【08】爬虫
1、相关包准备
- win10打开cmd,直接pip install 包名,安装
requests、beautifulsoup4、prettytable包
2、html基础准备
-详见链接https://www.jianshu.com/p/256296abefdc
- HTML标签主要分为单标签和双标签两类。单标签只有开始标签,所以需要在开始的同时关闭,例如meta标签,用于定义Web网页的基本信息。以下meta标签指定了网页使用UTF-8字符集,通过标签的属性值进行设定,即将属性名和属性值都写在标签内部。
- h1至h6,分别表示一级标题至六级标题,标题文字会依次减小
- 再介绍两个新的概念:块级标签和内联标签。块级标签单独占据一行,其后面的标签会在下一行出现,而多个内联标签则会显示在同一行中,直到总宽度超过了浏览器宽度才换行。之前介绍的h1至h6、p都是块级标签,而a、img则是内联标签。浏览器在渲染HTML页面时会遵循默认的文档流,从上往下依次显示每个HTML标签,对于块级标签则独占一行,对于内联标签则放置在同一行,直到总宽度超过浏览器宽度才换行。
- 可以在HTML标签之间或者p等标签内容中添加br,用于添加空白行或换行
- div和span分别属于块级标签和内联标签,都可以用作其他HTML标签或页面文本的容器。它们本身没有具体的语义,仅作为其他内容的容器,从而将Web页面更加结构化地组织起来。我们在设计网页时,往往会将页面划分为多个区域,例如导航栏、侧边栏、第一部分、第二部分、第三部分、底栏等,如果将全部内容都直接写在body的下一级中,则会给开发带来很大的不便。相比之下,合理使用div勾勒出网页内容的结构和层次,可以使代码编写和阅读变得更加清晰明朗。
