机器学习概述与开发流程
机器学习的定义
Machine Learning(ML) is a scientific discipline that deals with the construction and study of algorithms that can learn from data.
机器学习是一门从数据中研究算法的科学学科。机器学习是人工智能的一个分支。我们使用计算机设计一个系统,使它能够根据 提供的训练数据按照一定的方式来学习;随着训练次数的增加,该系统可以在性 能上不断学习和改进;通过参数优化的学习模型,能够用于预测相关问题的输出。
机器学习直白来讲,是根据已有的数据,进行算法选择,并基于算法和数据构建 模型,最终对未来进行预测;
备注:机器学习就是一个模拟人决策过程的一种程序结构。
机器学习理性认识

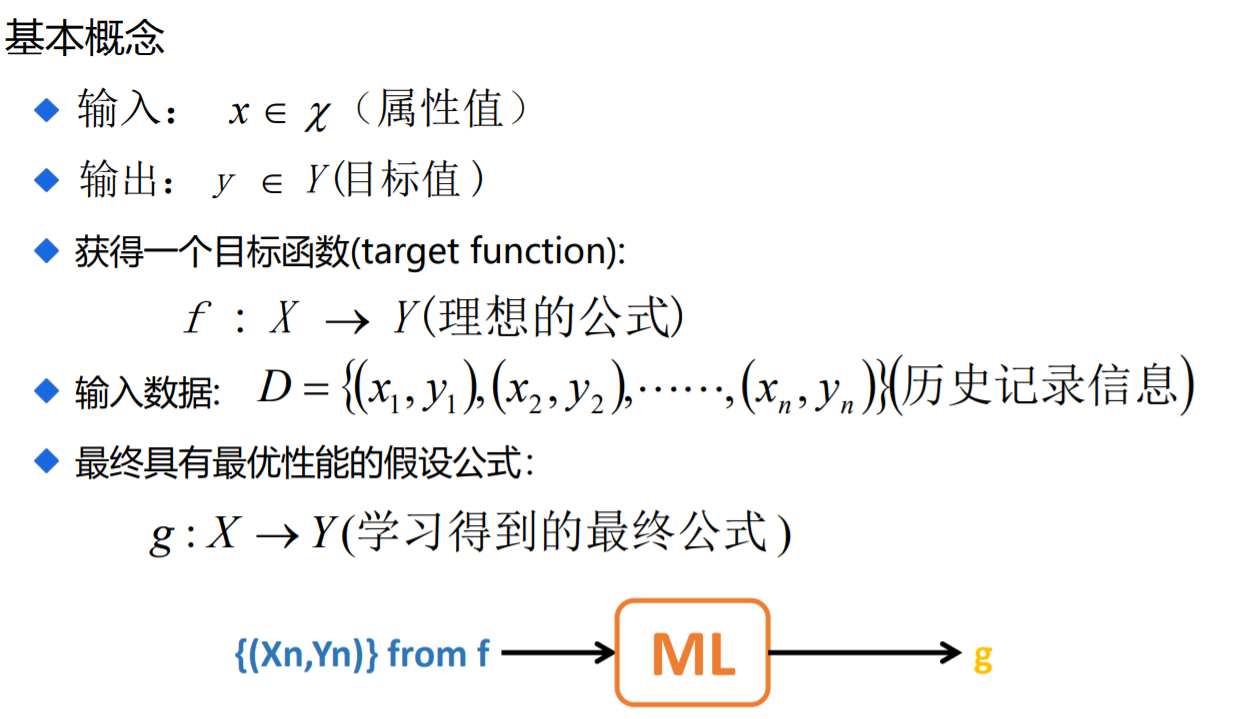
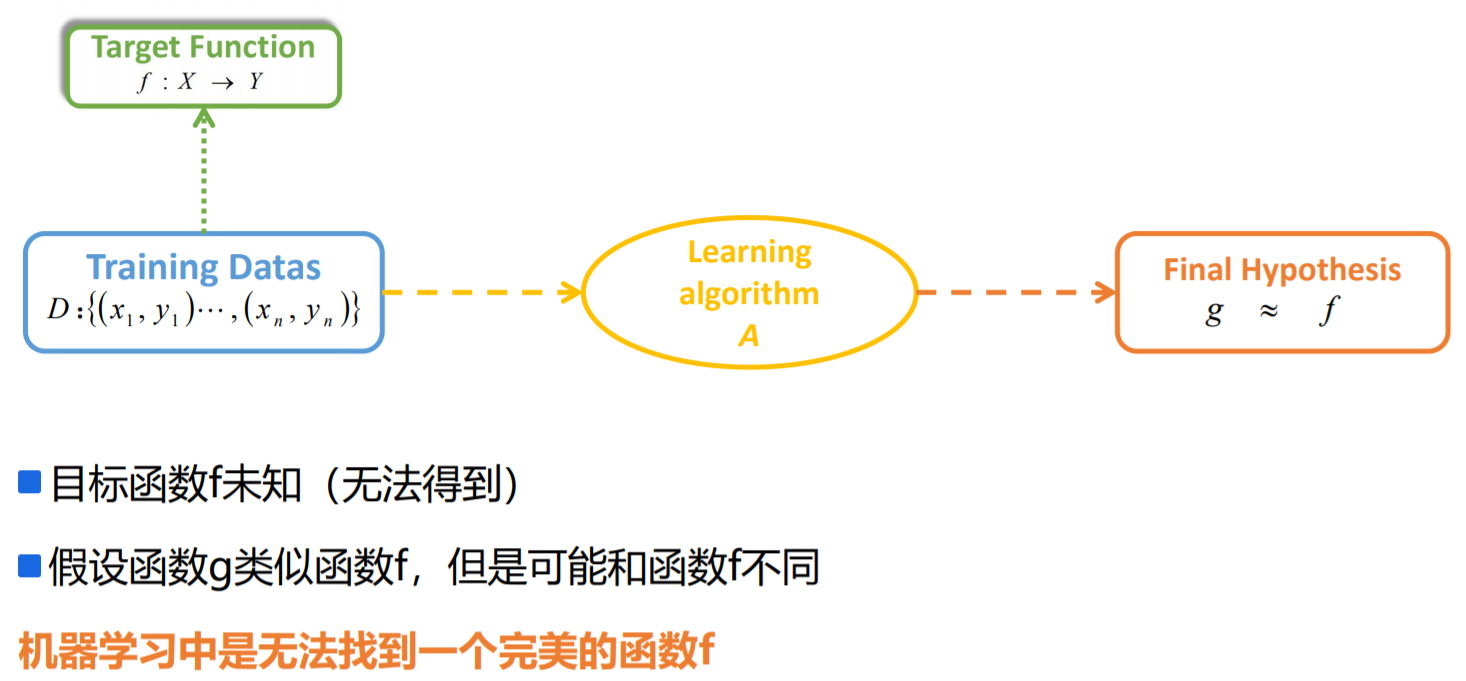
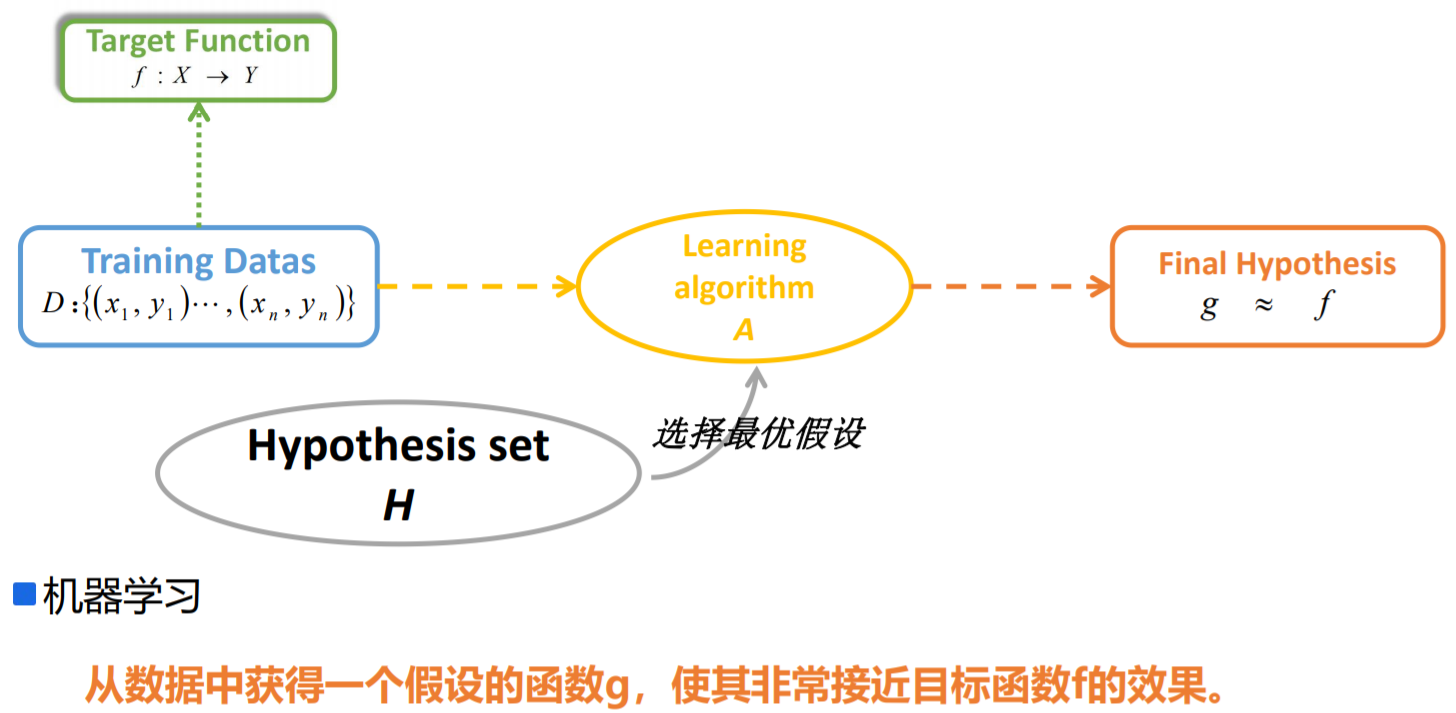
机器学习概念
A program can be said to learn from experience E with respect to some class of tasks T and performance measure P , If its performance at tasks in T, as measured by P, improves with experience E.
对于某给定的任务T,在合理的性能度量方案P的前提下,某计算机程序可以自主学习任 务T的经验E;随着提供合适、优质、大量的经验E,该程序对于任务T的性能逐步提高。
其中重要的机器学习对象:
- 任务Task T,一个或多个、经验Experience E、度量性能Performance P
- 即:随着任务的不断执行,经验的累积会带来计算机性能的提升。
- 美国卡内基梅隆大学(Carnegie Mellon University)机器学习研究领域的著名教授Tom Mitchell对机器学习的经典定义。
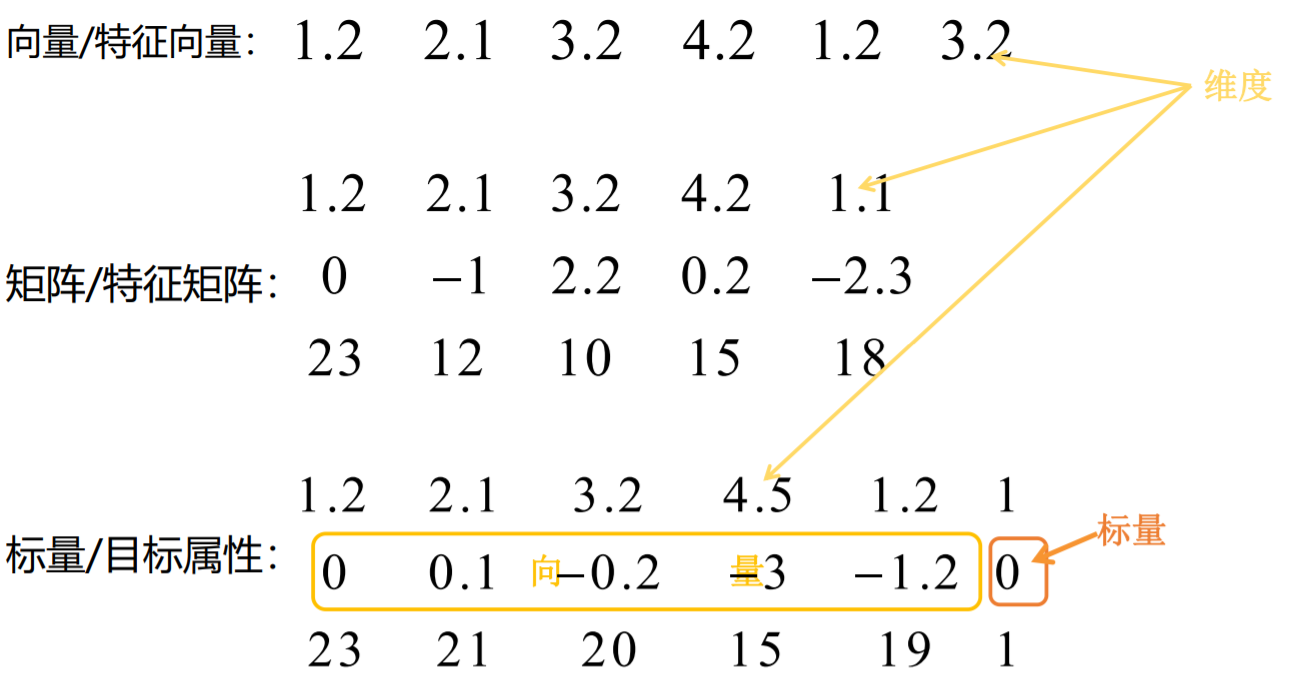

机器学习之常见应用框架
scikit-learn(Python)(授课环境)
