py3+requests+bs4+xlwt,爬取自己博客园博客标题和链接,并写入excel
获取链接并写入excel
除了首页(首页有置顶博客),其余页每页10篇博客
所以,先从非首页入手。
爬取思路还是和之前的一遍博客写的一样,http://www.cnblogs.com/uncleyong/p/6892688.html
python3 -m pip install beautifulsoup4
python3 -m pip install xlwt
python3 -m pip install lxml
这里给出详细代码及注释:
import requests, xlwt
from bs4 import BeautifulSoup
url_list = [] # 用于存放标题和url
# 获取源码
def get_content(url):
html = requests.get(url).content
return html
# 获取某页中的所有博客url
def get_url(html):
soup = BeautifulSoup(html, 'lxml') # lxml是解析方式,第三方库
blog_url_list = soup.find_all('div', class_='postTitle')
for i in blog_url_list:
url_list.append([i.find('a').text, i.find('a')['href']])
for page in range(1,10):
url = 'http://www.cnblogs.com/uncleyong/default.html?page={}'.format(page)
# print(url)
get_url(get_content(url))
newTable = 'blog_list2.xls'
wb = xlwt.Workbook(encoding='utf-8') # 打开一个对象
ws = wb.add_sheet('blog') # 添加一个sheet
headData = ['博客标题', '链接']
# 写标题
for colnum in range(0, 2):
ws.write(0, colnum, headData[colnum], xlwt.easyxf('font:bold on')) # 第0行的第colnum列写入数据headDtata[colnum],就是表头,加粗
index = 1
lens = len(url_list)
# 写内容
for j in range(0, lens):
ws.write(index, 0, url_list[j][0])
ws.write(index, 1, url_list[j][1])
index += 1 # 下一行
wb.save(newTable) # 保存
结果:
总共50条数据
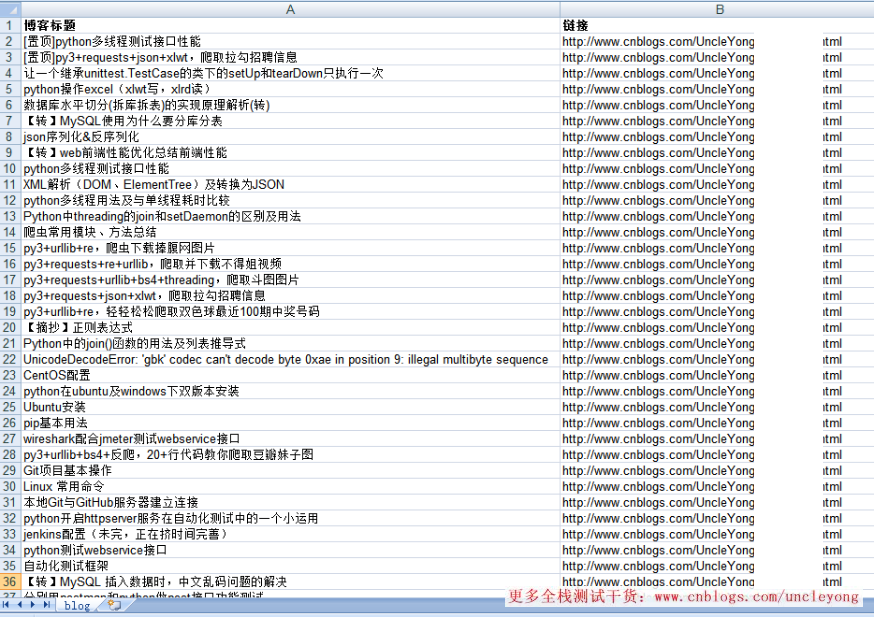

