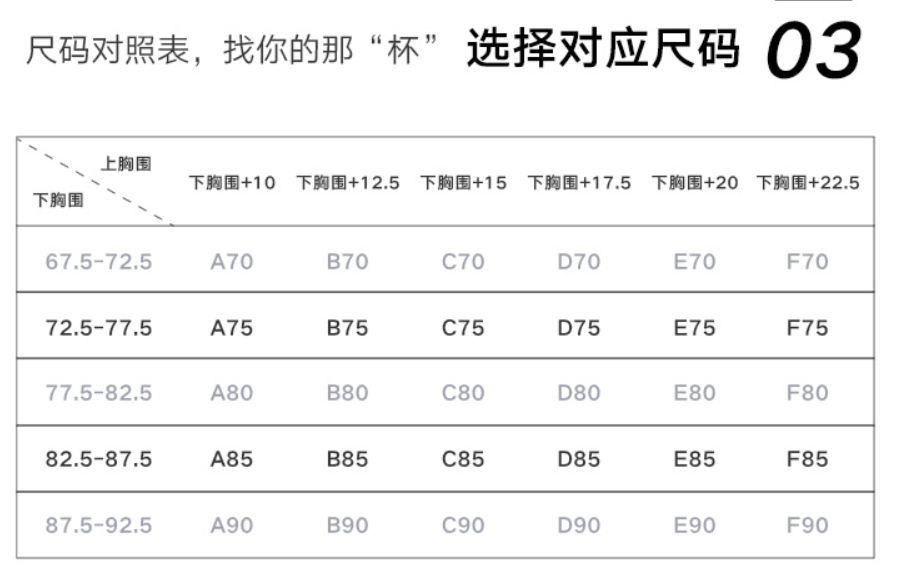
科普部分就到这了。。。
什么???还想看???
没了!!!
正题:爬取淘宝数据
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import csv
import time
import re
def deal_data(str):
res = re.sub(r'此用户没有填写评论!\n', "", str)
res2 = re.sub(r'收货.*?追加:\n', "", res)
res3 = re.sub(r'初次评价:\n', "", res2)
res4 = re.sub(r'颜色分类:\d+', "", res3)
res5 = re.sub(r'尺码:', "", res4)
res6 = re.sub(r'解释:.*?\n', "", res5)
list1 = res6.split("\n")
if len(list1[2]) > 3:
del list1[2]#删除初次评价
del list1[-1]#删除顾客名字
if len(list1) > 4:#判断该顾客是否是超级会员,是的话就删掉
del list1[-1]
try:#让评论在列表的第一项
if isinstance(eval(list1[0]), float):
list1[0], list1[1] = list1[1], list1[0]
except:
pass
return list1
def deal_data_again(contents):
for content in contents:
content.append(content[-1][:2])
content.append(content[-2][-1:])
return contents
def save_to_csv(contents):
with open('underwear_info.csv', 'w', newline='', encoding='utf_8_sig')as f:
csv_writer = csv.writer(f)
csv_writer.writerow(["评论", "日期", "颜色", "尺码", "下胸围", "罩杯"])
csv_writer.writerows(contents)
print("数据录入成功!!!")
if __name__ == '__main__':
url = "https://detail.tmall.com/item.htm?id=17568465508&ali_refid=a3_430583_1006:1104111323:N:q0napovGLPrB8Dfa089ENfL6YEZwgUBp:2a574904899e290ad05c9915fb0465d6&ali_trackid=1_2a574904899e290ad05c9915fb0465d6&spm=a230r.1.14.3"
url2 = "https://www.taobao.com/"
driver = webdriver.Chrome()
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
})
driver.get(url2)
driver.find_element_by_css_selector("#q").send_keys("文胸")
driver.find_element_by_css_selector("#J_TSearchForm > div.search-button > button").click()
wait = WebDriverWait(driver, 20)
# 设置判断条件:等待id='kw'的元素加载完成
button = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '#J_Itemlist_TLink_14298752380')))
button.click()
driver.switch_to.window(driver.window_handles[1])#切换标签页
css_str = "#J_Reviews > div > div.rate-grid > table > tbody > tr:nth-child({0})"
css_str2 = "#J_Reviews > div > div.rate-page > div > a:nth-child({0})"
contents = []
for i in range(20):#页数循环s
if i > 0:
for k in range(20, 50):#缓慢向下滚动页面
driver.execute_script('window.scrollBy(0,{0})'.format(10 * k))
time.sleep(0.5)
else:
for k in range(20, 200):#缓慢向下滚动页面
driver.execute_script('window.scrollBy(0,{0})'.format(10 * k))
time.sleep(0.5)
for j in range(1, 21):#评论循环
str = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, css_str.format(j)))).text
content = deal_data(str)
contents.append(content)
print(content)
if i <= 5:
element1 = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, css_str2.format(i + 6))))
driver.execute_script("arguments[0].click();", element1)
else:
element1 = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, css_str2.format(11))))
driver.execute_script("arguments[0].click();", element1)
contents = deal_data_again(contents)
save_to_csv(contents)将爬取数据可视化
写在最后
问答
Q : 为什么想要去做这么一个数据分析呢?
A : 是因为最近发现了一个名叫pyecharts的可视化库,我觉得它画图画的很好看,所以想学习一下。然后又在和鲸社区上看到了一篇,关于对淘宝文胸数据的可视化分析,我觉得很有趣,然后就想试一试。
Q : 为什么就爬了400条数据?
A : 有一个原因是,淘宝好像对我进行了浏览限制,翻页翻到一半的时候就不让我翻了,老是让我休息休息hhh
Q : 你这爬取数据的代码咋看起来这么拉垮?
A : 一是因为我好久没写python了。
二是因为我也是个半吊子,没有正规标准的学这门语言,总之就是基础有点差哈哈哈哈,没记住过啥东西,一般想到啥写啥,不会写了或者有问题了一般都会上网解决。
所以大家轻点喷,有啥建议我会虚心接受,谢谢谢谢!
参考链接
因为那些个可视化的代码基本上都是照搬过来的,就改了一些数据源,以及解决了一些跳出来的问题。因为一方面我刚刚开始看这个库,另一方面我觉得我写不出他那样的效果,而且我觉得他也做的蛮好看的然后就拿过来了hhhh
https://www.heywhale.com/mw/project/5ee5033271a691002d55267d
下面那个是关于pyecharts这个库的详细用法,以及一些例子
https://www.heywhale.com/mw/notebook/600c3b03e455800015b9a7e5

 浙公网安备 33010602011771号
浙公网安备 33010602011771号