Python学习笔记(五)之Python高级特性
0. 导读
Python高级特性,根据我的理解来说就是一些用来简化代码操作的方法,可以用更少的代码写出功能一样的程序。常听到一句话,一个优秀的程序员,最多也只能更新和维护两万行左右的代码,超过这个值,可能就没有那么大的精力了,当然这个特性也不限制是哪种语言,Python相对其他语言来说,写出相同的程序代码量本身不需要花很多行代码去实现,如果我们能想方设法再节约一些代码行数,那可谓是锦上添花呀。例如要创建一个从1到100的列表,我们可以使用for函数来创建,但是要写好几行代码,但是可以使用高级特性来简化只要一行代码足以,即li = list(range(1, 101))。那么接下来详细地来学习一下Python高级特性。
1. 切片(Slice)
-
切片是用来做什么的?
- 切片的目的是用来取指定索引范围的操作。平时我们去指定索引范围的操作会选择用循环来解决,但是相对于切片来说,循环就显得有些冗余。
-
来看一个切面操作和循环操作取指定索引范围的列表的具体实例对比.
-
例1.1:
#!/user/bin/python #coding=utf-8 #author@ zjw if __name__ == "__main__": li = [1, 2, 3, 4, 5] #切片取法,取前三个数 sli = li[0 : 3] #循环取法,取前三个数 fli = [] for i in range(3): fli.append(li[i]) print(sli) print(fli) -
输出:
[1, 2, 3]
[1, 2, 3]
-
-
上面的1.1例子中,去前三个数的操作还可以简化为li[:3],这是当第一个索引是0时,可以省略。
-
一大波切片例子来袭:以 li = [1, 2, 3, 4, 5] 为初始列表来实现相应操作。
-
例1.2:可以从索引1所以开始取3个数。
>>> li[1 : 4] [2, 3, 4] -
例1.3:去最后一个元素。
>>> li[4] 5 >>> li[-1] 5-
注意:在Python中倒数第一个元素的索引可以用-1来表示,那么它前面的数以此类推是-2,-3...画了一张图可以直观展示该特性。
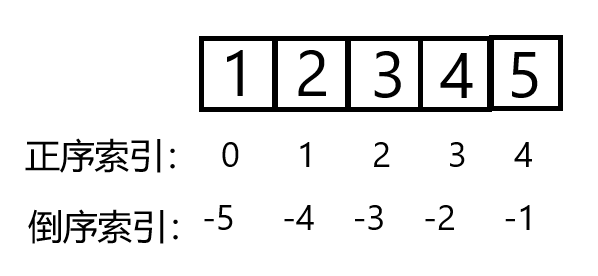
-
-
例1.4:根据正序索引取相应的范围,倒序同理可行。
>>> li[-2:] [4, 5] >>> li[-2:-1] [4] -
例1.5:用切片创建一个0-99的数列:
>>> num = list(range(100)) >>> print num [0, 1, 2, ... , 99] -
例1.6:取num数列中的偶数索引值的数。
>>> num[::2] [0, 2, 4, ... , 96, 98]- 注:第二个冒号后面的数表示步长,即要隔几个取一个数的意思。第一个冒号前后的值都不写,表示对整个数列进行操作。
-
例1.7:倒排li列表。
>>> li = li[-1::-1] >>> li [5, 4, 3, 2, 1]- 注:切片中第一个-1表示从最后一个索引开始,第二个-1表示步长为-1,即表示从最后一个索引开始往前取值,可以得到一个完全倒序的序列。
-
例1.8:用切片操作tuple和字符串
>>> (1, 2, 3, 4, 5)[:2] (1, 2) >>> "abcde"[:2] 'ab' >>> "abcde"[::2] 'ace'
-
2.迭代(遍历)
-
到这里,我已经接触到很多的挺多的for循环了,但大多数使用的情况都是对list或tuple进行操作。
-
迭代操作实际上就是遍历。通过迭代我们可以得到某个列表或数组中的各个值。
-
这里看一下比较特殊的dict迭代。
-
实例2.1:
#!/user/bin/python #coding=utf-8 #author@ zjw if __name__ == "__main__": dic = {1 : 'a', 2 : 'b'} #取出所有的key值 for key in dic: print key #取出所有的value值 for value in dic.values(): print value #取出所有的key-value值 for key, value in dic.items(): print key, value -
输出:
1
2
a
b
1 a
2 b -
分析:dict默认情况下迭代的是key。迭代value则要用
for value in dic.values(),同时迭代key和value则要用for key, value in dic.items()。
-
-
字符串的迭代实际上和列表迭代是一样的。
-
例2.2:
#!/user/bin/python #coding=utf-8 #author@ zjw if __name__ == "__main__": for ch in "abc": print(ch) -
输出:
a
b
c
-
-
这里学到一种像C语言一样下标循环的方法。
-
例2.3:
#!/user/bin/python #coding=utf-8 #author@ zjw if __name__ == "__main__": for i in enumerate(['a', 'b', 'c']): print i for i, value in enumerate(['a', 'b', 'c']): print i, value -
输出:
(0, 'a')
(1, 'b')
(2, 'c')
0 a
1 b
2 c -
注:注意看输出的形式,可以根据需求来调用。
-
3.列表生成器(List Comprehensions)
-
列表生成器是Python内置简单强大的用来创建list的生成式。
-
生成1到100我们可以用
list(range(1, 101))来创建。 -
那么生成
[1*1, 2*2, ..., 99*99, 100*100]如何实现,当然用普通的思路,for语句是可以实现的,但是太繁琐了,这里给出更简单的操作。-
例3.1:
