图论算法初步
咕了两个月的我(如果不算Luogu的题解)终于回来写博了qwq,因为我的数据结构知识一直很薄弱,每次考试老是失分,所以我决定写一写关于图论的博客,最近一段时间也正好在复习这部分,这篇博客的内容会涉及到:树与图的遍历,树的深度,图的联通块,拓扑排序,树的重心,最短路,最小生成树,并查集,Tarjan与图的连通性,树的直径,LCA,树链剖分,负环,0/1分数规划。文章内容与lyd的《算法竞赛进阶指南》重合度比较高(因为我就是按照他的书来复习的),同时文章以讲解为辅,代码为主,适合各位同学复习而并非初学者接触。
所有模板都是我手打的,也许有错误,欢迎批评指正弱弱的我qwq。
声明
博客中如果没有特殊说明,则默认是n个点和无向图,文中会使用vector,邻接表,邻接矩阵这三种方式来存储。
树与图的遍历
树与图的存储方式是相同的,遍历可以采用dfs和bfs这两种方式。
深度优先遍历与深度
众所周知写这个只是为了知识的完整性,大家随便看看就行。
dep是深度数组。
void dfs(int u) { vis[u]=true; for(int i=h[u];i!=-1;i=e[i].nxt) { int v=e[i].v; if(vis[v]) continue; dep[v]=dep[u]+1; dfs(v); } }
广度优先遍历
bfs并没有dfs常用,用队列q来存储,每次遇到一个节点u,就入队,然后依次入队它的子节点,如果子节点也全部入队,就把u出队,又入队它第一个子节点的所有子节点,以此类推...
eg:
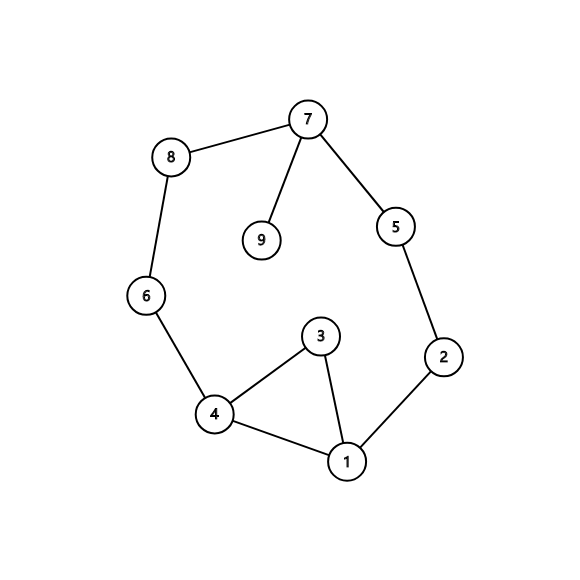
入队标蓝,出队标红,这张图的bfs模拟过程如下:
1 234
234 5
345
45 6
56 7
67 8
78 9
89
代码的实现很简单。
void bfs() { memset(d,0,sizeof(d)); q.push(1); d[1]=1; while(!q.empty()) { int u=q.front(),q.pop(); for(int i=h[u];i!=-1;i=e[i].nxt) { int v=e[i].v; if(d[v]) continue; d[v]=d[u]+1; q.push(v); } } }
我们可以看到图中有一个d数组,d[u]的作用是存储从1遍历到节点u所需经过的最少点数,qwq但是请大家不要妄想能用这个来求最短路,stO青君大佬。
bfs的遍历有两个性质:
1.在访问完节点i的所有节点后,才会开始访问节点i+1。
2.队列中的元素至多有两个层次的节点,第一部分属于i层,第二部分属于i+1层,所有i的节点排在i+1的节点之前,也就是说,bfs遍历满足两段性和单调性,这也是它的基本性质。
树的dfs序
一般地,我们在dfs时,在刚进入递归前和即将回溯之前各记录一次该点的编号,最后产生的2n长节点的序列就是dfs序,如果用a[N>>1]存储dfs序,l[ ]和r[ ]分别存递归前和回溯前的cnt,a[ l [ u ] ]和a[ r [ u ] ]这一段记录的就是u节点的子树,由此可以很好地把树上操作转化为区间问题~!