https://scikit-learn.org/stable/
建议Anaconda安装方式;pip不建议,pip案例命令:pip install scikit-learn==0.18.1
Mahout(Hadoop生态圈基于MapReduce)
Spark MLlib
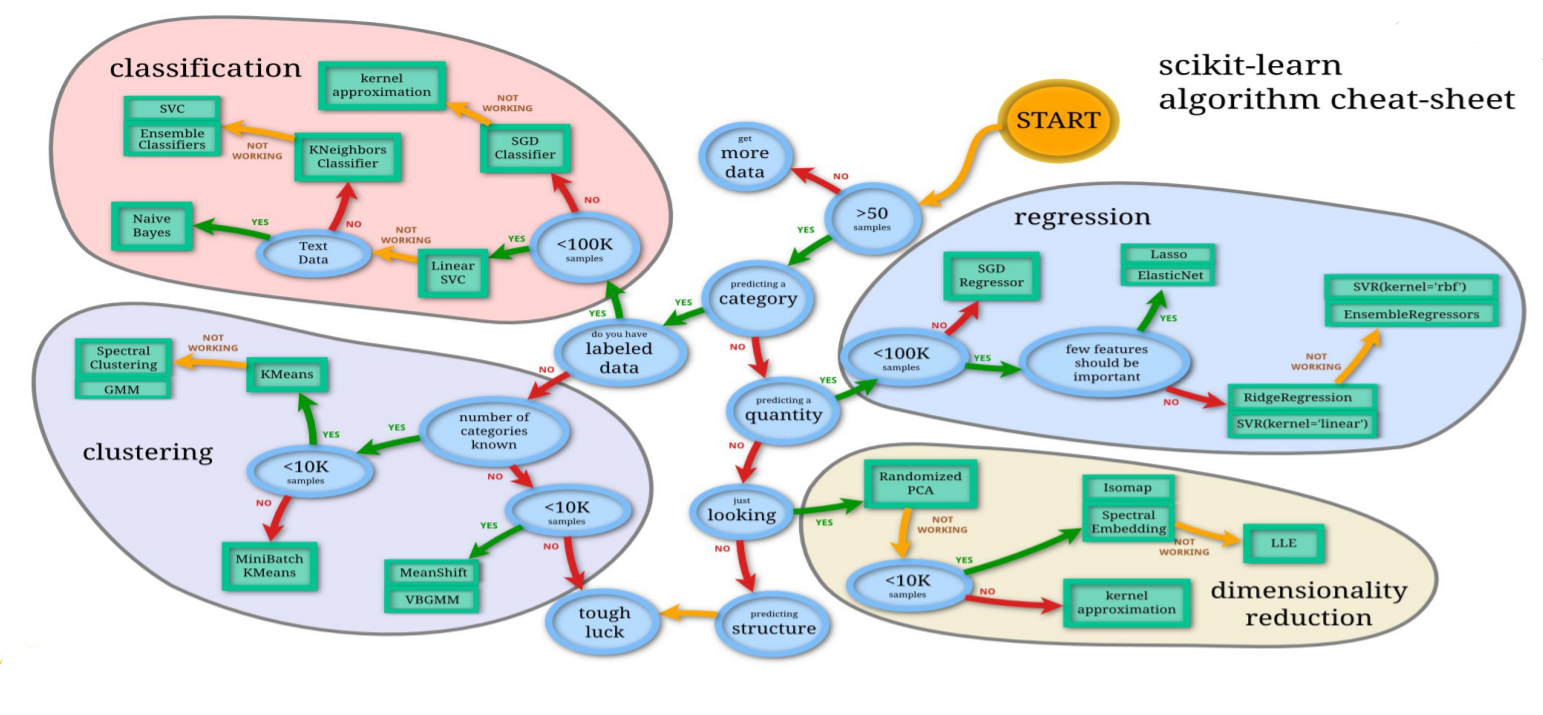
https://scikit-learn.org/stable/tutorial/machine_learning_map/index.html
机器学习、人工智能和深度学习的关系
深度学习是机器学习的子类;深度学习是基于传统的神经 网络算法发展到多隐层的一 种算法体现。
机器学习是人工智能的一个 子类;

机器学习基本概念和常用的应用场景


机器学习、数据分析、数据挖掘的区别与联系
数据分析:数据分析是指用适当的统计分析方法对收集的大量数据进行分析,并 提取有用的信息,以及形成结论,从而对数据进行详细的研究和概括过程。在实 际工作中,数据分析可帮助人们做出判断;数据分析一般而言可以分为统计分析、 探索性数据分析和验证性数据分析三大类。
数据挖掘:一般指从大量的数据中通过算法搜索隐藏于其中的信息的过程。通常 通过统计、检索、机器学习、模式匹配等诸多方法来实现这个过程。
机器学习:是数据分析和数据挖掘的一种比较常用、比较好的手段。
机器学习分类 机器学习概述
有监督学习:用已知某种或某些特性的样本作为训练集,以建立一个数学模型,再用已建立的模型来预 测未知样本,此种方法被称为有监督学习,是最常用的一种机器学习方法。是从标签化训 练数据集中推断出模型的机器学习任务。
- 判别式模型(Discriminative Model):直接对条件概率p(y|x)进行建模,常见判别模型有: Logistic回归、决策树、支持向量机SVM、k近邻、神经网络等;
- 生成式模型(Generative Model):对联合分布概率p(x,y)进行建模,常见生成式模型有: 隐马尔可夫模型HMM、朴素贝叶斯模型、高斯混合模型GMM、LDA等;
- 生成式模型更普适;判别式模型更直接,目标性更强。
- 生成式模型关注数据是如何产生的,寻找的是数据分布模型;判别式模型关注的数据的 差异性,寻找的是分类面。
- 由生成式模型可以产生判别式模型,但是由判别式模式没法形成生成式模型。
