Coursera - 机器学习基石 - 林轩田 | 作业一 - 题目 & 答案 & 解析
 分享 Coursera 上林轩田老师的机器学习基石作业一,自己的做题思路、代码和原题目。个人基础不好,比较啰嗦,不过也许是好事。
分享 Coursera 上林轩田老师的机器学习基石作业一,自己的做题思路、代码和原题目。个人基础不好,比较啰嗦,不过也许是好事。
机器学习基石 | 作业一
个人基础不太好,做题花了挺长时间,分享一下自己的解题方法。基础不太好嘛,可能比较啰嗦。
原题目和编程题的程序(Jupyter Notebook 源文件),还有本解答的 PDF 版本都放在了 此链接 中。
题目
见文件 作业一_Coursera_2020-03-23.html
Q1
§ Q1 题目
Which of the following problems are best suited for machine learning?
(i) Classifying numbers into primes and non-primes
(ii) Detecting potential fraud in credit card charges
(iii) Determining the time it would take a falling object to hit the ground
(iv) Determining the optimal cycle for traffic lights in a busy intersection
(v) Determining the age at which a particular medical test is recommended
🔘 (i) and (ii)
🔘 (ii), (iv), and (v)
🔘 none of the other choices
🔘 (i), (ii), (iii), and (iv)
🔘 (i), (iii), and (v)
Q1 解析
(i) ✖️ 判断一个数是否为质数。这个问题可以简单地用编程实现,比如:判断一个数是否只能被 1 和它自身整除。
(ii) ✔️ 检测潜在的信用卡诈骗问题。
(iii) ✖️ 确定物体下落到地面的时间。自由落体运动可以简单地用编程实现:\(h = \frac{1}{2}gt^2\)
(iv) ✔️ 确定繁忙交通路口的最佳交通信号灯周期。
(v) ✔️ 确定某种医疗检查的推荐年龄。
Q1 知识点
Key Essence of Machine Learning: Machine Learning Foundations - Slide 01 - P10
- exists some ‘underlying pattern’ to be learned
—so ‘performance measure’ can be improved - but no programmable (easy) definition
—so ‘ML’ is needed - somehow there is data about the pattern
—so ML has some ‘inputs’ to learn from
Q2-Q5
For Questions 2-5, identify the best type of learning that can be used to solve each task below.
§ Q2 题目
Play chess better by practicing different strategies and receive outcome as feedback.
🔘 active learning
🔘 reinforcement learning
🔘 supervised learning
🔘 none of other choices
🔘 unsupervised learning
Q2 解析
本题目的关键点在于 receive outcome as feedback,强化学习通过接收环境对动作的奖励(反馈)获得学习信息并更新模型参数。
Q2 知识点
Learning with Different Data Label \(y_n\): Machine Learning Foundations - Slide 03 - P14
- supervised: all \(y_n\)
- unsupervised: no \(y_n\)
- semi-supervised: some \(y_n\)
- reinforcement: implicit \(y_n\) by goodness(\(\widetilde{y}_n\))
§ Q3 题目
Categorize books into groups without pre-defined topics.
🔘 none of other choices
🔘 active learning
🔘 unsupervised learning
🔘 supervised learning
🔘 reinforcement learning
Q3 解析
本题关键在于 without pre-defined topics,是典型的非监督学习中的聚类学习问题。
Q4 题目
Recognize whether there is a face in the picture by a thousand face pictures and ten thousand non-face pictures.
🔘 unsupervised learning
🔘 supervised learning
🔘 active learni
🔘 reinforcement learning
🔘 none of other choices
Q4 解析
face 和 non-face 都是给图片打的标签,本题是典型的监督学习问题。
§ Q5 题目
Selectively schedule experiments on mice to quickly evaluate the potential of cancer medicines.
🔘 reinforcement learning
🔘 unsupervised learning
🔘 supervised learning
🔘 active learning
🔘 none of other choices
Q5 解析
slides 中对主动学习(active learning)的定义是:improve hypothesis with fewer labels
(hopefully) by asking questions strategically.
