(神州优车)大数据平台建设经验分享
作者:卢彪(神州优车技术专家)
QQ:634659517
介绍大数据平台建设经验的文章已经不在少数,再次发表该类文章是因为我们觉得:条条大路通罗马,形形色色景不同。本文主要介绍了神州优车大数据平台(只介绍离线平台并且侧重于基础架构部分)的一些建设经验,希望能给同仁们带来一些帮助。文章将从4个方面展开介绍,分别是建设目标、总体架构、深入讲解和总结规划,介绍过程中将直抒其意,不会对行业术语和专有名词进行解释,如有疑问可自行百科。
建设目标
2018年之前我司的数据平台依次经历了基于SqlServer的传统数仓阶段、基于Hadoop的探索应用阶段和基于Hadoop的全面应用阶段,不同阶段解决了不同的问题,完成了不同的历史使命。站在新的起点,为了满足企业数字化转型的和精细化运营的需要,平台建设进入了一个新的阶段,一句话概括建设目标:打造全新平台,提升数据赋能水平,支持业务快速发展。主要建设目标如下:
- 进一步提升数据开发效率
快速响应业务需求,高效开发数据任务,需要平台提供更加高效的服务能力,主要措施有:
- 提供一站式Portal
打通各个子系统,对功能进行整合和集成,保证用户只需登录一个平台,便可完成任务开发(现状是数据交换平台、元数据平台和任务调度平台等都是独立的子系统,用户需要跨平台进行操作) - 实现OneClick
用户发起新的开发任务,一般需要新建HIVE表、跑全量数据、合并全量数据到HIVE表,配置增量同步、配置定时ETL任务、配置数据质量校验等一系列操作,由于各子系统还未完全打通,这些操作都是半自动化的,系统打通之后,实现一键式快速开发 - 支持用户DIY
诸如数据权限的管控、自定义函数的管控、自定义插件的管理、文件的上传和下载等功能,依托新的平台服务策略,支持团队和个人自我管理,降低平台服务方的运维压力
- 进一步提升资源利用率
对于大数据平台来说,最核心的资源就是存储、内存和计算,如何利用好这些资源,是一件比较有挑战的事情。系统从0到1的过程中,更多关注的还是功能的实现,资源问题考虑相对较少,经过快速发展期之后,系统在资源利用方面需要进行更深层次的调整和优化。
- 提升小文件治理能力
MR任务或SPARK任务的分区设置如果不合理,会导致任务输出巨量的小文件,如不加以合理控制,不仅影响查询性能,还会给NameNode(或Impala Catalog Server)造成巨大压力,影响集群稳定性。随着平台承担了越来越多的业务需求,需要对小文件进行更合理的控制和优化 - 提升过期文件治理能力
数仓中的很多表、用户自己目录空间下的文件、大量日志文件和临时文件、数据同步的原始文件等,可能已经过期没用了,但仍然占据了大量磁盘空间。所以,需要对冷文件和僵尸文件进行更深层次的管控 - 对数据任务的资源配置进行治理
一个数据任务应该分配多大的资源,需要更加精细化的控制,分小了影响性能,分大了浪费资源,CPU和内存的配比也很重要,为了实现更科学的资源分配,需要基于数据分析,提升资源分配的合理性
- 进一步提升系统稳定性
平台建设过程中,积累了不少经验,也趟了不少坑,深知系统稳定性的重要性。基于历史经验,站在新的起点,需要为平台打造一套新的稳定性体系,事前、事中和事后,实现管控的三位一体,保障数据质量和数据安全。下面列举一些我们经历的稳定性问题:
-
NameNode宕机
HDFS本身还是很稳定的,像我们的HBase集群,很少因为HDFS出问题而导致系统故障,但HDFS最怕的就是小文件,文件数过多将给NameNode带来巨大压力。有段时间我们的NameNode经常宕机,定位到是文件数量过载导致的之后,一方面调大了NameNode进程的内存,另一方面想办法控制文件数量,随后系统稳定运行了相当长的时间。但突然有一天NameNode又宕了,反复试了几次,把内存调到很大,才勉强启动起来,启动起来之后发现文件数量在一天之内暴增了近一倍,随后系统长时间处于blockmissing状态无法恢复。最后定位到的原因是一个非常大的数据任务执行失败了,但是产生了巨量的.hiveStaging文件没有释放,造成文件数暴增,压垮了NameNode;而重启后一直处于blockmissing状态无法解除是因为,文件数暴增导致DataNode负责的block块儿也增多了,DataNode在向NameNode汇报块儿信息的时候,传输的数据量太大,超过了参数ipc.maximum.data.length的限制,汇报不上去。针对这个问题,如果有"文件数量异动报警"功能,便可以及早发现问题,从而避免事故的发生。关于.hiveStaging和blockmissing的问题,可参见如下两个链接:
参考一:https://www.cnblogs.com/ucarinc/p/11831280.html
参考二:https://www.cnblogs.com/ucarinc/p/11831353.html -
调度任务延迟
任务一旦出现延迟,早晨报表就出不来,随之而来的是大量投诉,顿时感觉亚历山大。导致任务延迟的原因非常多,最直接的就是hadoop集群出问题,另外就是调度引擎和执行引擎自身的问题,再有就是调度任务的时间安排的不合理等。举几个印象深刻的任务延迟场景,如下:- HiveServer卡住导致所有MR任务延迟
https://cloud.tencent.com/developer/article/1149029 - HiveServer内存溢出导致所有MR任务延迟
- MetaStore内存溢出导致所有任务延迟
- Yarn资源预留机制触发了Yarn死锁,导致任务延迟,参考资料如下
https://blog.csdn.net/zhanyuanlin/article/details/78799341 - 超长的大任务占据大量资源,影响调度任务
- 队列设置的maxRunningApps参数过小
如上所列的这些问题,已经有保障体系(如:长任务超时报警,jvm内存报警、GC报警等)可以进行预警,但需要在广度和深度上做更多的整合和细化
- HiveServer卡住导致所有MR任务延迟
- 数据质量问题
出现过由于幂等控制不合理,导致调度任务重复提交,引发表数据重复的问题;出现过由于主子表外键类型不统一(一个String,一个BigInteger),导致关联查询数据重复,引发表数据重复问题;出现过由于并发控制不合理,导致同一任务并行执行,引发表数据丢失的问题;出现过由于hadoop写入机制不健全(参见:https://issues.apache.org/jira/browse/HDFS-11915 ),导致spark-sql无法完整读取block块儿数据,引发表数据丢失和截断的问题。
-
进一步提升数据安全性
数据是企业的核心资产,数据安全的重要性可想而知,大数据平台的安全控制是一个非常棘手的问题,没有标准化的方案,需要根据自己的具体场景,因地制宜,自我创新。新平台的建设,要打通各个子系统,过程中需要迭代出一套更加科学合理的功能权限控制体系和数据权限控制体系。
- 进一步降低运维成本
运维工作主要分两类:一类是面向集群的底层运维,主要包括环境的搭建和维护、集群的监控和预警、故障的分析和解决等;另一类是面向用户的上层运维,主要包括用户问题的答疑、数据需求的支持、数据质量的保证、数据问题的解决等。新平台,要不断开发更多的工具,提升自动化运维能力。
总体架构
全局视图
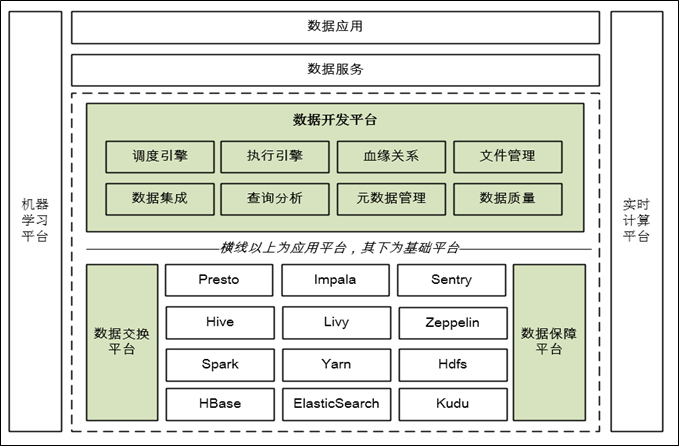
-
上图为神州优车大数据架构的全局视图,虚框以内的部分代表的是离线大数据平台的基础服务平台,本文所述的大数据平台特指该部分,请读者注意
-
如图所示,平台由两个域组成,侧重于技术支撑的基础平台域和侧重于数据开发的应用平台域,这两个域使用的产品既有开源也有自研,图中绿色的部分为自研产品。在我们的场景中,目前还未发展到开源产品既有功能无法满足需求的阶段,所以,并没有对使用的开源产品做过多的二次开发,一般都是遇到问题解决问题
