

04>>>模拟用户登录、request其他方法补充
今天开始就要进入激动人心的部分了。
cookie与session

随着时代的发展,网页能展示的东西越来越多,功能越来越强,网民群体也越发茁壮起来。这时候的网络社区就有草根交流的需求,想要交流就必须在各个门户站点注册用户了。
登录账号的原理是这样的:
1.当用户第一次登录网站,需要输入用户名和密码。
2.浏览器会将用户名和密码保存在本地。
3.下一次再登录同一个网站时,浏览器会自动帮用户输入用户名密码。
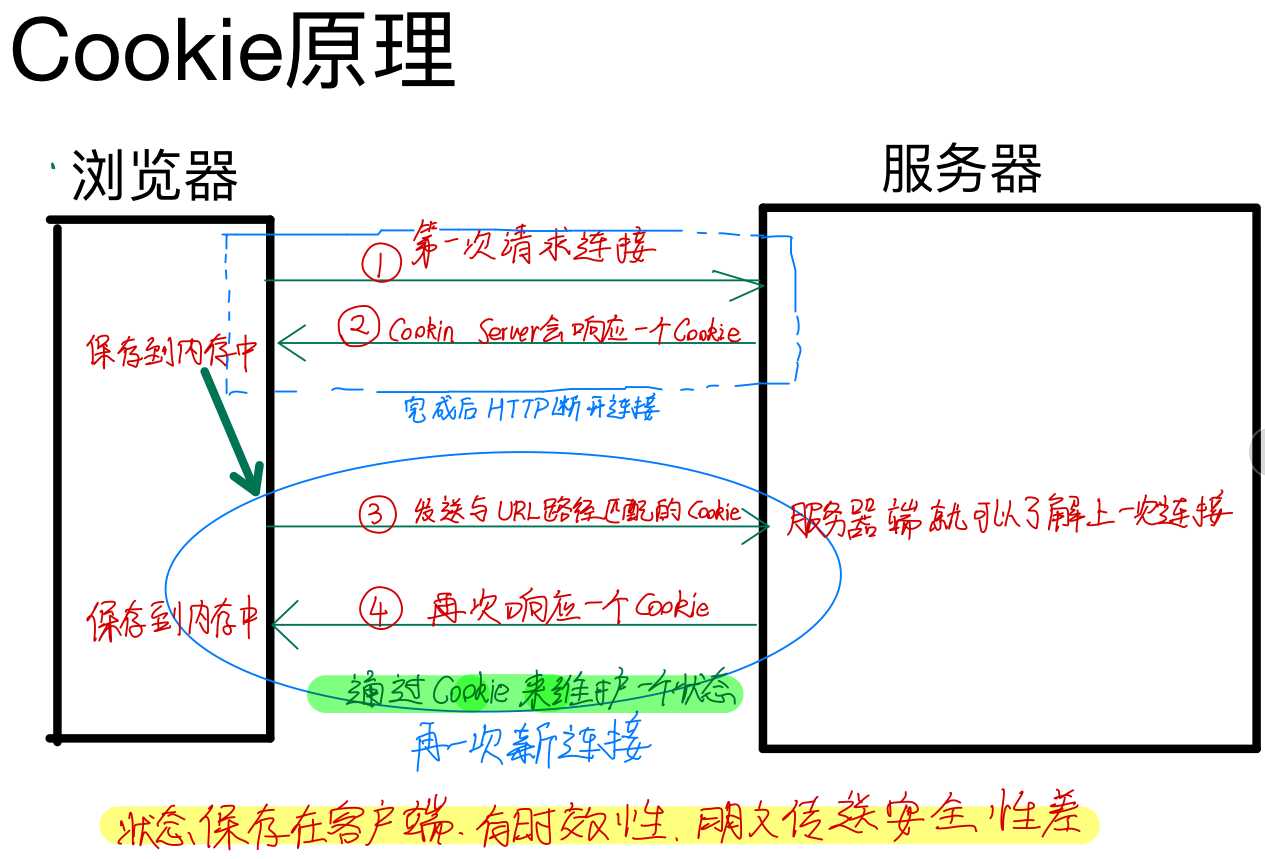
保存在客户端浏览器内的键值对数据,就被称作cookie。
cookie:保存在客户端浏览器内的键值对数据。
cookie可以看做是进公司上班,每次上工都需要在签到表上填写自己的工作证号并签名。
浏览器会把不同网站的用户名密码建立不同的cookie,在登录不同网站时选用相应的cookie就行了。
但是cookie存在一个重大缺陷:
如果直接把用户名密码保存在本地的浏览器内,会有很大的安全隐患。
于是出现了一种改进方法:
在用户第一次登陆成功之后,服务端会返还给客户端一串随机字符串(有时候也可能是多个),客户端保存该随机字符串。以后再登录时客户端只需要提交这段字符串就可以了。