代码简短也好理解。
void dfs(int u) { vis[u]=true; l[u]=++cnt; // a[cnt]=u; for(int h[u];i!=-1;i=e[i].nxt) { int v=e[i].v; if(vis[v]) continue; dfs(v); } r[u]=++cnt; // a[cnt]=u; }
树的重心和子树大小
如果一棵树有v1~vk个节点,并且以v1~vk为根的子树大小是siz[v1]~siz[vk],那么以u为根的子树大小是siz[u]=siz[v1]+...+siz[vk],也就是说siz数组用来存储节点的子树大小(包括节点本身)。
树的重心指的是,如果我们把一个节点u从树中删除,那么原来的一棵树可能会分成若干个不同的部分,如果在删除一个节点后,剩下的所有子树中最大的一棵是最小的,那么这个被删去的节点称为树的重心,对于无权图,大小一般指的是节点个数。
代码简短好理解,如下。
void dfs(int u) { max_point=0; siz[u]=1; vis[u]=true; for(int i=h[u];i!=-1;i=e[i].nxt) { int v=e[i].v; if(vis[v]) continue; dfs(v);//要先遍历子节点才能找到子节点的siz值 qwq为什么总是忘记dfs 我有罪 siz[u]+=siz[v]; max_point=max(max_point,siz[v]); } max_point=max(max_point,n-siz[u]); if(max_point<ans) { ans=max_point; pos=u; } }
图的连通块划分
经过多次dfs,可以找出一张图的每一个连通块,不会连通块的同学可以去看看知识点再做两道题,这个很简单,不赘述了。
void dfs(int u) { scc[u]=cnt; for(int i=h[u];i!=-1;i=e[i].nxt) { int v=e[i].v; if(scc[v]) continue; scc[v]=cnt; dfs(v); } } int main() { for(int i=1;i<=n;i++) if(!scc[i]) dfs(i); }
拓扑排序
给定一张有向无环图,若一个由图中所有点构成的序列A满足:对于图中边(x,y),x在A中都出现在y之前,则称A是这张图的一个拓扑序,求解这个序列的过程我们称其为拓扑排序。
拓扑排序的实现过程很简单:
1.建立空的序列A
2.预处理所有的入度d[i],入队初始入度为0的点。
3.取出队头节点x,把x加入A的末尾。
4.对于从A出发的每条边(x,y),如果被减为0,就把y入队。
5.重复3,4步直到队列为空,这个时候我们就求出了拓扑序。
#include<bits/stdc++.h> using namespace std; int n,m,h[10005],cnt,tot,d[20005],a[10005]; struct node { int v,nxt; }e[20005]; void add(int u,int v) { e[++cnt].v=v; e[cnt].nxt=h[u]; h[u]=cnt; d[v]++;//d数组表示v的入度,入度指的是以某一个点为终点的边数 } void topsort() { queue<int>q; for(int i=1;i<=n;i++) if(!d[i]) q.push(i);//入度为0则入队 while(!q.empty()) { int u=q.front(); q.pop(); a[++tot]=u; for(int i=h[u];i!=-1;i=e[i].nxt) { int v=e[i].v; if(--d[v]) q.push(v);//--d[v]表示的是,u此刻为v的出度,如果减去u之后v是0个节点的入度,那么可以入队 } } } int main() { memset(h,-1,sizeof(h)); scanf("%d%d",&n,&m); while(m--) { int u,v; scanf("%d%d",&u,&v); add(u,v); } topsort(); if(tot<n)printf("there is a circle\n"); else for(int i=1;i<=tot;i++) printf("%d ",a[i]); return 0; }
upt 2019.10.24:今天想用一下topsort的模板发现有一堆锅。。(已补)所以看这篇blog的小伙伴都没有发现吗。。
最短路径
如题,这里求的是图论当中的最短路,最短路有多源和单源最短路。
Floyd算法
Floyd属于多源最短路算法,非常简单,但时间复杂度为o(n^3),太高了qwq,优点是简单好理解,思想是dp。
dp[k][i][j]=min(dp[k-1][i][j],dp[k-1][i][k]+dp[k-1][k][j);
