
清华大学刘洋--基于深度学习的机器翻译(1)
<----- 1980 2013----------->
基于规则的机器翻译 基于统计的机器翻译 基于神经网络的机器翻译
——————————————————————————————————————
平行语料库
数据驱动的机器翻译
短语的切分、调序
统计机器翻译的优缺点:

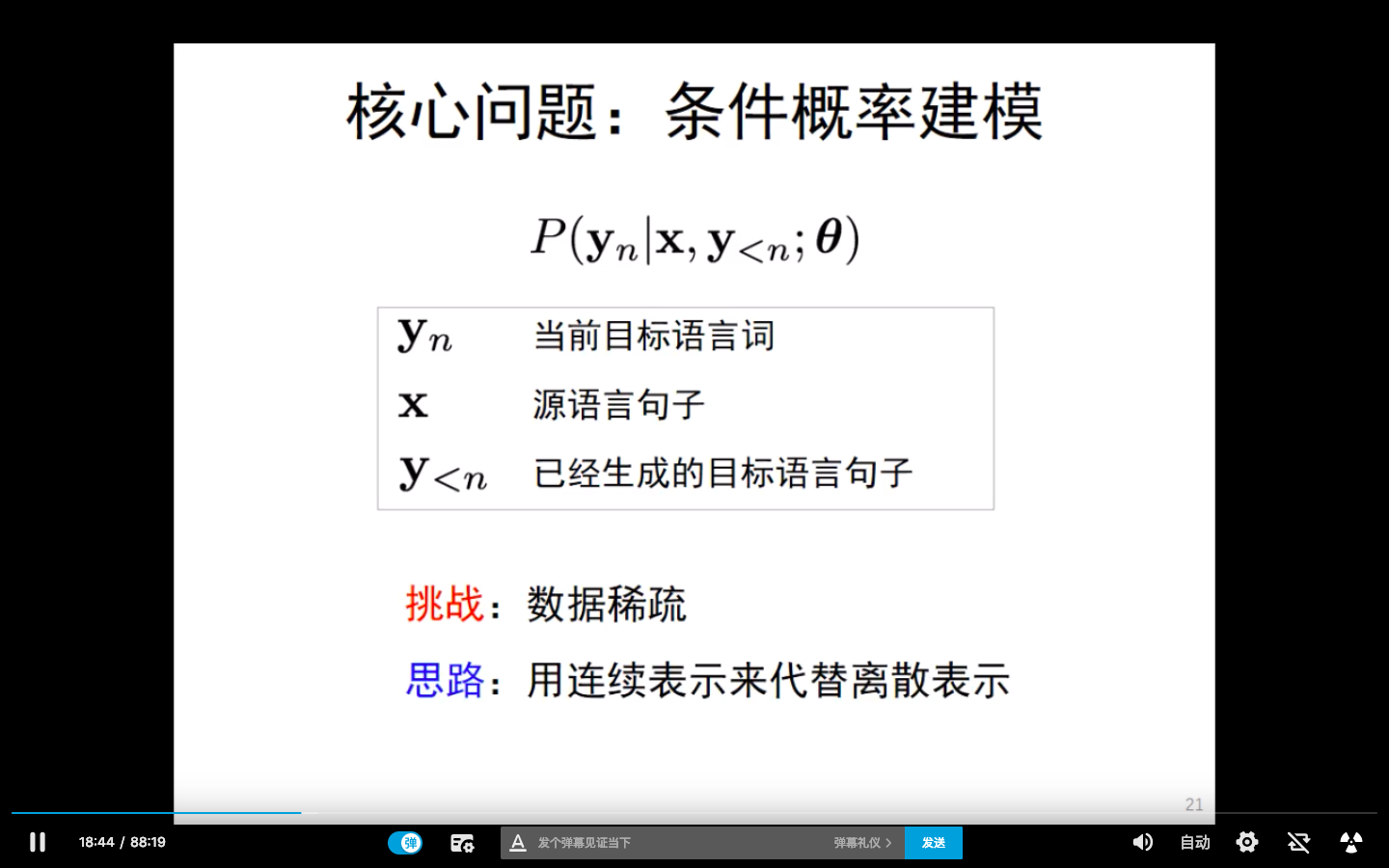
然而,用神经网络进行建模,核心思路:用连续替代离散。
RNN 进行句子向量表示
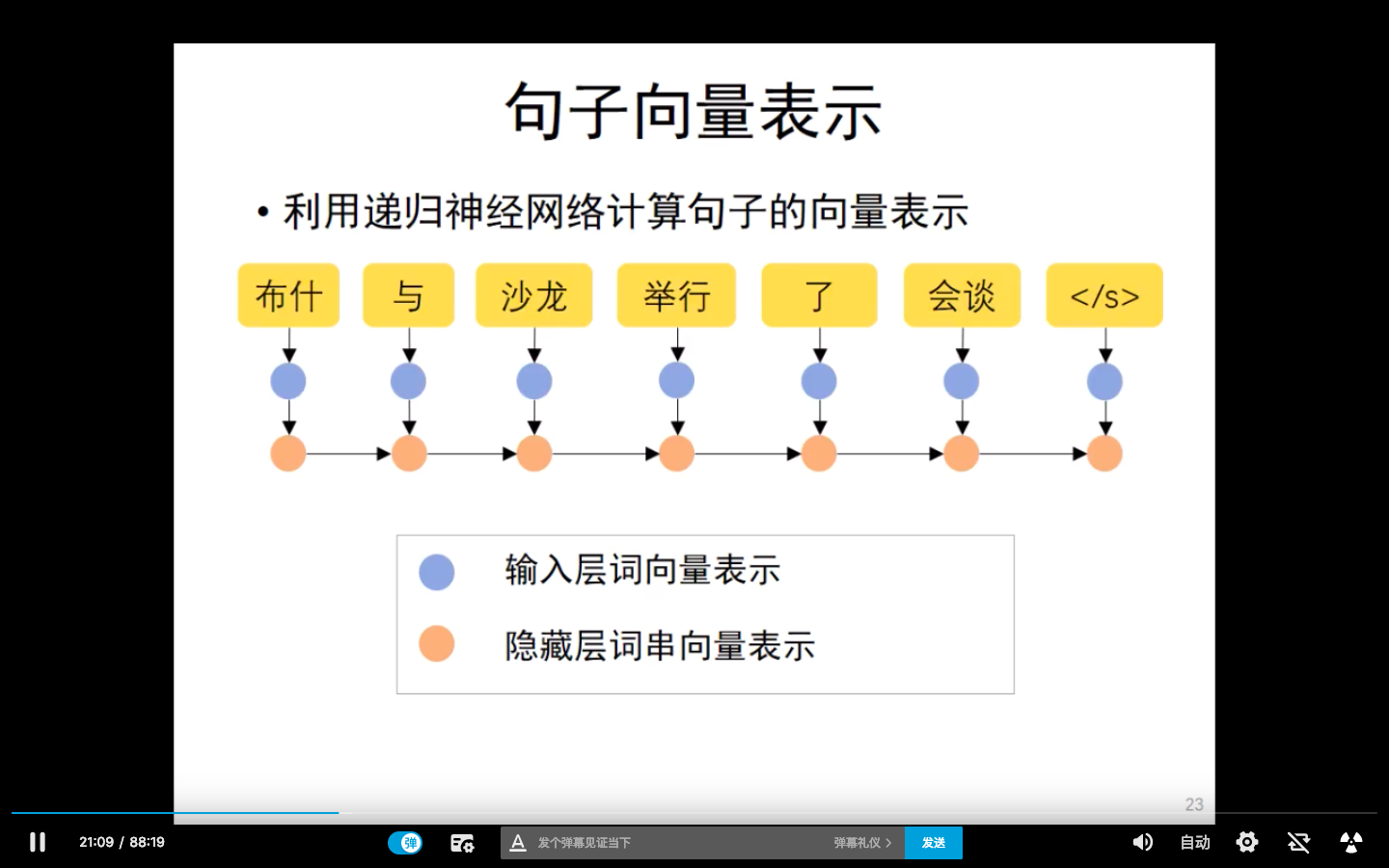
