

基于 Eclipse 的 MapReduce 开发环境搭建
文 / vincentzh
原文连接:http://www.cnblogs.com/vincentzh/p/6055850.html
上周末本来要写这篇的,结果没想到上周末自己环境都没有搭起来,运行起来有问题的呢,拖到周一才将问题解决掉。刚好这周也将之前看的内容复习了下,边复习边码代码理解,印象倒是很深刻,对看过的东西理解也更深入了。
目录
1、概述
Hadoop提供了Java的API用于处理程序的开发及,同样的,通过在本地搭建熟悉的 eclipse 开发环境也能够方便大型程序的开发与调试,完成的代码无需部署,通过eclipse就能执行并输出结果,通过抽样数据的处理结果查看方便调试与验证数据处理逻辑。代码处理逻辑验证无误后,即可将所有程序打包上传至集群,进行全集数据的处理工作。
在搭建开发环境之前,需要部署好自己的Hadoop环境,这样做起来才会比较真实,并且集群的调度及参数配置也是与大型集群的配置维护几乎没什么差别(Hadoop环境的搭建详见:Hadoop单机/伪分布部署、Hadoop集群/分布式部署)。
一般通过单机单机和伪分布环境来开发和调试程序,在单机环境下使用的是本地的文件系统,能够利用 linux 命令方便获取和查看代码的执行结果,相反,在伪分布和集群环境上,代码直接从HDFS读取并输出数据,相较于本地环境需要将数据在本地和HDFS之间 put/get ,麻烦不少,开发调试程序过程都使用的是数据的抽样,否则代码执行一次的时间过长,在单机和伪分布环境验证无误后才会将代码部署上集群进行全集数据的处理。LZ在虚拟上部署了两套环境,一个是伪分布环境、另一个是一个小的集群,当然单机/伪分布/集群之间可以互相切换,但自己部署的环境,为了互相切换麻烦,就干脆两套环境都搭了起来,需要再那个环境执行,直接通过开发环境进行连接切换即可。
2、环境准备
1)配置集群并启动所有守护进程,集群搭建见:Hadoop单机/伪分布部署、Hadoop集群/分布式部署。
2)安装eclipse,本地安装与集群上同一版本的 JDK 和 HADOOP。
3、配置插件
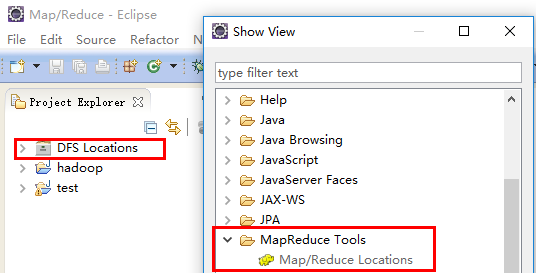
下载 Hadoop2.x-eclipse-plugin.jar,将其放入 eclipse 的 \plugins 目录,并重启 eclipse,在 Windows—>Show View—>Other 将会看到有 Map/Reduce 视图,同时左侧工程空间出现 DFS Locations 类似文件夹的东西。
4、配置文件系统连接
切换至 Map/Reduce 视图,进行配置。

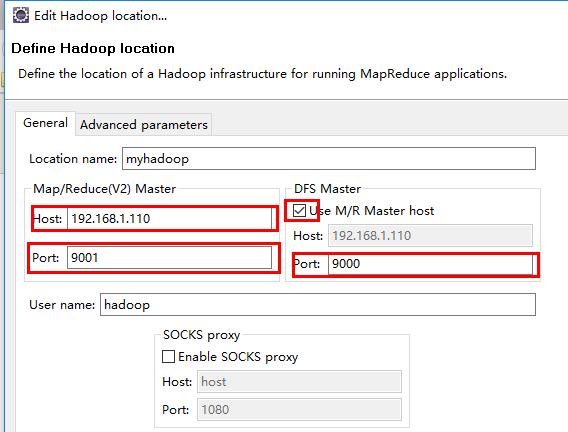
在这里的配置需要注意,要与自己集群上的 core-site.xml 配置文件中的配置一致。附上LZ配置文件的配置。当然有人在 Host 中直接写的主机名,但要主义主机名与IP的映射关系是直接写在HADOOP环境中的,这里的本地环境根本无法解析你写进去的‘master’或者‘hadoop’之类的主机名称,最简单直接的就是用IP去配置,core-site.xml 配置文件中也使用 IP 进行配置。