局部视图
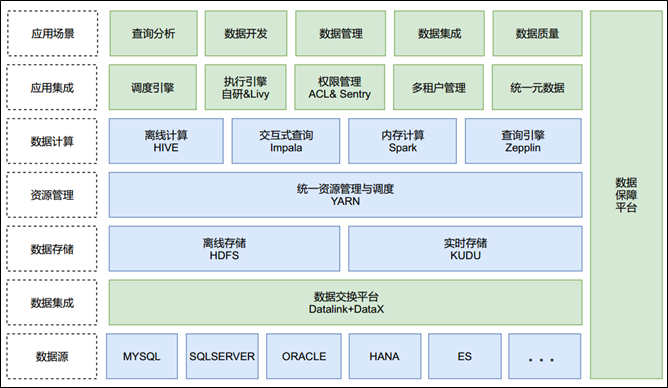
-
上图是从功能层次的角度对平台的另一种展现,绿色的部分将是本文重点讲解的内容
-
数据交换平台,担负了数据集成的重任,包含数据采集和数据回流
-
数据保障平台,跨越多个层次为大数据平台提供稳定性保证
-
数据开发平台,由两部分组成:一是应用集成层,用来把技术组件进行整合和封装,为上层应用场景提供架构支撑和模型支撑;二是应用场景层,用来提供各种类型的业务功能,让技术充分发挥价值,实现数据的高效管理和利用
深入讲解
数据交换平台
神州优车数据交换平台,能够支持多种异构数据源之间的【实时增量同步】和【离线全量同步】,是一个能支撑多种业务场景的综合性平台,本文只介绍和大数据相关的功能板块,更多详细介绍可参考:https://mp.weixin.qq.com/s/BVuDbS-2Ra5pIJ7oV78FBA。概括来讲,数据交换平台在整个大数据平台的【数据处理Pipeline】中担任了【数据采集】和【数据回流】的重任,如下所示:
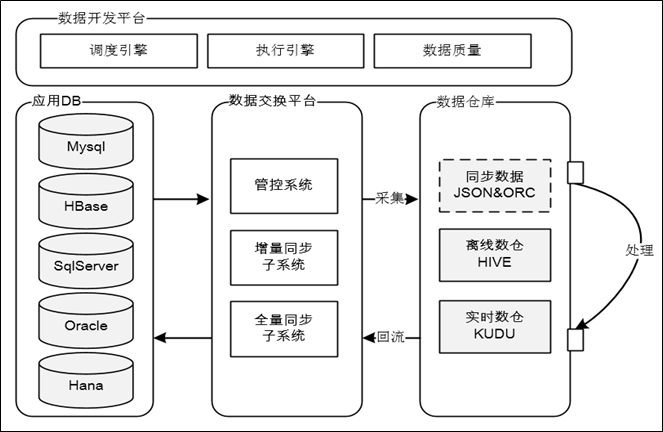
而专讲数据采集或回流略显单薄,所以接下来将围绕大数据平台的【数据处理Pipeline】展开介绍,Pipeline分为3个部分,分别是数据采集、数据处理和数据回流:
数据采集
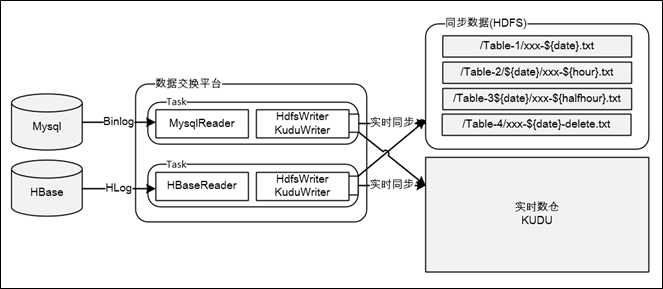
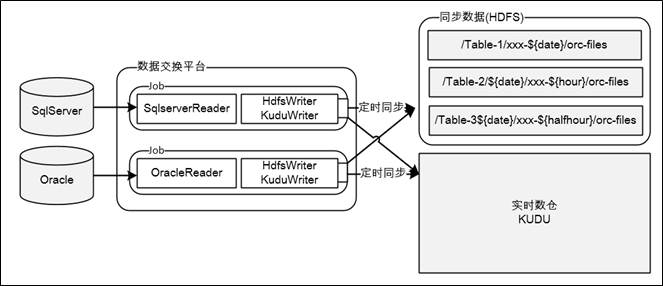
如上图所示,数据采集是把业务系统数据通过数据交换平台流转给大数据平台的过程,采集方式分为两大类:一类是依靠DB的Replication机制,通过抓取DB的日志获取数据,如:Mysql的Binlog,Hbase的Hlog;另一类是受限于DB的日志机制不够强大,只能直接从DB抽数,如:SqlServer、Oracle、Hana。下面对两种方式展开说明:
- 通过Log方式的采集操作是实时的,数据交换平台内运行了很多实时Task,Task由Reader和Writer组成,TaskReader负责读取或接收Log数据,TaskWriter负责封装Log数据然后写入HDFS或KUDU。同步到HDFS的数据,数据格式为Json,是按照库名、表名、时间等维度组织到一起的,数据虽然是实时写入的,但被合并到离线数仓的频率,取决于数据开发平台中对应【数据处理任务】的执行频次,一般都为一天处理一次,即数据的时效性是T-1;同步到KUDU的场景比较简单,直接调用API进行实时写入即可,在我们的场景中实时数仓是依托KUDU搭建的,实现"Fast Data,Fast Analysis"
- 通过从DB抽数的采集操作是定时的,到HDFS的采集频率一般是一天一次,到KUDU的采集频率一般以小时或半小时为单位,数据交换平台内管理了很多定时Job,这些Job也是由Reader和Writer组成,交换平台提供了Job的管理接口,数据开发平台的【调度引擎】会定时触发调用这些Job完成数据同步操作;同步到HDFS的数据格式是ORC,也是按照库名、表名、时间等维度组织到一起的;定时抽数Job,大部分都是全量抽取,对于数据量超大的表,也支持增量抽取(如每次判断modify_time)
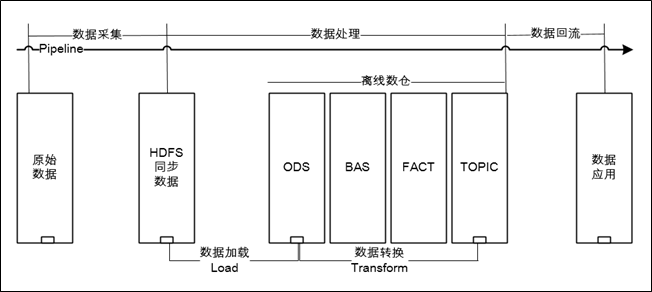
数据处理
此处说的数据处理主要指的是离线数仓的数据处理流程(实时数仓比较简单,没有load的过程),处理过程由两部分组成,分别是【数据加载】和【数据转换】,前者负责把同步数据Load到ODS库中,后者负责依照数仓模型对数据进行Transform。数据采集、数据加载和数据转换,是一个ELT的过程,如下图所示,关于ETL和ELT的对比介绍,可参考:https://mp.weixin.qq.com/s/osCRnfnuCFGJIR1jkhgUwA
数据回流
数据回流可以看做数据采集的逆向过程,但远没有数据采集的流程复杂,其核心功能就是表间的数据同步,目前支持两种形式的回流,分别是:【数据交换平台任务回流】和【SparkSql回流】,两种方式各有优缺点,将在后面的【数据开发平台】章节详解
数据保障平台
数据保障平台(内部代号SpaceX),是一个集成了监控、运维和资源治理的平台,用于对大数据平台的基础设施进行稳定性保障,目前在监控和资源治理方面已经有了一定的成果,在自动化运维或者智能运维方面还有很长的路要走。接下来分3部分对平台进行介绍,分别是平台整体架构、HDFS监控治理和YARN监控治理
平台整体架构
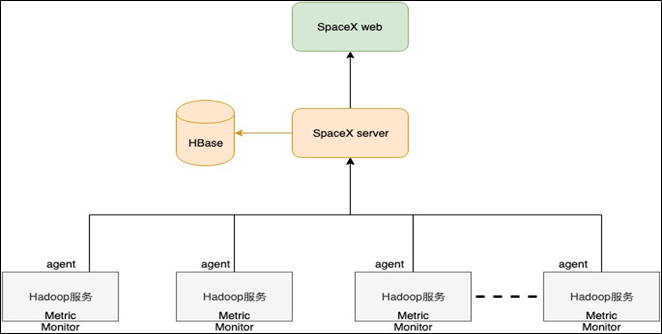
上面是SpaceX的部署架构图,其架构深入参考了Ambari的设计,主要由4部分组成:
-
SpaceX Web:提供各种维度的监控图表,并对系统风险和异常进行预警,其通过Rest Api与SpaceX Server 进行交互
-
SpaceX Server:和Agent保持长连接,接收Agent上报的监控数据,也会主动轮询各系统的Metrics Api收集监控数据,监控数据会被存储到Hbase,然后对监控数据进行聚合处理
-
Agent:被部署到集群节点的守护进程,接收SpaceX Server的指令进行相关操作,主动收集系统Metrics信息上报给SpaceX Server
-
Hbase:用Hbase存储监控数据,用到了phoenix引擎
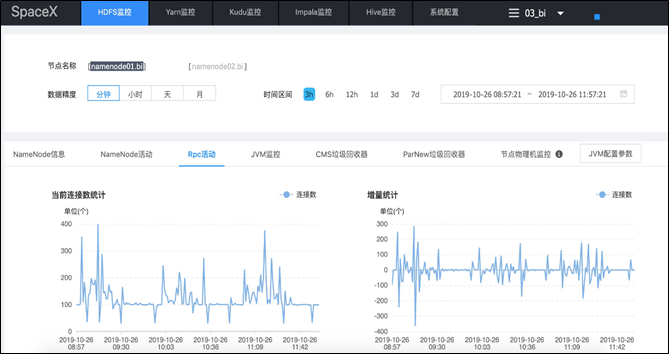
上图是系统Portal的一个概览图,目前支持对HDFS、Yarn、Kudu、Impala和Hive的监控和管理,系统支持多集群模式,即:可以对多套集群同时管理,并可快速增加对新集群的监控,如SpaceX同时管理了实时计算集群、离线计算集群、Hbase集群、OpenTsDB集群的HDFS文件系统
HDFS监控治理
对于HDFS的监控治理,分为3个层级:第一个层级是基本的可用性监控,第二个层级是集群各项Metrics的监控,第三个层级是对文件的深度分析和治理。
- 第一个层级
对NameNode、DataNode、JournalNode、DFSZKFailoverController等的进程状态进行监控,监控的主要指标有:基本的健康状态、Jvm内存监控、JvmGC监控、Jvm线程监控、Jvm日志监控等,当进程出现崩溃或监控指标超过阈值后,会第一时间进行预警处理。总的来说,这些组件在大部分情况下还是很稳定的,下面举两个容易出问题的场景:其一,NameNode一般会因为集群文件数增多导致内存溢出而挂掉;其二,JournalNode在磁盘读写慢或者网络带宽被占满的情况下,容易出现元数据同步超时而挂掉,并且当出现大部分JournalNode都挂掉时,NameNode也会随之挂掉 -
第二个层级
首先对硬件的各项指标进行监控,如磁盘、IO、CPU、内存等,这些业界都有通用的方案,不再赘述;其次是对HDFS文件系统的各项指标进行监控,可以全方位透视系统状态,一些主要的监控场景举例如下:- 文件数量趋势监控,展示集群文件数量的变化轨迹,以及每天的增量变化轨迹
- 文件数量异动监控,总量超过阈值发出报警,出现暴增或暴跌进行预警
- 磁盘容量趋势监控,展示集群磁盘使用量的变化轨迹,以及每天的增量变化轨迹
- 磁盘容量异动监控,使用率超过阈值发出报警,出现暴增或暴跌进行预警
- 文件分布均衡度监控,展示文件在datanode的分布情况,出现不均衡时发出报警
- NameNode活动监控,如:添加block的操作数、创建文件的操作数、创建链接操作数、创建快照操作数、删除文件操作数、RPC活动等等
- DataNode活动监控,如:块校验平均时间、块检验次数、块报告平均时间、读块总数、删除块总数、写块总数、块校验次数、心跳次数等等
-
第三个层级