hidden layer的最后一个神经元包含了这个句子所携带的所有信息,听起来特别的荒诞,但是就是好用啊。
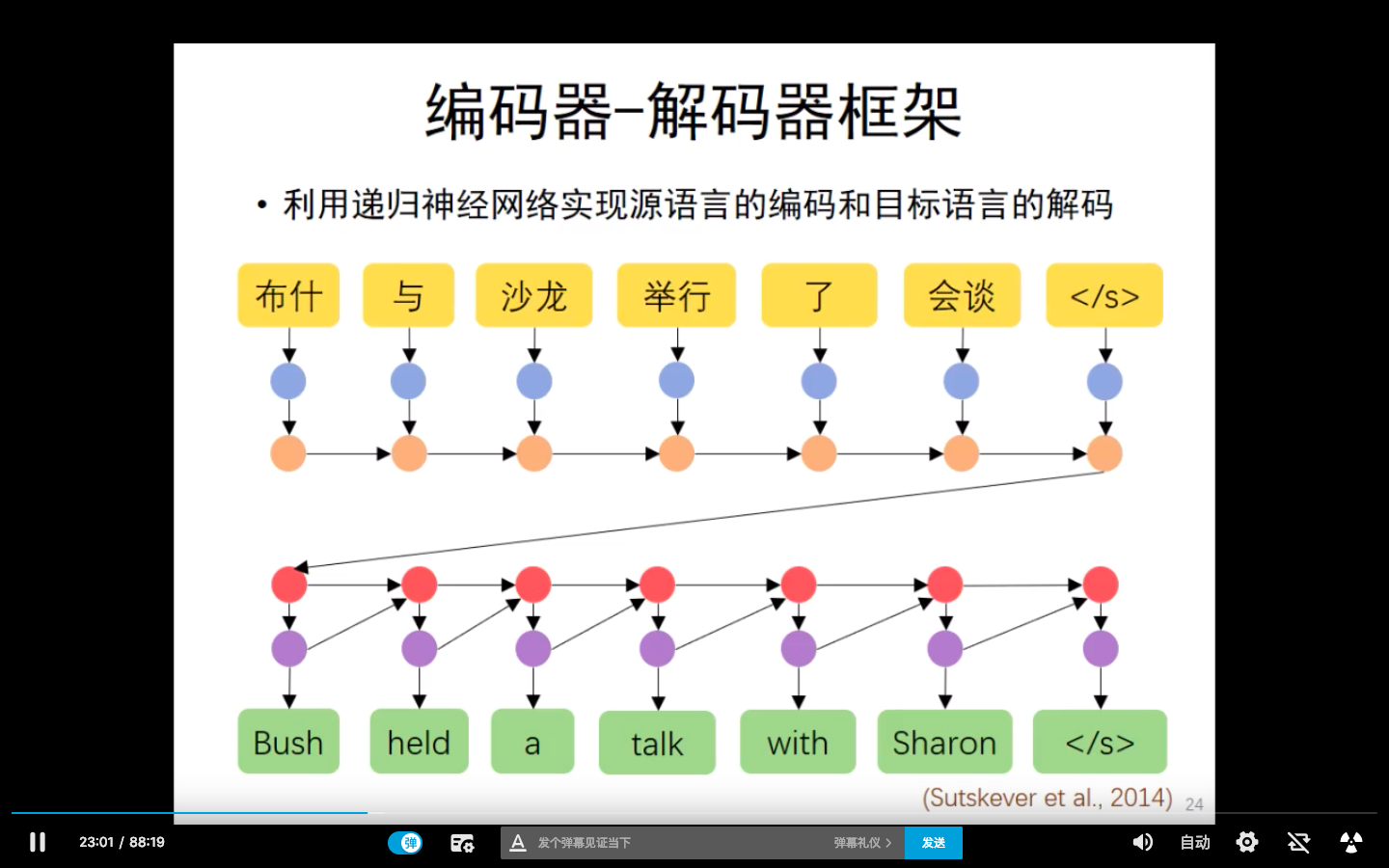
这时再用decoder解码器进行解码
那么,递归神经网络进行机器翻译,有哪些优缺点呢?