无监督学习:与监督学习相比,无监督学习的训练集中没有人为的标注的结果,在非监督的学习过程中, 数据并不被特别标识,学习模型是为了推断出数据的一些内在结构。
- 无监督学习试图学习或者提取数据背后的数据特征,或者从数据中抽取出重要的 特征信息,常见的算法有聚类、降维、文本处理(特征抽取)等。
- 无监督学习一般是作为有监督学习的前期数据处理,功能是从原始数据中抽取出 必要的标签信息。
半监督学习:考虑如何利用少量的标注样本和大量的未标注样本进行训练和分类的问题,是有监督学习 和无监督学习的结合
- 主要考虑如何利用少量的标注样本和大量的未标注样本进行训练和分类的问题。 半监督学习对于减少标注代价,提高学习机器性能具有非常重大的实际意义。
- SSL的成立依赖于模型假设,主要分为三大类:平滑假设、聚类假设、流行假设; 其中流行假设更具有普片性。
- SSL类型的算法主要分为四大类:半监督分类、半监督回归、半监督聚类、半监 督降维。
- 缺点:抗干扰能力弱,仅适合于实验室环境,其现实意义还没有体现出来;未来 的发展主要是聚焦于新模型假设的产生。
分类:通过分类模型,将样本数据集中的样本映射到某个给定的类别中(在模型构建之前,类别信息已经 确定了。),目标属性分布为离散型的。
聚类:通过聚类模型,将样本数据集中的样本分为几个类别,属于同一类别的样本相似性比较大。
回归:反映了样本数据集中样本的属性值的特性,通过函数表达样本映射的关系来发现属性值之间的依 赖关系。目标属性分布为连续型的。
关联规则:获取隐藏在数据项之间的关联或相互关系,即可以根据一个数据项的出现推导出其他数据项的出现频率。
机器学习开发流程
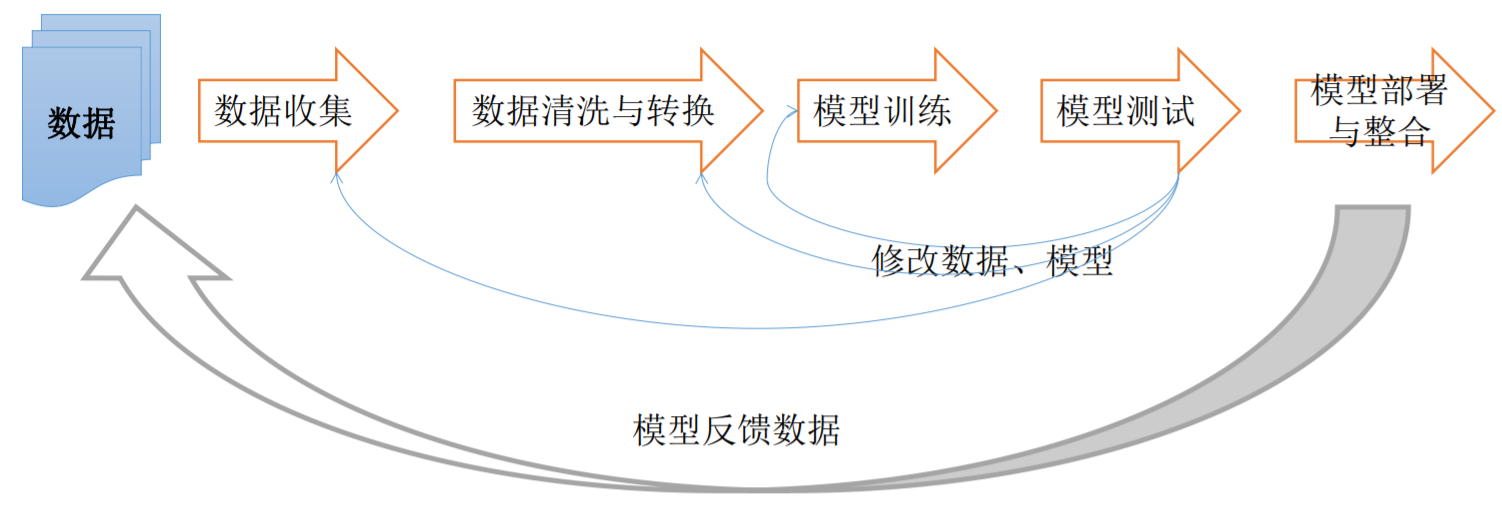
数据收集
数据来源
- 用户访问行为数据
- 业务数据
- 外部第三方数据
数据存储
- 需要存储的数据:原始数据、预处理后数据、模型结果
- 存储设施:mysql、HDFS、HBase、Solr、Elasticsearch、Kafka、Redis、磁盘等
数据收集方式: Flume & Kafka。
机器学习可用公开数据集
- https://archive.ics.uci.edu/ml/index.php
- https://registry.opendata.aws/
- https://www.kaggle.com/competitions