#include<cstdio> #include<cstring> #include<algorithm> using namespace std; #define N 1005 int d[N][N]; int n,m; int main() { scanf("%d%d",&n,&m); memset(d,0x3f,sizeof(d)); for(int i=1;i<=n;i++) d[i][i]=0; for(int i=1;i<=m;i++) { int u,v,w; scanf("%d%d%d",&u,&v,&w); d[u][v]=min(d[u][v],w); } for(int k=1;k<=n;k++) for(int i=1;i<=n;i++) for(int j=1;j<=n;j++) d[i][j]=min(d[i][j],d[i][k]+d[k][j]); for(int i=1;i<=n;i++) { for(int j=1;j<=n;j++) printf("%d ",d[i][j]); printf("\n"); } return 0; }
Dijkstra算法
qwq这是基于贪心思想的算法,一个伪代码就能体现
d[v]=min(d[v],d[u]+w)(u为当前到起点路最短的点)
邻接矩阵实现
#include<cstdio> #include<cstring> #include<algorithm> using namespace std; #define N 3005 int d[N],a[N][N],n,m,v[N]; void dijkstra() { memset(d,0x3f,sizeof(d)); d[1]=0; for(int i=1;i<n;i++) { int x=0; for(int j=1;j<=n;j++) if(!v[j]&&(x==0||d[j]<d[x])) x=j; v[x]=1; for(int j=1;j<=n;j++) d[j]=min(d[j],d[x]+a[x][j]); } } int main() { scanf("%d%d",&n,&m); memset(a,0x3f,sizeof(a)); for(int i=1;i<=n;i++) a[i][i]=0; for(int i=1;i<=m;i++) { int u,v,w; scanf("%d%d%d",&u,&v,&w); a[u][v]=min(a[u][v],w); } dijkstra(); for(int i=1;i<=n;i++) printf("%d ",d[i]); return 0; }
邻接链表+堆优化
#include<cstdio> #include<cstring> #include<queue> #include<algorithm> using namespace std; #define N 100005 struct node { int v,nxt,w; }e[N]; int d[N],h[N],v[N]; int n,m,cnt; priority_queue< pair <int,int> >q; void add(int u,int v,int w) { e[++cnt].v=v; e[cnt].w=w; e[cnt].nxt=h[u]; h[u]=cnt; } void dijkstra() { q.push(make_pair(0,1)); d[1]=0; while(q.size()) { int u=q.top().second; q.pop(); if(v[u]) continue; v[u]=1; for(int i=h[u];i!=-1;i=e[i].nxt) { int v=e[i].v; int w=e[i].w; d[v]=min(d[v],d[u]+w); q.push(make_pair(-d[v],v));//运用相反数思想实现一个小根堆 每次找到权值最小的u访问一个G(U,V) 满足贪心思想 } } } int main() { memset(h,-1,sizeof(h)); memset(d,0x3f,sizeof(d)); scanf("%d%d",&n,&m); for(int i=1;i<=m;i++) { int u,v,w; scanf("%d%d%d",&u,&v,&w); add(u,v,w); } dijkstra(); for(int i=1;i<=n;i++) printf("%d ",d[i]); return 0; }
SPFA算法
qwq俗话说得好:SPFA死了,所以对于它不做过多介绍,只提一句:
边(u,v,w)满足三角形不等式d[v]<=d[u]+w;