- 使用table标签可以定义表格,用tr表示表格中的每一行,用td表示每一行中的单元格,用th表示表头行中的单元格。以下是一个简单的例子,当然可以通过更复杂的语法实现合并单元格等效果,在我们掌握了CSS之后,也可以进一步美化表格样式,使得表格看起来更美观。
- 使用ul和ol定义列表,分别对应无序列表和有序列表,用于展示多个并列项,每一项用li定义
3、编解码
以网页使用gbk编码,如何正常显示获取的数据为例,大致过程如下所示。
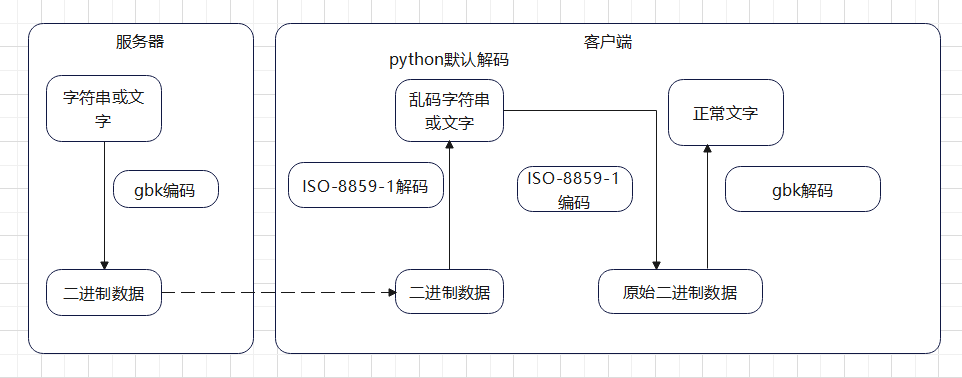
- 网页使用gbk编码,所以我们爬虫抓取的数据是原始文字,经过gbk编码得到的二进制数据;
- 而python会使用默认的ISO-8859-1来解码二进制数据,所以显示的文字会乱码;
- 此时想要正确显示文字,需要先对解码后的字符串,进行ISO-8859-1格式的编码,还原成服务端的二进制数据,再用gbk格式进行解码,就可以得到正常显示的文字了
import requests
url='https://www.qbiqu.com/0_1/'
response=requests.get(url)
print(response.text.encode(response.encoding).decode('gbk')) #先对字符串进行编码还原成原始二进制数据,再用gbk解码得到正常文字,其中response.encoding为python默认编码,response.apparent_encoding是通过内容分析出的编码,使用response.apparent_encoding也行,代码对不同编码格式的网站兼容性更强