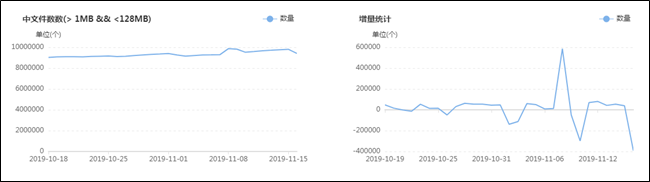
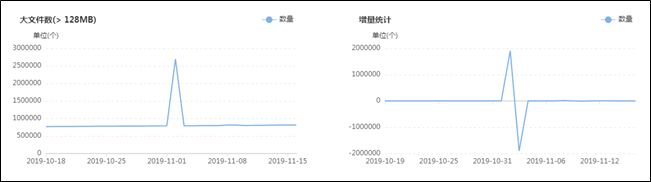
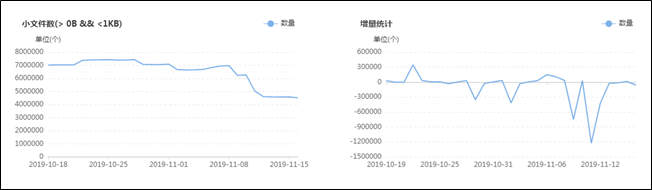
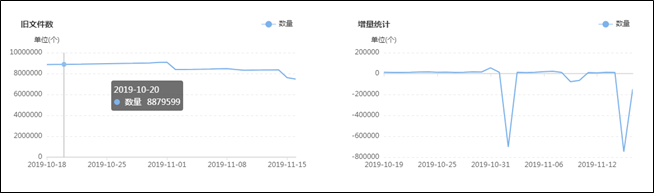
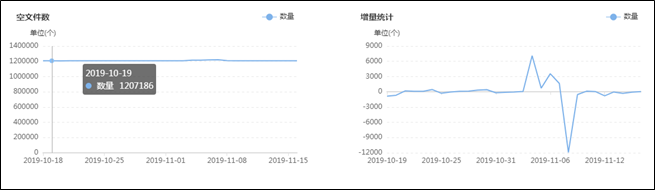
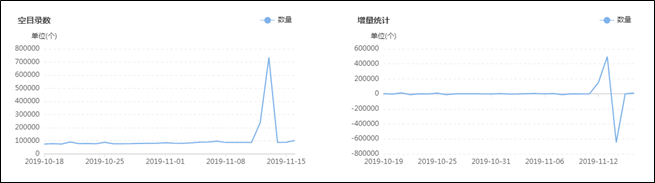
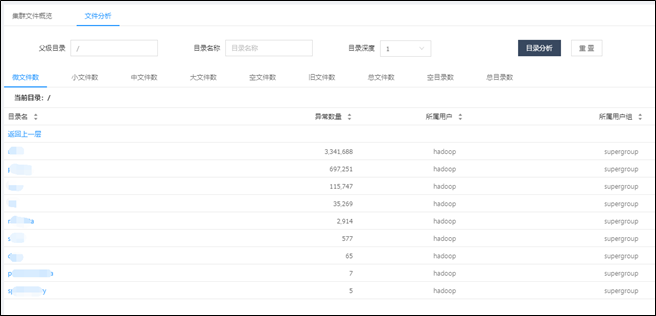
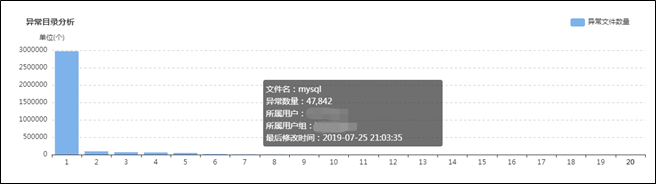
集群目前有多少大文件,有多少中文件,有多少小文件,有多少空文件,有多少冷(旧)文件,它们的比例如何,它们在文件目录中是怎么分布的,它们归属于哪个团队等等,这些问题靠第三层级的监控治理给出答案,先列出一组图,如下:![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
上面这组图是SpaceX中涉及文件分析功能的一些核心页面,总的来说分为两类:一类是对各种类别的文件进行分析,监控其数量变化的轨迹和趋势,以及不同文件的数量比例;另一类是提供交互式页面,允许用户精确分析指定的目录,当输入目录并点击分析之后,系统会列出不同类型文件的分析结果,如:每个子目录下存在的异常文件个数,按存在的异常文件个数列出Top10的异常子目录,展示Top500的异常文件列表等;除此之外,系统还会根据后台的分析数据,定期输出报表发给各开发团队,各开发团队根据报表的指导进行对应的优化,如:把历史分区中的小文件合并为大文件、把旧文件进行压缩归档、调整任务参数以降低输出的文件数量等等。
在建设背景章节提到过资源铺张浪费的问题,其中涉及文件相关问题的解决主要依托的就是该文件分析功能,而该功能得以实现的首要功臣是PayPal开源的NNAnalytics,一款基于HDFS-FSImage的文件分析引擎(https://github.com/paypal/NNAnalytics),我们在其基础上进行了二次封装和改造,结合自身场景进行了应用落地。目前,集群的总文件数已经从接近1亿优化到了5000W以内,后续的目标是降到3000W以下,随着优化的不断进行,集群性能随之不断提升,举例如下:
- NameNode堆内存使用率大大降低,稳定性不断提高
- Impala Catalog Server堆内存使用率大大降低,可用性不断提升
- Hadoop集群执行任务的吞吐量明显提升:小文件的大幅减少大大降低了IO压力,带来的是任务执行速度的提升,单位时间内可执行的任务数随之增大,吞吐率随之提升
- Impala对Hive表执行compute stats的执行时间从几十分钟减小到几分钟,大表Sql查询对CPU和内存的使用也明显降低


YARN监控治理
和HDFS的监控治理类似,YARN的监控治理也分为3个层级:第一个层级是基本的可用性监控,第二个层级是集群各项Metrics的监控,第三个层级是对任务资源(CPU&MEMORY)的深度分析和治理,下面展开介绍:
- 第一个层级
主要对ResourceManager、NodeManager、JobHistoryServer的健康状态、JVM各项指标进行监控和报警,比较简单,不再赘述 -
第二个层级
主要对YARN的各项Metrics进行统计分析和监控报警,全面掌控系统核心状态,主要的监控场景有:-
对ResourceManager和NodeManager的RPC活动进行监控,当出现异动时及时发现问题,主要的监控点有: CallQueueLength、NumOpenConnections、ReceivedBytes、RpcAuthenticatio、RpcProcessingTimeAvgTime、RpcProcessingTimeNumOps、RpcQueueTimeAvgTime、RpcQueueTimeNumOps、SentBytes等
-
对集群和队列的核心指标进行监控统计:CPU使用量、CPU使用率、内存使用量、内存使用率、应用运行个数、应用失败个数、应用排队个数、应用耗时分布、应用耗时排行、应用类型统计分析、FairShare分配情况、Container分配运行情况等
-
任务运行时长监控:当任务执行时长超过预警阈值后,及时通知管理员进行分析处理,避免个别异常任务影响集群的整体服务能力
-
任务运行排队监控:当任务排队数量超过预警阈值之后,及时报警排查问题
-
资源异动监控:当集群负载突然飙高,对运行中的任务按照资源使用情况进行排序,快速定位出异常任务,进行诊断分析
-
-
第三个层级
在资源治理方面,我们对开源产品Dr.Elephant进行了二次开发,由于社区版的Dr.Elephant已经停止维护,不支持Spark 2.x版本,因此我们在阅读源码的基础上,对其进行了改造,使其支持Hadoop 2.6.3+Spark 2.0.2版本的Spark任务。该系统上线后,我们通过Dr.Elephant排查有【资源浪费】的任务,及时在调度系统中调整任务的配置,比如Spark任务的executor数量和内存配置,调整后,整个YARN集群的CPU和内存使用率较之前有大幅度降低,高峰时任务排队数量、集群资源报警明显减少;当然,同时也会排查存在【资源紧缺】或【资源倾斜】的任务,及时进行调整。Dr.Elephant开源地址:
https://github.com/linkedin/dr-elephant -
其它模块目前还没有非常深入的研发,此处就暂不介绍了,这个产品也是刚刚完成基本版的建设,以后要走的路还很长,更高效的自动化运维、更深层次的监控分析、更便捷的易用性等都还需要不断迭代
数据开发平台
数据开发平台(内部代号:DSpider)是整个大数据架构中最核心的一个版块,起着承上启下的作用,对下,将底层的技术框架进行集成和封装,转化为不同的功能引擎,对上,为用户提供方便易用的功能,屏蔽技术细节。本章节将对数据开发平台展开详细的介绍
架构介绍
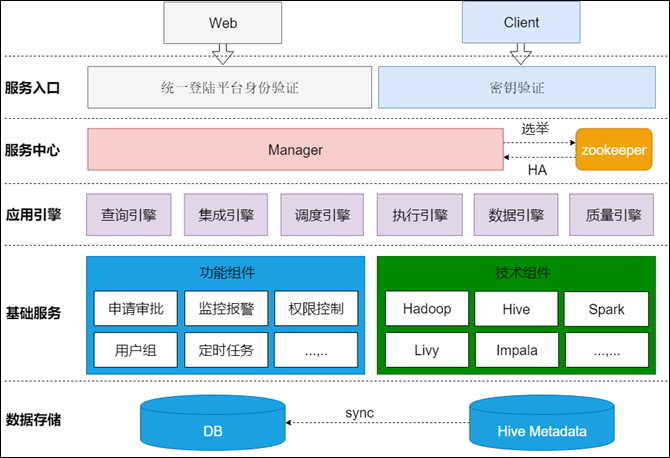
上图展示的是DSpider的应用架构,分为5个层次,分别是数据存储、基础服务、应用引擎、服务中心和服务入口,每个层次的介绍如下:
- 数据存储
使用Mysql数据库,存储平台各个模块的各种类型的数据,如:用户数据、权限数据、调度任务配置数据、调度任务执行数据、查询分析日志数据、任务插件配置数据、数据仓库配置数据、平台的各级元数据等等,其中元数据的管理首先会把Hive的元数据同步到DSpider,然后基于自己的元数据模型再进行整合,提供规范统一的元数据服务 - 基础服务
基础服务分为两类,一类是DSpider自己的基础业务功能组件,如:统一的权限模型、定时调度机制等,另一类是开源的大数据技术组件,如:Hive、Spark等,这些基础服务为上层应用提供了最基础的服务支撑 - 应用引擎
根据不同的应用域划分了不同的应用引擎,如:提供自助分析功能的查询引擎、提供任务开发和编排的调度引擎、提供数据质量稽查的质量引擎等,这些引擎会对基础服务进行集成和封装,聚合出直接面向用户的应用服务,这些引擎是DSpider的核心发动机 - 服务中心
服务中心用来把应用引擎组装到一起,让这些引擎在一个标准化的"机架"上稳定运行,并协调各引擎间的交互关系和调用流程,而为用户提供统一的服务模式和服务体验,如:统一的portal、统一的用户体系、统一的团队体系、统一的审批机制、统一的权限控制、统一的监控报警机制等 - 服务入口
系统目前提供了两类服务入口:其一,提供Web-Portal,用户直接登录系统,进行数据开发和管理;其二,提供编程接口,用户在自己的程序中调用远程服务,实现数据的开发利用
数据引擎
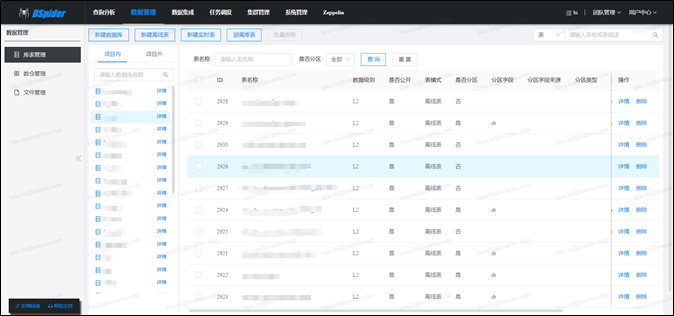