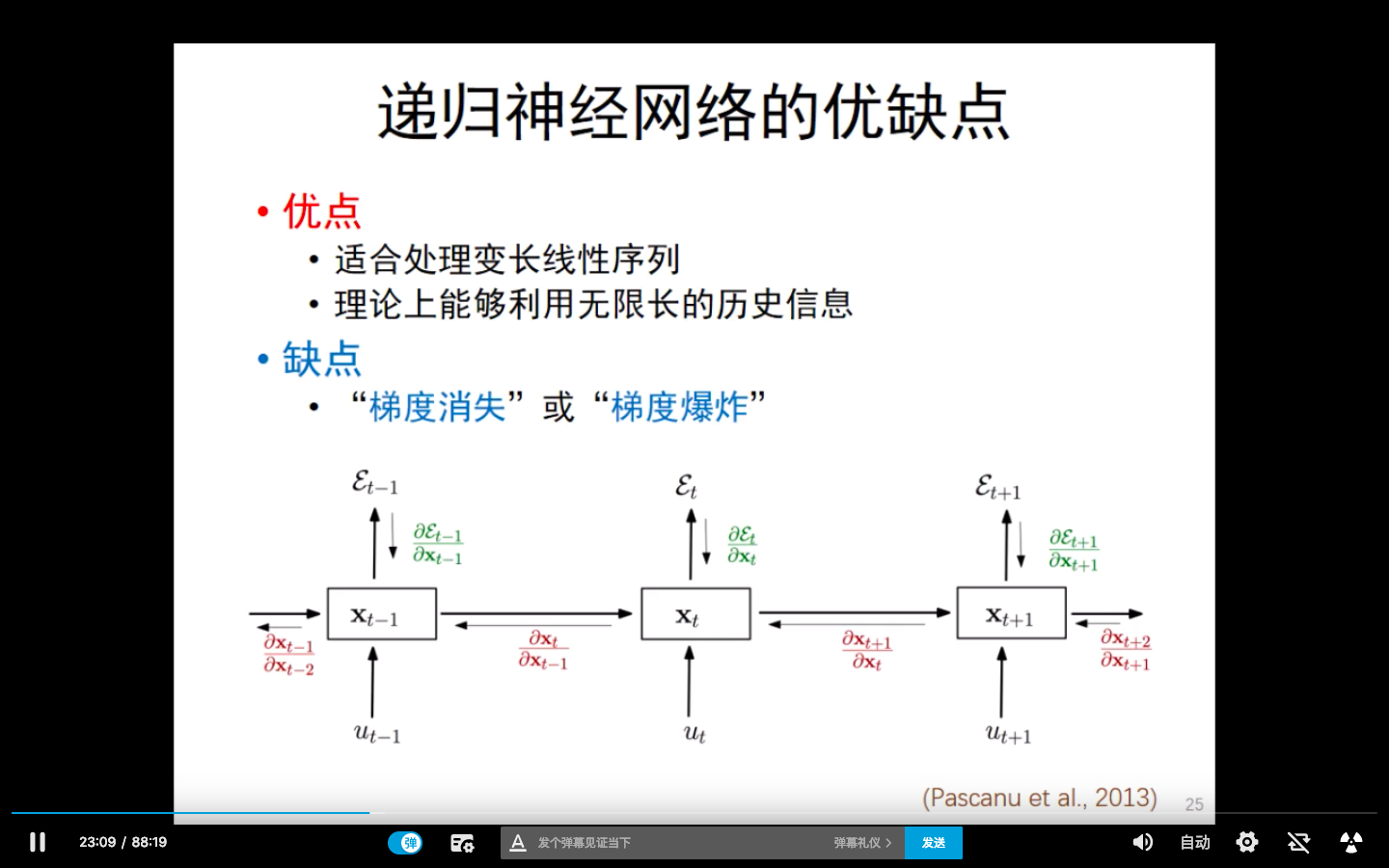
这时,为了解决“梯度消失”或者“梯度爆炸”的问题,就引入了LSTM。LSTM,引入了“input gate”" forget gate" "output gate"。

