


推荐系统算法学习导论
作者:July。推荐(引擎)系统算法学习导论
出处:结构之法算法之道
引言
昨日看到几个关键词:语义分析,协同过滤,智能推荐,想着想着便兴奋了。于是昨天下午开始到今天凌晨3点,便研究了一下推荐引擎,做了初步了解。日后,自会慢慢深入仔细研究(日后的工作亦与此相关)。当然,此文也会慢慢补充完善。
本文作为对推荐引擎的初步介绍的一篇导论性的文章,将略去大部分的具体细节,侧重用最简单的语言简要介绍推荐引擎的工作原理以及其相关算法思想,且为了着重浅显易懂基本上全部援引自本人1月7日在微博上发表的文字(特地整理下,方便日后随时翻阅),言简意赅,保证本文的短小,尽量不引用太多专业术语。
同时,本文所有相关的算法都会在日后的文章一一陆续具体阐述。本文但求微言导论,日后但求具体而论。若有任何问题,欢迎随时不吝赐教或批评指正。谢谢。
推荐引擎原理
推荐引擎原理如下图所示(尽最大努力的收集尽可能多的用户信息及行为,所谓广撒网,勤捕鱼,然后“特别的爱给特别的你”):
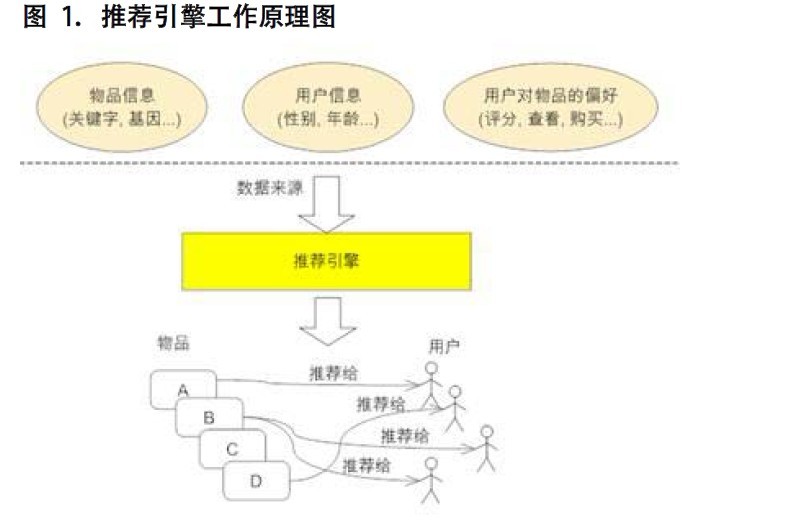
推荐引擎的分类
推荐引擎根据不同依据如下分类:
- 根据其是不是为不同的用户推荐不同的数据,分为基于大众行为、及个性化推荐引擎;
- 根据其数据源,分为基于人口统计学的(用户年龄或性别相同判定为相似用户)、基于内容的(物品具有相同关键词和Tag),以及基于协同过滤的推荐(相似或相关性,分为三个子类,下文阐述);
- 根据其建立方式,分为基于物品和用户本身的(用户-物品二维矩阵描述用户喜好,聚类算法)、基于关联规则的、以及基于模型的推荐。
- 基于用户的推荐(通过共同口味与偏好找相似邻居用户,K-邻居算法,你朋友喜欢,你也可能喜欢),
- 基于项目的推荐(发现物品之间的相似度,推荐类似的物品,你喜欢物品A,C与A相似,可能也喜欢C),
- 基于模型的推荐(机器学习)。
多种推荐方式结合
协调过滤推荐
做协同过滤推荐,一般要做好以下几个步骤:
1)若要做协同过滤,那么收集用户偏好则成了关键。可以通过用户的行为诸如评分(如不同的用户对不同的作品有不同的评分,而评分先进意味着喜好口味相近,便可判定为相似用户),投票,转发,保存,书签,标记,评论,点击流,页面停留时间,是否购买等获得。如下面第2点所述:所有这些信息都可以数字化,如一个二维矩阵表示出来。
2)收集了用户行为数据之后,我们接下来便要对数据进行减噪与归一化操作(得到一个用户偏好的二维矩阵,一维是用户列表,另一维是物品列表,值是用户对物品的偏好,一般是 [0,1] 或者 [-1, 1] 的浮点数值)。
3)找到相似的用户和物品,通过什么途径找到呢?便是计算相似用户或相似物品的相似度。
