

flink架构介绍
前言
flink作为基于流的大数据计算引擎,可以说在大数据领域的红人,下面对flink-1.7的架构进行逻辑上的分析并和spark做了一些关键点的对比。
架构
如图1,flink架构分为3个部分,client,JobManager(简称jm)和TaskManager(简称tm)。client负责提交用户的应用拓扑到jm,注意这和spark的driver用法不同,flink的client只是单纯的将用户提交的拓扑进行优化,然后提交到jm,不涉及任何的执行操作。jm负责task的调度,协调checkpoints,协调故障恢复等。tm负责管理和执行task。通过flink的架构我们可以了解到,flink把任务调度管理和真正执行的任务分离,这里的分离说的是物理分离。而对比spark的调度和执行任务是在一个jvm里的,也就是driver。分离的好处很明显,不同任务可以复用同一个任务管理(jm,tm),避免多次提交,缺点可能就是多了一个步骤,需要额外提交维护tm。
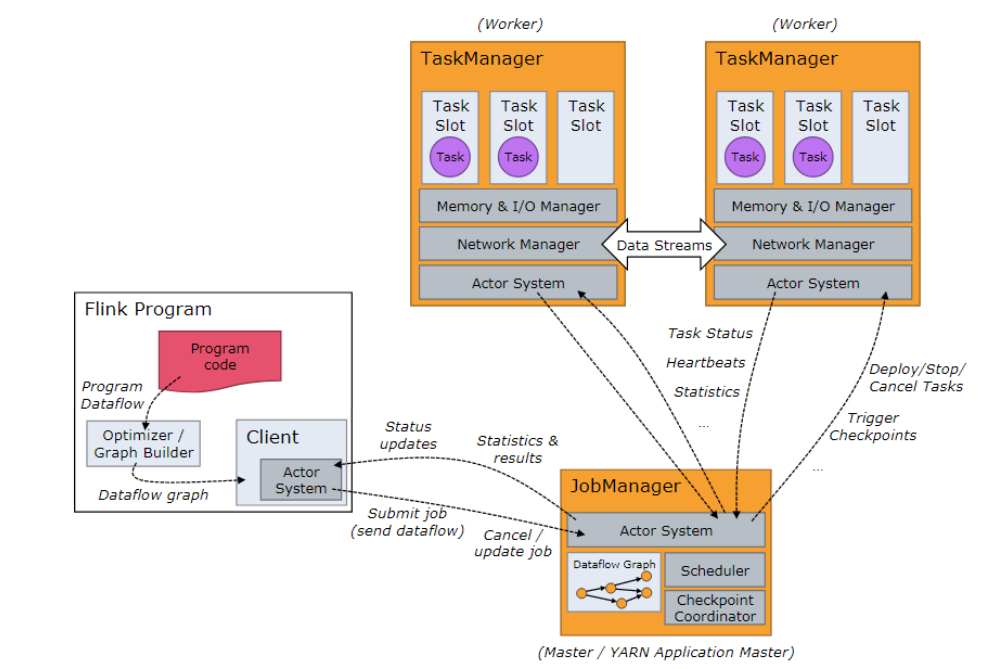
图1 架构
flink架构中另一个重要的概念是slot,在tm中有一个slot的概念,这个概念类似storm里的slot,用来控制并发度的,但不同于storm,flink的slot控制的是线程。首先1个tm对应1个jvm,然后并发度task对应一个线程,而slot就代表1个tm中可以执行的最大的task数。此外,task被tm管理,但是目前只会对内存进行管理,cpu是不做限制的。建议slot的数量和该节点的cpu数量保持一致。
部署策略
flink支持多种部署策略,独立部署模式或者基于其他资源容器yarn,mesos。
standalone
不依赖第三方资源容器进行部署,部署相对麻烦,需要将jm,tm分别部署到多个节点中,然后启动,一般不建议单独部署。
yarn