我们的神经网络学习到了什么呢?谷歌到研究人员做了一些可视化的工作。说明,神经网络来进行机器翻译,还是有一定的效果的。

但是,编码器-解码器架构存在缺点,即(个人理解)在解码过程中的神经元是黑盒的,可解释性很低。
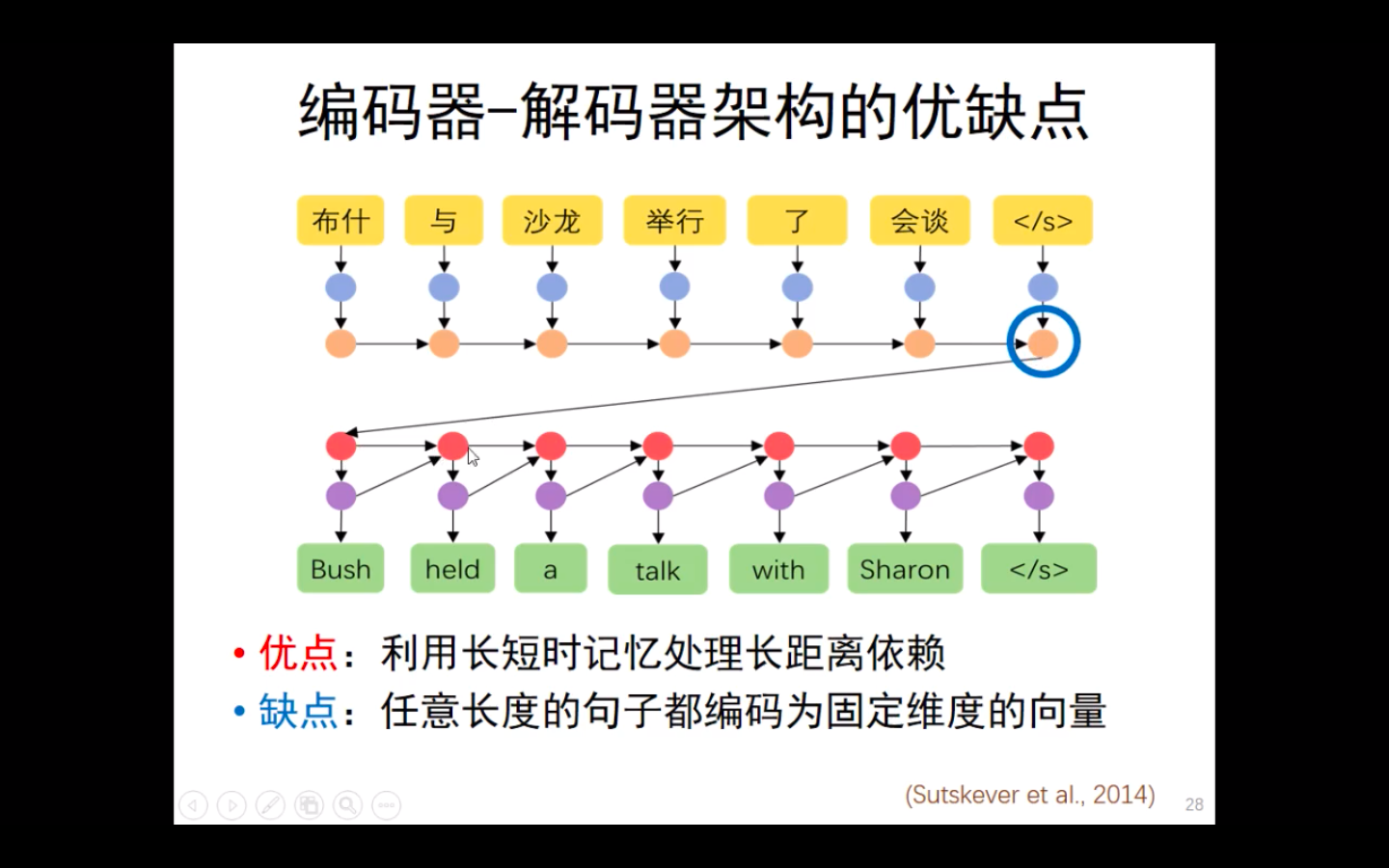
在这种情况下,注意力机制横空出世。
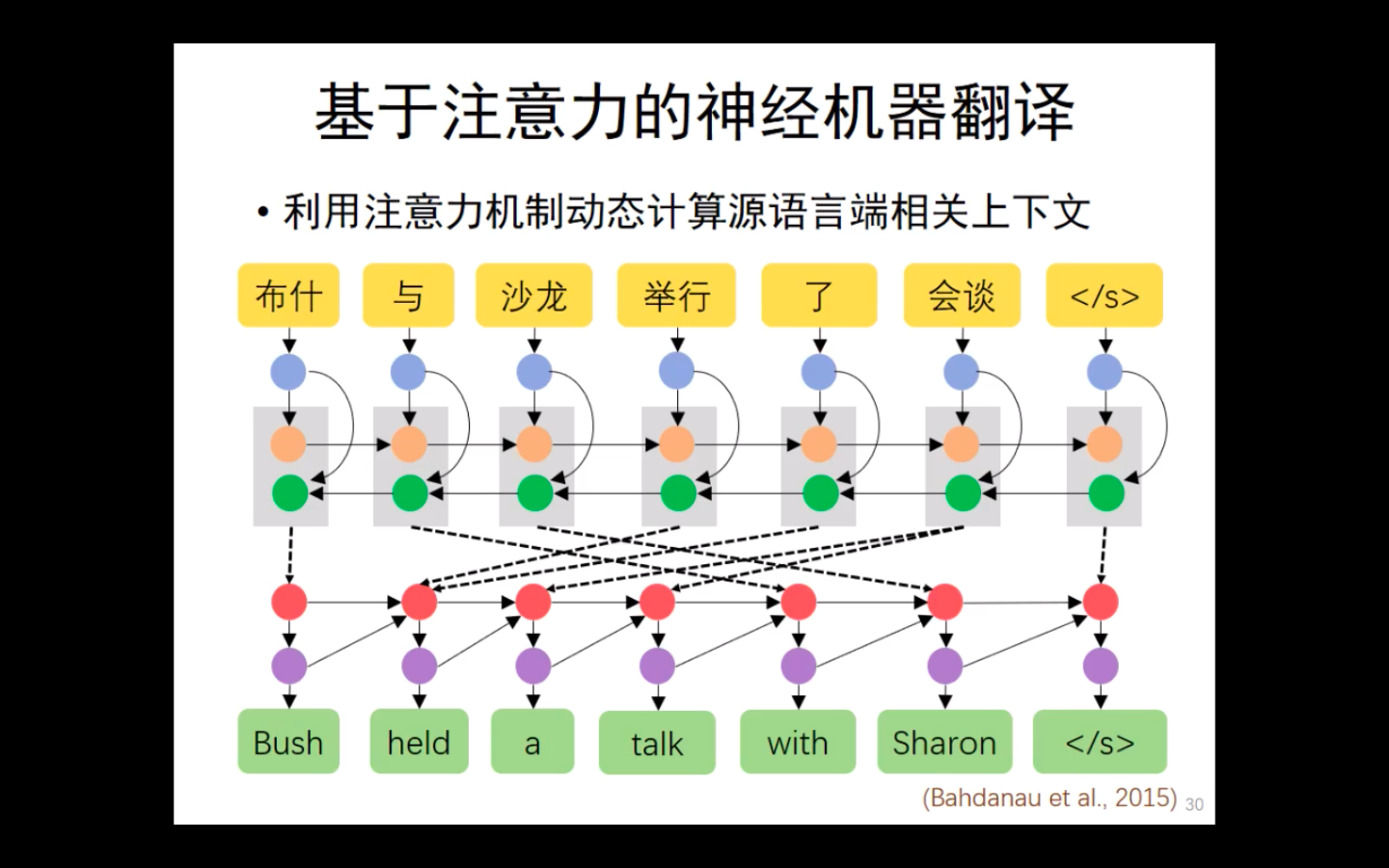
其核心思想是:集中关注相关的上下文。

注意力机制是怎么回事呢?