这相当于公司给员工办理一张门禁卡,以后进出公司就不需要填表,日常打卡就可以了。
这种方法被称为session。
session:保存在服务端上面的用户相关数据。
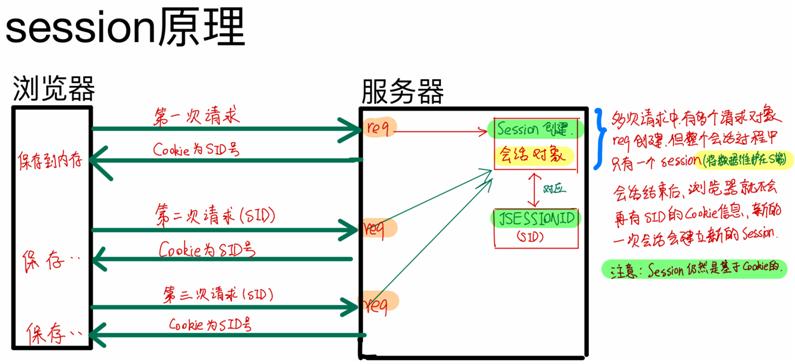
然而这样还是有隐患的:如果门禁卡被人偷了,他就可以进入公司了。session要是被人知道了,也一样可以登录你的账号。
cookie和session是什么关系?
session需要依赖cookie,只要是涉及到用户登录的操作都需要使用到cookie。
当然,浏览器也可以拒绝保存用户数据。
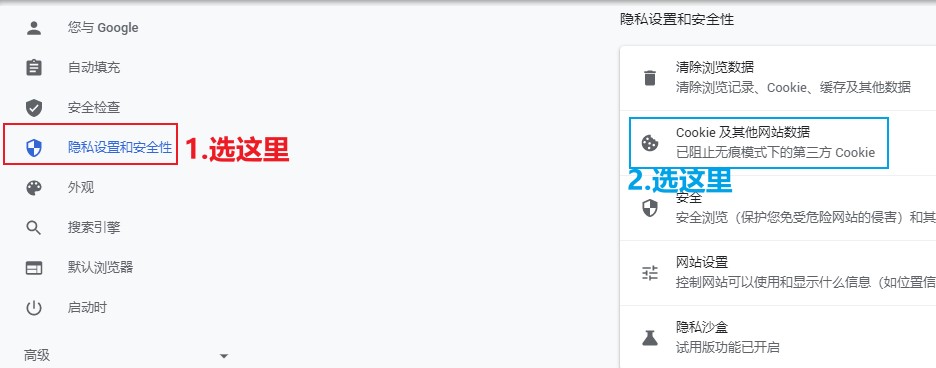
拒绝保存Cookie
(以chrome为例)只要在浏览器中点击设置,随后在隐私设置和安全性选项卡中选择Cookie及其他网站数据,随后选择阻止所有Cookie即可。
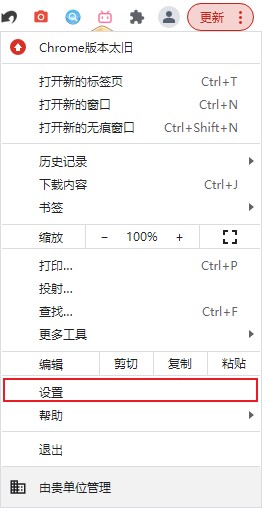
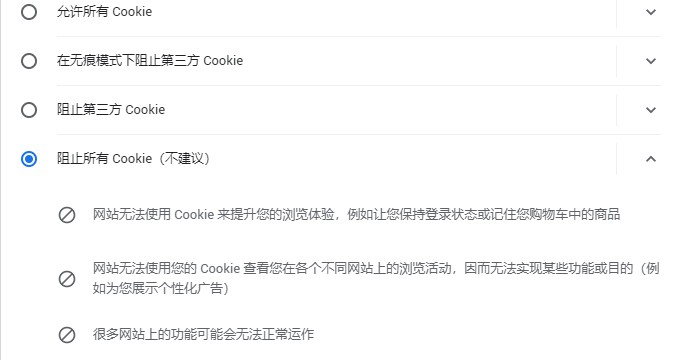
注意:选择阻止所有Cookie的话会把现在浏览器中正在运行的网页所对应的Cookie也清除掉,要求用户登录使用的网站会把你踢出去。