Active Learning 的主要方式是模型通过与用户或专家进行交互,抛出 “query” (unlabel data) 让专家来确定数据的标签,如此反复,以期让模型利用较少的标记数据获得较好“性能”[1]。
本题可以理解为机器选择性地抛出“需要验证的可能会带来很大进展的实验”,让专家执行给出的实验判断其是否真的有用,将结果返回给机器以学习。
Q5 知识点
Learning with Different Protocol \(f \Rightarrow (\mathbf{x}_n, y_n)\): Machine Learning Foundations - Slide 03 - P20
- batch: all known data
- online: sequential (passive) data
- active: strategically-observed data
Q6-Q8
Question 6-8 are about Off-Training-Set error.
Let \(\mathcal{X} = \{\mathbf{x}_1,\mathbf{x}_2,\ldots,\mathbf{x}_N,\mathbf{x}_{N {\!+\!} 1},\ldots,\mathbf{x}_{N {\!+\!} L}\}\) and \(\mathcal{Y} = \{-1,+1\}\) (binary classification). Here the set of training examples is \(\mathcal{D}=\Bigl\{(\mathbf{x}_n,y_n)\Bigr\}^{N}_{n=1}\), where \(y_n \in \mathcal{Y}\), and the set of test inputs is \(\Bigl\{\mathbf{x}_{N {\!+\!} \ell}\Bigr\}_{\ell=1}^L\). The Off-Training-Set error (\(\mathit{OTS}\;\)) with respect to an underlying target \(\mathit{f}\;\) and a hypothesis \(\mathit{g}\;\) is \(E_{OTS}(g, f)= \frac{1}{L} \sum_{\ell=1}^{L}\bigl[\bigl[ g(\mathbf{x}_{N {\!+\!} \ell}) \neq f(\mathbf{x}_{N {\!+\!} \ell})\bigr]\bigr]\) .
§ Q6 题目
Consider \(f(\mathbf{x})=+1\) for all \(\mathbf(x)\) and \(g(\mathbf{x})=\left \{\begin{array}{cc}+1, & \mbox{ for } \mathbf{x} = \mathbf{x}_k \mbox{ and } k \mbox{ is odd } \mbox{ and } 1 \le k \le N+L\\-1, & \mbox{ otherwise}\end{array}\right.\)
\(E_{OTS}(g,f)=?\) (Please note the difference between floor and ceiling functions in the choices)
🔘 \({\frac{1}{L} \times ( \lfloor \frac{N+L}{2} \rfloor - \lceil \frac{N}{2} \rceil )}\)
🔘 \({\frac{1}{L} \times ( \lceil \frac{N+L}{2} \rceil - \lceil \frac{N}{2} \rceil )}\)
🔘 \({\frac{1}{L} \times ( \lceil \frac{N+L}{2} \rceil - \lfloor \frac{N}{2} \rfloor )}\)
🔘 \({\frac{1}{L} \times ( \lfloor \frac{N+L}{2} \rfloor - \lfloor \frac{N}{2} \rfloor )}\)
🔘 none of the other ch oices
Q6 解析
这其实是一道阅读理解题 😆
一起读一下题:
- 第一句话表明这是一个二分类问题
- 第二句话表明数据分为两部分:
- 训练集 \(\mathcal{D}\) - 从 \(\mathbf{x}_1\) 到 \(\mathbf{x}_N\) (含对应的 \(y\) 标签)总共 \(N\) 个样本
- 测试集 - 从 \(\mathbf{x}_{N\!+\!1}\) 到 \(\mathbf{x}_{N\!+\!L}\) (含对应的 \(y\) 标签)总共 \(L\) 个样本
- 第三句话在讲什么是 Off-Training-Set error, 就是 \(g\) 在测试集上的错误率,即在 \(g\) 测试集上错误点的个数除以测试集总样本数
- 第四句话说 \(f\) 恒为 \(+1\); \(g\) 在整个数据集上第奇数个 \(\mathbf{x}\) 上是 \(+1\),在第偶数个 \(\mathbf{x}\) 上是 \(-1\)
- 求 \(E_{OTS}(g, f)\). 由第四句我们知道 \(g\) 在第偶数个 \(\mathbf{x}\) 时是错的(与 \(f\) 值不相等)
所以这题目这么长,竟然就在考 \(N+1\) 到 \(N+L\) 总共有多少个偶数???