基于yarn的部署是比较常见的,flink提供了两种基于yarn的提交模式,attached和detached。无论是jb和tm的提交还是任务的提交都支持这两种模式。和spark基于yarn的两种模式不同,flink的这两种模式仅仅只是在client端阻塞和非阻塞的区别,attached模式会hold yarn的session直到任务执行结束,detached模式在提交完任务后就退出client,这个区别是很简单的。结合flink的架构来看,client不参与任何任务的执行,这点和spark是有很大区别的,不要搞混。
调度
flink同样采用了基于图的调度策略,client生成图然后提交给jm,jm解析后执行。但是flink的对task的执行思路和spark不同,spark是基于一个操作的并发,而flink是基于操作链的并发,这里先解释一下操作链,比如source(),map(),filter()这些都是操作,操作链就是多个连续的操作合并到一起,如图2,source(),map()形成一个操作链,keyBy(),window(),apply()[1]形成一个操作链。flink这样设计的目的在于,操作链中的所有操作可以使用一个线程来执行,这样可以避免多个操作在不同线程执行带来的上下文切换损失,并且可以直接在一个jvm中共享数据,这个思路可以说是一种新的优化思路。图3可以从一个任务的角度看到flink的并发思路。
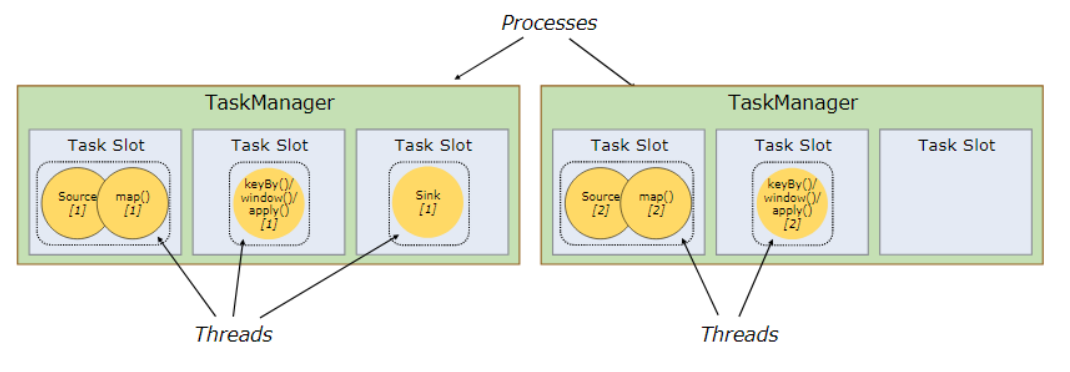
图2
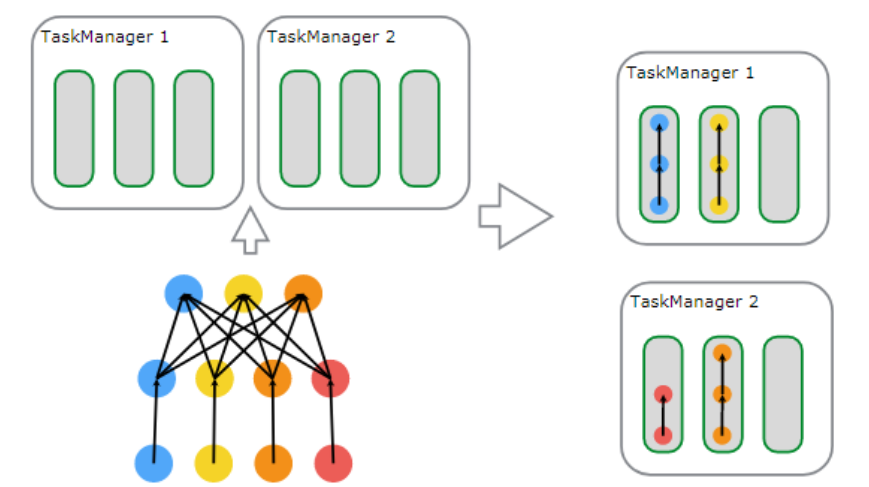
图3
总结
从架构上来看,flink也采用了常见的主从模型,不过不用担心flink已经支持了对jm的ha,很多地方可以看到其他大数据计算引擎的影子,在选择计算引擎的时候可以尝试一下。
参考
// flink官网对分布式执行环境的介绍
https://ci.apache.org/projects/flink/flink-docs-release-1.7/concepts/runtime.html
// flink官网对调度的介绍
https://ci.apache.org/projects/flink/flink-docs-release-1.7/internals/job_scheduling.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号