一般不推荐使用阻止所有Cookie,因为这样不便于使用各家的网站。选择允许所有Cookie或者在无痕模式下阻止第三方Cookie就可以了。
查看Cookie
想要查看Cookie,也很简单:在网页中右键选择检查然后点击Network,通常只需要打开第一个文件,就能在请求头里找到cookie。
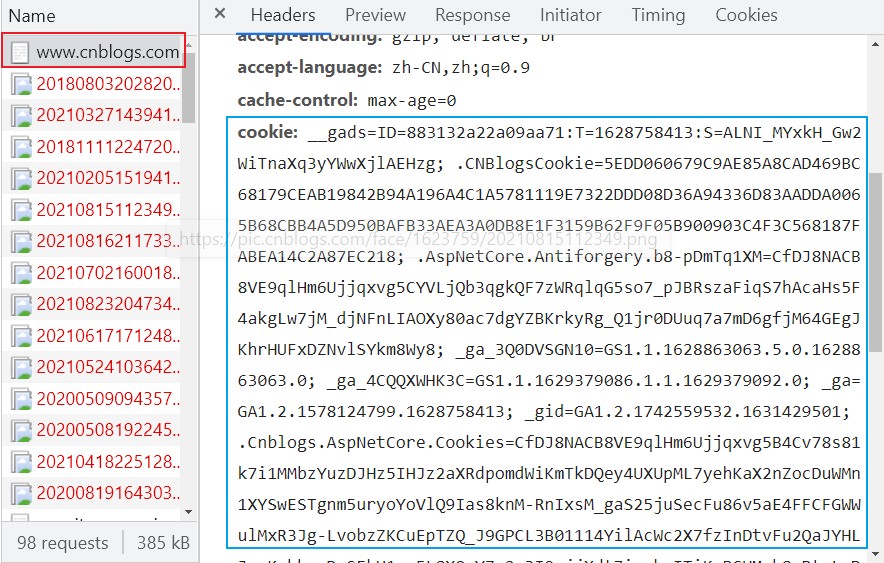
如果删除cookie,就相当于门禁卡丢失了。想要重新用门禁卡(session)进出公司,就需要用员工证(cookie)去重新补办。
代码模拟用户登录
这次用pycharm来看看能不能携带cookie实现登录注册。
方法:写爬虫程序时,一定要先用浏览器登录一遍。
1.研究登录数据提交给后端的url地址
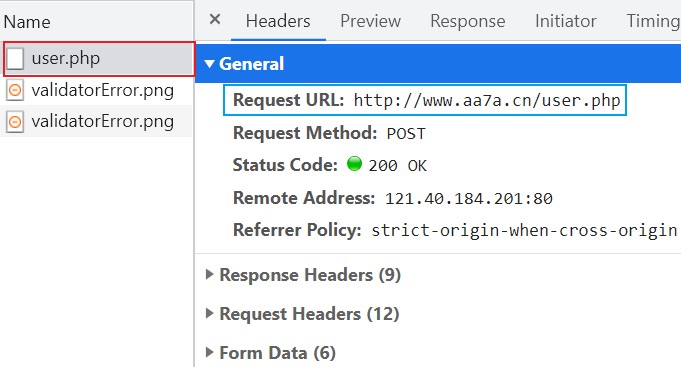
首先在网站的登录界面中右键点击检查,选择Network选项卡。
然后随便写个用户名密码假意登录一下,Network里瞬间出现了一堆文件,我们只要看叫user.php的那个文件。
选中文件后我们可以在General中看到Request URL键值对,这后面的网页地址就是浏览器发出post请求的目标地址。
2.研究登录post请求携带的请求体数据格式