下面来解题:
- (\(N\!+\!1\) 到 \(N\!+\!L\) 偶数的个数) = (\(1\) 到 \(N\!+\!L\) 偶数个数) - (\(1\) 到 \(N\) 偶数个数)
- 上式右侧等式减号两边用的是同样的算法,排除选项中两个前后
floorceiling不同的选项 - \(1\) 到 \(N\) 有多少个偶数?想不明白的用赋值法,假如 \(N = 2\),那么有 \(1\) 个偶数,正好是 \(\frac{N}{2}\);假如 \(N=3\),那么还是只有一个偶数,\(\frac{N}{2} = 1.5\) 需要向下取整为 \(1\),故该项为 \(\lfloor{\frac{N}{2}}\rfloor\)
§ Q7 题目
We say that a target function \(f\) can "generate'' \(\mathcal{D}\) in a noiseless setting if $f(\mathbf{x}_n) = y_n $for all \((\mathbf{x}_n,y_n) \in \mathcal{D}\).
For all possible \(f: \mathcal{X} \rightarrow \mathcal{Y}\), how many of them can generate \(\mathcal{D}\) in a noiseless setting?
Note that we call two functions \(f_1\) and \(f_2\) the same if \(f_1(\mathbf{x})=f_2(\mathbf{x})\) for all \(\mathbf{x} \in \mathcal{X}\).
🔘 \(1\)
🔘 \(2^L\)
🔘 \(2^{N+L}\)
🔘 none of the other choices
🔘 \(2^N\)
Q7 解析
这仍然是一道阅读理解题。
读题:
- 第一句解释了 \(f\) can "generate'' \(\mathcal{D}\) in a noiseless setting 的定义:在训练集 \(\mathcal{D}\) 上,对所有样本都有\(f(\mathbf{x}_n)=y_n\).
- 结合上一题信息:
- 训练集 \(\mathcal{D}\) - 从 \(\mathbf{x}_1\) 到 \(\mathbf{x}_N\) (含对应的 \(y\) 标签)总共 \(N\) 个样本
- 测试集 - 从 \(\mathbf{x}_{N\!+\!1}\) 到 \(\mathbf{x}_{N\!+\!L}\) (含对应的 \(y\) 标签)总共 \(L\) 个样本
- 第三句说如果对整个数据集上(训练集 + 测试集)的 \(\mathbf{x}\),\(f(\mathbf{x}_n)=y_n\) 得到的 \(y\) 都是一样的话,那么称这些 \(f\) 是相同的
分析一下:
- \(f\) can "generate'' \(\mathcal{D}\) 说明这些 \(f\) 在 训练集上 所有数据是相同的
- 不同的 \(f\) 在 整个数据集(训练集 + 测试集) 上不能完全相同,又由于他们在训练集上相同,所以只能在 测试集上 不同
- 由上题信息,\(y\) 只能取 \(\left\{-1, +1\right\}\) ,测试集上有 \(L\) 个点,所以有 \(2^{L}\) 种不同的组合方式
§ Q8 题目
A determistic algorithm \(\mathcal{A}\) is defined as a procedure that takes \(\mathcal{D}\) as an input, and outputs a hypothesis \(g\). For any two deterministic algorithms \(\mathcal{A}_1\) and \(\mathcal{A}_2\), if all those \(f\) that can "generate'' \(\mathcal{D}\) in a noiseless setting are equally likely in probability,
🔘 For any given \(f\) that "generates" \(\mathcal{D}\), \(E_{OTS}(\mathcal{A}_1(\mathcal{D}), f) = E_{OTS}(\mathcal{A}_2(\mathcal{D}), f)\).
