#tesk3.py
with open('data3.txt','r+', encoding='UTF-8') as f:
Z=[]
Y=[]
x=[]
for i in f:
x.append(i.strip('\n'))
newx=x[1:11]
for i in newx:
y=float(i)
Y.append(y)
if y-int(y) >= 0.5:
y=int(y)+1
else:
y=int(y)
Z.append(y)
print(f'原始数据\n{Y}')
print(f'四舍五入后的数据\n{Z}')
with open('data3_processed.txt','w',encoding='utf-8') as f:
write1=['原始数据']+Y
write2=['四舍五入后的数据']+Z
for i in range (len(Y)):
f.write(f'{write1[i]}\t{write2[i]}\n')
![]()
![]()
#test.4.py
with open('data4.txt', 'r', encoding = 'utf-8') as f:
Y=[]
l=[]
t=[]
e=[]
data=f.readlines()
for i in data:
i=i.split()
Y.append(i)
Y.remove(Y[0])
newlist1=sorted(Y,key=(lambda x : x[2]))
for i in range (0,8):
l.append(newlist1[i])
l1=sorted(l,key=(lambda x : x[3]),reverse=True)
for i in range (8,10):
t.append(newlist1[i])
l2=sorted(t,key=(lambda x : x[3]),reverse=True)
X=l1+l2
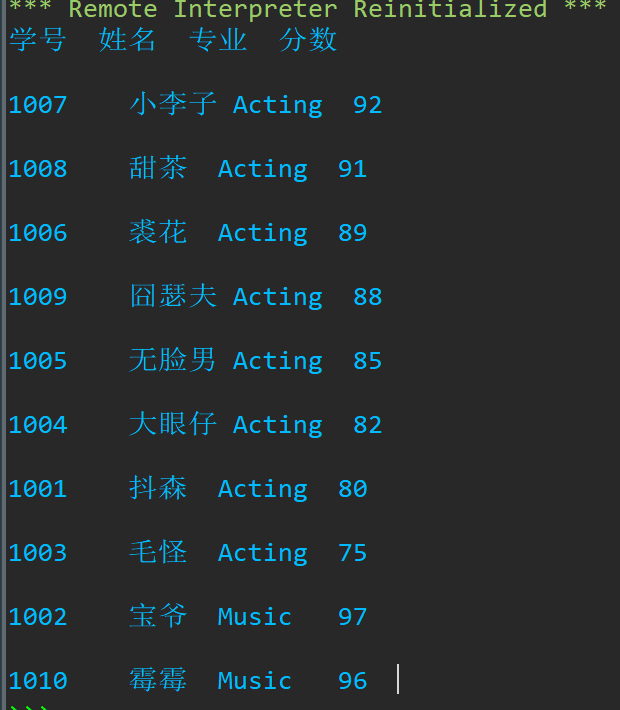
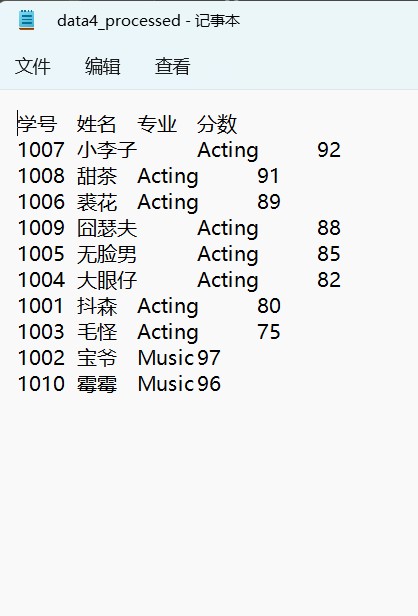
for i in X:
i1='\t'.join(i)
i1=i1+'\n'
e.append(i1)
e.insert(0,'学号\t姓名\t专业\t分数\n')
for i in e:
print(i)
with open('data4_processed.txt','w',encoding='utf-8') as f:
for i in e:
f.write(i)
![]()
![]()
#test.5py
with open('data5.txt', 'r+', encoding = 'utf-8') as f:
data=f.read()
print('行数',len(data.splitlines()))
print('单词数',len(data.split()))
s=0
for i in data:
if i.isspace():
s=s+1
print('空格数',s)
print('字符数',len(data))
with open('data5_with_line.txt', 'w+', encoding = 'utf-8') as f:
for i in range(len(data.splitlines())):
f.write(str(i+1)+' '+str(data.splitlines()[i])+'\n')
![]()
![]()





 浙公网安备 33010602011771号
浙公网安备 33010602011771号