现在来看看最下方表单数据中有些什么收获。
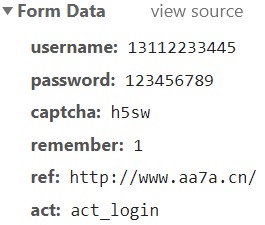
可以看到,我选用的这个网站安全性不够高,可以直接看到用户名和明文密码,但这也方便了我们学习。
将这些数据都复制下来,一会就要用到。
3.模拟发送post请求
现在用户名、密码、验证码等等数据都拿到了。只要将它加入到程序里就可以用程序实现登录账户功能了。
我们可以把这些登录注册需要的数据做成一个字典方便程序读取,而这个字典在requests模块中专门有一个参数叫做data。
我们先来试一下能不能成。
import requests res = requests.post('http://www.aa7a.cn/user.php', data={ 'username':'13112233445' , 'password':'123456789', 'captcha':'h5sw', 'remember':'1', 'ref':'http://www.aa7a.cn/', 'act':'act_login' } # data参数携带请求体数据 )
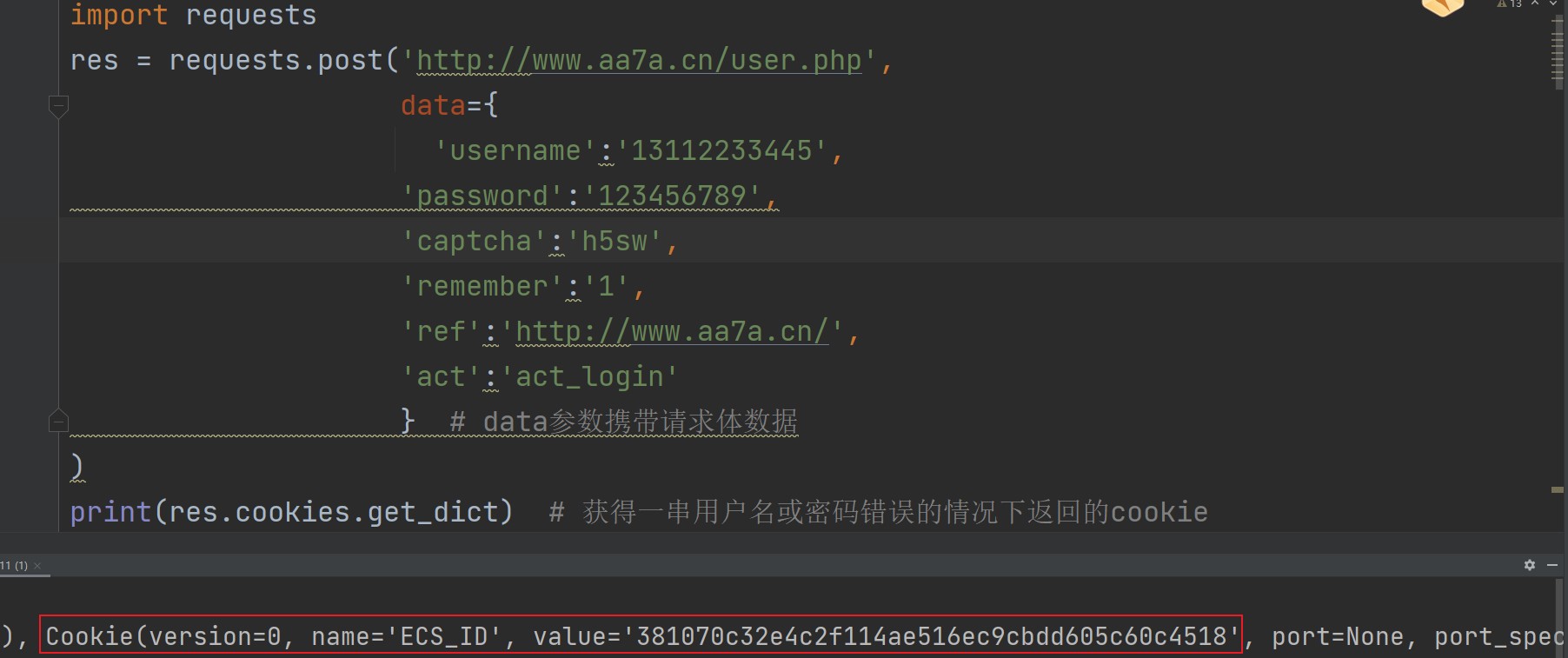