🔘 none of the other choices
🔘 \(\mathbb{E}_f\left\{E_{OTS}(\mathcal{A}_1(\mathcal{D}), f)\right\} = \mathbb{E}_f\left\{E_{OTS}(f, f)\right\}\)
🔘 \(\mathbb{E}_f\left\{E_{OTS}(\mathcal{A}_1(\mathcal{D}), f)\right\} = \mathbb{E}_f\left\{E_{OTS}(\mathcal{A}_2(\mathcal{D}), f)\right\}\)
🔘 For any given \(f'\) that does not "generate" \(\mathcal{D}\), \(\left\{E_{OTS}(\mathcal{A}_1(\mathcal{D}), f')\right\} = \left\{E_{OTS}(\mathcal{A}_2(\mathcal{D}), f')\right\}\)
Q8 解析
- \(\mathcal{D} \xrightarrow{\mathcal{A}} g\)
- 在训练集中,由于所有 \(f\) 等概,所以对任意一个样本点,\(f\) 为 \(-1\) 或 \(+1\) 的概率都为 \(\frac{1}{2}\),任一 \(g\) 在每个点上错误概率的期望都为 \(\frac{1}{2}\),因此对每个 \(\mathcal{A}\),对应的 \(E_{OTS}\) 的期望都相等
Q9-Q12
For Questions 9-12, consider the bin model introduced in class. Consider a bin with infinitely many marbles, and let \(\mu\) be the fraction of orange marbles in the bin, and \(\nu\) is the fraction of orange marbles in a sample of 10 marbles.
§ Q9 题目
If \(\mu = 0.5\), what is the probability of \(\nu=\mu\)? Please choose the closest number.
🔘 \(0.12\)
🔘 \(0.90\)
🔘 \(0.56\)
🔘 \(0.24\)
🔘 \(0.39\)
Q9 解析
\(\mu =\) fraction of orange marbles in bin
\(\nu =\) fraction of orange marbles in sample