- https://www.kdnuggets.com/datasets/index.html
- http://www.sogou.com/labs/resource/list_pingce.php
- https://tianchi.aliyun.com/dataset/
- https://www.pkbigdata.com/common/cmptIndex.html
- https://www.kesci.com/
数据预处理
实际生产环境中机器学习比较耗时的一部分。
大部分的机器学习模型所处理的都是特征,特征通常是输入变量所对应的可用于模型的。数值表示。
大部分情况下 ,收集得到的数据需要经过预处理后才能够为算法所使用,预处理的操作 主要包括以下几个部分:
- 数据过滤
- 处理数据缺失
- 处理可能的异常、错误或者异常值
- 合并多个数据源数据
- 数据汇总
对数据进行初步的预处理,需要将其转换为一种适合机器学习模型的表示形式, 对许多模型类型来说,这种表示就是包含数值数据的向量或者矩阵。
- 将类别数据编码成为对应的数值表示(一般使用1-of-k方法)。
- 从文本数据中提取有用的数据(一般使用词袋法或者TF-IDF)。
- 处理图像或者音频数据(像素、声波、音频、振幅等<傅里叶变换>)。
- 对特征进行正则化、标准化,以保证同一模型的不同输入变量的取值范围相同
- 数值数据转换为类别数据以减少变量的值,比如年龄分段。
- 对数值数据进行转换,比如对数转换。
- 对现有变量进行组合或转换以生成新特征,比如平均数 (做虚拟变量)不断尝试。
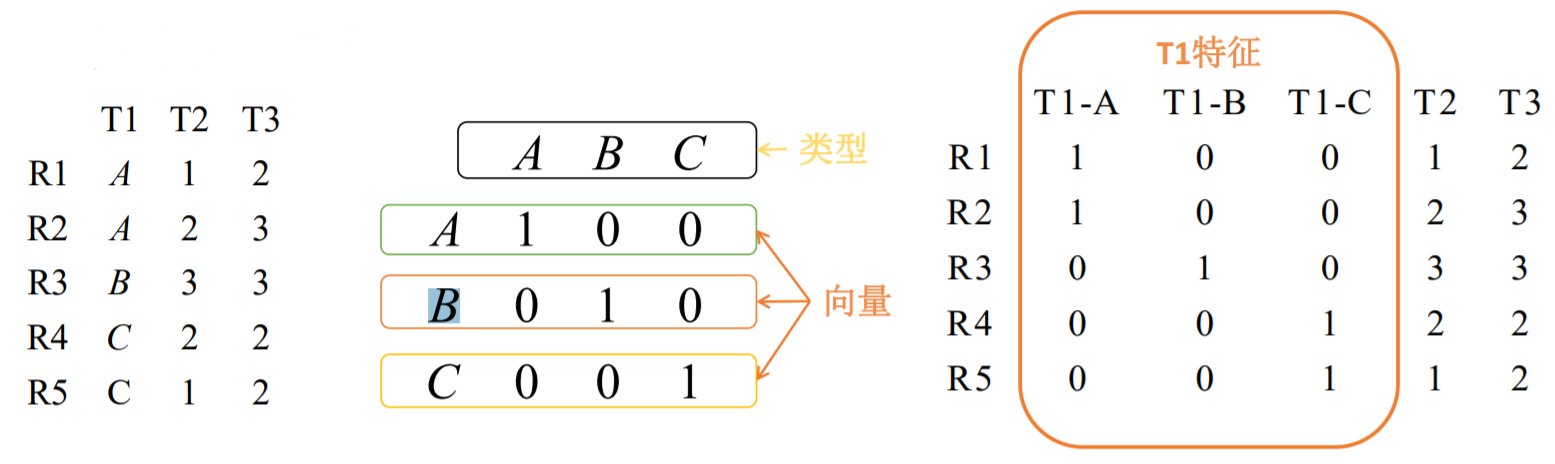
类型特征转换之1-of-k(哑编码)
功能:将非数值型的特征值(类别特征值)转换为数值型的数据。
描述:假设变量的取值有 k 个,如果对这些值用 1 到 k 编序,则可用维度为 k 的向量来表示一个变量的值。在这样的向量里,该取值所对应的序号所在的元素 为1,其他元素均为0.
词袋法:将文本当作一个无序的数据集合,文本特征可以采用文本中的词条T进 行体现,那么文本中出现的所有词条及其出现的次数就可以体现文档的特征。