#include<cstdio> #include<queue> #include<cstring> #include<algorithm> using namespace std; #define N 100005 struct node { int nxt,v,w; }e[N]; int n,m,d[N],h[N],cnt,v[N]; void add(int u,int v,int w) { e[++cnt].v=v; e[cnt].w=w; e[cnt].nxt=h[u]; h[u]=cnt; } queue<int>q; void spfa() { memset(d,0x3f,sizeof(d)); d[1]=0,v[1]=1; q.push(1); while(q.size()) { int u=q.front();q.pop(); v[u]=0; for(int i=h[u];i!=-1;i=e[i].nxt) { int y=e[i].v; int w=e[i].w; d[y]=min(d[y],d[u]+w); if(!v[y]) q.push(y),v[y]=1; } } } int main() { scanf("%d%d",&n,&m); memset(h,-1,sizeof(h)); for(int i=1;i<=m;i++) { int u,v,w; scanf("%d%d%d",&u,&v,&w); add(u,v,w); } spfa(); for(int i=1;i<=n;i++) printf("%d ",d[i]); return 0; }
dijkstra和SPFA这两种算法的思想不同,虽然代码有点像,但是有细微差别,比如v数组,dijkstra是函数内和for循环内无赋值,while内有continue/1的判断,而SPFA在函数内和for循环内有赋值1的操作,while内清零,画个图手%,搞一搞就出来为什么了。
BTW,还是要插两句,koalawy大佬说不加v数组的判断仍然能跑,但有时候会跑不过,尤其是SPFA。俗话说“SPFA死了”,但koalawy大佬告诉我dijkstra也经常死掉,他喜欢SPFA,而且只死过一次,但实际上我本人还是更喜欢dij,贪心思想很好理解。最短路就到这里。
最小生成树
最小生成树指的是,一个图有n个点m条边,要求从中找出n-1条边来连成一棵树,使这棵树上的权值之和最小。
Kruskal算法
我觉得这个算法还是很好理解的,sort一遍权值挨着挨着找就完事了,在一个集合就continue,不在就用并查集合并,so easy!30+行代码也太友好了~我就不讲了。
#include<cstdio> #include<cstring> #include<algorithm> using namespace std; #define N 10005 struct node { int u,v,w; }e[N<<1]; int n,m,ans,fa[N<<1]; int find(int x) { if(x==fa[x]) return x;; return fa[x]=find(fa[x]); } bool cmp(node a,node b) { return a.w<b.w; } int main() { scanf("%d%d",&n,&m); for(int i=1;i<=m;i++) scanf("%d%d%d",&e[i].u,&e[i].v,&e[i].w); sort(e+1,e+1+m,cmp); for(int i=1;i<=n;i++) fa[i]=i; for(int i=1;i<=m;i++) { int x=find(e[i].u); int y=find(e[i].v); if(x==y) continue; fa[x]=y; ans+=e[i].w; } printf("%d\n",ans); return 0; }
Prim算法
Prim是基于Kruskal算法基础的,但是它是用最小生成树已有点集合当中最小的点和当前访问点相连来维护这棵树,咋一看和dijkstra还是很像的,算法复杂度是O(n<<1),不想写了(十二点多了好困),代码的锅已补。
upd:Prim算法的存储方式主要是邻接矩阵,可以堆优化,但那样还不如用dijkstra,所以,Prim比较适合稠密图。
#include<cstdio> #include<cstring> #include<algorithm> using namespace std; #define N 3005 int a[N][N],d[N],n,m,ans; bool v[N]; void prim() { memset(d,0x3f,sizeof(d)); memset(v,0,sizeof(v)); d[1]=0; for(int i=1;i<n;i++) { int x=0; for(int j=1;j<=n;j++) if(!v[j]&&(x==0||d[j]<d[x])) x=j; v[x]=1; for(int y=1;y<=n;y++) if(!v[y]) d[y]=min(d[y],a[x][y]); } } int main() { scanf("%d%d",&n,&m); memset(a,0x3f,sizeof(a)); for(int i=1;i<=n;i++) a[i][i]=0; for(int i=1;i<=m;i++) { int x,y,z; scanf("%d%d%d",&x,&y,&z); a[x][y]=a[y][x]=min(a[x][y],z); } prim(); for(int i=2;i<=n;i++) ans+=d[i]; printf("%d\n",ans); return 0; }
树的直径
定义一棵树,使两点之间的距离等于它们路径上的边权之和,那么这棵树上两个点之间的最远距离就称为树的直径,也叫树的最长链。