4)相似度的计算有多种方法,不过都是基于向量Vector的,其实也就是计算两个向量的距离,距离越近相似度越大。在推荐中,用户-物品偏好的二维矩阵下,我们将一个用户对所有物品的偏好作为一个向量来计算用户之间的相似度,或者将所有用户对某个物品的偏好作为一个向量来计算物品之间的相似度。
5)而计算出来的这两个相似度则将作为基于用户、项目的两项协同过滤的推荐。常见的计算相似度的方法有:欧几里德距离,皮尔逊相关系数(如两个用户对多个电影的评分,采取皮尔逊相关系数等相关计算方法,可以抉择出他们的口味和偏好是否一致),Cosine相似度,Tanimoto系数。下面,简单介绍其中的欧几里得距离与皮尔逊相关系数:
- 欧几里德距离(Euclidean Distance)是最初用于计算欧几里德空间中两个点的距离,假设 x,y 是 n 维空间的两个点,它们之间的欧几里德距离是:
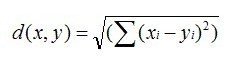
可以看出,当 n=2 时,欧几里德距离就是平面上两个点的距离。 当用欧几里德距离表示相似度,一般采用以下公式进行转换:距离越小,相似度越大:
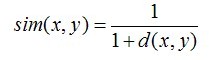
- 皮尔逊相关系数一般用于计算两个定距变量间联系的紧密程度,计算公式为:
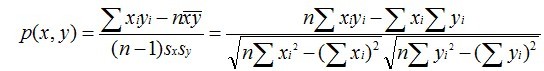
它的取值在 [-1,+1] 之间。 sx, sy是 x 和 y 的样品标准偏差。
6)相似邻居计算。邻居分为两类:固定数量的邻居K-neighborhoods 或者 Fix-size neighborhoods不论邻居的“远近”,只取最近的 K 个,作为其邻居,如下图A部分所示;基于相似度门槛的邻居,落在以当前点为中心,距离为 K 的区域中的所有点都作为当前点的邻居,如下图B部分所示。
7)经过4)计算出来的基于用户的CF(基于用户推荐之用),基于物品的CF(基于项目推荐之用)。一般来说,社交网站内如facebook宜用User CF(用户多嘛),而购书网站内如Amazon宜用Item CF(你此前看过与此类似的书比某某也看过此书更令你信服,因为你识书不识人)。
聚类算法
聚类聚类,通俗的讲,即所谓“物以类聚,人以群分”。
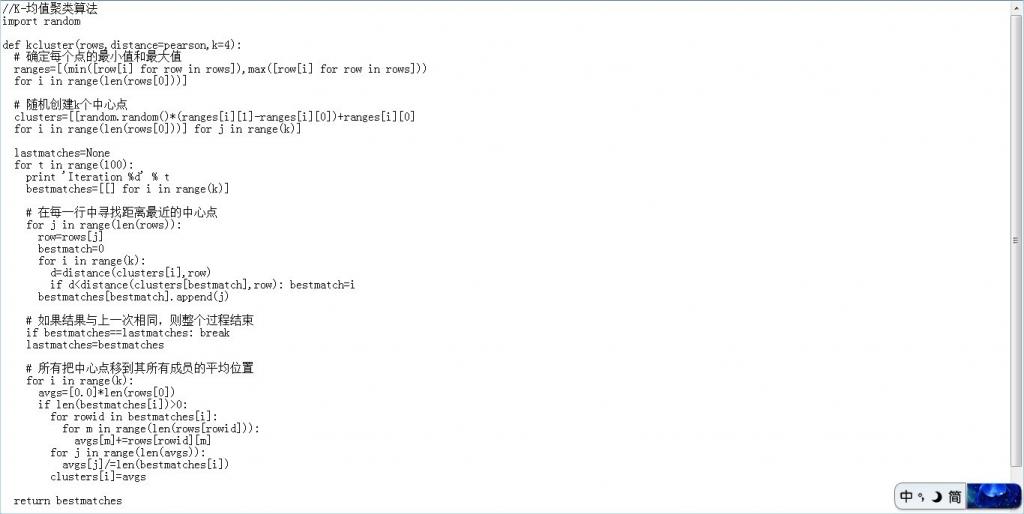
K 均值聚类算法
K 均值(k-Means)是典型的基于距离的排他的划分方法:给定一个 n 个对象的数据集,它可以构建数据的 k 个划分,每个划分就是一个聚类,并且 k<=n,同时还需要满足两个要求:1、每个组至少包含一个对象;2、每个对象必须属于且仅属于一个组。下图所示即是此算法的python实现:
Canopy 聚类算法
Canopy 聚类算法的基本原则是:首先应用成本低的近似的距离计算方法高效的将数据分为多个组,这里称为一个 Canopy,我们姑且将它翻译为“华盖”,Canopy 之间可以有重叠的部分;然后采用严格的距离计算方式准确的计算在同一 Canopy 中的点,将他们分配与最合适的簇中。Canopy 聚类算法经常用于 K 均值聚类算法的预处理,用来找合适的 k 值和簇中心。