TF-IDF:词条的重要性随着它在文件中出现的次数成正比增加,但同时会随着它 在语料库/所有文本中出现的频率成反比下降;也就是说词条在当前文本中出现 的次数越多,表示该词条对当前文本的重要性越高,词条在所有文本(语料库)中 出现的文件次数越少,说明这个词条对文本的重要性越高。TF(词频)指某个词条 在文本中出现的次数,一般会将其进行归一化处理(该词条数量/该文档中所有词条数量,即转换成为频率);IDF(逆向文件频率)指一个词条重要性的度量,一般 计算方式为语料库中总文件数目除以包含该词语的文件数目,再将得到的商取对数得到。TF-IDF实际上是:TF * IDF,即:(该词条数量/该文档中所有词条数量)* log(语料库中总文件数目/包含该词语的文件数目)。

特征选择和特征提取
特征选择(feature selection)和特征提取(Feature extraction)都属于降维(Dimension reduction)。特征选择是呆在原始世界中,只是想对现有的“取其精华,去其糟粕”,这个是所谓特征选择。只是对现有进行筛选。特征提取是从杂乱无章的世界中,去到更高层的世界去俯瞰原始世界,你会发现很多杂乱无章的物理现象中背后暗含的道理是想通的,这时候你想用一个更加普世的观点和理论去解释原先的理论,这个是特征提取要做的事情。
这两者达到的效果是一样的,就是试图去减少特征数据集中的属性(或者称为特征)的数目;但是两者所采用的方式方法却不同:
- 特征提取的方法:主要是通过属性间的关系,如组合不同的属性得到新的属性,这样就改变了原来的特征空间。
- 特征选择的方法:是从原始特征数据集中选择出子集,是一种包含的关系,没有更改原始的特征空间。
特征选择的方法
1、Filter(过滤)方法
其主要思想是:对每一维的特征“打分”,即给每一维的特征赋予权重,这样的权重就代表着该维特征的重要性,然后依据权重排序。
主要的方法有:Chi-squared test(卡方检验),ID3(信息增益)
correlation coefficient scores(相关系数)
2、Wrapper(封装)方法:
其主要思想是:将子集的选择看作是一个搜索寻优问题,生成不同的组合,对组合进行评价,再与其他的组合进行比较。这样就将子集的选择看作是一个是一个优化问题,这里有很多的优化算法可以解决,尤其是一些启发式的优化算法,如GA,PSO,DE,ABC等,详见“优化算法——人工蜂群算法(ABC)”,“优化算法——粒子群算法(PSO)”。