因为有置顶的文章,所以,上面的url是有重复的,比如:
[置顶]python多线程测试接口性能,http://www.cnblogs.com/uncleyong/p/7004415.html
python多线程测试接口性能,http://www.cnblogs.com/uncleyong/p/7004415.html
所以,可以先存入字典,每次判断url是否在keys()中,不在的话,增加字典的key和value
import requests, xlwt
from bs4 import BeautifulSoup
url_dic = {} # 用于存放标题和url
li = [] # 用于存放有序的标题和url
# 获取源码
def get_content(url):
html = requests.get(url).content
return html
# 获取某页中的所有博客url
def get_url(html):
soup = BeautifulSoup(html, 'lxml') # lxml是解析方式,第三方库
blog_url_list = soup.find_all('div', class_='postTitle')
for i in blog_url_list:
if i.find('a')['href'] not in url_dic.values():
url_dic[i.find('a').text]=i.find('a')['href']
for page in range(1,10):
url = 'http://www.cnblogs.com/uncleyong/default.html?page={}'.format(page)
# print(url)
get_url(get_content(url))
for i,j in url_dic.items():
# print(i, j)
li.append((i,j))
newTable = 'blog_list4.xls'
wb = xlwt.Workbook(encoding='utf-8') # 打开一个对象
ws = wb.add_sheet('blog') # 添加一个sheet
headData = ['博客标题', '链接']
for colnum in range(0, 2):
ws.write(0, colnum, headData[colnum], xlwt.easyxf('font:bold on')) # 第0行的第colnum列写入数据headDtata[colnum],就是表头,加粗
index = 1
lens = len(li)
for j in range(0, lens):
ws.write(index, 0, li[j][0])
ws.write(index, 1, li[j][1])
index += 1 # 下一行
wb.save(newTable) # 保存
这样,就少了两条被置顶的数据,获取到的是加了置顶二字的数据。
但是,如果是要获取到没有置顶二字的数据,那就通过切片,每次获取到标题都做切片操作
# 有置顶二字的标题
print('[置顶]python多线程测试接口性能'.split('[置顶]')[1])
# 无置顶二字的标题
print('python多线程测试接口性能'.split('[置顶]')[0])

但是问题又来了,因为标题中可能也包含‘[置顶]’,
可以这样:
li = ['[置顶]python多线程测试[置顶]接口性能','python多线程测试[置顶]接口性能','python多线程测试接口性能']
for i in li:
print(i.center(50,'*'))
if i.count('[置顶]') > 0:
if i.split('[置顶]')[0]=='':
# print(i.split('[置顶]')[1])
print(''.join(i.split('[置顶]')))
else:
print(i)
else:
print(i)

请求博客
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import urllib.request, time, random
# 得到指定一个url的网页内容函数
def sendRequest(url):
# 模拟浏览器头部信息,向服务器发送消息(伪装)
# 用户代理,表示告诉服务器,我们是什么类型的机器/浏览器(本质上告诉浏览器,我们可以接受什么水平的文件内容)
head = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36"
}
request = urllib.request.Request(url, headers=head)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
print(html)
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html
if __name__ == '__main__':
i,j = 0,0
while True:
j = j + 1
with open("url.txt","r",encoding="utf8") as f:
for url in f:
url = url.strip("\n")
if len(url)==0:
continue
sendRequest(url)
i = i + 1
randomtime = random.randint(61, 120)
print("当前是第【"+str(j)+"轮】,第【"+str(i)+"】次访问了:"+url+" ,下次请求等待时间【" + str(randomtime) + "秒】")
time.sleep(randomtime)
# if j==2:
# break
# nohup python3 qzcsbj.py > log.out 2>&1 &
# nohup python3 -m qzcsbj > log.out 2>&1 &
__EOF__

本文作者:持之以恒(韧)
关于博主:擅长性能、全链路、自动化、企业级自动化持续集成(DevTestOps)、测开等
面试必备:项目实战(性能、自动化)、简历笔试,https://www.cnblogs.com/uncleyong/p/15777706.html
测试提升:从测试小白到高级测试修炼之路,https://www.cnblogs.com/uncleyong/p/10530261.html
欢迎分享:如果您觉得文章对您有帮助,欢迎转载、分享,也可以点击文章右下角【推荐】一下!
关于博主:擅长性能、全链路、自动化、企业级自动化持续集成(DevTestOps)、测开等
面试必备:项目实战(性能、自动化)、简历笔试,https://www.cnblogs.com/uncleyong/p/15777706.html
测试提升:从测试小白到高级测试修炼之路,https://www.cnblogs.com/uncleyong/p/10530261.html
欢迎分享:如果您觉得文章对您有帮助,欢迎转载、分享,也可以点击文章右下角【推荐】一下!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号