\(n_{sample} = 10\)
题干中没有提到霍夫丁不等式的题目,都用普通的排列组合方法去求准确的答案。
题目可以理解为:在橙球概率为 \(0.5\) 的罐子中随机取出 \(10\) 个小球,其中有 \(5\) 个小球为橙球的概率是多少?
Q9 知识点
排列组合基础知识
放一张之前复习排列组合的思维导图,参考了 知乎 | 如何通俗的解释排列公式和组合公式的含义?- 浣熊老师的回答[2]
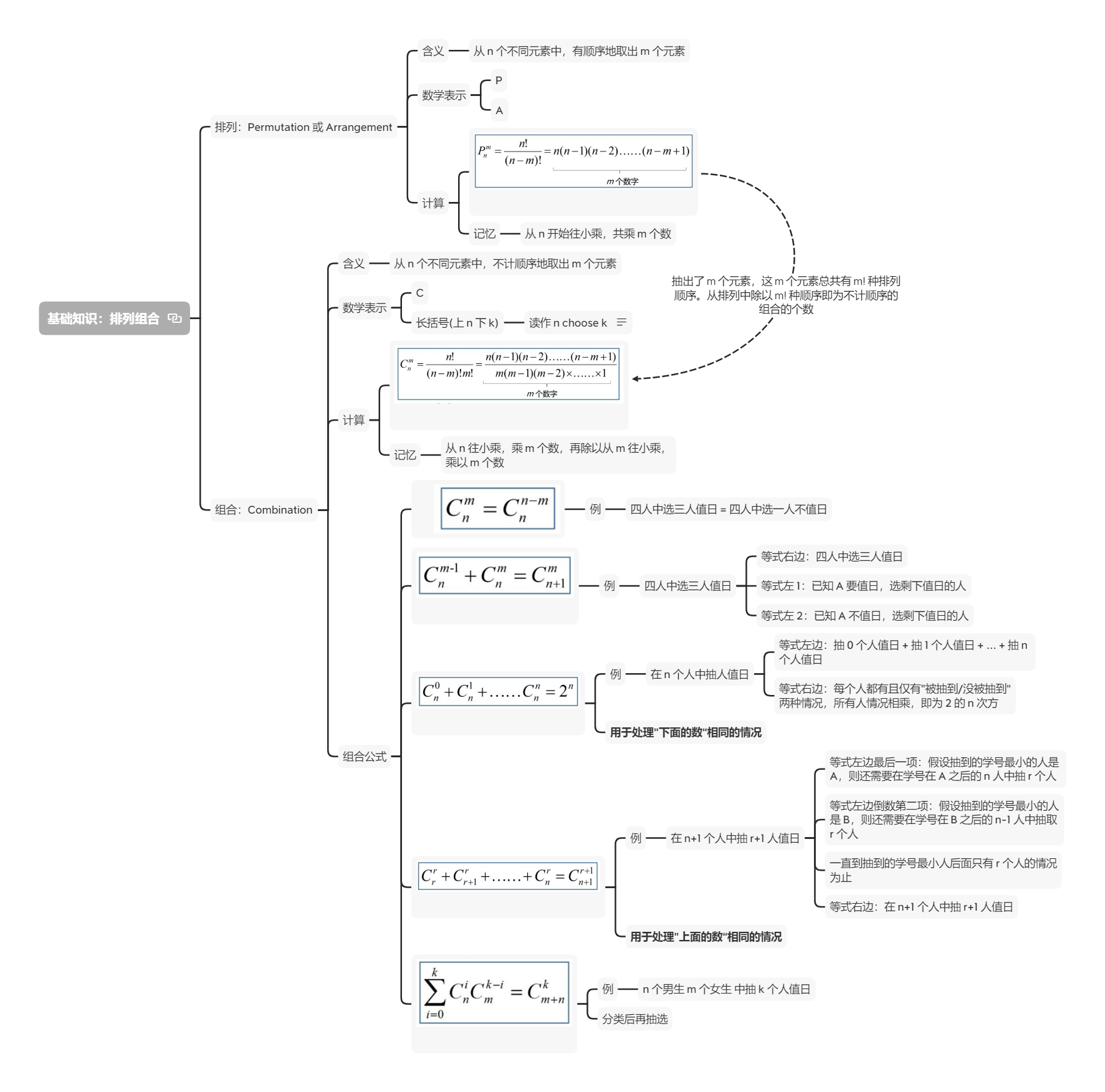
§ Q10 题目
If \(\mu = 0.9\), what is the probability of \(\nu=\mu\)? Please choose the closest number.
🔘 \(0.39\)
🔘 \(0.90\)
🔘 \(0.12\)
🔘 \(0.56\)
🔘 \(0.24\)
Q10 解析
解法同上题,只是换了个数据。
§ Q11 题目
If \(\mu = 0.9\), what is the actual probability of \(\nu \le 0.1\)?
🔘 \(9.1 \times 10^{-9}\)
🔘 \(0.1 \times 10^{-9}\)
🔘 \(4.8 \times 10^{-9}\)
🔘 \(1.0 \times 10^{-9}\)
🔘 \(8.5 \times 10^{-9}\)
Q11 解析
\(\nu \le 0.1\) 有两种情况:\(10\) 个球里只有 \(0\) 个或 \(1\) 个橙球。两种情况的概率相加即可。
§ Q12 题目
If \(\mu = 0.9\), what is the bound given by Hoeffding's Inequality for the probability of \(\nu \le 0.1\)?
🔘 \(5.52 \times 10^{-6}\)
🔘 \(5.52 \times 10^{-10}\)
🔘 \(5.52 \times 10^{-4}\)
🔘 \(5.52 \times 10^{-12}\)
🔘 \(5.52 \times 10^{-8}\)
Q12 解析
本题要计算的是代入霍夫丁不等式后得到的边界值,而不是计算实际的概率(如上题)。
霍夫丁不等式:\(P[|\nu - \mu| > \epsilon] \le 2\exp(-2{\epsilon^2}N)\).
\(\exp(n)\) 即 \(e^n\).
已知 \(\mu = 0.9\),要使 \(\nu \le 0.1\),需有 \(\epsilon \ge 0.8\).