主要方法有:recursive feature elimination algorithm(递归特征消除算法)
3、Embedded(嵌入)方法
其主要思想是:在模型既定的情况下学习出对提高模型准确性最好的属性。这句话并不是很好理解,其实是讲在确定模型的过程中,挑选出那些对模型的训练有重要意义的属性。
主要方法:正则化。如岭回归就是在基本线性回归的过程中加入了正则项。
特征提取的主要方法
PCA,LDA,SVD等。(SVD本质上是一种数学的方法, 它并不是一种什么机器学习算法,但是它在机器学习领域里有非常广泛的应用)
图像的经典特征提取方法:
- HOG(histogram of Oriented Gradient,方向梯度直方图)
- SIFT(Scale-invariant features transform,尺度不变特征变换)
- SURF(Speeded Up Robust Features,加速稳健特征,对sift的改进)
- DOG(Difference of Gaussian,高斯函数差分)
- LBP(Local Binary Pattern,局部二值模式)
- HAAR(haar-like ,haar类特征,注意haar是个人名,haar这个人提出了一个用作滤波器的小波,为这个滤波器命名为haar滤波器,后来有人把这个滤波器用到了图像上,就是图像的haar特征)
https://blog.csdn.net/LUFANGBO/article/details/82491680
https://blog.csdn.net/yuanlulu/article/details/82148429
图像的一般提取特征方法:
- 灰度直方图,颜色直方图
- 均值,方差
- 信号处理类的方法:灰度共生矩阵,Tamura纹理特征,自回归纹理特征,小波变换。
- 傅里叶形状描述符,小波描述符等,
模型构建
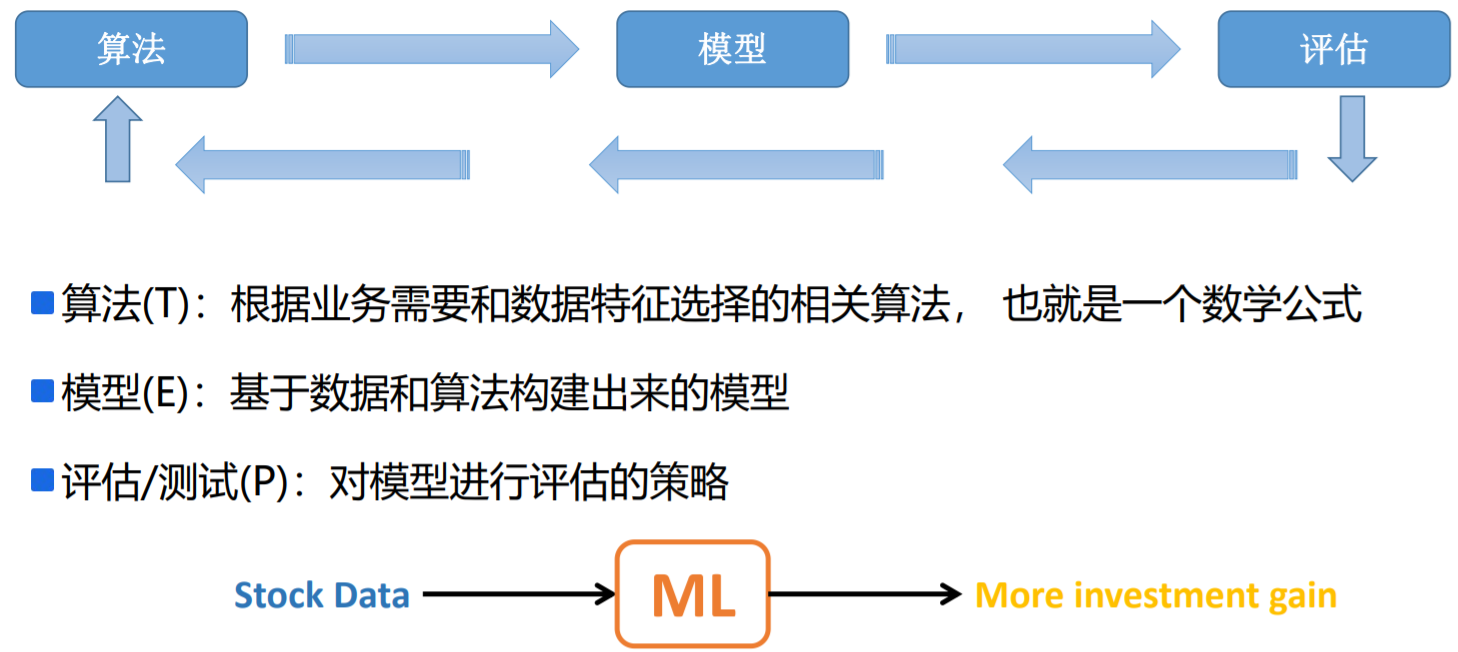
模型选择:对特定任务最优建模方法的选择或者对特定模型最佳参数的选择。
在模型训练之前,会将数据分为训练集和测试集,训练集主要用于模型的训练, 当模型训练好后,会使用测试集来验证模型的效果;如果模型效果不好的话,那 么需要重新更改数据、更改特征工程或者更改模型参数,来重新训练模型;如果 测试集验证效果不错的话,那么进入模型的部署和应用阶段。