4 BS4学习
首要学习文档,BS4官方文档链接
BS4的特点就是把网站数据存储为树结构,上面的中文文档还是很好用的,重点学习遍历文档树,搜索文档树,输出,最常用的是find_all方法,过滤器功能很强大。取网页数据时可以翻翻搜索和遍历文档树,把数据过滤出来
- 以BS4爬取网站小说内容写入csv文件为例
4.1 准备部分
import csv
import time
from bs4 import BeautifulSoup
import requests
url = "https://www.qbiqu.com/0_1/"
with open("chapter.csv", 'w', newline='', encoding='utf-8') as f:
writer = csv.writer(f)
resp = requests.get(url)
# print(resp.text.encode(resp.encoding).decode(resp.apparent_encoding)) #查看html响应报文解码是否正常
resp_text_decode = resp.text.encode(resp.encoding).decode(resp.apparent_encoding)
resp.encoding = 'utf-8'
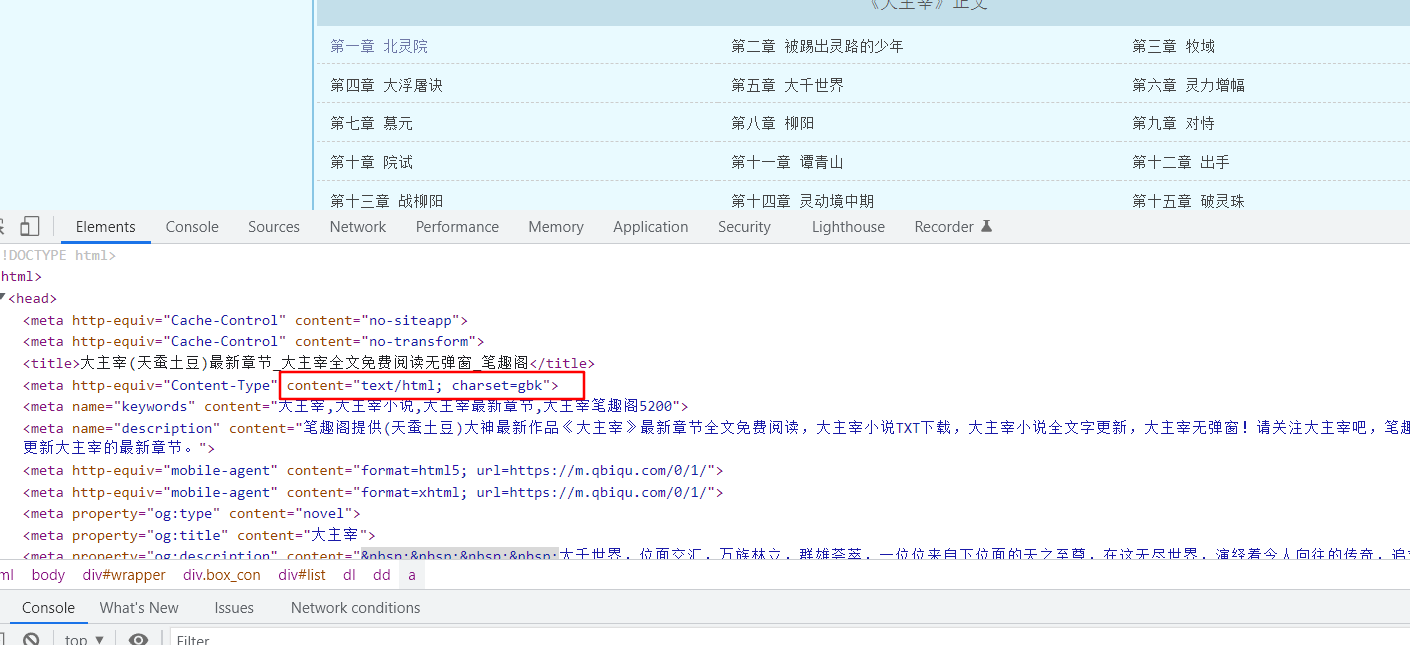
newline=''是为了规避csv读写的换行- resp_text_decode是对网站爬取之后进行解码。因为网站使用gbk编码,直接resp.text中文是乱码,python(或者requests?)默认编码是ISO-8859-1,祥见上面。
