【【使用keras自带的路透社新闻数据集运行RNN的实例】】
import numpy as np
from sklearn.metrics import accuracy_score
from keras.datasets import reuters
from keras.preprocessing.sequence import pad_sequences
from keras.utils import to_categorical
(X_train, y_train), (X_test, y_test) = reuters.load_data(num_words = 30000, maxlen = 50, test_split = 0.3) //数据集来源于路透社的 11,228 条新闻文本,总共分为 46 个主题。
num_words:整数或None,训练集中我们指保留词频最高的前30000个单词
maxlen: 整数。最大序列长度。 任何更长的序列都将被截断。
test_split: 浮点型。用作测试集的数据比例。
X_train = pad_sequences(X_train, padding = 'post')
X_test = pad_sequences(X_test, padding = 'post') //在长度不足50的序列的后面填补0
X_train = np.array(X_train).reshape((X_train.shape[0], X_train.shape[1], 1))
X_test = np.array(X_test).reshape((X_test.shape[0], X_test.shape[1], 1)) //更改数组形状
y_data = np.concatenate((y_train, y_test)) //训练集和测试集纵向拼接
y_data = to_categorical(y_data)
y_train = y_data[:1395]
y_test = y_data[1395:]
1. Vanilla RNN
from keras.models import Sequential
from keras.layers import Dense, SimpleRNN, Activation
from keras import optimizers
from keras.wrappers.scikit_learn import KerasClassifier
def vanilla_rnn(): //定义vanilla rnn模型
model = Sequential() //序贯模型
model.add(SimpleRNN(50, input_shape = (49,1), return_sequences = False))
//input_shape:即张量的shape。从前往后对应由外向内的维度。
//units: 正整数,输出空间的维度为50。
//return_sequences为布尔值,默认False,控制返回类型。若为True则返回整个序列,否则仅返回输出序列的最后一个输出
model.add(Dense(46))//46为神经元个数(节点数)
model.add(Activation('softmax')) //激活函数为softmax adam = optimizers.Adam(lr = 0.001) //学习率为0.001
model.compile(loss = 'categorical_crossentropy', optimizer = adam, metrics = ['accuracy']) //categorical_crossentropy:亦称作多类的对数损失,注意使用该目标函数时,需要将标签转化为形如(nb_samples, nb_classes)的二值序列
return model
model = KerasClassifier(build_fn = vanilla_rnn, epochs = 20, batch_size = 50, verbose = 1)
//KerasClassifier类使用参数build_fn指定用来创建模型的函数的名称
- batch_size:整数,指定进行梯度下降时每个batch包含的样本数。训练时一个batch的样本会被计算一次梯度下降,使目标函数优化一步。
- epochs:整数,训练终止时的epoch值,训练将在达到该epoch值时停止,训练的总轮数为epochs - inital_epoch(该值默认为0)
- verbose:日志显示,0为不在标准输出流输出日志信息,1为输出进度条记录,2为每个epoch输出一行记录
model.fit(X_train, y_train) // 进行训练
y_pred = model.predict(X_test) // 进行预测
y_test_ = np.argmax(y_test, axis = 1) //返回每行最大值的索引
print(accuracy_score(y_pred, y_test_)) //报告模型得分
//报告结果//
模型的准确度为74.96%
![]()
2.Stacked Vanilla RNN
def stacked_vanilla_rnn():
model = Sequential()
model.add(SimpleRNN(50, input_shape = (49,1), return_sequences = True)) # return_sequences parameter has to be set True to stack
model.add(SimpleRNN(50, return_sequences = False))
model.add(Dense(46))
model.add(Activation('softmax'))
adam = optimizers.Adam(lr = 0.001)
model.compile(loss = 'categorical_crossentropy', optimizer = adam, metrics = ['accuracy'])
return model
model = KerasClassifier(build_fn = stacked_vanilla_rnn, epochs = 200, batch_size = 50, verbose = 1)
model.fit(X_train, y_train)
y_pred = model.predict(X_test) // 进行预测
print(accuracy_score(y_pred, y_test_)) //报告模型得分
//报告结果//
模型的准确度为75.63%
![]()
3. LSTM
from keras.layers import LSTM
def lstm():
model = Sequential()
model.add(LSTM(50, input_shape = (49,1), return_sequences = False))
model.add(Dense(46))
model.add(Activation('softmax'))
adam = optimizers.Adam(lr = 0.001)
model.compile(loss = 'categorical_crossentropy', optimizer = adam, metrics = ['accuracy'])
return model
model = KerasClassifier(build_fn = lstm, epochs = 200, batch_size = 50, verbose = 1)
model.fit(X_train, y_train)
y_pred = model.predict(X_test) // 进行预测
print(accuracy_score(y_pred, y_test_)) //报告模型得分
//报告结果//
模型的准确度为84.47%
![]()
4. Stacked LSTM
def stacked_lstm():
model = Sequential()
model.add(LSTM(50, input_shape = (49,1), return_sequences = True))
model.add(LSTM(50, return_sequences = False))
model.add(Dense(46))
model.add(Activation('softmax'))
adam = optimizers.Adam(lr = 0.001)
model.compile(loss = 'categorical_crossentropy', optimizer = adam, metrics = ['accuracy'])
return model
model = KerasClassifier(build_fn = stacked_lstm, epochs = 200, batch_size = 50, verbose = 1)
model.fit(X_train, y_train)
y_pred = model.predict(X_test) // 进行预测
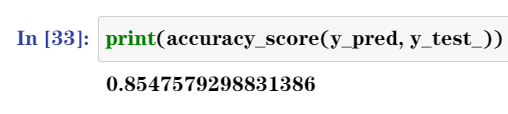
print(accuracy_score(y_pred, y_test_)) //报告模型得分
//报告结果//
模型的准确度为85.48%
![]()





 浙公网安备 33010602011771号
浙公网安备 33010602011771号