
spark监控入门
前言
Spark作为计算引擎每天承载了大量的计算任务,为了监控集群的资源使用情况,对spark的监控也在所难免,Spark的监控有3个入口,1. Rest; 2.另一个是Metrics; 3. Log。
Rest
参考spark的rest接口文档
http://spark.apache.org/docs/latest/monitoring.html
spark支持把每个计算实例的执行信息写到hdfs,然后通过historyserver或者自己去hdfs上找到文件解析出来。数据包括spark执行关键点,job,stage,task,数据种类上大致和MapReduce收集的内容差不多,主要是jvm,资源,shuffle,io这四个方面。
Metrics
默认情况spark不打开metrics,也就是没有metrics数据,可以看配置conf/metrics.properties,默认都是被注释掉的。Spark内置了多种metrics的sink方式,控制台,csv,slf4j等。
案例
打开基于控制台的metrics sink。如图1,将3个配置的注释去掉,将metrics信息每过10s打印到控制台上。如图2,spark会将内存信息,job调度信息以及其他一些信息打印出来。
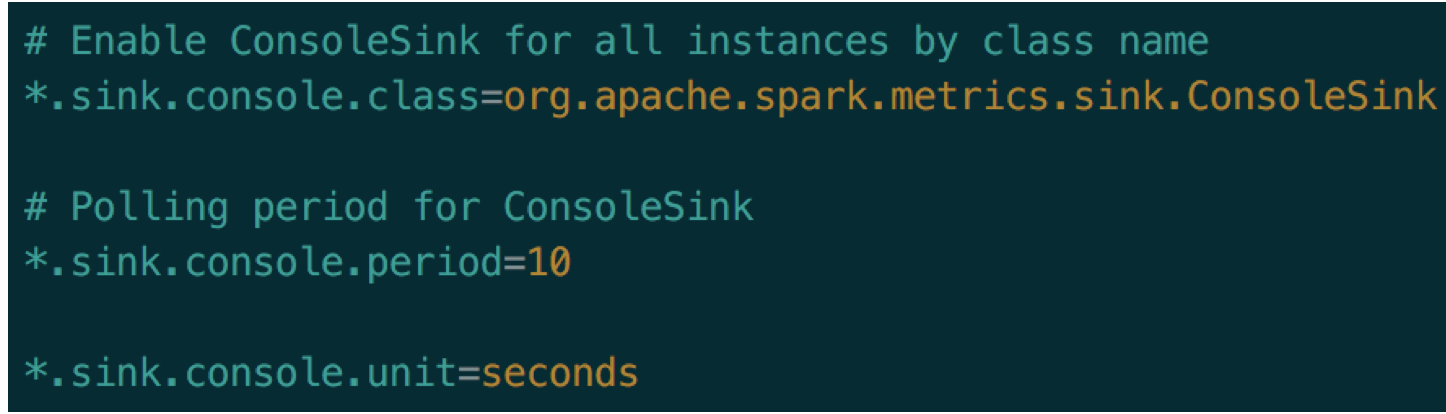
图1
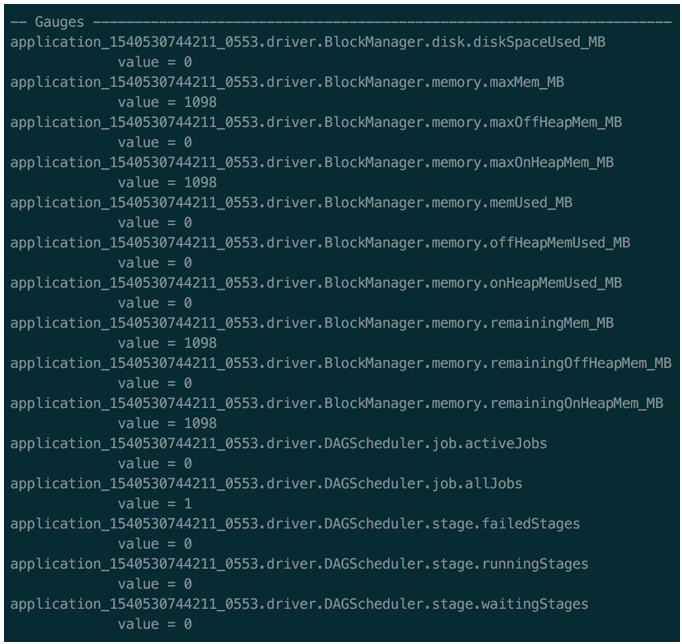
图2
Log
Spark在on yarn模式下,日志由yarn统一管理,一般情况,我们会选择把yarn的日志聚合功能打开,spark的日志也会跟着上传到hdfs上,这样自己去解析日志也会很容易。如果想要通过日志来监控spark任务执行情况,那么可能会需要业务层面的埋点,否则只能针对一些异常日常进行监测。
总结
Spark由于本身只是计算执行引擎,没有常驻进程(history server不算),所以在监控层面相对比较灵活,但是也有复杂的地方。当每天有成千上万个spark任务提交到集群执行的时候,那么需要监控的数据量就上来了,粒度越细,监控的压力越大。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号