模糊 K 均值聚类算法
模糊 K 均值聚类算法是 K 均值聚类的扩展,它的基本原理和 K 均值一样,只是它的聚类结果允许存在对象属于多个簇,也就是说:它属于我们前面介绍过的可重叠聚类算法。
其余聚类算法本文不再介绍。
后记
OK,更多请参看本人1月7日的微博。再者,推荐一份本文主要参考的资料:探索推荐引擎内部的秘密(作者:赵晨婷,马春娥)http://www.ibm.com/developerworks/cn/web/1103_zhaoct_recommstudy1/index.html?ca=drs-,推荐一本书:集体智慧编程(TobySeganra著)。
最后,编程艺术室内,Algorithms1~17群系列,程序员技术联盟的朋友与我祝本blog的所有读者朋友们(不论是老读者,还是新读者)元旦快乐,2012年新年快乐。同时,在上一篇文章中已说过:“近几日后,准备编程艺术室内38位兄弟的靓照和blog或空间地址公布在博客内,给读者一个联系他们的方式,顺便还能替他们征征友招招婚之类的(有的除外)”。下面贴一下编程艺术室内的部分朋友们的微博或主页(排名不分先后):
BigPotato:http://weibo.com/bigpotatoc;ys:http://weibo.com/yanshazi;上善若水qin.yusen:http://www.renren.com/240148123/profile;梦想天窗:http://weibo.com/dirichlet09;时间飘过:http://weibo.com/weedge;well:http://t.qq.com/fairywell28;飞羽:http://weibo.com/jxtsung;
√3:http://blog.csdn.net/ThinkArt;☆滨 湖∮:http://weibo.com/lakeshore;Eric:http://weibo.com/softkitty;Lynn :http://weibo.com/375367539;蜡笔小轩:http://weibo.com/dinosoft;∈Φ.威士忌:http://weibo.com/hwiskey;宝宝虫:http://t.qq.com/chengzhenqiang1981;狸待桃将:http://weibo.com/u/1177168711;天天向上:http://t.qq.com/zjllike,海风月影:http://t.qq.com/zjhangtian;wawayu:http://hi.csdn.net/bbswawa。
谢谢。完。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号