现在显示的是用户名或密码错误时服务器返回的cookie。
接下来登录正确的用户名密码然后获取cookie,然后保存为一个字典。
user_cookie =res.cookies.get_dict()
然后完善后续的步骤,看看用代码可否实现用户注册登录。
res1 = requests.get('http://'www.aa7a.cn/user.php,
cookies=user_cookie
) # 使用cookie访问网站
if '用户名(输入真实的用户名,别照抄)' in res1.text: # 如果用户名可以在res1网页字符串数据内获取到
print('登录身份访问')
else: # 否则
print('coockie存在错误')
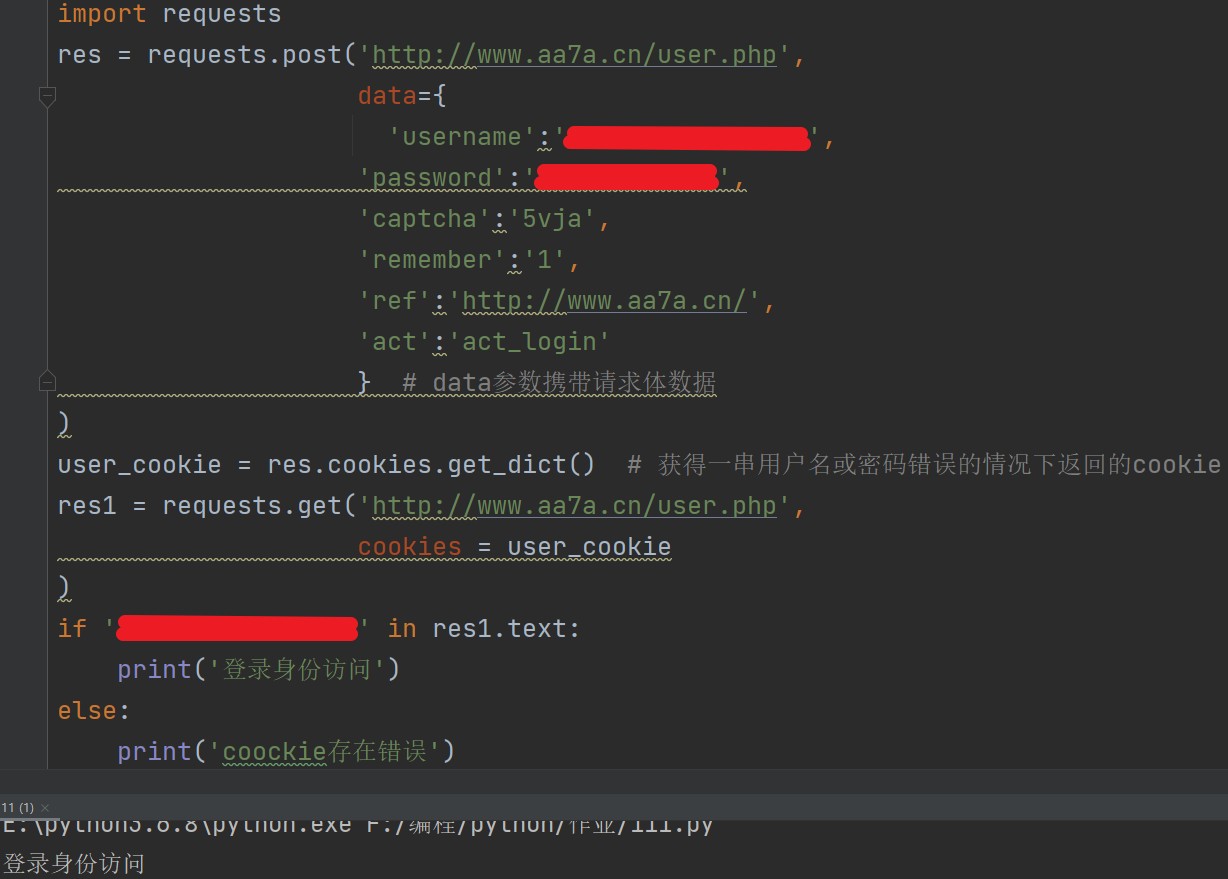
这样一来就可以证明,账号登录成功了。
不过需要注意,有时候网站工程师也会暗中下套。发出post请求可能会暗中返回好几个加密过的cookie,把我们拖入一场持久的阵地战中。
requests其他方法补充
获取大数据
现在学会了爬取数据,想玩点大的,从网上爬取一部10G甚至更大的高清电影。
如果直接用现在所学的方法的话,下载下来的数据会直接把内存撑爆。
需要把视频文件变成二进制流以避免这种惨祸。
