跑批 - Spring Batch 批处理使用记录
根据spring官网文档提供的spring batch的demo进行小的测验
启动类与原springboot启动类无异
package com.example.batchprocessing; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; /** * Although batch processing can be embedded in web apps and WAR files, * the simpler approach demonstrated below creates a standalone application. * You package everything in a single, executable JAR file, * driven by a good old Java main() method. * * springboot */ @SpringBootApplication public class BatchProcessingApplication { public static void main(String[] args) { SpringApplication.run(BatchProcessingApplication.class, args); } }
批量处理的不管是数据,文本,数据库备份等,需要对应的有实体类进行映射,比如要备份数据库得有Tables实体类(里面含有表名等一些数据字段)
这里是批量处理一个用户角色名,使其全部改为大写(成为一个大写的人)
package com.example.batchprocessing; import lombok.AllArgsConstructor; import lombok.Data; import lombok.NoArgsConstructor; /** * 现在您可以看到数据输入和输出的格式,您可以编写代码来表示一行数据, * 如下面的示例(来自src/main/java/com/ example/batchprocessing/person.java)所示 * Now that you can see the format of data inputs and outputs, * you can write code to represent a row of data, * as the following example shows: * * You can instantiate the Person class either with first and * last name through a constructor or by setting the properties. */ @Data @NoArgsConstructor @AllArgsConstructor public class Person { private String lastName; private String firstName; }
哪个去执行这个操作(变为大写的人),得有专门的处理类
package com.example.batchprocessing; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.batch.item.ItemProcessor; /** * PersonItemProcessor implements Spring Batch's ItemProcessor(项目处理器)interface. * This makes it easy to wire the code into a batch job that you will define later in this guide. * According to the interface, you receive(接收) an incoming Person object, * after which you transform it to an upper-cased Person.(然后将其转换成大写的人 ^_^) */ //人类中间处理机 public class PersonItemProcessor implements ItemProcessor<Person,Person> { private static final Logger log = LoggerFactory.getLogger(PersonItemProcessor.class); @Override public Person process(final Person person) throws Exception { final String firstName = person.getFirstName().toUpperCase(); final String lastName = person.getLastName().toUpperCase(); final Person transformedPerson = new Person(firstName,lastName); log.info("Converting("+person+")info("+transformedPerson+")"); return transformedPerson; } }
这里实现的是spring batch里的ItemProcessor<~,~> 其中的<Person,Person>表示要读,写的数据类型
在文档里说明了读与写的类型可以是不同的.这里是相同的Person类型.
其中重写的process方法,获取了传入的Person类,将其firstName,lastName进行大写更改.生成新的Person,进行数据回传. return transformedPerson.
有了映射数据实体类,有了更改数据的中间处理器,还需要批量处理,需要进行配置
package com.example.batchprocessing; import org.springframework.batch.core.Job; import org.springframework.batch.core.Step; import org.springframework.batch.core.configuration.annotation.EnableBatchProcessing; import org.springframework.batch.core.configuration.annotation.JobBuilderFactory; import org.springframework.batch.core.configuration.annotation.StepBuilderFactory; import org.springframework.batch.core.launch.support.RunIdIncrementer; import org.springframework.batch.item.database.BeanPropertyItemSqlParameterSourceProvider; import org.springframework.batch.item.database.JdbcBatchItemWriter; import org.springframework.batch.item.database.builder.JdbcBatchItemWriterBuilder; import org.springframework.batch.item.file.FlatFileItemReader; import org.springframework.batch.item.file.builder.FlatFileItemReaderBuilder; import org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.core.io.ClassPathResource; import javax.sql.DataSource; /** * For starters(初学者),the @EnableBatchProcessing annotation adds many critical * beans that support jobs and save you a lot of leg work. * This example uses a memory-based database (provided by @EnableBatchProcessing) * meaning that, when it is done, the data is gone. * It also autowires a couple factories needed further below. * Now add the following beans to your BatchConfiguration class to define a * reader, a processor, and a writer. */ @Configuration @EnableBatchProcessing public class BatchConfiguration { @Autowired public JobBuilderFactory jobBuilderFactory; @Autowired public StepBuilderFactory stepBuilderFactory; //读该读的 /** * reader() creates and ItemReader. It looks for a file called sample-data.csv * and parses each line item with enough information to turn it into a Person. * @return */ @Bean public FlatFileItemReader<Person> reader(){ //单调文件 return new FlatFileItemReaderBuilder<Person>() .name("personItemReader") .resource(new