求树的直径方法多种多样,这里讲一下树形dp求(主要是我不会两次dfs/bfs)
设一个数组d,d[u]表示以u为根的子树,求从它开始能走到的最远距离,那么如果u有一个节点v,状态转移方程就可以写成d[u]=max(d[u],d[v]+w[u][v])。
那么问题来了,我们怎么去求树的直径呢?两点之间的最远距离又怎么表示,这个很好实现嘛,设有任意节点u,v,则最远距离为d[u]+d[v]+w[u][v]。
所以这个时候就可以搞一个ans出来,ans=max(ans,d[u]+d[v]+w[u][v])。
void dp(int u) { vis[u]=1; for(int i=h[u];i!=-1;i=e[i].nxt) { int v=e[i].v; if(vis[v]) continue; dp(v); ans=max(ans,d[u]+d[v]+e[i].w); d[u]=max(d[u],d[v]+e[i].w); } }
LCA(最近公共祖先)
LCA求的是一棵树上两个点深度最大的公共祖先,因为两个点都和这个祖先联通且没有深度更大的祖先,所以u-->lca-->v的路径一定是u,v在树上的最短路径。于是你发现,求树上最短路的时候,LCA非常有用惹。我先讲倍增,其他的慢慢补充。
倍增
不熟悉倍增算法的小伙伴建议就不要看这个方法哈,或者先去了解下倍增。假如我们搞一个p[N][25]出来,设p[u][i]表示节点u向上跳1<<i步所到达的点,那么p[u][0]表示的就是u的父亲节点,我们可以把p数组预处理出来,再存储一个深度数组d,求点u,v的LCA的时候,把这两个节点不断往上倍增跳直到祖先相同,就找到了LCA,具体细节在代码中。接下来放的代码是luogu的一道模板题,大家可以做一做。
#include<cstdio> #include<cstring> #include<algorithm> using namespace std; #define N 500005 int n,m,h[N],cnt,rt,p[N][25],d[N]; struct node { int v,nxt; }e[N<<1]; void add(int u,int v) { e[++cnt].v=v; e[cnt].nxt=h[u]; h[u]=cnt; } void dfs(int u,int fa) { d[u]=d[fa]+1; p[u][0]=fa; for(int i=1;(1<<i)<=d[u];i++) p[u][i]=p[p[u][i-1]][i-1]; for(int i=h[u];i!=-1;i=e[i].nxt) { int v=e[i].v; if(v==fa) continue; dfs(v,u); } } int lca(int a,int b) { if(d[a]>d[b]) swap(a,b); for(int i=22;i>=0;i--) if(d[a]<=(d[b]-(1<<i))) b=p[b][i]; if(a==b) return a; for(int i=22;i>=0;i--) { if(p[a][i]==p[b][i]) continue; a=p[a][i],b=p[b][i]; } return p[a][0]; } int main() { memset(h,-1,sizeof(h)); scanf("%d%d%d",&n,&m,&rt); for(int i=1;i<n;i++) { int u,v; scanf("%d%d",&u,&v); add(u,v); add(v,u); } dfs(rt,0); while(m--) { int u,v; scanf("%d%d",&u,&v); printf("%d\n",lca(u,v)); } return 0; }
强连通分量
最基础用法
众所周知,强连通分量是个好东西。
有向图中,点能两两互达的一个连通块称为一个强连通分量,于是乎我们可以知道,无向图只有一个强连通分量,具体怎么实现呢?
设置一个dfn数组表示某个点出现的次序编号,low数组表示某个点能直接或者间接到达的最远点。
所以如果在一棵有根树上,若low[u]=dfn[u],就说明以点u为根节点的整个搜索子树就是一个强连通分量。
我们每一次将顶点入栈,遍历它的儿子节点,若儿子节点v没有被访问过,low[u]=min(low[u],low[v]),若儿子节点v在栈中,则low[u]=min(low[u],dfn[v])。
举个例子
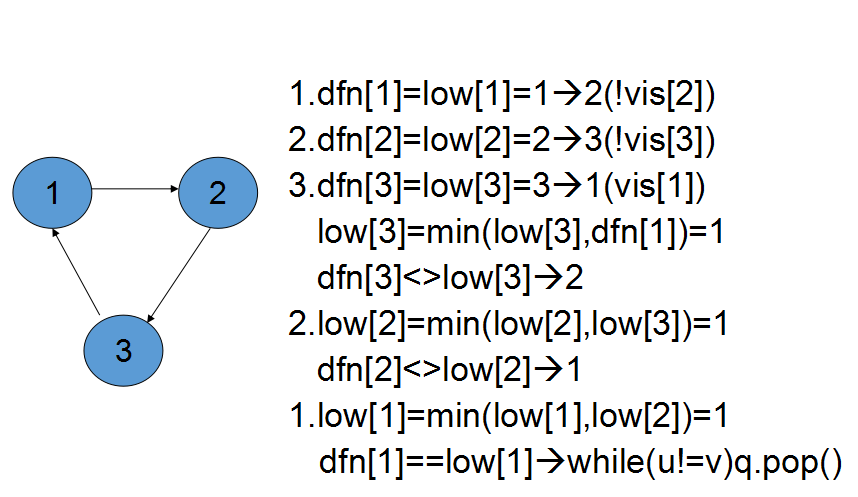
算了...我真的好懒..讲不下去了,放代码吧。