训练模型的时候,对于模型参数的选择,可以在训练数据集上运行模型(算法)并 在测试数据集中效果,自动迭代进行数据模型的修改,最终返回模型效果最优的 模型参数,这种方式被称为交叉验证(将训练集数据分为子训练集和验证集,使 用子训练集构建模型,并使用验证集评估模型)-->交叉验证操作可选。
模型的选择会尽可能多的选择算法进行执行,并比较执行结果。
机器学习中的常用算法

模型测试评估
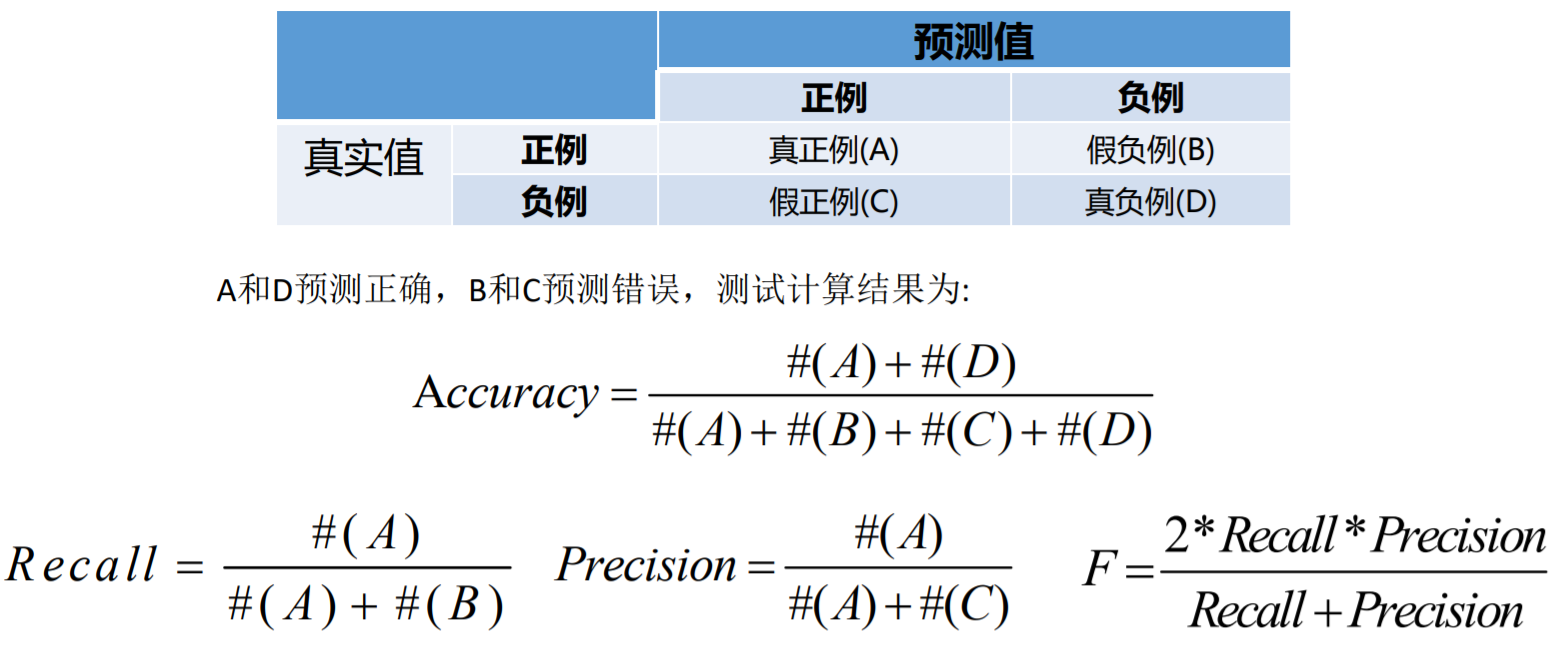
分类应用的模型中测试评估指标一般以以下几个方面来进行比较,分别是准确率 /召回率/精准率/F值。
- 准确率(Accuracy)=预测正确样本数/总样本数。
- 召回率(Recall)=预测正确的正例样本数/样本中的正例样本数——覆盖率。
- 精准率(Precision)=预测正确的正例样本数/预测为正例的样本数。
- F值(F1)=Precision*Recall*2 / (Precision+Recall) (即F值为精准率和召回率的调 和平均值)
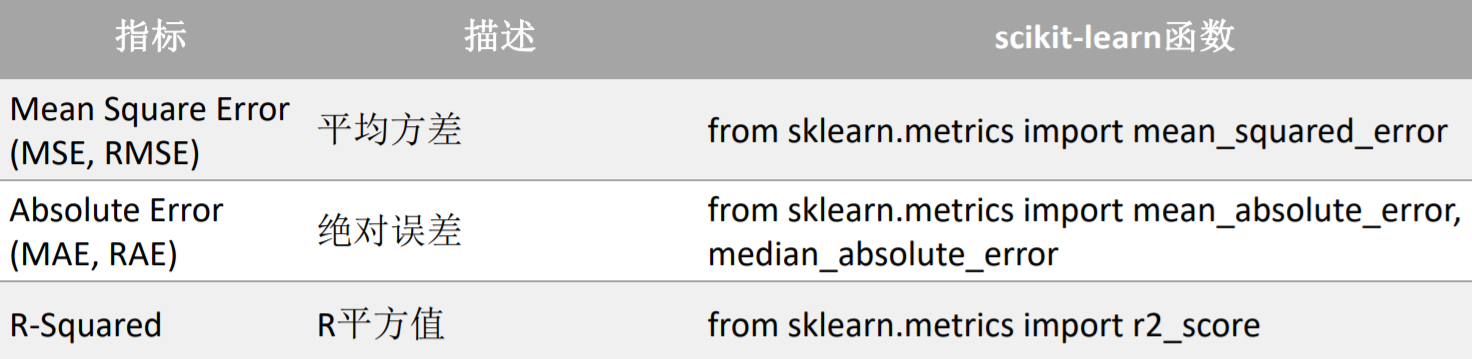
回归应用的模型中测试评估指标一般以以下几个方面来进行比较,分别是: RMSE、MSE、MAE、R2。
ROC曲线
ROC(Receiver Operating Characteristic)最初源于20世纪70年代的信号 检测理论,描述的是分类混淆矩阵中FPR-TPR两个量之间的相对变化情况, ROC曲线的纵轴是“真正例率”(True Positive Rate 简称TPR),横轴是“假 正例率” (False Positive Rate 简称FPR)。
如果二元分类器输出的是对正样本的一个分类概率值,当取不同阈值时会 得到不同的混淆矩阵,对应于ROC曲线上的一个点。那么ROC曲线就反映了 FPR与TPR之间权衡的情况,通俗地来说,即在TPR随着FPR递增的情况下,谁 增长得更快,快多少的问题。TPR增长得越快,曲线越往上屈,AUC就越大, 反映了模型的分类性能就越好。当正负样本不平衡时,这种模型评价方式比起 一般的精确度评价方式的好处尤其显著。
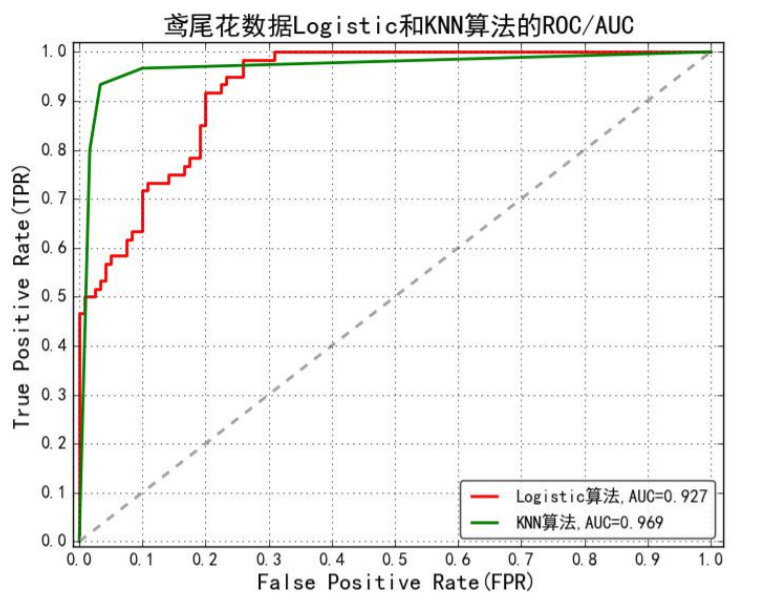
