
RKE 集群配置升级策略
配置最大不可用节点数量
升级集群前,您可以编辑cluster.yml文件对应的参数,调整最大不可用节点的数量。
-
max_unavailable_controlplane: 升级集群时,RKE 可以容忍的无响应 controlplane 节点数量,默认值为 1,表示如果有 1 个节点在升级 RK 集群的过程中没有响应,不会导致集群升级失败;在同一个升级过程中出现 2 个或多节点失败时,则会导致升级集群失败。
-
max_unavailable_worker: 升级集群时,RKE 可以容忍的无响应 worker 节点数量,默认值为 10%。这个参数的取值范围可以使用正整数或百分比表示。使用百分比时,如果得出的结果是大于 1 的小数,则会向下取整,如果得出的结果小于或等于 1,则会取 1 这个值。若该值为小数时,会向下取整至最接近的整数。例如,执行升级的集群中有 11 个 worker 节点,11x10%=1.1,向下取整,最终的结果是 1。如果有 1 个节点在升级 RK 集群的过程中没有响应,不会导致集群升级失败;在同一个升级过程中出现 2 个或多节点失败时,则会导致升级集群失败。
以下代码示例展示了如何使用百分比指定失效 worker 节点数量和使用数字指定失效 controlplane 节点数量:
upgrade_strategy:
max_unavailable_worker: 10%
max_unavailable_controlplane: 1
驱逐节点
默认情况下,升级节点前需要使用kubectl cordon命令将节点标记为“不可用”,这个标记的目的是防止在节点在升级的过程中因为被分配到新的 pods 或者流量而中断。完成升级后,您需要使用kubectl uncordon命令将节点重新标记为“可用”,此时可以将 pods 和流量分配到该节点上。该操作不会对节点上已有的 pods 造成影响。
除了将节点标记为“不可用”外,您也可以使用kubectl drain命令,在升级节点前将节点内的所有 pod 驱逐到其他节点上,并且将其标记为“不可用”,确保这个节点内在升级完成之前不会有正在运行的 pods。kubectl drain命令会导致节点内所有的 pods 被驱逐。
请参考Kubernetes 官方文档,了解驱逐节点的注意事项。
注意:drain的默认值是false,如果将它的值改为true,会导致 worker 节点在升级之前被驱逐,无法升级 worker 节点。
upgrade_strategy:
max_unavailable_worker: 10%
max_unavailable_controlplane: 1
drain: false
node_drain_input:
force: false
ignore_daemonsets: true
delete_local_data: false
grace_period: -1 // grace period specified for each pod spec will be used
timeout: 60
Ingress 和网络插件的副本
Ingress 和网络插件的副本通过Kubernetes daemonset的方式运行。如果不指定升级策略,update_strategy的值为空,Kubernetes 会使用默认的RollingUpdate滚动升级策略。同理,如果不指定最大不可用节点的数量,maxUnavailable为空,Kubernetes 会使用默认值1。
配置 Ingress 和网络插件的示例代码如下:
ingress:
provider: nginx
update_strategy:
strategy: RollingUpdate
rollingUpdate:
maxUnavailable: 5
network:
plugin: canal
update_strategy:
strategy: RollingUpdate
rollingUpdate:
maxUnavailable: 6
DNS 和监控插件的副本
DNS 和监控插件的副本通过deployments的方式运行。DNS 插件包括:coredns、kubedns和metrics-server。
如果不指定升级策略,update_strategy的值为空,Kubernetes 会使用默认的RollingUpdate滚动升级策略。同理,如果不指定最大不可用节点的数量,maxUnavailable为空,Kubernetes 会使用默认值25%,如果不指定最大增量,maxSurge 为空,则会使用默认值25%。
DNS 插件使用cluster-proportional-autoscaler,一个开源的容器镜像 ,监控集群内可调配的节点和 cores 的数量,以调整资源所需要的副本数量。这个功能非常有用,应用可以根据集群内的节点自动伸缩。DNS 插件需要用到的cluster-proportional-autoscaler参数是可以配置的,详情如下表所示。
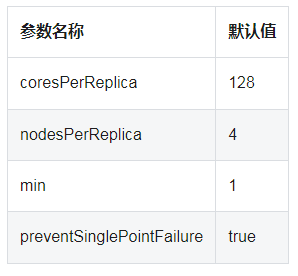
cluster-proportional-autoscaler使用这个公式计算实际所需的副本数量:
replicas = max( ceil( cores * 1/coresPerReplica ) , ceil( nodes * 1/nodesPerReplica ) )
replicas = min(replicas, max)
replicas = max(replicas, min)
配置 DNS 和监控插件的示例代码如下:
dns:
provider: coredns
update_strategy:
strategy: RollingUpdate
rollingUpdate:
maxUnavailable: 20%
maxSurge: 15%
linear_autoscaler_params:
cores_per_replica: 0.34
nodes_per_replica: 4
prevent_single_point_failure: true
min: 2
max: 3
monitoring:
provider: metrics-server
update_strategy:
strategy: RollingUpdate
rollingUpdate:
maxUnavailable: 8
cluster.yml 示例
# 如果您使用的是离线安装环境,请参考离线安装RKE的文档,配置自定义的RKE镜像文件。
nodes:
# 至少需要三个etcd节点、两个controlplane节点和两个worker节点。
# 为了简化案例,本示例只展示了一个节点,其他节点的配置类似,就不一一展示了。
upgrade_strategy:
max_unavailable_worker: 10%
max_unavailable_controlplane: 1
drain: false
node_drain_input:
force: false
ignore_daemonsets: true
delete_local_data: false
grace_period: -1 // grace period specified for each pod spec will be used
timeout: 60
ingress:
provider: nginx
update_strategy: # Available in v2.4
strategy: RollingUpdate
rollingUpdate:
maxUnavailable: 5
network:
plugin: canal
update_strategy: # Available in v2.4
strategy: RollingUpdate
rollingUpdate:
maxUnavailable: 6
dns:
provider: coredns
update_strategy: # Available in v2.4
strategy: RollingUpdate
rollingUpdate:
maxUnavailable: 20%
maxSurge: 15%
linear_autoscaler_params:
cores_per_replica: 0.34
nodes_per_replica: 4
prevent_single_point_failure: true
min: 2
max: 3
monitoring:
provider: metrics-server
update_strategy: # Available in v2.4
strategy: RollingUpdate
rollingUpdate:
maxUnavailable: 8

 浙公网安备 33010602011771号
浙公网安备 33010602011771号