#include<cstdio> #include<cstring> #include<algorithm> #include<vector> using namespace std; int cnt,tot,dfn[50005],low[50005],h[50005],s[50005],ins[50005],n,m,num,scc,belong[50005]; struct node { int v,nxt; }e[100005]; vector<int>vec[50005]; void add(int u,int v) { e[++cnt].v=v; e[cnt].nxt=h[u]; h[u]=cnt; } void tarjan(int u) { int v; dfn[u]=low[u]=++tot; s[++num]=u; ins[u]=true; for(int i=h[u];i!=-1;i=e[i].nxt) { v=e[i].v; if(!dfn[v]) tarjan(v),low[u]=min(low[u],low[v]); else if(ins[v]) low[u]=min(low[u],dfn[v]); } if(low[u]==dfn[u]) { scc++; //scc表示强连通个数 do { v=s[num--]; belong[v]=scc;//belong[v]存储节点v属于哪一个强连通 ins[v]=false;//出栈 vec[scc].push_back(v);//vec存储第scc个强连通的所有元素 }while(v!=u); } } void init() { for(int i=1;i<=n;i++) if(!dfn[i]) tarjan(i); } void clean() { cnt=tot=num=scc=0; memset(dfn,0,sizeof(dfn)); memset(low,0,sizeof(low)); memset(belong,0,sizeof(belong)); memset(s,0,sizeof(s)); memset(ins,0,sizeof(ins)); memset(h,-1,sizeof(h)); for(int i=1;i<=n;i++) vec[i].clear(); } int main() { clean(); scanf("%d%d",&n,&m); for(int i=1;i<=m;i++) { int u,v; scanf("%d%d",&u,&v); add(u,v); // add(v,u); } init(); printf("%d\n",scc); }
割点
割点也叫割顶,它指的是在一个图中去掉会使整个图不相连的点.
割点的判定方法很简单:
1.如果一个点是根节点,若它有两个及以上的节点并且有low[son]>=dfn[root]的条件,就说明这个点是一个割点。
2.如果一个点u不是根节点,那么它只需要满足low[v]>=dfn[u]这个条件,保证子节点最终不会回到图中其他点,否则点u就不是割点。
#include<cstdio> #include<cstring> #include<algorithm> using namespace std; int n,m,cnt,idx,h[50005],flag[50005],dfn[50005],low[50005],rt; struct node { int v,nxt; }e[100005]; void add(int u,int v) { e[++cnt].v=v; e[cnt].nxt=h[u]; h[u]=cnt; } void tarjan(int u) { dfn[u]=low[u]=++idx; int ans=0; for(int i=h[u];i!=-1;i=e[i].nxt) { int v=e[i].v; if(!dfn[v]) { tarjan(v),low[u]=min(low[u],low[v]); if(low[v]>=dfn[u]) { ans++; if(ans>1||u!=rt) flag[u]=1;//我感觉这里的逻辑关系不是很好理解 //1.若为根节点 ans>1&&low[v]>=dfn[u]才可行 } //2.若非根节点 有low[v]>=dfn[u]这个条件即可 } else low[u]=min(low[u],dfn[v]); } } void clean() { memset(h,-1,sizeof(h)); memset(flag,0,sizeof(flag)); memset(low,0,sizeof(low)); memset(dfn,0,sizeof(dfn)); cnt=rt=idx=0; } void init() { for(int i=1;i<=n;i++) if(!dfn[i]) rt=i,tarjan(i); } int main() { while(~scanf("%d",&n)) { if(!n) break; clean(); int a; while(scanf("%d",&a)!=EOF) { if(!a) break; while(1) { char c=getchar(); if(c=='\n') break; int b; scanf("%d",&b); add(a,b); add(b,a); } } init(); int answ=0; for(int i=1;i<=n;i++) if(flag[i]) answ++; printf("%d\n",answ); } return 0; }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号