ClassPathResource("sample-data.csv")) .delimited() //界限 .names(new String[]{"firstName","lastName"}) .fieldSetMapper(new BeanWrapperFieldSetMapper<Person>(){{ setTargetType(Person.class); }}) .build(); } /** * processor() creates an instance of the PersonItemProcessor that you defined earlier, * meant to converth the data to upper case. * @return */ @Bean public PersonItemProcessor processor(){ //人类中间处理器 使之成为大写的人 return new PersonItemProcessor(); } /** * write(DataSource) creates an ItemWriter.This one is aimed at a JDBC * destination and automatically gets a copy of the dataSource created by * @EnableBatchProcessing. It includes the SQL statement needed to isnert a * single Person,driven by Java bean properties. * @param dataSource * @return */ //写该写的 @Bean //JDBC批量项目写入器 public JdbcBatchItemWriter<Person> writer(DataSource dataSource){ return new JdbcBatchItemWriterBuilder<Person>() .itemSqlParameterSourceProvider(new BeanPropertyItemSqlParameterSourceProvider<>()) .sql("INSERT INTO people (first_name,last_name) VALUES (:firstName,:lastName)") .dataSource(dataSource) .build(); } // tag::jobStep[] /** * The first method defines the job,and the second one defines a single step. * Jobs are built from steps,(工作是一个步骤一个步骤建立起来的),where each step can involve * a reader, a processor, and a writer. * 每个step步骤都涉及到读取器,处理器,写入器 * * / /** * The last chunk shows the actual job configuratoin * */ /** * * The first method defines the job,and the second one defines a single step. * Jobs are built from steps, where each step can involve a reader, * a processor, and a writer. * * In this job definition, you need an incrementer, because jobs use a database * to maintain execution state, You then list each step,(though this job has only one step) * The job ends,and the Java API produces(产生生成) a perfectly configured job. * * @param listener 监听器 * @param step1 步骤1 * @return */ //设定工作 包含步骤 @Bean public Job importUserJob(JobCompletionNotificationListener listener, Step step1){ return jobBuilderFactory.get("importUserJob") .incrementer(new RunIdIncrementer()) .listener(listener) .flow(step1) .end() .build(); } /** * In the step definition, you define how much data to write at a time. * In this case,it writes up to ten records at a time, Next, * you configure the reader,processor, and writer by using the bits * injected earlier. * @param writer * @return */ //设定步骤 @Bean public Step step1(JdbcBatchItemWriter<Person> writer){ return stepBuilderFactory.get("step1") .<Person,Person> chunk(10) .reader(reader()) .processor(processor()) .writer(writer) .build(); } }
其中配置中包含读取器,设定了要读哪些,即读该读的.
包含了写入器,即写到哪里,按理说这里如果要做持久存储,需要在这里配置一些PersonService进行数据的存储的操作.
包含了中间处理器,在上面已经说过了.
包含了Job配置,其中参数为一个工作完成监听器,一个步骤step1,下面讲到step.
每个Job(工作)是需要一项一项的step组成的,例如这次只是更改为大写的人名,而需要更改为大写的人之后,还需要将另一个对应着该Person的电话写在用户名后面
那么可能需要要加入一个readPhoneNo()方法,从另一个文件中获取其对应的电话.再需要一个数据库连接查询回来的已经更改为大写的人名,
在中间处理器PersonItemProcessor中加入这些查询数据库获取新大写人名,并再加入到配置类中一个writePersonAndPhone方法,使用另一种write方式写到想写到地方.

而这个改为大写的人,和将电话写在大写的人名后面可以分为两步操作,即两个step.
但是可以作为一个Job来执行.
有了这些当然还要有批处理的事件提醒,是完成了Job还是没有,完成到哪一步,以及通过这个事件提醒来记录一些批处理日志.
package com.example.batchprocessing; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.batch.core.BatchStatus; import org.springframework.batch.core.JobExecution; import org.springframework.batch.core.listener.JobExecutionListenerSupport; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.jdbc.core.JdbcTemplate; import org.springframework.stereotype.Component; /** * What's this Class use to? * The last bit of batch configuration is a way to get notified * when the job completes. * * This Class listens for when a job is BatchStatus.COMPLETED * and then uses JdbcTemplate to inspect the results. */ @Component public class JobCompletionNotificationListener extends JobExecutionListenerSupport { private static final Logger log = LoggerFactory.getLogger(JobCompletionNotificationListener.class); private final JdbcTemplate jdbcTemplate; @Autowired public JobCompletionNotificationListener(JdbcTemplate jdbcTemplate){ this.jdbcTemplate = jdbcTemplate; } @Override public void afterJob(JobExecution jobExecution){ if(jobExecution.getStatus()==BatchStatus.COMPLETED){ log.info("!!!Job Finished! Time to verify the results"); jdbcTemplate.query("SELECT first_name,last_name FROM people", (rs,row)-> new Person( rs.getString(1), rs.getString(2) )).forEach(person -> log.info("Found <"+person+"> in the database.")); } } }
上面的事件提醒为查看是否完成了批处理,这里通过查询数据库,查看批处理更改后的数据.