等号右侧式子随 \(\epsilon\) 增加而减小,故在 \(\epsilon\) 取最小值 \(0.8\) 时得到式子的上界,代入 \(N = 10\),得到 \(2\exp(-2{\epsilon^2}N) = 5.52 \times 10^{-6}\)
Q12 知识点
Hoeffding’s Inequality: Machine Learning Foundations - Slide 04 - P11
Slide 04 - P13 的课后题,第 ③ ④ 选项知道分别是怎么得出的,就能举一反三求得 Q9-Q12.
Q13-Q14
Questions 13-14 illustrate what happens with multiple bins using dice to indicate 6 bins. Please note that the dice is not meant to be thrown for random experiments in this problem. They are just used to bind the six faces together. The probability below only refers to drawing from the bag.
Consider four kinds of dice in a bag, with the same (super large) quantity for each kind.
A: all even numbers are colored orange, all odd numbers are colored green
B: all even numbers are colored green, all odd numbers are colored orange
C: all small (1~3) are colored orange, all large numbers (4~6) are colored green
D: all small (1~3) are colored green, all large numbers (4~6) are colored orange
§ Q13 题目
If we pick \(5\) dice from the bag, what is the probability that we get \(5\) orange 1's?
🔘 \(\frac{1}{256}\)
🔘 \(\frac{8}{256}\)
🔘 \(\frac{31}{256}\)
🔘 \(\frac{46}{256}\)
🔘 none of the other choices
Q13 解析
注意理解题目 They are just used to bind the six faces together. 取出的每一个骰子,都有六面(六个数字),只是骰子每一面涂颜色的方法不同而已,不要理解为取一个骰子只能有一个数字。
| 骰子种类 | 抽到每种骰子的概率 | 骰子上的 1 被涂成橙色? |
|---|---|---|
| Type A | \(P_A = \frac{1}{4}\) | ✖️ |
| Type B | \(P_B = \frac{1}{4}\) | ✔️ |
| Type C | \(P_C = \frac{1}{4}\) | ✔️ |
| Type D | \(P_D = \frac{1}{4}\) | ✖️ |
\(P_{Q_{13}} = \left(P_B+P_C\right)^{5} = \left(\frac{1}{4} + \frac{1}{4}\right)^{5} = \frac{1}{32} = \frac{8}{256}\)
Q13 知识点
dice: dice - volabulary.com
The noun dice is the plural form of the singular die. Although many people use the word dice when they're talking about a single die, it's actually only correct to call two or more of the dotted cubes dice. You can also use the word as a verb to mean "chop into tiny pieces or cubes." You might, for example, read a recipe instruction that says: "Dice three tomatoes."
英语中,dice 是复数形式,指两个或以上的骰子;它的单数形式是 die. 所以题干中是 5 dice 而不是 5 dices.
但包括在英语母语人群中,也有很多误用成 a dice 的情况。
§ Q14 题目
If we pick \(5\) dice from the bag, what is the probability that we get "some number" that is purely orange?
🔘 \(\frac{1}{256}\)
🔘 \(\frac{8}{256}\)
🔘 \(\frac{31}{256}\)
🔘 \(\frac{46}{256}\)
🔘 none of the other choices
Q14 解析
| 骰子种类 | 抽到每种骰子的概率 | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|---|
| Type A | \(P_A = \frac{1}{4}\) | green | orange | green | orange | green | orange |
| Type B | \(P_B = \frac{1}{4}\) | orange | green | orange | green | orange | green |
| Type C | \(P_C = \frac{1}{4}\) | orange | orange | orange | green | green | green |
| Type D | \(P_D = \frac{1}{4}\) | green | green | green | orange | orange | orange |
为使某个数字全为橙色:
| 数字 | 组合(包括仅有组合中单种骰子的情况,如:全 B 时数字 1 也为全 orange) |
|---|---|
| 1 | BC |
| 2 | AC |
| 3 | BC |
| 4 | AD |
| 5 | BD |
| 6 | AD |
取他们的并集,得到可能的组合有:AC, AD, BC, BD
其中,AC 组合与 AD 组合的交集是全 A,故全 A 重复计算了一次。其他项同理,要从组合概率和中减去重复的部分:
Q15-Q17
见文件 my_hw1_Q15~Q17.html
Q18-Q19
见文件 my_hw1_Q18~Q20.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号