import requests response = requests.get('https://www.douyin.com/video/6998765696788303139?previous_page=recommend&tab_name=recommend', stream=True) # 启用二进制流 with open(r'a.mp4','wb') as f: for line in response.iter_content(): # 一行一行读取内容 f.write(line)
json格式数据
在网络爬虫领域,内部其实有很多数据采用的都是json格式。且前后端数据交互一般使用的都是json格式。
再复习一下json格式数据的特点:引号肯定是双引号。
我们以bilibili上一个视频作为例子讲解一下。
首先在B站上随意找一个分集视频,右键点击检查,寻找一个叫pagelist的文件。
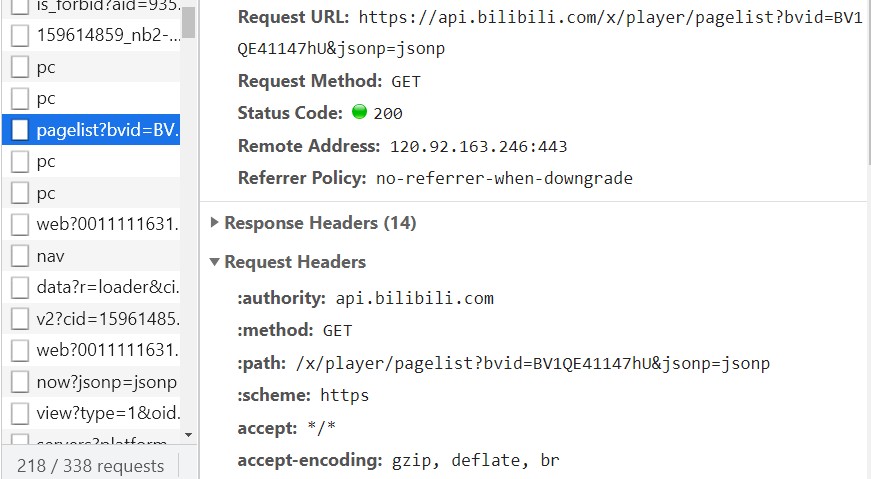
我们知道了Request URL,接下来在pycharm里打开它。