首先,进行一步双向的RNN,双向RNN的好处时,每一个单词都可以获得一个自己全局的地位。

再根据每个词的重要程度,动态地生成下一个词。
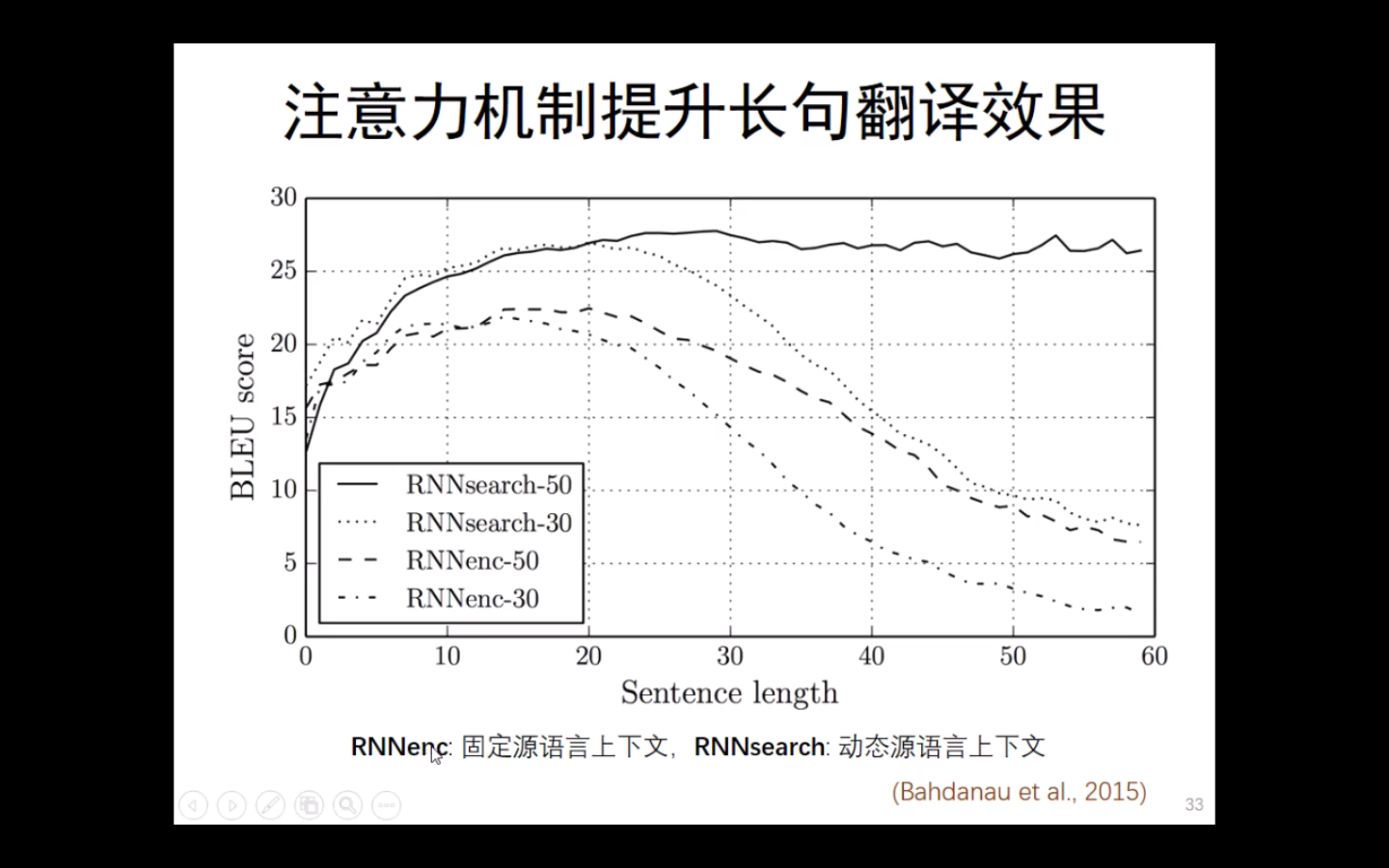
注意力机制能够有效的提升长句的翻译效果,