AUC(Area Under Curve)被定义为ROC曲线下的面积,显然这个 面积的数值不会大于1。又由于ROC曲线一般都处于y=x这条直线的 上方,所以AUC的取值范围在0.5和1之间。使用AUC值作为评价标准 是因为很多时候ROC曲线并不能清晰的说明哪个分类器的效果更好, 而AUC作为数值可以直观的评价分类器的好坏,值越大越好。
- AUC = 1,是完美分类器,采用这个预测模型时,不管设定什么阈值 都能得出完美预测。绝大多数预测的场合,不存在完美分类器。
- 0.5 < AUC < 1,优于随机猜测。这个分类器(模型)妥善设定阈值 的话,能有预测价值。
- AUC = 0.5,跟随机猜测一样(例:丢铜板),模型没有预测价值。
- AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机
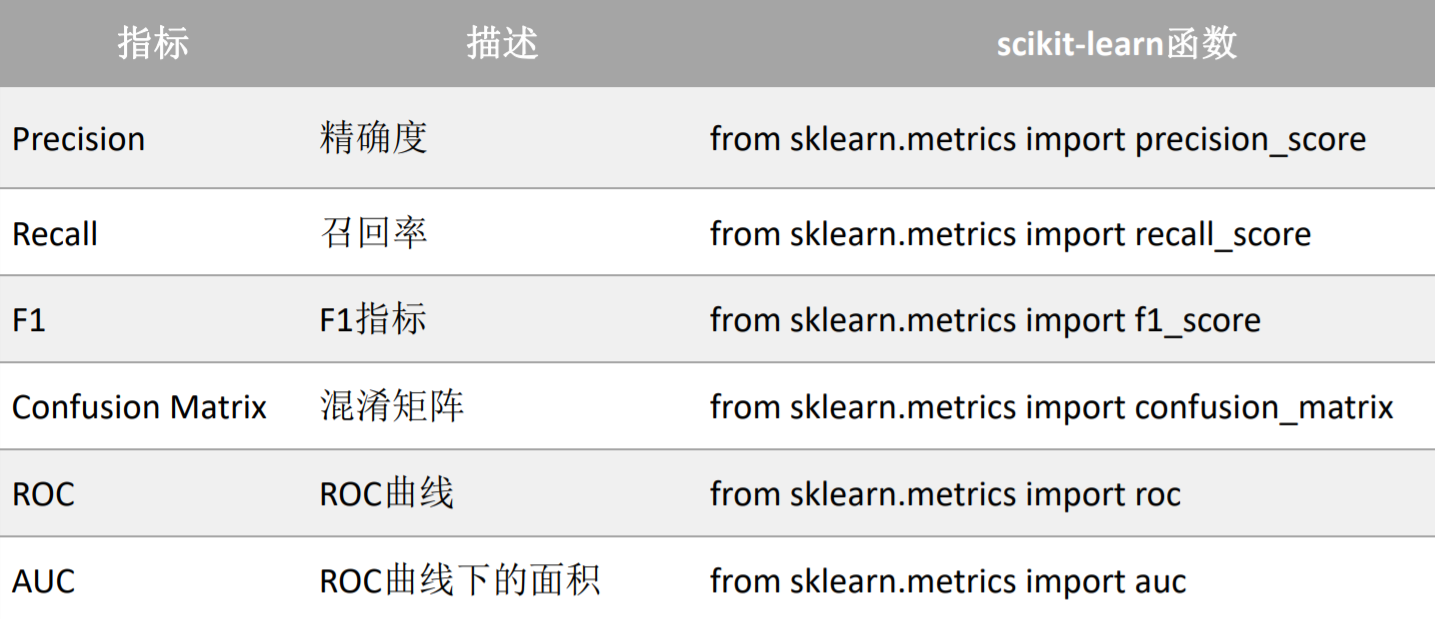
模型评估总结 EDUCATION TO CREATE A BRIGHT FUTURE _分类算法评估方式
模型评估总结 EDUCATION TO CREATE A BRIGHT FUTURE _回归算法评估方式
投入使用(模型部署与整合)
当模型构建好后,将训练好的模型存储到数据库、磁盘中,方便其它使用模型的 应用加载(构建好的模型一般为一个矩阵);也有可能我们提供一个用于模型预测 的rest api(web端的一个应用)。
模型需要周期性的调整,一般周期为:一个月、一周
迭代优化
当模型一旦投入到实际生产环境中,模型的效果监控是非常重要的,往往需要关 注业务效果和用户体验,所以有时候会进行A/B测试。
模型需要对用户的反馈进行响应操作,即进行模型修改,但是要注意异常反馈信 息对模型的影响,故需要进行必要的数据预处理操作。
机器学习实现代码的流程
# 一、加载数据 # 二、基于业务提取最原始的特征属性X和目标属性Y # 三、数据的清洗 """ 可选操作 比如异常数据的处理,缺省数据的填充.... """ # 四、数据的划分(将数据划分为训练集和测试集) # 五、特征工程 """ 可选操作 主要就是一些:哑编码、TF-IDF、连续数据的离散化、标准化、归一化、特征选择、降维.... """ # 六、算法模型的选择/算法模型对象的构建 # 七、算法模型的训练 # 八、模型效果评估 # 九、模型保存

 浙公网安备 33010602011771号
浙公网安备 33010602011771号