-
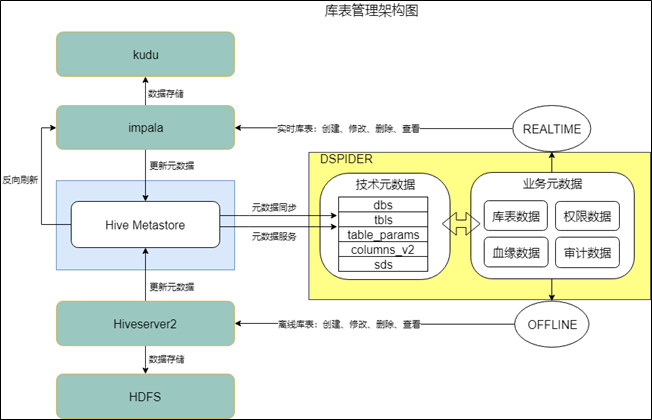
数据引擎目前由3个大的模块组成,分别是库表管理、数仓管理和文件管理。其中库表管理是数据引擎的核心模块,其担负着整个平台的元数据管理功能(平台内的元数据靠Dspider管理,平台外的元数据靠数据交换平台管理,二者对接时会互相提供元数据服务)
-
对于元数据的管理,我们并没有引入第三方开源框架(如:Uber的Databook),而是自己设计了一套数据模型,用于存储库信息、表信息、权限信息、血缘信息等。开源元数据解决方案通常是通过数据采集机制,把分散到各个系统的元数据集成到一起,而我们的解决方案是元数据的管理入口必须经过DSpider,进行集中统一管理,并且当检测到不受平台管理的游离库表时可以进行预警。元数据的管理流程可参见下图:
![]()
整个流程架构可以划分为三部分:
- 第一部分是业务元数据的管理
业务元数据主要记录了各个层级的业务要素,如:库表所属的团队、库表类型(离线库表还是实时库表)、表是否分区、表分区类型(按年?按月?按日?按小时?)、表依据那一列计算分区值、表的主键名称、库表的权限信息、库表的数据安全级别等等,数据引擎通过自定义的数据存储模型保存这些业务元数据。这些元数据作为Dspider的血肉,是各个引擎正常运转的重要支撑,如查询引擎需要使用权限数据控制数据安全,集成引擎的ETL任务需要知道表的业务主键才能进行数据去重和合并,等等。 - 第二部分是技术元数据的管理
如果说业务元数据是系统的血肉,那么技术元数据就是系统的骨架。前面说到Dspider作为元数据的管理入口,自定义了一套元数据存储模型,这个模型主要用来保存元数据的基本信息和业务要素信息,诸如column名称、column类型、存储路径等技术性元数据的管理,靠的还是存储产品自身的机制。我们目前用到的存储产品主要是hive和kudu,二者都可以接入hive-metastore,所以技术元数据全部靠hive-metastore进行管理,当通过impala-server或hive-server对库表进行新增、修改、删除、查看等操作时,hive-metastore提供元数据的服务支撑。 - 第三部分是元数据的协同整合
业务元数据和技术元数据需要整合到一起,才能提供完整的服务,这里"整合"的定义主要是指怎样把技术元数据集成给DSpider,目前我们的整合方式有两种,分别是元数据服务和元数据同步。元数据服务,即直接调用hive-metastore提供的服务接口,来满足常规的功能需求,如获取库表的column详情信息;元数据同步,是通过数据交换平台把hive-metastore的数据实时同步给Dspider,来满足更高级和更灵活的功能需求,如全文检索和关联查询。当后期需要引入除hive-metastore之外的元数据管理产品时,整合方式基本上也就是这两大类,DSpider内部做好隔离和抽象即可。
- 第一部分是业务元数据的管理
-
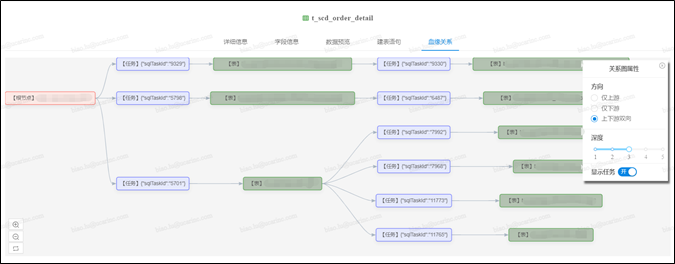
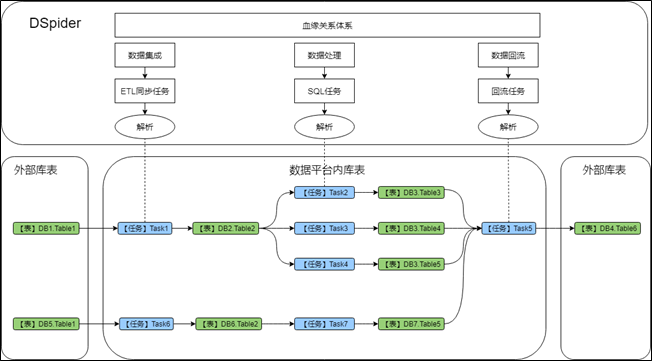
血缘关系(或者叫数据地图)是数据引擎另一个非常重要的模块,其能够立体化分析出数据从哪里来、到哪里去的依赖视图,DSpider的血缘关系不仅能展现大数据平台内表之间的上下游关系,还能把和外部系统的表间关系分析出来。
![]()
如上图所示,血缘分析工作贯通数据平台pipeline的所有环节,主要通过分析【ETL同步任务】、【SQL任务】和【数据回流任务】的配置信息来构建血缘依赖,不仅能展现表之间的直接依赖关系,还可以展示出是靠哪些任务构建出的依赖关系。
-
数仓管理和文件管理两个模块相对比较简单:数仓管理提供的主要功能是维护数仓主题和数仓表之间的关联关系;文件管理主要为用户提供文件目录查看、文件上传下载、文件编辑删除等功能,提供服务的同时会严格控制文件权限。说到权限,数据安全是大数据平台非常重要的一个核心板块,数据权限作为Dspider整体权限模型的一部分,会放到后面的权限模型章节一起进行介绍。
查询引擎
-
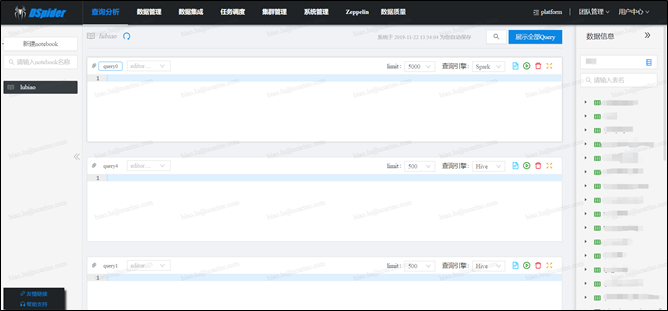
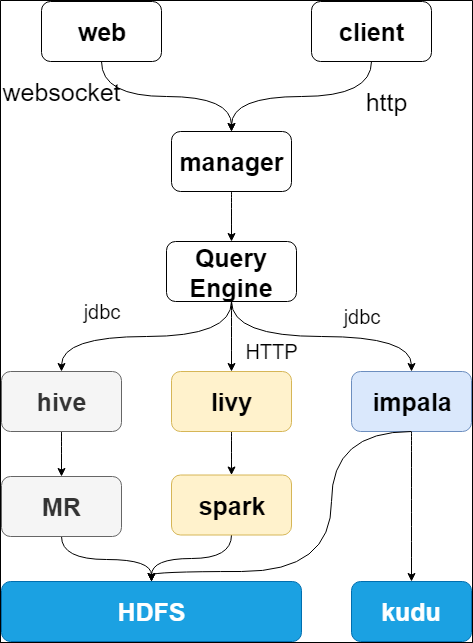
查询分析目前提供3种形式的查询入口,分别是hive-sql、spark-sql和impala-sql,其中spark-sql靠apache livy提供支撑,用户可以任意切换至某种查询引擎进行使用,整个引擎的功能架构图如下所示:
![]()
-
系统通过websocket技术支持查询会话的状态保持,即支持:用户点击查询后,可切换至其它页面并行工作(此时查询操作会在浏览器后台继续执行),待用户切换回查询分析页面后,可继续刚刚的查询会话
-
系统支持notebook的管理、多任务并行查询、查询任务可终止、执行日志的查看、查询历史的记录、查询结果的下载、查询结果的可视化展现等功能
-
除了自建的查询分析模块,系统还集成了zeppelin作为补充,sql查询一般走查询分析的入口,python&scala等脚本查询走zeppelin的入口
集成引擎
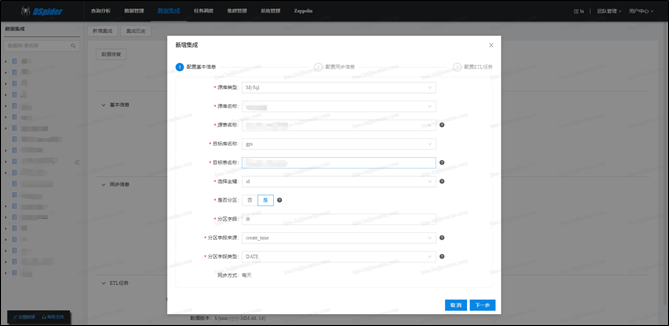
- 所谓【数据集成】就是把源端各类型数据进行采集并加载到ODS数据库的过程,在介绍数据交换平台时,介绍了【数据采集】和【数据加载】功能,这两个功能合到一起,便是此处要介绍的【数据集成】。采集和加载是分别独立的功能板块,而集成是把这两个板块组装、串联到一起,进行更高层次的封装,为用户提供统一服务的引擎
-
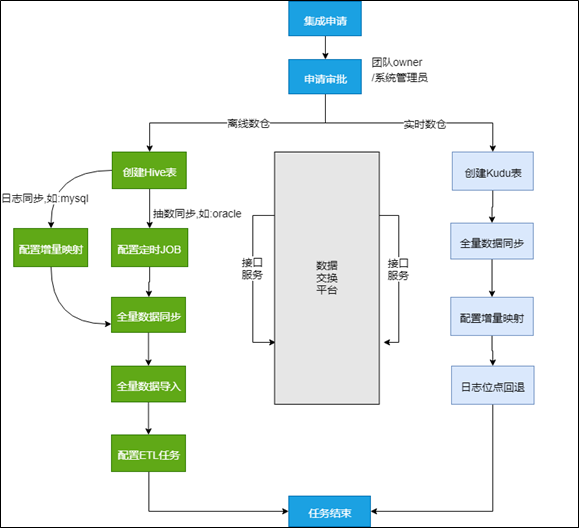
对用户而言,数据集成的处理流程是全透明的,用户只需填写集成申请单,待审批通过之后,数据集成引擎会按照规则进行自动化处理,下图展示的是集成引擎自动处理的主流程
![]()
- 实时数仓的数据集成比较简单,直接配置源DB(Mysql)到目标DB(Kudu)的同步即可
- 离线数仓的数据集成相对复杂,如果源端数据采集方式是【日志同步】,则处理流程为:创建Hive表—>配置增量映射—>全量数据同步—>全量数据导入—>配置ETL任务;如果源端数据采集方式是【直连抽数】,则处理流程为:创建Hive表—>配置定时JOB—>全量数据同步—>全量数据导入—>配置ETL任务;前后两者的流程差异主要在第二步,前者是配置实时增量同步映射,后者是配置定时抽数Job
- 数据集成任务的执行,需要数据交换平台提供服务支撑:【创建Hive表】需要平台提供元数据服务,【配置增量映射】和【日志位点回退】需要平台开放Task配置接口,【配置定时JOB】和【全量数据同步】需要平台开放JOB配置接口等
- 离线数仓流程中,第二步配置的定时JOB和最后一步配置的ETL任务,其执行是靠调度引擎进行驱动的,并且两者是有依赖关系的,只有定时JOB执行完数据同步,ETL任务才能执行合并数据到Hive的操作。定时JOB是由数据交换平台提供的,调度引擎提供对应类型的调度任务,调度任务会保存JobId,任务按照规则被调度引擎触发执行,然后和交换平台进行交互完成执行;ETL任务是调度引擎提供的,不需要跨系统交互,其负责读取增量同步数据或者定时JOB抽取的数据,然后将这些数据进行去重、合并等操作,然后和hive中已有的数据进行全表外连接,完成数据合并的工作
- 数据集成引擎,还提供了补数据的功能,当仓库表出现数据问题,需要修复的时候,用户可以发起修复申请,审批通过之后,系统会自动化进行处理
调度引擎

-
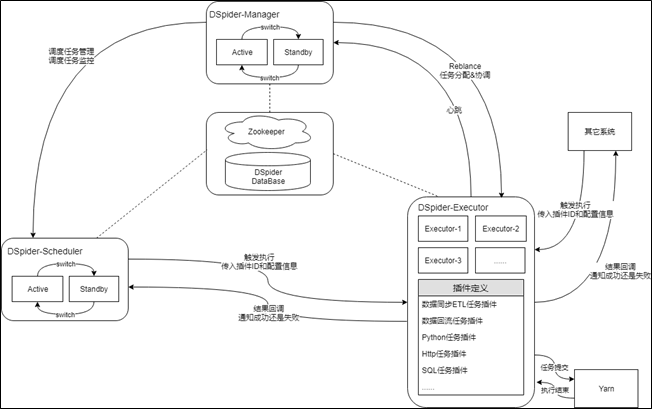
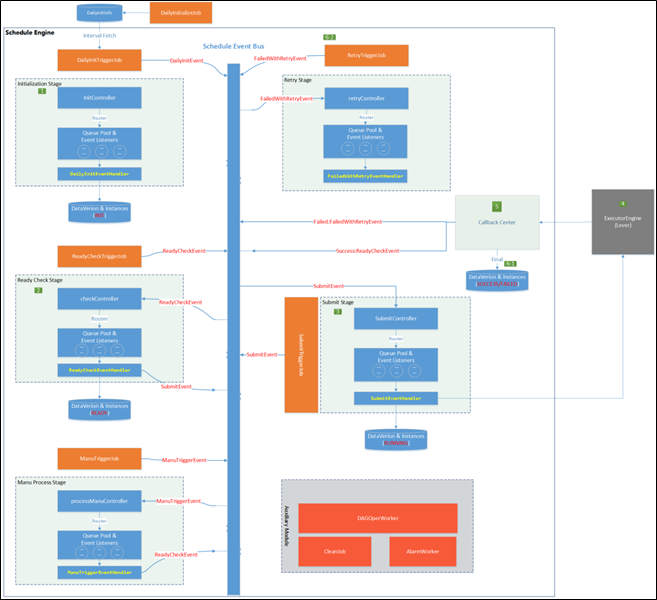