- 网站编码格式在head头里面可以查询
![]()
4.2 解析数据
- 分析网页,找到小说的章节目录页面,需要拿到章节目录的http链接
![]()
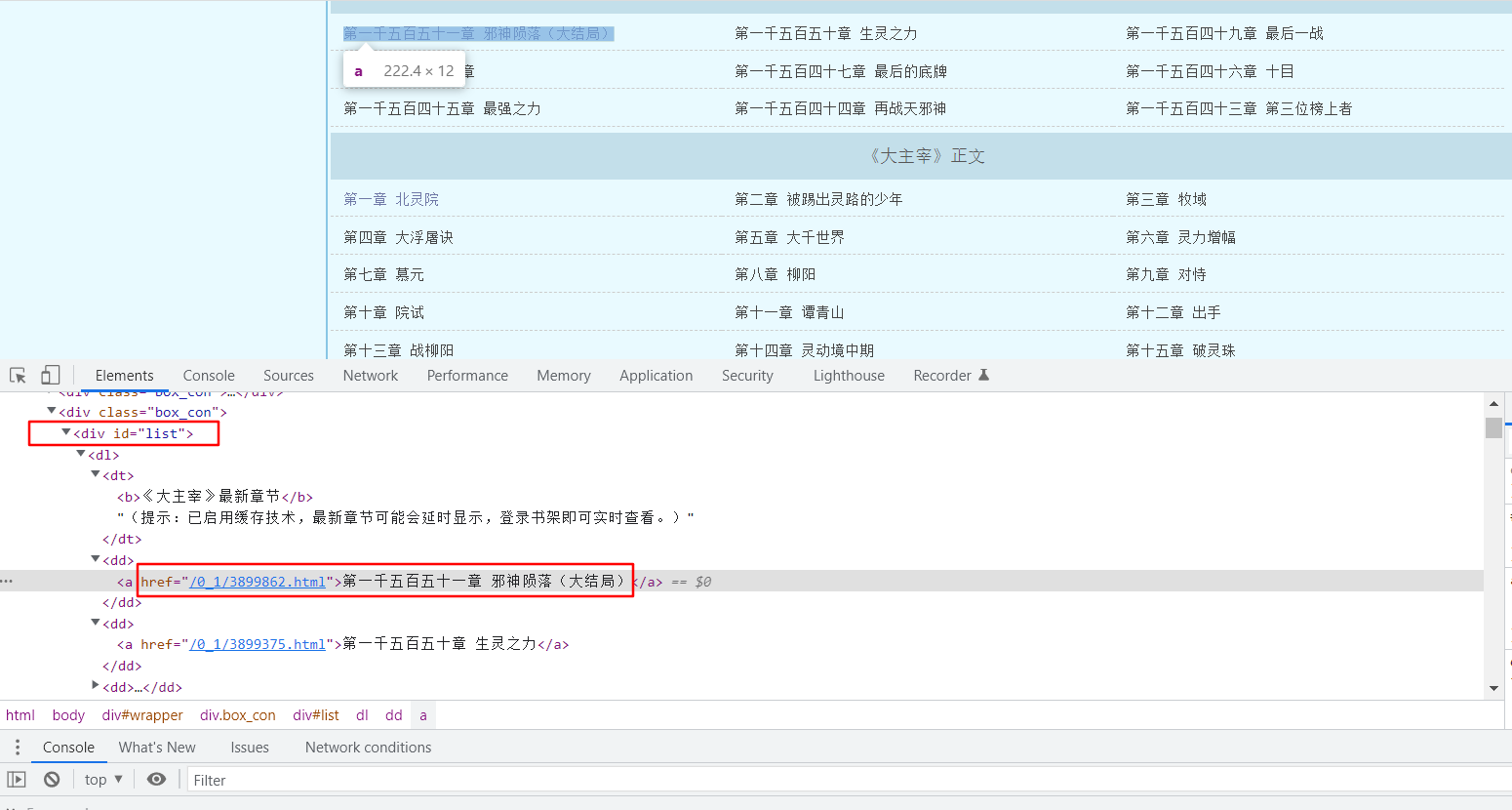
如上图,小说章节目录链接及名称,在div标签,id为list的里面一层的dd标签里面的a标签里
soup_html = BeautifulSoup(resp_text_decode, "html.parser")#注意这部分在with里面,有一个tab的缩进
dd_out=soup_html.find_all('dd') #这一行直接查找所有dd标签,返回的dd_out是很多dd标签tag组成的列表
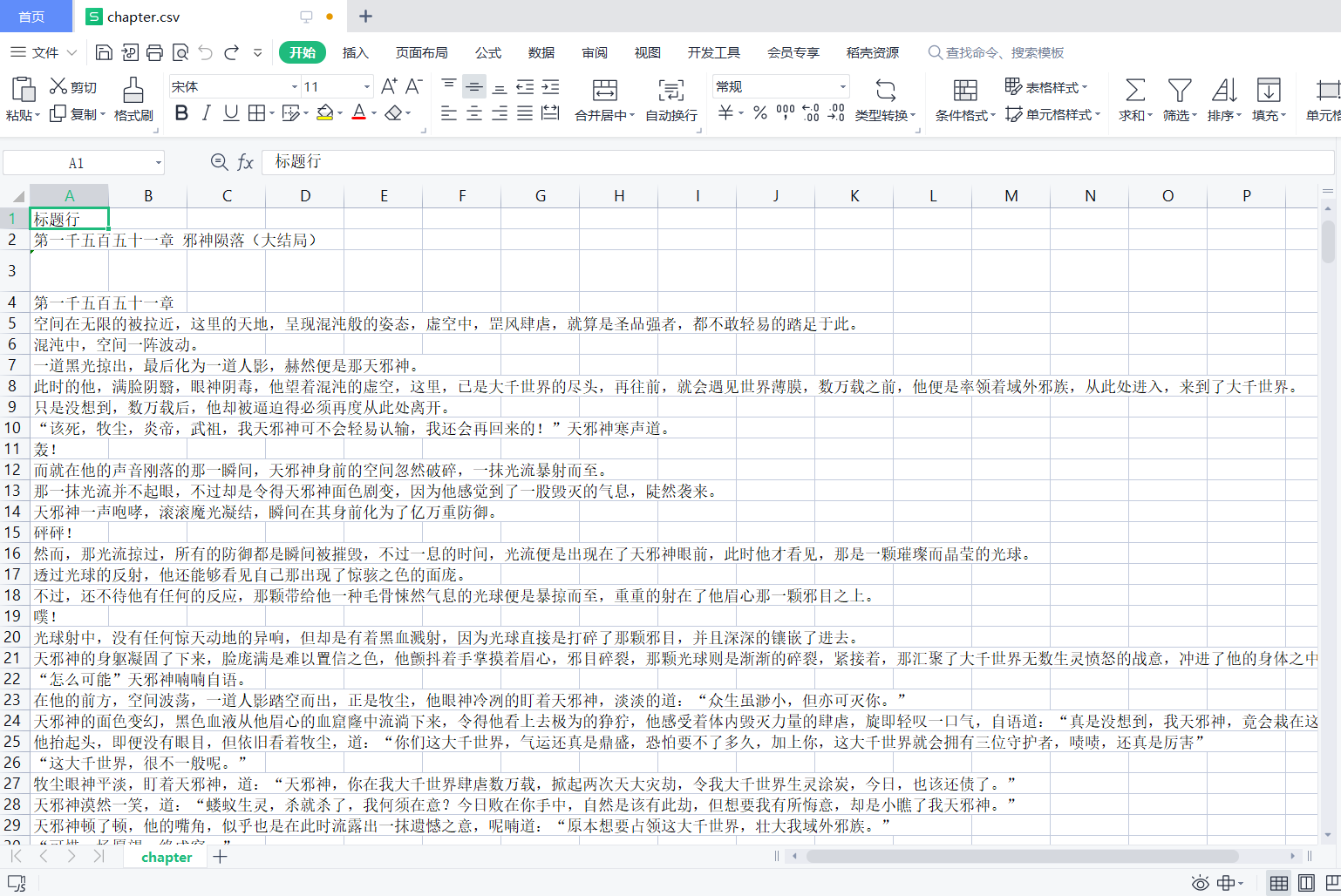
writer.writerow(['标题行'])
for dd in dd_out:
chap=dd.a.string #循环读取列表每个元素,找到链接,`chap=dd.a.string`,dd.a.string表示dd这个节点的子节点a的NavigableString 类型子节点,即a标签中的文字部分,即图中的`第一千五百五十一章...`,即章节目录
writer.writerow([chap])
writer.writerow('\n')
chap_url=url+dd.a['href'] #取dd节点下的a节点的href属性,加上网站前缀,组成每个章节的详细路径
chap_resp=requests.get(chap_url)
