
一篇文章搞清spark内存管理
在执行Spark的应用程序时,Spark集群会启动Driver和Executor两种JVM进程,前者为主控进程,后者负责执行具体的计算任务。由于Driver的内存管理相对简单,本文主要对Executor的内存管理进行分析,下文中的Spark内存均特指Executor的内存。
1.堆内存和堆外内存
由于spark还是JVM进程,所以Executor 的内存管理建立在 JVM 的内存管理之上,因此存在着堆的概念,但是我们知道,堆内存受到 JVM 统一管理,它的GC是有一定算法逻辑的,当spark任务需要申请和释放内存的时候,并不是那么的自由灵活,因此spark引入了堆外内存,使之可以直接在工作节点的系统内存中开辟空间,进一步优化了内存的使用,不受JVM GC的管控,放飞自我。
1.1 堆内存
Executor 内运行的并发任务共享 JVM 堆内存,他们按照用途共分为3类。
- Storage:缓存 RDD 数据和广播变量数据
- Execution:执行Shuffle时占用的内存
- 剩余空间:不做特殊规划,存储Spark内部的对象实例,和用户定义的Spark应用程序中的对象实例
spark submit参数配置:
--executor-memory 或者 spark.executor.memory
Spark虽然不能精准控制堆内内存的申请和释放,但通过对存储内存和执行内存各自独立的规划管理,可以决定是否要在存储内存里缓存新的 RDD,以及是否为新的任务分配执行内存,在一定程度上可以提升内存的利用率,比如更改参数配置spark.storage.memoryFraction可调整storage占的百分比,spark.shuffle.memoryFraction可调整Execution占的百分比
1.2 堆外内存
为了进一步优化内存的使用以及提高Shuffle时排序的效率,Spark引入了堆外(Off-heap)内存,使之可以直接在工作节点的系统内存中开辟空间,存储经过序列化的二进制数据。
默认情况下堆外内存并不启用,启用参数:spark.memory.offHeap.enabled
堆外内存大小参数:spark.memory.offHeap.size。除了没有 other空间,堆外内存与堆内内存的划分方式相同,所有运行中的并发任务共享存储内存和执行内存。
JVM 对于内存的清理是无法准确指定时间点的,因此无法实现精确的释放。堆外内存由于序列化的数据占用的空间可以被精确计算,所以相比堆内内存来说降低了管理的难度,也降低了误差
2. 内存空间分配
2.1 早期的静态内存管理
spark 1.6之前的内存管理较为简单,采用静态内存管理机制,用户可在启动前进行配置各个区域大小占比,但是运行过程中,各内存区间的大小均是固定的。堆内内存默认 Storage:Execution:Other=6:2:2,堆外内存没有other区,默认Storage:Execution=1:1。by the way,由于 Spark 堆内内存大小的记录是不准确的,Storage 内存和 Execution 内存都有预留空间防止OOM。堆外内存不需要
2.2 统一内存管理机制
Spark1.6之后引入的统一内存管理机制,与静态内存管理的区别在于存储内存和执行内存共享同一块空间,可以动态占用对方的空闲区域。
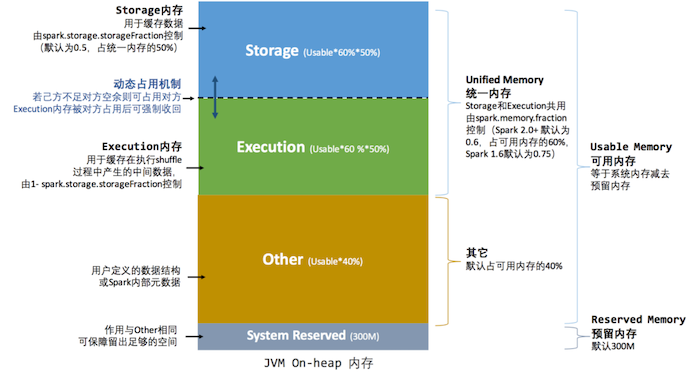
统一内存管理机制堆内内存模型如图:
统一内存管理机制堆外内存模型如图:
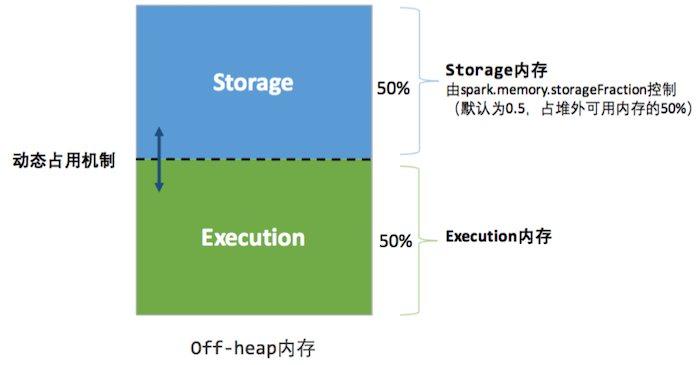
在运行前,用户设定基本存储内存(Storage)和执行内存(Execution)的比例,方式和静态内存管理机制一致,在此基础上,统一内存管理做了如下优化(注意只在Storage和Execution之间开了这个窗口,other还是固定的):
- 双方的空间都不足时,则存储到硬盘;若己方空间不足而对方空余时,可借用对方的空间;(存储空间不足是指不足以放下一个完整的 Block)