此处所说的【调度引擎】属于调度体系的一部分,下面先对调度体系进行一下总体介绍,调度体系作为大数据平台的指挥中枢由两部分组成,分别是调度引擎(DSpider-Scheduler)和执行引擎(DSpider-Executor),如下图所示:
![]()
-
调度引擎是调度体系的核心中枢,采用主备模式的架构,通过zookeeper进行HA协调,其核心功能主要有作业的定义和管理、作业依赖的控制和管理、作业执行计划的编排和管理、作业的调度和执行、作业运行状态的监控和管理等。
-
执行引擎是调度体系的外围炮火,采用集群模式的架构,可横向任意伸缩,靠DSpider-Manager进行HA协调,其核心功能主要有接收执行请求、对请求进行封装和路由、提交任务到Yarn、任务状态追踪、任务执行结果回调等。调度引擎通过调用执行引擎提供的服务接口,完成调度作业的触发执行,但需要注意的是,执行引擎服务于调度体系,但并不属于调度体系,其可独立存在,除调度引擎外,还有其它很多系统也会调用执行引擎的服务接口。下一小节会对执行引擎进行更详细介绍。
-
-
大数据调度引擎的作业调度有两个流派,静态执行列表和动态执行列表,具体可参见该篇文章:https://blog.csdn.net/colorant/article/details/75090158(或参考《大数据平台基础架构指南》一书中第3章的介绍),我们的引擎采用的是静态执行列表的模式,其应用模型如下所示:
![]()
-
Task是作业计划,作业计划不是执行计划,它只是对作业的定义或配置,主要信息有:作业名称、作业类型、作业的优先级、作业的时间粒度、调度时间规则、失败重试次数、失败重试间隔、是否核心作业、提交到哪个队列执行、申请的CPU和内存资源大小、对应作业类型的各种应用参数,等等。调度引擎的【作业类型】和执行引擎的【任务插件】会有映射关系,一般是1对1的关系,前面说过调度引擎会调用执行引擎的服务接口触发作业的执行,而服务接口要求传入的插件ID就是从此映射关系中获取。
- Task-Collection是作业集,一个作业集是一个工作单元(或称之为功能单元),代表一个独立的功能任务,如创建一个作业集用于统计租车的出租率。在作业集内,用户可以从作业计划列表中选中自己关心的作业,然后配置这些作业之间的依赖关系,形成一个小的"任务流",但是需要强调一点,只是看上去像一个"工作流"而已,调度引擎中并没有"工作流"的概念(或者说并没有静态显示定义和管理工作流,而是动态隐式定义和管理工作流),只有作业依赖的概念,调度引擎只会以作业的粒度按时间和依赖规则进行触发调度。
其实,系统本身只维护了一个或几个DAG图(这个图很很大),每个Task-Collection只是全局DAG图的一个小子集,调度过程中完全不会关心Task-Collection的存在,Task-Collection只是为了便于用户使用而定义的一个概念,让用户只关注自己当前工作单元内任务的依赖关系就好了。不同的Task-Collection可能会有交集,比如在两个Task-Collection中都配置了A、B任务之间的依赖,遇到这种情况系统会自动对重复配置进行合并,保证全局只存储一份依赖关系。 -
Task-DataVersion是作业的数据版本(时间维度),Task-Instance是挂在数据版本下的作业实例,二者合在一起代表的是作业的执行计划。一个作业实例代表的是作业在对应数据版本下的一次执行,作业实例执行成功后会把所依附的数据版本也置为成功,正常情况下,一个数据版本只对应一个作业实例,但当出现作业实例执行失败或对数据版本进行修复时会生成新的作业实例。调度引擎主要是围绕作业实例进行调度触发的,当作业实例满足触发时间时,调度引擎会进一步检查实例依赖的上游数据版本是否成功,如果二者都满足条件将会触发作业实例的执行。总结一下有,数据版本代表了作业在某个业务时间上对数据的一次版本处理,作业实例代表了数据版本的一次执行。
-
我们的调度引擎使用的是【静态执行列表】模式,所以,每天晚上会生成下一天的执行计划,首先为每个作业生成数据版本计划,然后为每个数据版本生成作业实例。作业的时间粒度决定了数据版本的生成方式,如果时间粒度是天,则只会生成一个数据版本,如20191201;如果时间粒度是小时,则会生成24个时间版本,如2019120100~2019120123。
-
-
下面对数据版本着重进行一下说明。我们了解到,一些介绍调度引擎的文章,里面都有Task和Task-Instance的概念,Task用于定义作业计划,Task-Instance用于按作业计划生成执行计划,但并没有数据版本的概念,受限于研究的还不够深入,我们暂时不太清楚其它团队的Task-Instance和我们的Task-Instance都有哪些的区别,也不太清楚其它团队对于基于业务时间的数据版本是如何管理的(猜想一下,可能是在Task-Instance上增加了一个业务时间),所以此处只介绍一下我们的设计初衷和解决方案,不在展开对比和更深入的讲解。
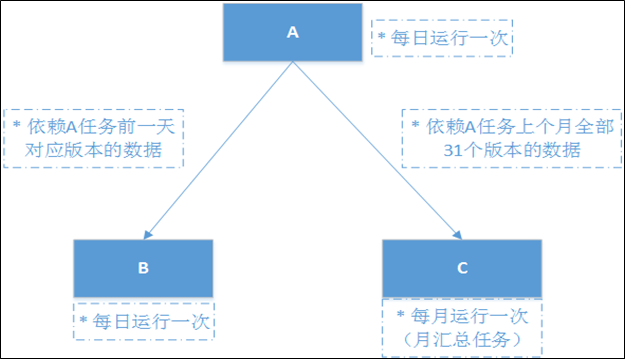
离线大数据平台主要面对的场景是数仓,数仓非常关注的一个核心点就是业务时间,并且作业之间的依赖本质上是对数据作业产生的数据的依赖。鉴于此,我们强化了数据版本的概念,作业的每次执行都框在了数据版本的范畴下,即在某个时间版本下对数据进行处理,每次作业实例执行时系统默认都会把数据版本传给执行上下文,供程序使用。有了数据版本之后,用户如果想修复一段时间内的数据,直接选中起始时间,系统会自动筛选出该段时间内的数据版本,自动进行修复;有了数据版本之后,配置作业之间的依赖关系也会更容易,比如某个按月周期执行的任务需要依赖某个按天周期执行的任务,月任务每次执行时必须保证天任务上个月每天都执行成功,在系统中只需要在配置依赖关系时指定一个"数据版本步长(offset)"即可,如下图所示:![]()
![]()
-
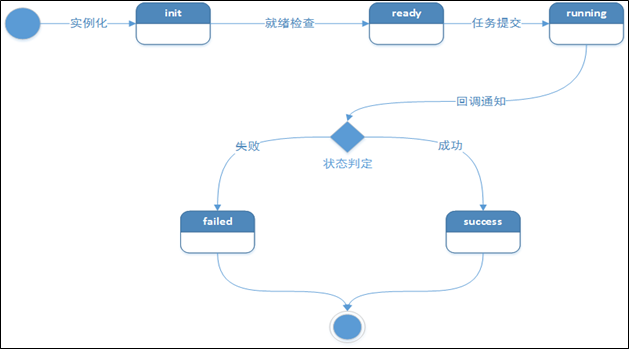
下面对调度系统内部的运行机制进行一下介绍,首先看一下作业实例的状态机,实例一共有5个核心状态,分别是init、ready、running、success和failed,状态间的流转关系比较简单,如下所示:
![]()
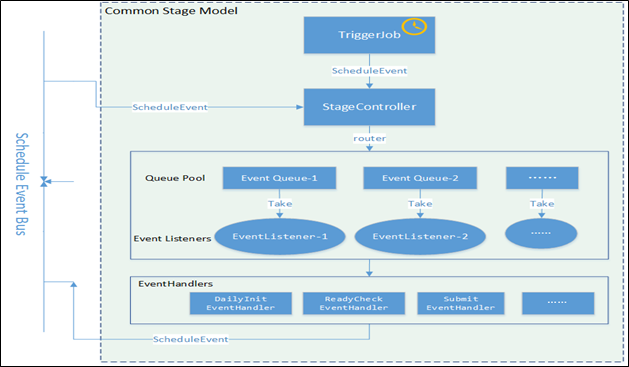
调度引擎的内核是仅仅围绕这个状态机进行设计的,内核整体采用SEDA的设计思想(进行了部分改良),将调度流程分成多个独立的Stage ,每个Stage处理特定的Event,系统全局通过Event机制实现调度引擎运转,为了降低Stage间的耦合度,系统通过独立的Schedule Event Bus(SEB)实现Event在不同Stage间的传递。内核架构如下图所示:
![]()
![]()
几个核心的Stage分别是:InitizlizationStage,接收DailyInitEvent,用于生成下一日的执行计划,生成后的作业实例状态为init;ReadyCheckStage,接收ReadyCheckEvent,用于把满足条件的作业实例状态置为ready;SubmitStage,接收SubmitEvent,用于把满足条件的作业实例状态置为running,并提交作业到执行引擎;RetryStage,接收FailedWithRetryEvent,用于把失败的作业实例状态置为failed,并触发重试;ManuProcessStage,用于接收ManuTriggerEvent,执行用户手动触发的任务实例。
-
最后对调度引擎提供的产品功能,简单进行一下综述,
-
支持全可视化开发
-
支持DAG回环检查
-
支持失败自动重试
-
支持作业执行失败报警
-
支持作业执行超时报警
-
支持作业调度延迟报警
-
支持作业数据版本的单独修复
-
支持作业数据版本的批量修复
-
支持作业修复时触发下游
-
支持作业的图表化监控
-
支持作业的优先级配置
-
支持在线查看运行日志