chap_resp_text_decode=chap_resp.text.encode(chap_resp.encoding).decode(chap_resp.apparent_encoding) #同样的,解码下
chap_soup=BeautifulSoup(chap_resp_text_decode,"html.parser")
div=chap_soup.find_all('div',id='content') #div是列表,即使只有一个元素
#print(type(div[0].br.next_sibling.next_sibling))
#print(div[0].find_all())
#print(div[0].get_text()) #div[0]即div节点,get_text()也能取到所有文本内容,包括子孙节点的文本内容
for text in div[0].stripped_strings: #stripped_strings可以循环获取tag节点中的字符串,并去除换行,空格等
#print(repr(text))
writer.writerow([text])
time.sleep(3) #有的网站容易崩,或者请求太频繁,延时个几秒可能好一点,或者使用请求头,代理等避开网站反爬机制
-
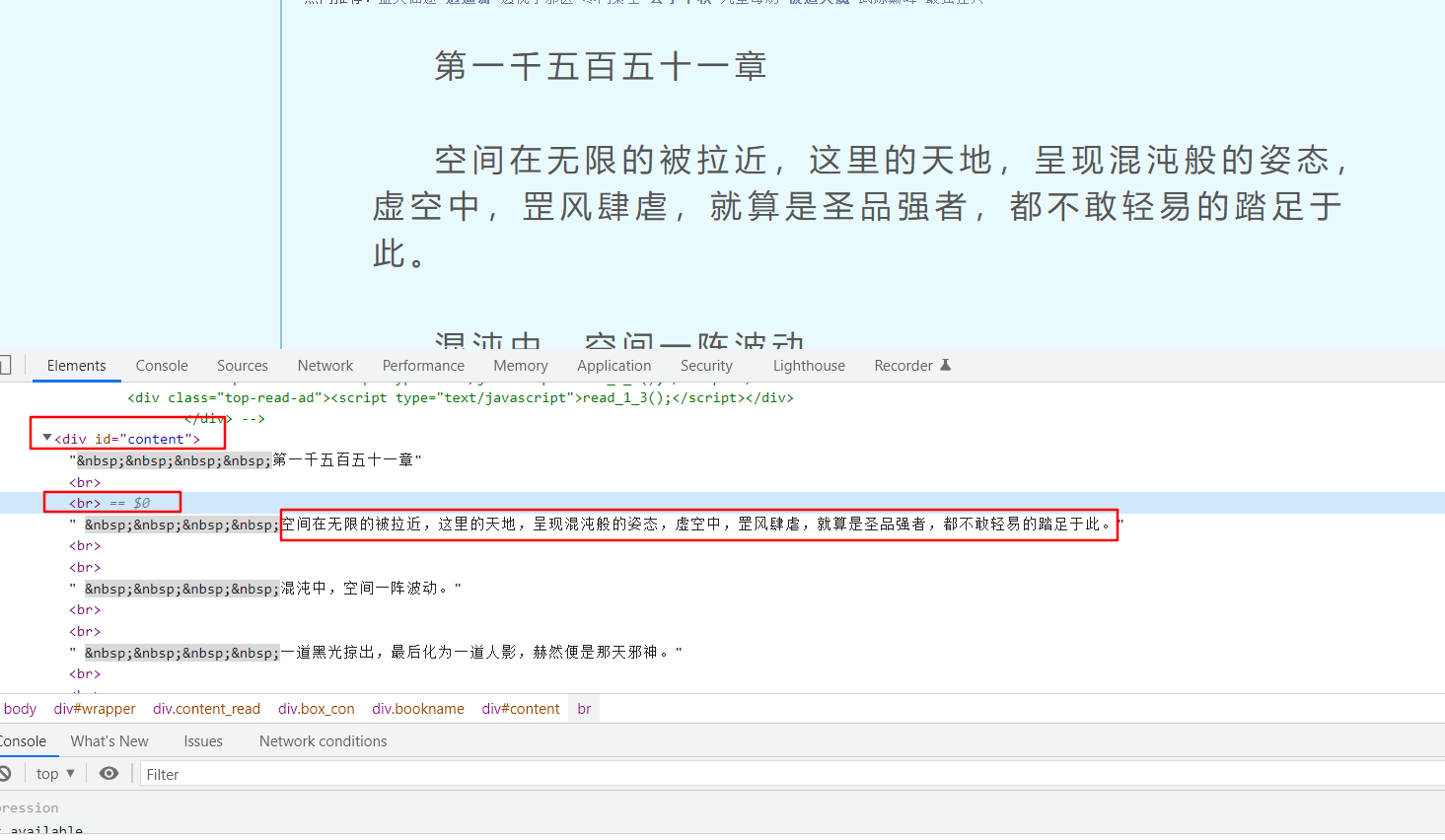
单独一个章节的正文内容,在div标签,id=content的节点下面,需要注意这个节点其实只有子节点,没有子孙节点,br是换行标签
![]()
-
成品
![]()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号