5、测试连接
配置完成测试连接,需要确认所有守护进程启动无误。

6、代码编写与执行
测试代码可以自己尝试去写,如果只是过过环境搭建成功的瘾,就去官网直接拿吧。链接在这里。
当你需要编写代码或 copy 代码时又会遇到这样的问题,工程工作区为何没有 MapReduce 开发相关的包呢,MapReduce 开发的包要去哪里找呢,就在这里。
代码测试之前,新建的工程中并没有 MapReduce 开发需要使用到的相关 jar 包,这就是前面提到的需要在 Windows 本地安装同样版本 Hadoop 的原因了,这里会用到其安装目录中开发编译 MapReduce 程序时需要的 jar 包。在 Windows—>Preferences—>Hadoop Map/Reduce 中设置 Windows 本地安装的Hadoop路径(如:E:\ProgramPrivate\hadoop-2.6.0),设置完成再去创建 Hadoop 工程时会自动导入 Hadoop 相关的 jar 包。
我就贴个通过 API 提供的一些常用的基本实现类去实现的 WordCount 代码吧,具体的参数配置可以参考。
1 package com.cnblogs.vincentzh.hadooptest; 2 3 import java.io.IOException; 4 5 import org.apache.hadoop.conf.Configuration; 6 import org.apache.hadoop.fs.Path; 7 import org.apache.hadoop.io.LongWritable; 8 import org.apache.hadoop.io.Text; 9 import org.apache.hadoop.mapred.FileInputFormat; 10 import org.apache.hadoop.mapred.FileOutputFormat; 11 import org.apache.hadoop.mapred.JobClient; 12 import org.apache.hadoop.mapred.JobConf; 13 import org.apache.hadoop.mapred.lib.LongSumReducer; 14 import org.apache.hadoop.mapred.lib.TokenCountMapper; 15 16 // 通过 Hadoop API 提供的基本实现类实现 WordCount 17 public class WordCount2 18 { 19 public static void main(String[] args) 20 { 21 //JobClient client = new JobClient(); 22 Configuration conf = new Configuration(); 23 JobConf jobConf = new JobConf(conf); 24 25 jobConf.setJobName("WordCount2"); 26 Path in = new Path("hdfs://192.168.1.110:9000/user/hadoop/input"); 27 Path out = new Path("hdfs://192.168.1.110:9000/user/hadoop/output"); 28 FileInputFormat.addInputPath(jobConf, in); 29 FileOutputFormat.setOutputPath(jobConf, out); 30 jobConf.setMapperClass(TokenCountMapper.class); 31 jobConf.setCombinerClass(LongSumReducer.class); 32 jobConf.setReducerClass(LongSumReducer.class); 33 jobConf.setOutputKeyClass(Text.class); 34 jobConf.setOutputValueClass(LongWritable.class); 35 36 //client.setConf(jobConf); 37 try 38 { 39 JobClient.runJob(jobConf); 40 } 41 catch (IOException e) 42 { 43 e.printStackTrace(); 44 } 45 } 46 }
执行完成,会有相应的作业执行统计信息输出,Refresh 文件夹后会在左侧 DFS 文件系统中看到输出的文件。

7、问题梳理
运行时可能会出现不少问题,在这里只罗列下LZ遇到过的问题和解决的方法,没遇到的自然也谈不上和路人分享了。
7.1 console 无日志输出问题
在 eclipse 执行 MapReduce 程序时会出现程序控制台无任何输出信息的问题,没有日志信息,没有执行信息,无法知道程序执行的结果如何。
原因:console无日志输出是因为在 project 中没有进行 log 配置。
解决方案:直接将 hadoop 配置文件目录($HADOOP_HOME/etc/hadoop/)下的 log4j.properties 文件 copy 进工程中即可。
7.2 权限问题
在 eclipse 执行 MapReduce 程序报错,错误信息类似:org.apache.hadoop.security.AccessControlException:org.apache.hadoop.security.AccessControlException: Permission denied:user=john, access=WRITE, inode="input":hadoop:supergroup:rwxr-xr-x...
原因:Hadoop 上的 HDFS 只有部署环境时的用户才有读写权限,大多数人应该都使用的是 ‘hadoop’ 吧,而我们的开发环境是在 Windows 本地进行搭建的,执行程序的时候是直接用本地的用户进行作业的提交和执行,Hadoop 在提交作业和执行作业时需要对提交的用户进行权限认证,自然 Windows 上的用户并没有读写 HDFS 文件和提交并执行作业的权利了。
解决方案:在 mapred-site.xml 配置文件中设置属性 dfs.permission 为 false 即可。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号