
kylin-cube存储结构
前言
本篇文章通过图文的方式分析不同维度组合下的cube在hbase中的存储结构
需要声明的是,kylin不存原始数据,存储cube
全维度构建
假设一张表有3个字段name,age,sex,那么当通过kylin构建这张表的cube时,hbase的表结构如下所示。注意本示例没有度量字段,value表示记录条数累计,代表count(*),度量如果存在那么也是存储在value的位置,可以手动配置cf。
通过图1很明显的可以看到,kylin将每个维度的所有基数都枚举了出来,并通过组合的方式构建出hbase的rowkey,另外将组合对应的记录数做预统计保存在value中,对应hbase表中的一个cf:c。
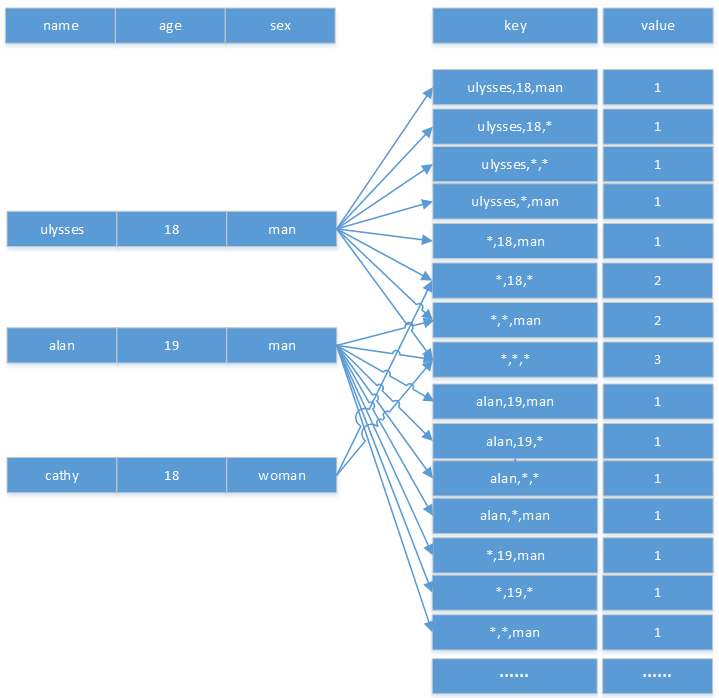
图1
当维度基数很大的时候,那么构建cube会称为灾难,所以kylin提供了cube的组合模式来减少cube的总维度组合。这里相关概念可以参考《kylin介绍》,下面直接对不同的模式进行案例分析。
aggregate group
意思是多少几个维度可以任一组合
假设图1中的cube配置aggregate group为2,那么构建出的cube相比全维度组合构建剪去了3个维度组合的部分,参数图2
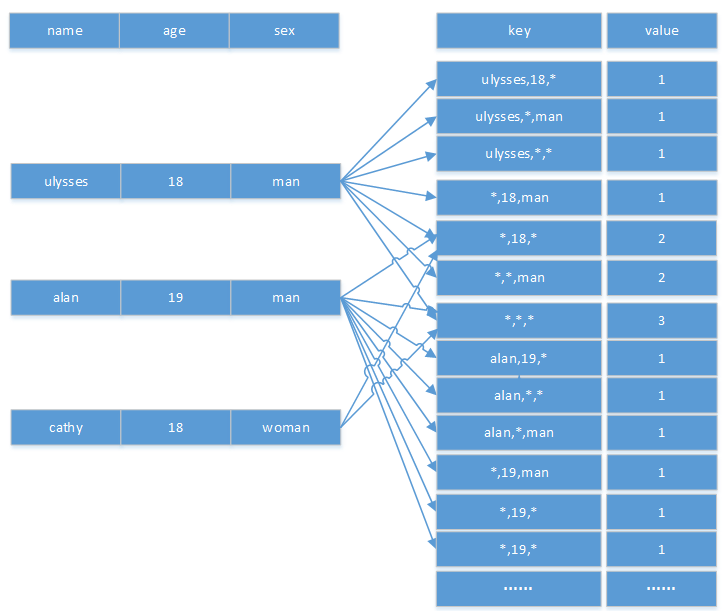
图2
mandatory
假设图1中的维度name是必要维度,那么构建出的hbase结构参考图3
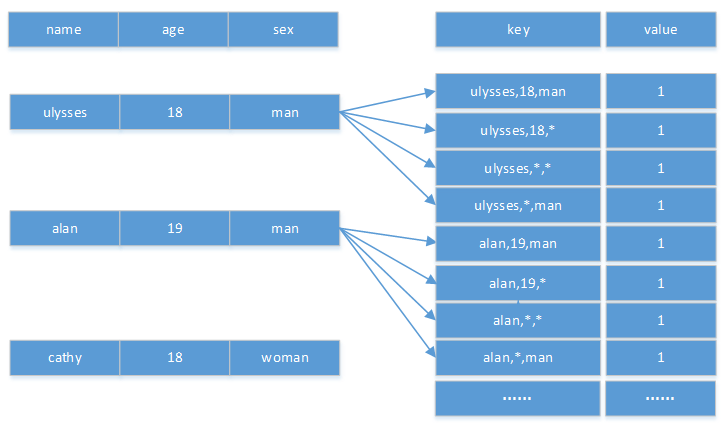
图3
joint
假设图1中name和sex维度是joint关系,那么构建出的hbase结构如图4

图4
Hierarchy
继承关系比较好理解,这里就不展示了: )
新博客地址
http://ixiaosi.art/
欢迎来访 : )

 浙公网安备 33010602011771号
浙公网安备 33010602011771号