LSTM是固定原语言的生成,而注意力是动态原语言生成
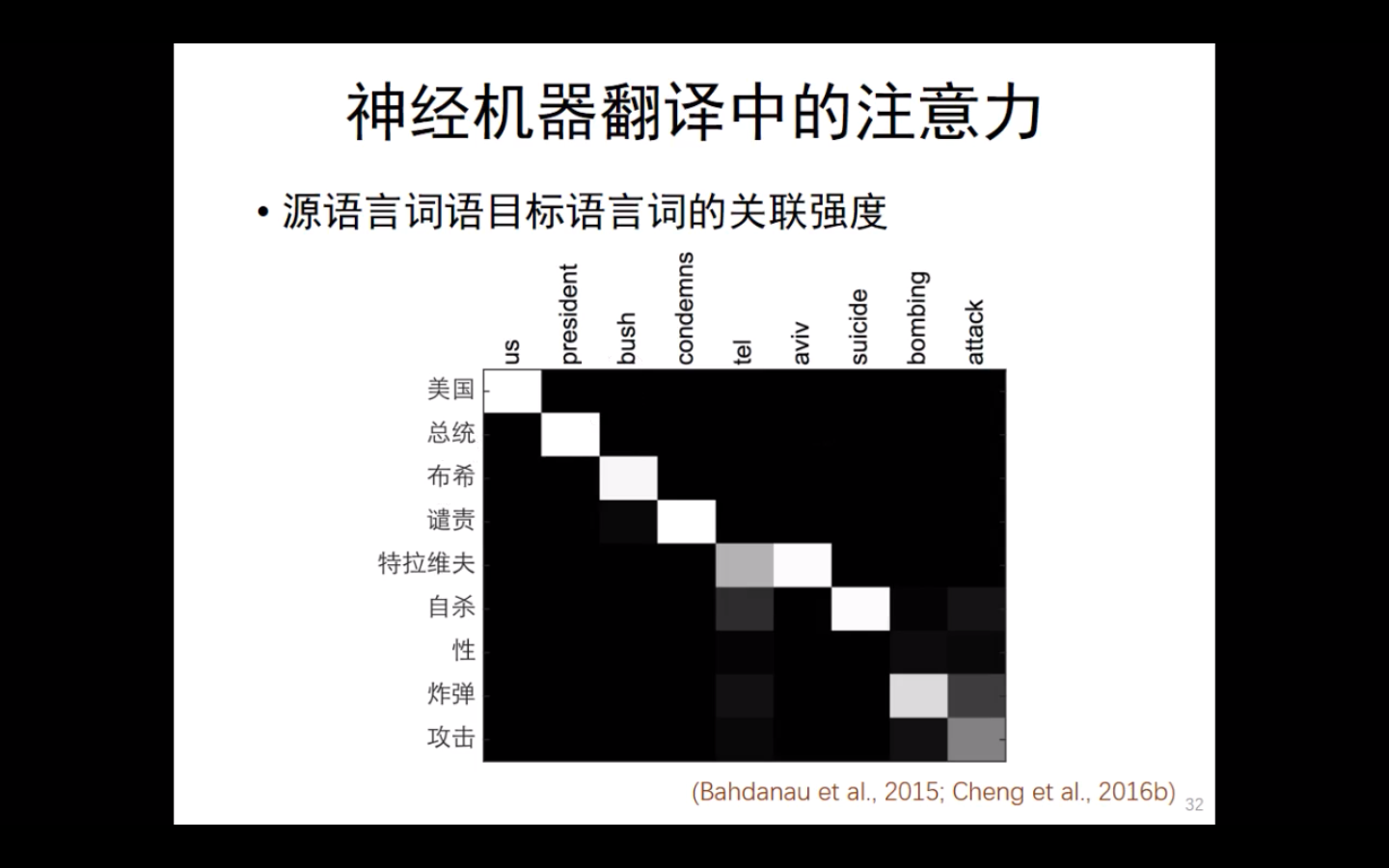
目前,注意力机制也应用在其他领域


 浙公网安备 33010602011771号
浙公网安备 33010602011771号