import requests res = requests.get('https://api.bilibili.com/x/player/pagelist?bvid=BV1QE41147hU&jsonp=jsonp') print(res.json()) # 可以直接将json格式字符串转化成python对应的数据类型
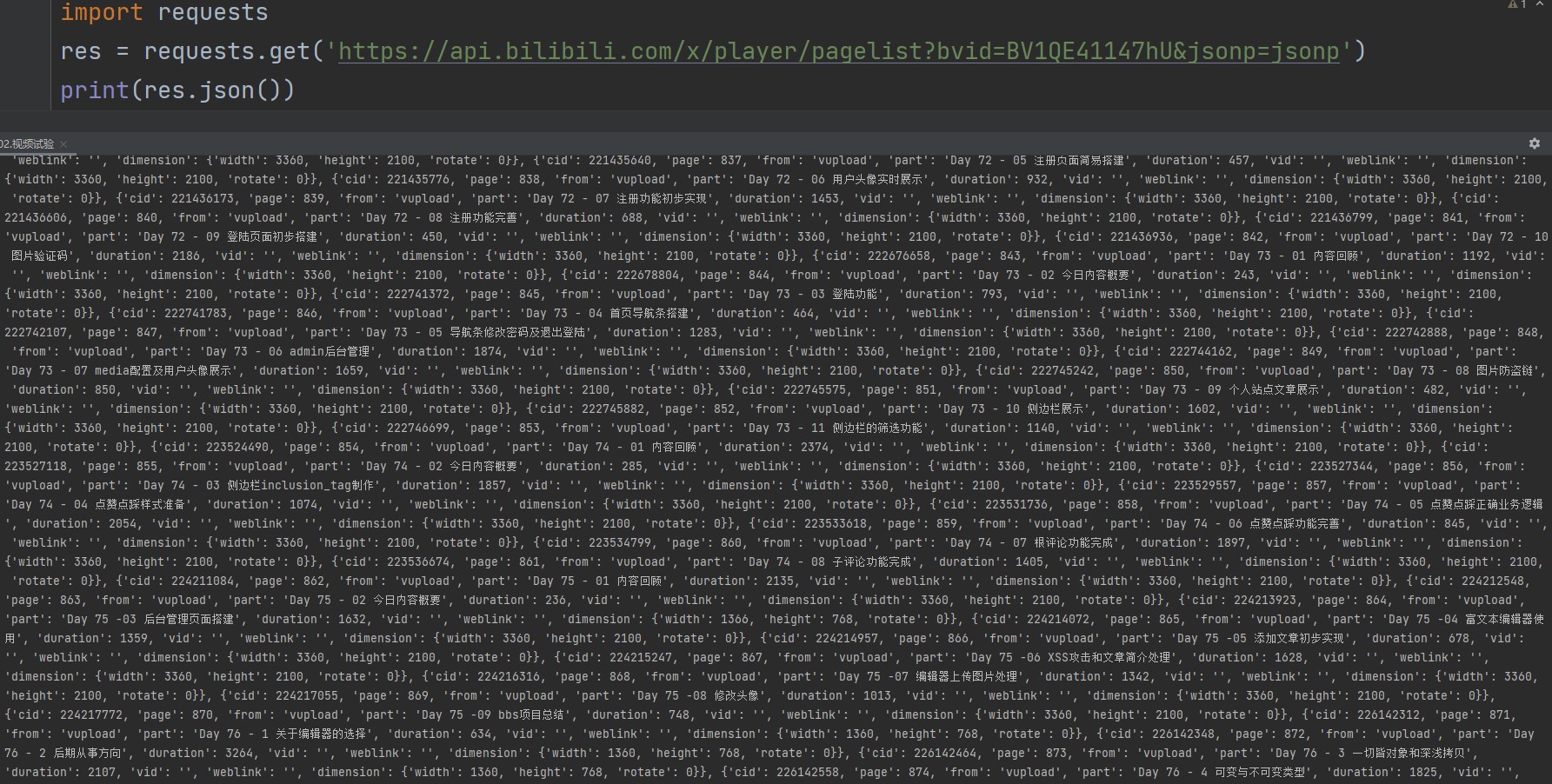
仔细看就能发现,这个文件是以键值对的形式保存的,实际上就是视频的目录。
除了用pycharm,还有一个网站可以帮助我们解析json文件。
json文件解析网站:bejson.com/explore/index_new/
SSL认证(Mac系统常见)
这个问题一般只有苹果用户会碰到。穷逼用不起苹果本,直接百度另寻即可……
ip代理池(高级防爬措施)
还是那个理,网站拥有者都是不希望其他人爬取自己的数据的。
除了各种反爬手段对抗爬虫数据,网站拥有者还可能采取法律武器保护自己。而对于我们来说,就是被对方顺着网线杀上门查水表了……
有很多网站针对客户端的ip地址也存在防爬措施。
比如:一分钟之内同一个ip地址访问该网站的次数不能超过30次,超过了就封禁该ip地址。
那么针对这种防爬措施该如何解决?
方法:狡兔三窟,采用ip代理池。
原理:ip代理池中有很多备用ip地址,每次访问网页时从中随机挑选一个备用ip代替本机ip使用。