也可以进行相应的校验及测试,查看是否批处理无误.
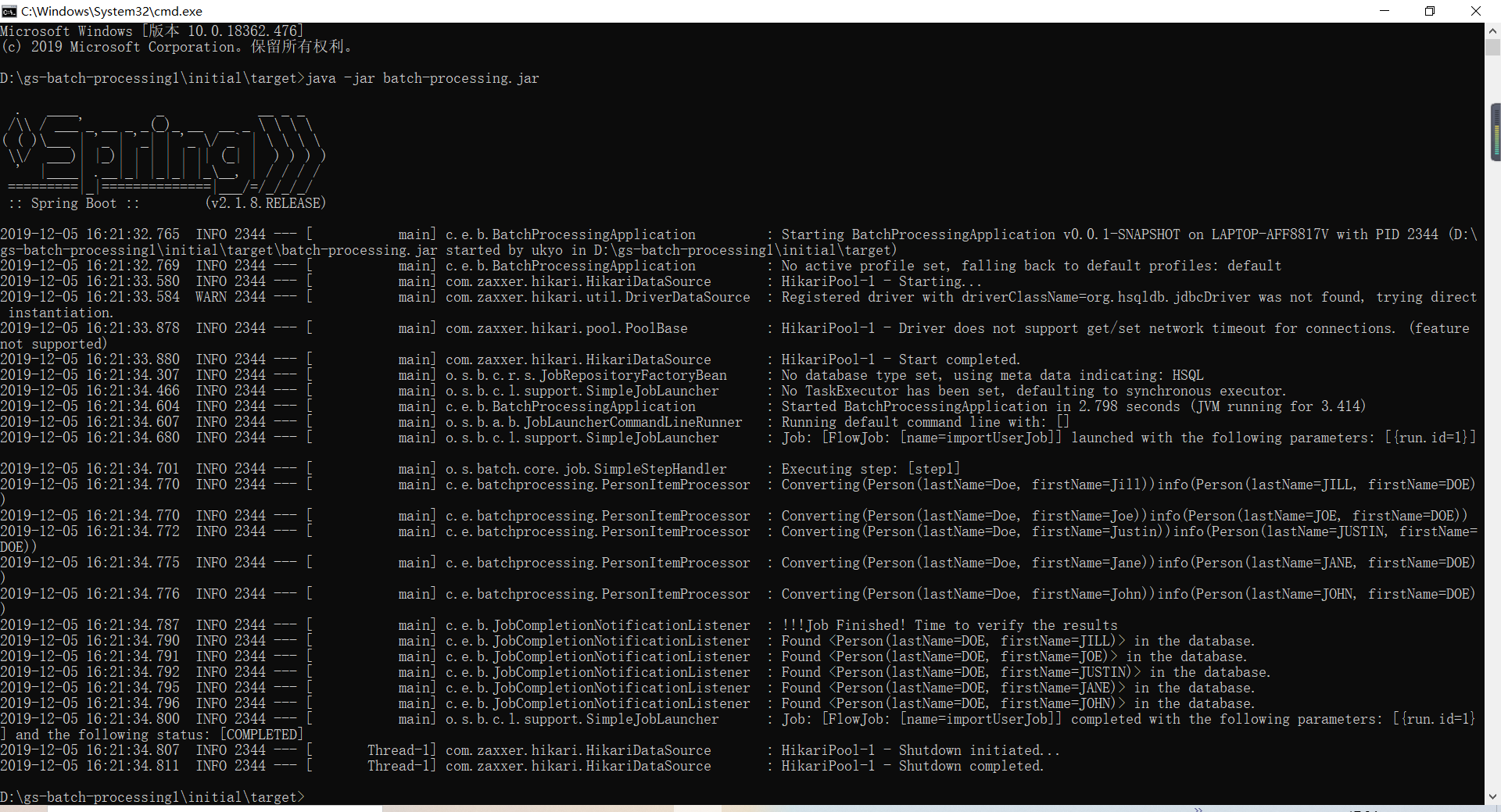
批量处理结果,其只是执行一个springboot的命令操作.
在后续步骤中,可以更改为某个方法实现.将批量处理可视化界面化.
本文来自博客园,作者:ukyo--碳水化合物,转载请注明原文链接:https://www.cnblogs.com/ukzq/p/11990613.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号