>>> [x * x for x in range(1, 101)] [1, 4, 9, 16, ..., 10000] -
分析:把要生成的元素
x*x放在前面,for循环放在后面,就可以自动创建我们需要的函数。 -
在for循环后我们还可以加if判断句,可以筛选掉我们不需要的元素。这里我们筛选出偶数的平方:
>>> [x * x for x in range(1, 101) if x % 2 == 0] [4, 16, 36, ..., 10000]
-
-
用列表生成器实现两层循环实现全排列操作:
-
例3.2:
>>> [i + j for i in 'abc' for j in 'xyz'] ['ax', 'ay', 'az', 'bx', 'by', 'bz', 'cx', 'cy', 'cz']
-
-
可以使用两个变量来生成list:
-
例3.3:
>>> dic = {'1' : 'a', '2' : 'b'} >>> [k + ' = ' + v for k, v in dic.items()] 1 = a 2 = b
-
-
用列表生成器将一个列表中的小写字母都变成大写。
-
例3.4:
>>> li = ['a', 'b', 'c'] >>> [ch.upper() for ch in li] ['A', 'B', 'C'] -
分析:通过将每个取出来的数经过upper函数转化为大写后,在放入到新的列表中即可。
-
4.生成器(generator)
-
生成器有什么用呢?它和列表生成器又有什么千丝万缕的关系?嘿嘿,让我们来一探究竟吧。
- 首先我们看到列表生成器实际上是直接创建了一个列表。但是,受内存限制,列表容量也是有限的。有时我们用列表生成器创建出来了几百万个数据,但是真正使用的时候才用到了其中的一点皮毛,那么久造成了大量的内存浪费。
- 那么现在我们就引出了
生成器,生成器可以有效解决这种内存浪费,生成器的工作原理是列表中的元素都是虚拟存在的,当你遍历到对应的位置时,其会自动计算接下来的元素,从而在需要的时候占用内存。这种一边循环一边计算的机制,称为生成器。
-
那么现在我们该如何创建一个generator呢?
-
实例4.1:
>>> [x*x for x in range(10)] #列表生成器 [0, 1, 4, 9, 16, 25, 36, 49, 64, 81] >>> (x*x for x in range(10)) #生成器 <generator object <genexpr> at 0x000000000317E778> -
分析:从上面我们可以看出,列表生成器和生成器的区别在与最外层,一个是
[],而生成器是()。列表生成器产生的是一个list,生成器产生是一个generator。
-
-
有了generator后,我们该如何使用(遍历)它呢?
-
可以用
next(),例4.2:>>> g = (x*x for x in range(3)) >>> g <generator object <genexpr> at 0x000000000354E728> >>> next(g) 0 >>> next(g) 1 >>> next(g) 4 >>> next(g) Traceback (most recent call last): File "<stdin>", line 1, in <module> StopIteration- 分析:用next()可以遍历g这个generator,但是一旦超过了g的范围,那么再用next()函数就会报错了,如上提示StopIteration错误。有没有发现一个问题,如果要一直遍历下去,那么不得写老多个next了,不觉内心发凉,没有了使用生成器的欲望。哈哈,其实生成器还有一种遍历方式,待我速速道来。
-
可以用for循环,使用方式和遍历list是一个样一个样的呢。
-
例4.3:
#!/user/bin/python #coding=utf-8 #author@ zjw if __name__ == "__main__": g = (x * x for x in range(4)) for i in g: print(i)
-
-
-
我们可以用生成器生成一个generator(像列表一样的东西),那么我们还可以用生成器来生成一个generator函数。
-
请看实例4.4:
def fib(max): n, a, b = 0, 0, 1 while n < max: print(b) a, b = b, a + b n = n + 1 return 'done' -
分析:这是一个生成斐波拉契数列的函数,把其中的print(b)改成
yield b,那么它就变成了一个generator的函数。在函数调用时我们可以使用如下命令:-
for n in fib(6):print(n)
-
当然也可以通过next函数一个个取出来。因为生成器函数跑到yield时候他就会停下来,这时候你就需要通过遍历的方法驱动他继续运行。上面这个写法还有一个问题就是跑不到return语句。要取得return语句,那么要进行如下操作:
-
>>> g = fib(6) >>> while True: ... try: ... x = next(g) ... print('g:', x) ... except StopIteration as e: ... print('Generator return value:', e.value) ... break ... g: 1 g: 1 g: 2 g: 3 g: 5 g: 8 Generator return value: done
-
-
5. 迭代器
- 可以作用于
for循环的对象都是iterable类型; - 可以作用于
next()函数的对象都是iterator类型,表示一个惰性计算的序列。比如generator生成的序列就是一个iterator类型的。 - 集合数据类型如list、dict、str等是
Iterable但不是iterator,不过可以通过iter()函数变成一个iterator对象。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号