使用方法
在网上随便找了几个ip来演示一下。
import requests proxies={ 'http':'114.99.223.131:8888', 'http':'119.7.145.201:8080', 'http':'175.155.142.28:8080', } respone=requests.get('https://www.12306.cn',proxies=proxies) print(respone) # 显示响应
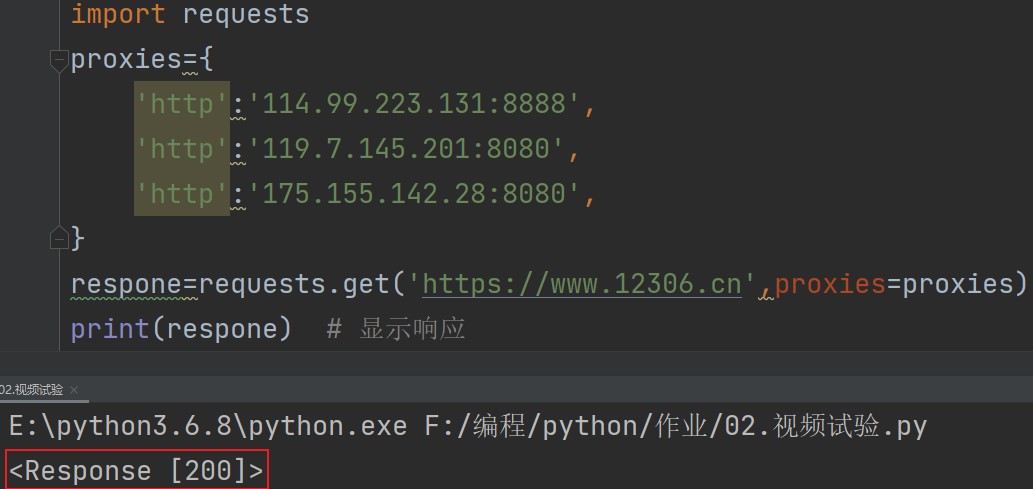
如此一来就能知道ip代理池可以正常运作。
http和https有什么区别?
https更安全。http相当于没穿衣服赤身裸体,https相当于穿了衣服。
注册https网站需要各种合法证件去正规部门(在美国而非中国)办理。
Cookie代理池
原理和ip代理池是一样的。有些反爬措施是通过cookie来判断的。
比如:一分钟之内同一个cookie访问该网站的次数不能超过30次,超过了就封禁该cookie。
那么针对这种防爬措施该如何解决?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号