-
支持为作业添加自定义参数
-
支持作业资源的灵活调整
-
等等
-


执行引擎

-
执行引擎是一个轻量级Master-Slave式的架构,由Manager主备节点和多个Executor节点组成,Executor节点可任意横向伸缩。Manager节点的主要职责是当集群状态发生变化时,对执行中的任务进行再分配(即Rebalance),而集群状态发生变化主要是指有新的Executor加入集群、现有的Executor离开集群和Manager发生主备切换。Executor节点的主要职责是接收任务执行请求,并对执行中的Task进行生命周期的管理,并配合Manager实现集群的HA和对Task的分布式管理。下
-
Executor内部执行流程
执行请求会以轮询的方式分别提交给不同的Executor,Executor会把一次执行请求封装转化为内部的一个Task,同时在内存中构建了多个Task队列,用来对不同阶段、不同状态的Task进行跟踪处理,整个处理流程都是全内存操作,只在关键节点进行Task的持久化,整体流程如下图所示:![]()
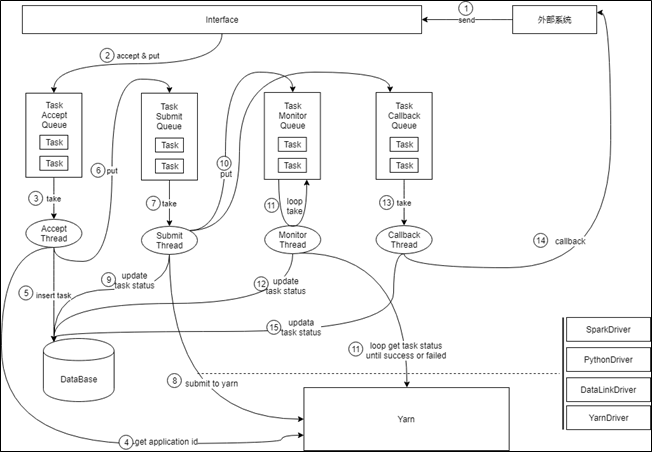
-
外部系统根据负载均衡策略(一般是轮询)发送执行请求到某个Executor
-
Executor接收请求,并将请求封装为Task放入Accept Queue
-
Accept工作线程从AcceptQueue取出Task
-
Accept工作线程访问Yarn,获取一个ApplicationId
-
Accept工作线程将ApplicationId赋给Task,并将Task信息插入数据库,此时Task的状态为INIT
-
Accept工作线程将Task放入Submit Queue,并返回响应给外部系统
-
Submit工作线程将Task从Submit Queue取出
-
Submit工作线程对Task进行解析,找到对应的Driver,用4步取到的ApplicationId进行任务提交
-
Submit工作线程将Task的状态变为RUNNING,并更新数据库
-
Submit工作线程将Task放入Monitor Queue和CallbackQueue
-
Monitor工作线程循环检测Monitor Queue中的Task是否执行完毕,将完毕的Task移出队列
-
对执行完毕的Task进行状态变更,并更新数据库,状态可以是SUCCEED、FAILED和KILLED
-
Callback工作线程将执行完毕的Task从Callback Queue中取出
-
调用外部系统回调接口通知Task执行结果
补充说明:1) 上图展示的是正向的核心流程,对一些异常情况的处理并没有体现出来;2) 第4步获取的ApplicationId非常重要,是系统进行幂等判断的主要依据,场景举例:第8步中Task提交到Yarn之后,Executor发生了宕机,然后触发了集群的Rebalance,随后Task被其它Executor接管,因为宕机前第9步未来得及执行,所以Task的状态还是INIT,被新的Executor接管后会被放到SubmitQueue,第8步会被新的Executor重复执行,但Yarn能识别这是重复提交,会予以忽略。
-
架构、HA和Rebalance流程
前面提到执行引擎是一个轻量级的Master-Slave架构,之所以说轻量级是因为Manager只在集群发生状态改变时才会介入,集群处于稳定状态时,Manager只和Executor维持心跳,并且对于外部系统来说也完全感知不到Manager的存在,外部系统直接和Executor进行对接。这个架构的主要特点是:-
系统处于稳定状态时,执行请求会轮询分配给不同的Executor,构建好的Task会驻留在Executor的内存中被处理,只在关键处理节点对Task进行持久化操作。此种分布式的设计,保证了系统的高可伸缩性,当Task数量增加时对应增加Executor机器即可,即可线性扩展。而传统的方式一般为将任务保存到数据库,然后通过定时任务扫表的方式驱动Task的执行,这种方式会很快触发性能瓶颈,因为随着Task数量的增多,扫描数据库的成本会越来越高,增加再多Executor也没用。
-
当系统发生状态变更时,系统会依托HA和Rebalance机制,根据数据库中保存的Task信息,对执行状态进行快速重建,保证系统快速恢复为稳定状态,完成从一个generation到下一个generation的重生。状态恢复后,可能会出现处理步骤被重复执行的问题,对于此,系统会提供一整套幂等机制,保证数据的一致性,如上文所述的ApplicationId。
Rebalance的机制和流程如下图所示:
-
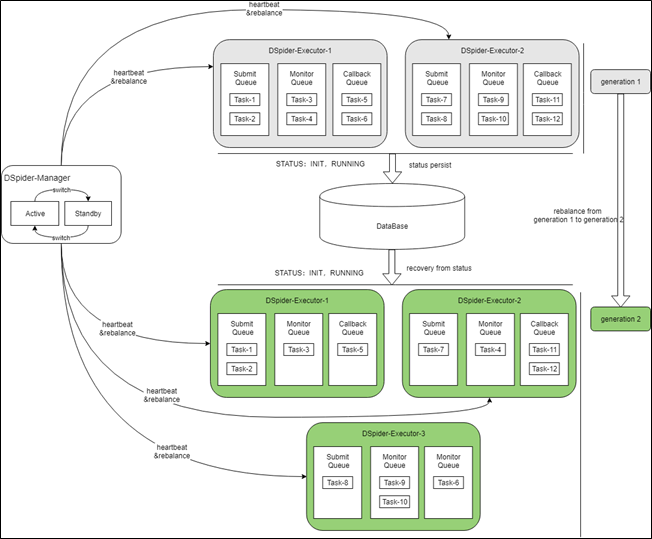
-
插件机制
执行引擎只是一个容器,Task也只是一个执行载体,最终提交到Yarn上的执行程序是任务插件,任务插件是支持一类功能的程序集,如:Sql插件可以执行各种类型的sql语句。执行引擎、Task和任务插件的交互关系如下图所示:![]()
执行引擎内置了一部分通用的插件供用户使用,并提供了可扩展的插件模型,方便用户自定义,自定义插件的上架流程也很简单:第一步开发插件,第二步注册插件,第三步上传插件,第四步使用插件。系统内置的核心通用插件简介如下:
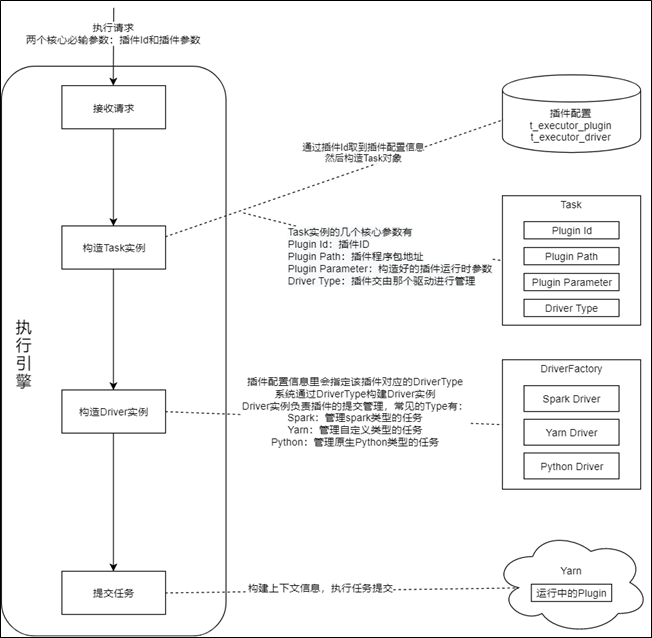
-
数据采集插件 (与数据交换平台打通,将业务数据同步到hdfs)
-
表同步ETL插件(将数据交换同步过来的数据文件进行去重和清洗,并合并到Hive表)
-
Sql插件(支持用户通过写Sql语句(hivesql、sparksql、impalasql等),对Hive、Kudu表数据进行操作)
-
Datalink回流插件(支持用户通过简单配置生成回流任务,比Spark回流插件更便捷)
-
Spark回流插件(支持用户通过SpakrSql将Hive表数据回流到业务库,比Datalink回流插件更灵活)
-
HTTP任务插件(根据用户传入的URL,发起http调用请求)
-
等等
质量引擎
数据质量的保证是所有一切数据分析和数据挖掘的基础,DSpider的质量引擎,提供了一套统一的流程来定义和检测数据集的质量并及时报告问题,其内核设计建立在Apache Griffin的基础上,并做了很多二次改造和封装,其功能模块主要分为三个部分:质量定义,数据度量和质量校验。总体架构图如下所示:

-
质量定义
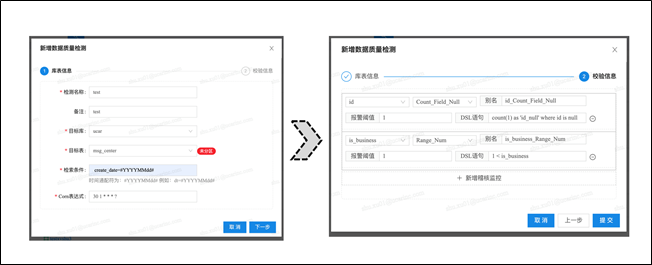
质量定义模块为用户提供【质量稽查任务】的配置入口,主要配置信息有:-
数据源(对哪些库表进行监测)
-
数据范围(监测哪个分区下哪些数据)
-
度量指标(度量哪些字段、取值规则是什么,等)
-
触发方式(定时表达式触发还是事件触发)
-
报警规则(出现问题时如何报警,报给谁,等)
-
如下是新增质量定义的页面截图,供参考
- 数据度量
数据度量,是执行【质量稽查任务】的过程,系统提供了不同类型的度量插件来执行这些稽查任务。任务达到触发条件后(定时触发或事件触发),对应的度量插件会被初始化,然后提交到Livy进行执行,每个任务执行的大体流程为:解析数据质量定义参数à转换为spark sql à执行sqlà将执行结果存储在ES中。质量引擎会定时从Livy中拉取任务状态,更新到Grififn本身数据库,并提供页面查看任务执行详情及ES中保存的执行结果。 - 数据校验
数据校验,是对数据度量的执行结果进行分析报警的过程,如果出现异常数据,则插入报警记录,通过Rest发送报警信息到相关系统
权限模型