- Execution执行内存的空间被对方占用后,可让对方将占用的部分转存到硬盘,然后"归还"借用的空间
- 存储内存的空间被Execution执行内存占用后,无法让对方"归还",因为需要考虑 Shuffle 过程中的很多因素,实现起来较为复杂
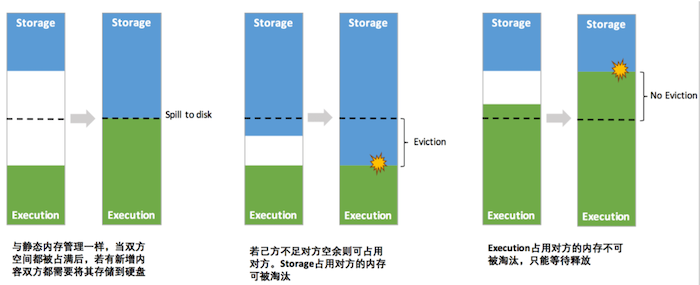
由此可见,Execution由于计算资源比较重要,因此凭实力借的区域在运行期间可以不还,当要收回自己空间时候,对方反抗不了。
3. 存储内存(Storage)缓存RDD怎么存储
一个RDD上要执行多次行动,可以在第一次行动中使用persist或cache方法,在内存或磁盘中持久化或缓存这个RDD,从而在后面的行动时提升计算速度。cache方法是使用默认的MEMORY_ONLY的存储级别将RDD持久化到内存,故缓存是一种特殊的持久化。堆内和堆外存储内存的设计,便可以对缓存RDD时使用的内存做统一的规划和管理。
RDD的缓存和持久化persist由Spark的Storage模块负责,实现了RDD与物理存储的解耦合。在存储上,Storage模块在逻辑上以Block为基本存储单位,RDD的每个Partition经过处理后唯一对应一个Block(BlockId 的格式为 rdd_RDD-ID_PARTITION-ID )。
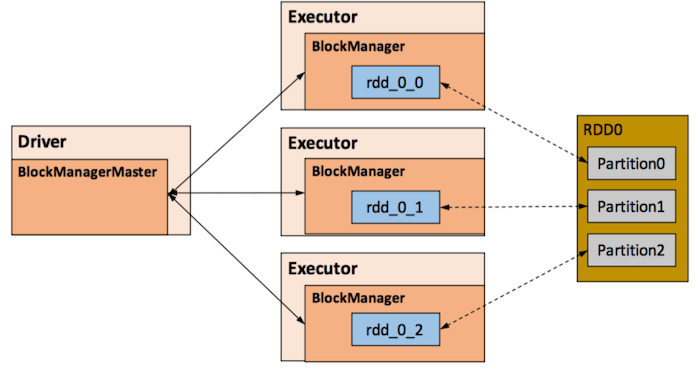
在具体实现时Driver端和Executor端的Storage模块构成了主从式的架构,即Driver端的BlockManager为Master,Executor端的BlockManager为Slave。Driver端的Master负责整个Spark应用程序的Block的元数据信息的管理和维护,而Executor端的Slave需要将Block的更新等状态上报到Master,同时接收Master的命令,例如新增或删除一个RDD。
4. 执行内存(Execution)怎么管理
执行内存主要用来存储任务在执行 Shuffle 时占用的内存,Shuffle 是按照一定规则对 RDD 数据重新分区的过程,主要关注 Shuffle 的 Write 和 Read 两阶段对执行内存的使用。
- Shuffle Write
-
若在 map 端选择普通的排序方式,会采用 ExternalSorter 进行外排,在内存中存储数据时主要占用堆内执行空间。
-
若在 map 端选择 Tungsten 的排序方式,则采用 ShuffleExternalSorter 直接对以序列化形式存储的数据排序,在内存中存储数据时可以占用堆外或堆内执行空间,取决于用户是否开启了堆外内存以及堆外执行内存是否足够。
- Shuffle Read
-
在对 reduce 端的数据进行聚合时,要将数据交给 Aggregator 处理,在内存中存储数据时占用堆内执行空间。
-
如果需要进行最终结果排序,则要将再次将数据交给 ExternalSorter 处理,占用堆内执行空间。
在 ExternalSorter 和 Aggregator 中,Spark 会使用一种叫 AppendOnlyMap 的哈希表在堆内执行内存中存储数据,但在 Shuffle 过程中所有数据并不能都保存到该哈希表中,当这个哈希表占用的内存会进行周期性地采样估算,当其大到一定程度,无法再从 MemoryManager 申请到新的执行内存时,Spark 就会将其全部内容存储到磁盘文件中,这个过程被称为溢存(Spill),溢存到磁盘的文件最后会被归并(Merge)。
Spark 的存储内存和执行内存有着截然不同的管理方式:对于存储内存来说,Spark 用一个 LinkedHashMap 来集中管理所有的 Block,Block 由需要缓存的 RDD 的 Partition 转化而成;而对于执行内存,Spark 用 AppendOnlyMap 来存储 Shuffle 过程中的数据,在 Tungsten 排序中甚至抽象成为页式内存管理,开辟了全新的 JVM 内存管理机制。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号