权限有两类,功能权限和数据权限,此处所说的权限模型主要是指数据权限(以及和Group关联的功能权限,下文有述)。对于大数据平台来说,数据权限模型的设计,是一个很大的痛点问题,主要原因在于业界没有一套统一的权限标准,平台建设过程中集成的很多框架或产品,要么没有权限模块(如:Spark),要么比较薄弱,要么自成体系。另外,不同公司或团队对权限的要求也不尽相同,各家公司大数据平台的架构方案也不尽相同,这就导致权限模型很难复用,都需要建设者自行开拓出一套适合自己的体系。
虽然没有银弹,但业界还是有不少可参考的解决方案的,《大数据平台基础架构指南》一书的第7章做了很好的总结,里面列举了各种技术方案,并做了深入的优缺点分析,可参考学习。在参考了不少技术文章和博客后,我们的权限模型设计思路也逐渐清晰,一句话来总结:统一服务入口,通用权限模型,合理平衡折中。首先通过服务入口的统一,保证数据使用者无法绕过权限验证;然后通过标准化权限模型和体系,屏蔽不同的技术组件,提供统一的权限体验;最后通过不同场景的适配,控制权限的松紧程度。
接下来对权限模型展开介绍。DSpider是一个多租户的平台,不同团队的不同个体都可以使用平台提供的服务,同时平台管理的各种数据和资源也带有团队的属性,团队之间的数据访问也都需要进行权限控制。团队、个人、数据、资源,是DSpider权限模型的基本组成要素,如下图所示:
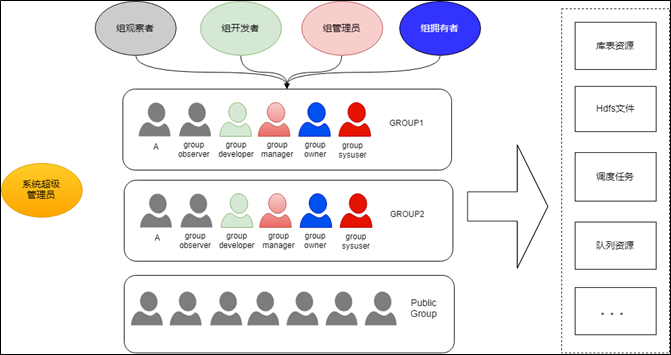
-
团队(Group)是权限模型的核心概念,数仓里的库表会归属不同的团队、文件目录会归属不同的团队、调度任务会归属不同的团队、Yarn中定义的队列会归属不同的团队等等,团队之间的资源控制是相对隔离的
-
团队(Group)内有不同的角色,分别是组拥有者、组管理员、组开发者和组观察者,拥有者具有至高无上的功能和数据权限,管理员拥有大部分的功能和数据权限,开发者只拥有涉及数据开发的功能和数据权限,观察者只拥有只读权限。此外,每个团队还有一个虚拟的组系统用户,系统用户用来执行很多后台程序,如每天的调度任务,系统用户的数据权限等同于GroupOwner
-
团队(Group)内的成员,对于库表和文件数据的Read权限都是平等的,即只要一个用户加入了某个团队,对团队的库表数据和文件数据就有了查看的权限。这么设计的一个背景是,对于研发团队来说,团队内的成员就没必要控制读取数据的权限了,否则的话,不仅管理繁琐,开发效率也会比较低下,所以只要团队的Owner控制好人员的准入就好了
-
跨团队的资源访问控制分为两类:一类是必须经过申请审批流程才能拥有读取权限(如:库表数据的Read权限),申请时可以以个人的名义申请,也可以为整个团队进行申请(只有团队Owner才有资格为团队申请);另一类是无需经过审批就能拥有查看权限(如:查看其它团队的调度任务)
-
下面对不同资源的权限控制做个总结:对于库表数据来说,权限控制的最严格,团队内的成员都拥有Read权限,团队外成员想拥有Read权限必须发起申请;对于文件数据来说,团队公共目录,团队成员都拥有读写权限,个人私有目录仅限于个人自己访问;对于调度任务来说,所有成员都可以查看任务,只有团队内成员才有编辑和删除权限,但允许配置跨团队的任务依赖;对于队列资源来说,每个团队只能使用自己的队列资源,团队间是完全隔离的
上面介绍的是权限体系的概念模型,概念模型如何映射为技术层面的物理模型,是比较有挑战的地方,下图展示的是DSpider权限模型的技术方案
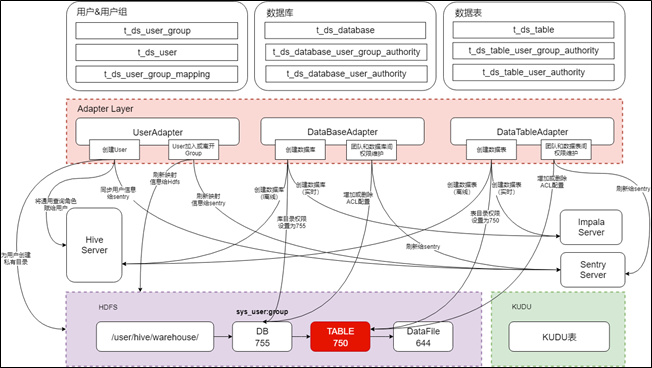
-
物理模型分为2个层次:第一层是权限定义层,用来定义不同的权限实体,以及实体之间的关联关系,屏蔽具体的技术细节,提供一套统一的领域模型;第二层是转化适配层,用来对权限配置进行映射转化,针对不同的技术框架设计不同的实现方案,保证权限目标的落地
-
上图展现了两种权限控制方案,一种是基于HDFS文件目录的权限控制方案,一种是基于Sentry的权限控制方案,前者用来控制Hive离线库表的权限,后者用来控制Kudu实时库表的权限。但并不代表该权限模型只支持这两种方案,当有其它技术框架或产品接入平台时,如果现有方案不能满足需求,在Adapter Layer进行逻辑扩展即可
-
对于Hive库表来说,我们并没有使用HiveServer自带的权限体系,因为其只能校验以Hive为入口的数据请求,当入口为Spark、Python或者用户自定义程序包时,无法进行校验,并且Hive自带的权限机制也不是很健全。鉴于此,我们选择了将权限控制下推给HDFS的方案(即:将权限定义直接映射转化到HDFS),直接靠HDFS的POSIX和ACL权限模型进行控制,当创建数据库表时,将对应目录的user属性设置为库表所属团队的系统用户,将对应目录的group属性设置为库表所属的团队,并将表目录的权限设置为750(rwxr_x___)。因为用户和团队的映射关系会刷新给HDFS(参见core-site.xml文件的hadoop.security.group.mapping配置),所以按照上述规则,团队内所有用户默认都会有表的Read权限,团队外的所有用户默认都没有Read权限,当需要单独为团队外的用户或其它整个团队配置库表权限时,在表目录上增加ACL控制即可,因为只在表这一级目录加ACL配置,也不会触发性能问题。HiveServer端需要做的事情是维护一个通用的查询角色,并将该角色赋给DSpider中所有的用户,即将权限校验透传给HDFS,保证HiveServer端都能通过,除此之外HiveServer还需开启用户代理机制,保证所有经过HiveServer的请求都能以实际用户的名义访问HDFS,关于代理机制的介绍可参见下面两个链接
https://blog.csdn.net/yu616568/article/details/54969729 ,https://www.cnblogs.com/tomato0906/articles/6057294.html
基于此方案,不管数据请求从哪个入口进入,都可以靠底层的HDFS权限进行控制,但有一个前提是访问入口能支持以实际用户的名义访问HDFS,如果不能支持,就得考虑其它方案
-
对于KUDU库表来说,我们限制了其访问入口只能是Impala,但Impala自己没有权限模块,它靠的是Sentry,所以我们需要将自定义的权限模型适配转化为Sentry的权限模型,才能实现权限控制,转化逻辑不再详述,可参考Sentry的官方文档。另外,Impala不仅能访问KUDU,还可以访问Hive,但其访问HDFS上的Hive数据时无法提供用户代理机制,所以Impala访问Hive数据时权限控制靠的不是HDFS的ACL,而是和KUDU一样,靠的Sentry。
总结规划
平台经过一年多的建设,已经基本成熟,但还有很多细节需要慢慢去研磨,目前只能说刚刚脱贫,同小康和全面富裕的目标相比,还有很长的路要走。在开发效率和系统资源的优化上还有很大提升空间,把离线平台、实时平台以及机器学习平台进行打通也是一个重点规划,总之,一直在路上。
平台建设心得一:系统建设可以先污染后治理,但不要污染到无可救药,否则带来的将是巨大的填坑成本和痛苦的系统重构,应该做好总体规划、做好过程控制、做好快速迭代。不谋万世者,不足谋一时;不谋全局者,不足谋一域;言前定则不跲,事前定则不困,行前定则不疚,道前定则不穷。
平台建设心得二:引用别人的一句话,系统建设的难点不在于组装多少时髦组件,而在于对技术和产品本质的理解,以及对公司文化、业务特点、团队组成等一系列真实世界问题的认知、思考和权衡。
附录
附一些数据架构相关的资料链接,供学习参考
产品架构
- 工作六年,我总结了一份数据产品建设指南
http://www.woshipm.com/pd/2095114.html -
360大数据中心平台化的演进与实践
https://mp.weixin.qq.com/s/rC37pV7mCluWOwEUbMKmPg - 大数据开发平台(Data Platform)在有赞的最佳实践
https://tech.youzan.com/data_platform/ - 为什么选择这样的大数据平台架构?
http://bigdata.51cto.com/art/201706/542792.htm - 余利华:网易大数据平台架构实践分享
http://bigdata.it168.com/a2018/0828/5011/000005011828.shtml - 面对日近两百亿数据量,美图大数据平台如何建成?
https://mp.weixin.qq.com/s/h1_klaZonIQnDdLlupvS4w - 民生银行大数据体系结构设计与演进
https://mp.weixin.qq.com/s/_ku8TNLC0XTMelsdvSUSUg - Netflix首次完整披露大数据分析基础架构
http://m.sohu.com/a/131167131_470008 - 这两年在大数据行业中的工作总结
https://mp.weixin.qq.com/s/n6bYiiWFx5NUbRtw9Ncn8w - 自服务数据共享与服务架构详解
https://mp.weixin.qq.com/s/78f6CLOtrJfgoU3Ie8AMfw - 数据中台已成下一风口,它会颠覆数据工程师的工作吗?
https://mp.weixin.qq.com/s/_KsFeHGUt62A7w3kvNlf2A - 实时主动数据仓库的概念、问题及应用
https://blog.csdn.net/pear_zi/article/details/6922572 - 如何设计实时数据平台(设计篇)
https://blog.csdn.net/gao2175/article/details/92994770 - 如何设计实时数据平台(技术篇)
https://blog.csdn.net/gao2175/article/details/93179965 - 一图读懂58大数据平台架构演进
https://mp.weixin.qq.com/s/ITDtgHti13pigiB8llZwRw - 百分点万亿级大数据平台的建设实践
https://mp.weixin.qq.com/s/efmYtf-sQd-M64OiHNJZAw - SQL on Hadoop在快手大数据平台的实践与优化
https://mp.weixin.qq.com/s/vTIgkf5CMaEoFEjPXrMoRA - 阿里巴巴大数据在高德地图上的应用
https://mp.weixin.qq.com/s/C9dZjlEXf0QytJKRZbEUJQ - Uber 大数据平台的演进(2014~2019)
https://mp.weixin.qq.com/s/IL-t_YttB9LcXJimqOl2wA
技术架构
- 运营商大规模数据集群治理实践指南
https://mp.weixin.qq.com/s/fFSp1_8Kk7MRaMc8LlGMdg - 【独家】一文读懂大数据计算框架与平台
https://mp.weixin.qq.com/s/Tij8H-J2-o09ZozcWXNUOg - 大数据平台常见开源工具集锦(强烈推荐收藏)
https://mp.weixin.qq.com/s/nRLur6aBXrIrwPE4AzfERw - 大数据架构如何做到流批一体
https://yq.aliyun.com/articles/706954?spm=a2c4e.11153940.0.0.578e3bbbsnEqQs - 唯品会大数据存储和计算资源管理的痛、解决方法与思路(附PPT)
https://mp.weixin.qq.com/s/0nb81YRMBpqwJn_IA7JZew - 千亿级的数据难题,优酷工程师怎么解决?
https://mp.weixin.qq.com/s/yUWtbm1Yzg4yc9rom30HJA - 进击的实时数仓:Flink在OPPO实时计算平台的研发与应用实践
https://mp.weixin.qq.com/s/B2BoJdIUw4RqI-aurtyeZA - Hadoop深度运维:Apache集群原地升级Ambari-HDP
https://mp.weixin.qq.com/s/sVmJ0i758tf9PStkKLRQDg - 独家揭秘!阿里大规模数据中心的性能分析
https://mp.weixin.qq.com/s/HRwn7CvY6D6OsJzN9tWKQg - [数据湖技术系列] 用于实时大数据处理的 Lambda 架构
http://blog.bingocloud.cn/archives/3308 - 阿里如何实现秒级百万TPS?搜索离线大数据平台架构解读
https://mp.weixin.qq.com/s/VKsbBvKibLDc-wFvYn3nxg
查询分析
- 如何打造一流的查询引擎,构建优秀的数据仓库?
https://mp.weixin.qq.com/s/2fdeRWNUkUfJSLOrzRKzbw - 快手万亿级实时OLAP平台的建设与实践
https://mp.weixin.qq.com/s/bKDtv892f4TJVV-JjW0vfQ - Kylin在马蜂窝数据分析团队的应用实战
https://mp.weixin.qq.com/s/9nUAVsv3mkcq4_nOhEyI0w - 实践 | Kylin在滴滴OLAP引擎中的应用
https://mp.weixin.qq.com/s/WDaSJHeHvWTDjGkUR7zmfg - Apache Kylin实践:链家数据分析引擎的演变史
https://mp.weixin.qq.com/s/0Ge7OYt-E-Z2JzAHUCiGBA - 实践 | Apache Kylin在4399大数据平台的应用
https://mp.weixin.qq.com/s/VYV5WhS2E4TB8BxUpWpsmQ - 每日生产万亿消息数据入库,腾讯如何突破大数据分析架构瓶颈
https://mp.weixin.qq.com/s/Y4MtwJsbGWx3XqajGV3ZpA - 小米大数据:借助Apache Kylin打造高效、易用的一站式OLAP解决方案
https://mp.weixin.qq.com/s/JPK_wHHaI6KPbw3hP34H5g - 每日生产万亿消息数据入库,腾讯如何突破大数据分析架构瓶颈
https://mp.weixin.qq.com/s/Y4MtwJsbGWx3XqajGV3ZpA - 卷皮OLAP平台进化史:Apache Kylin在卷皮网大数据平台的运用
https://mp.weixin.qq.com/s/QKkX6v07gr62qne0kpFKmw - 快手 HBase 在千亿级用户特征数据分析中的应用与实践
https://mp.weixin.qq.com/s/8VSH61TlWv7dXiPtrFDXaQ
调度系统
- 深入大数据平台心脏:饿了么调度系统全解
http://url.cn/5fnaDo9 - 数据平台作业调度系统详解-理论篇
https://blog.csdn.net/colorant/article/details/75090158 - 数据平台作业调度系统详解-实践篇
https://blog.csdn.net/colorant/article/details/76034188 - 苏宁大数据离线任务开发调度平台实践:设计与开发过程中的要点
https://mp.weixin.qq.com/s/t1rB-1y7_jIF-a51D97KXg - 深度解析 | 基于DAG的分布式任务调度平台:Maat
https://mp.weixin.qq.com/s/39FG8FXADFC9UQuUJGTwbQ
数据治理
- 广发证券:智能金融数据质量监控系统建设之路
https://mp.weixin.qq.com/s/ujmkcA5VLvnGMXd19DVSow - Uber推出Databook平台:自动收集元数据并转化为大数据洞见
https://mp.weixin.qq.com/s/F7jpPK2lr-N1RPOf9uW8SA - 重磅!Netflix开源大数据发现服务框架Metacat
https://mp.weixin.qq.com/s/_9WoyQd6ksPKuRbYiFpPdQ
流式计算
- 苏宁基于Spark Streaming的实时日志分析系统实践
https://mp.weixin.qq.com/s/KPTM02-ICt72_7ZdRZIHBA - 唯品会实时计算平台的演进之路
https://mp.weixin.qq.com/s/ZTm6B0NyPQ00CztV1whySg - 实时数据平台设计:技术选型与应用场景适配模式
https://mp.weixin.qq.com/s/zNN8F9xvimtHLdwpjCJ_Zg - 实时流处理统一批处理的最后一块拼图——Pravega
https://mp.weixin.qq.com/s/HK1bu1R3GpdrOkUYmCXgxQ - 以Flink为例,消除流处理常见的六大谬见
http://mobile.51cto.com/adatabase-524305.htm
数据集成
-
美团DB数据同步到数据仓库的架构与实践
https://mp.weixin.qq.com/s/MrGSWXd1Oa3jSjYX87ObSg -
弃用ETL,为什么说ELT才更适合AI应用场景?
https://mp.weixin.qq.com/s/osCRnfnuCFGJIR1jkhgUwA -
DataX在有赞大数据平台的实践
https://tech.youzan.com/datax-in-action/ -
Uber推出数据湖集成神器DBEvents,支持MySQL、Cassandra等
https://mp.weixin.qq.com/s/O94Q1Dxe8TnbCMv9d_hlOg' -
数据埋点太难!知乎的做法有何可借鉴之处
https://mp.weixin.qq.com/s/IvGkPnYdifuAzrUV3MTyhA -
Apache新成员:LinkedIn分布式数据集成框架Gobblin
https://mp.weixin.qq.com/s/IJghN051vddzBAGb0KkcpQ -
开源实时数据处理系统Pulsar:一套搞定Kafka+Flink+DB
https://mp.weixin.qq.com/s/B9zo0zThARAi11hRuJ-AqA

 浙公网安备 33010602011771号
浙公网安备 33010602011771号