

搭建es集群,用一台机器不同端口来实现
1.下载elasticsearch-7.6.1-linux-x86_64.tar.gz
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.6.1-linux-x86_64.tar.gz
2. 解压 tar -zxvf elasticsearch-7.6.1-linux-x86_64.tar.gz
3. 将解压后的es拷贝出三份
cp -r elasticsearch-7.6.1/ elasticsearch-7.6.1_c1 cp -r elasticsearch-7.6.1/ elasticsearch-7.6.1_c2 cp -r elasticsearch-7.6.1/ elasticsearch-7.6.1_c3
4.编辑配置文件
先进入elasticsearch-7.6.1_c1的config目录,开始编辑elasticsearch.yml
vim elasticsearch.yml
cluster.name: my-es
node.name: node-1
network.host: 192.168.220.101
#默认是9200,如果搭建的集群用的是多台不同的服务器,则不用修改
http.port: 9201
#默认是9300,如果搭建的集群用的是多台不同的服务器,则不用修改
transport.tcp.port: 9301
#es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点,也就是说把所有的节点都写上
discovery.seed_hosts: ["192.168.220.101:9301", "192.168.220.101:9302","192.168.220.101:9303"]
#当你在搭建集群的时候,选出合格的节点集群,有些人说的太官方了, #其实就是,让你选择比较好的几个节点,在你节点启动时,在这些节点中选一个做领导者, #如果你不设置呢,elasticsearch就会自己选举,这里我们把三个节点都写上
cluster.initial_master_nodes: ["node-1", "node-2","node-3"]
#简单点说在集群启动后,至少复活多少个节点以上,那么这个服务才可以被使用,否则不可以被使用,
gateway.recover_after_nodes: 2
#是不是有资格竞选主节点
node.master: true
#是否存储数据
node.data: true
#跨域访问设置
http.cors.enabled: true
http.cors.allow-origin: "*"
编辑elasticsearch-7.6.1_c2配置文件elasticsearch.yml
cluster.name: my-es
node.name: node-2
network.host: 192.168.220.101
http.port: 9202
transport.tcp.port: 9302
discovery.seed_hosts: ["192.168.220.101:9301", "192.168.220.101:9302","192.168.220.101:9303"]
cluster.initial_master_nodes: ["node-1", "node-2","node-3"]
gateway.recover_after_nodes: 2
node.master: true
node.data: true
http.cors.enabled: true
http.cors.allow-origin: "*"
编辑elasticsearch-7.6.1_c3配置文件elasticsearch.yml
cluster.name: my-es
node.name: node-3
network.host: 192.168.220.101
http.port: 9203
transport.tcp.port: 9303
discovery.seed_hosts: ["192.168.220.101:9301", "192.168.220.101:9302","192.168.220.101:9303"]
cluster.initial_master_nodes: ["node-1", "node-2","node-3"]
gateway.recover_after_nodes: 2
node.master: true
node.data: true
http.cors.enabled: true
http.cors.allow-origin: "*"
在上面的配置文件中,data和logs用的都是默认配置路径,path.data: /path/to/data和path.logs: /path/to/logs,指的是es目录下定义好的data和log目录。
如果我们自己创建了数据和日志目录,则可以修改这两处配置。
5.创建elasticsearch用户
elasticsearch不允许使用root账号启动,需要创建一个账户,比如我新建一个账户zxp,然后通过命令,将elasticsearch目录授权给zxp和他所在组
chown -R zxp:zxp elasticsearch-7.6.1_c1
chown -R zxp:zxp elasticsearch-7.6.1_c2
chown -R zxp:zxp elasticsearch-7.6.1_c3
6.启动
首先切换到新建的es账号下:su zxp
然后到es的bin目录下,执行启动命令[zxp@localhost local]$ ./elasticsearch-7.6.1_c1/bin/elasticsearch,可能会报以下错误:
问题一:ERROR: bootstrap checks failed max file descriptors [4096] for elasticsearch process likely too low, increase to at least [65536] max number of threads [1024] for user [lishang] likely too low, increase to at least [2048] 解决:切换到root用户,编辑limits.conf 添加如下内容 vi /etc/security/limits.conf 添加如下内容:
* soft nproc 65536
* hard nproc 65536
* soft nofile 65536
* hard nofile 65536
问题二:max number of threads [1024] for user [lish] likely too low, increase to at least [2048] 解决:切换到root用户,进入limits.d目录下修改配置文件。 vi /etc/security/limits.d/90-nproc.conf 修改如下内容:
* soft nproc 1024
#修改为
* soft nproc 2048
问题三:max virtual memory areas vm.max_map_count [65530] likely too low, increase to at least [262144] 解决:切换到root用户修改配置sysctl.conf vi /etc/sysctl.conf 添加下面配置:
vm.max_map_count=655360
最后并执行命令:
sysctl -p
然后,重新启动elasticsearch,即可启动成功:[zxp@localhost local]$ ./elasticsearch-7.6.1_c1/bin/elasticsearch
7.通过访问地址查看集群状态
http://192.168.220.101:9201/_cat/health?v

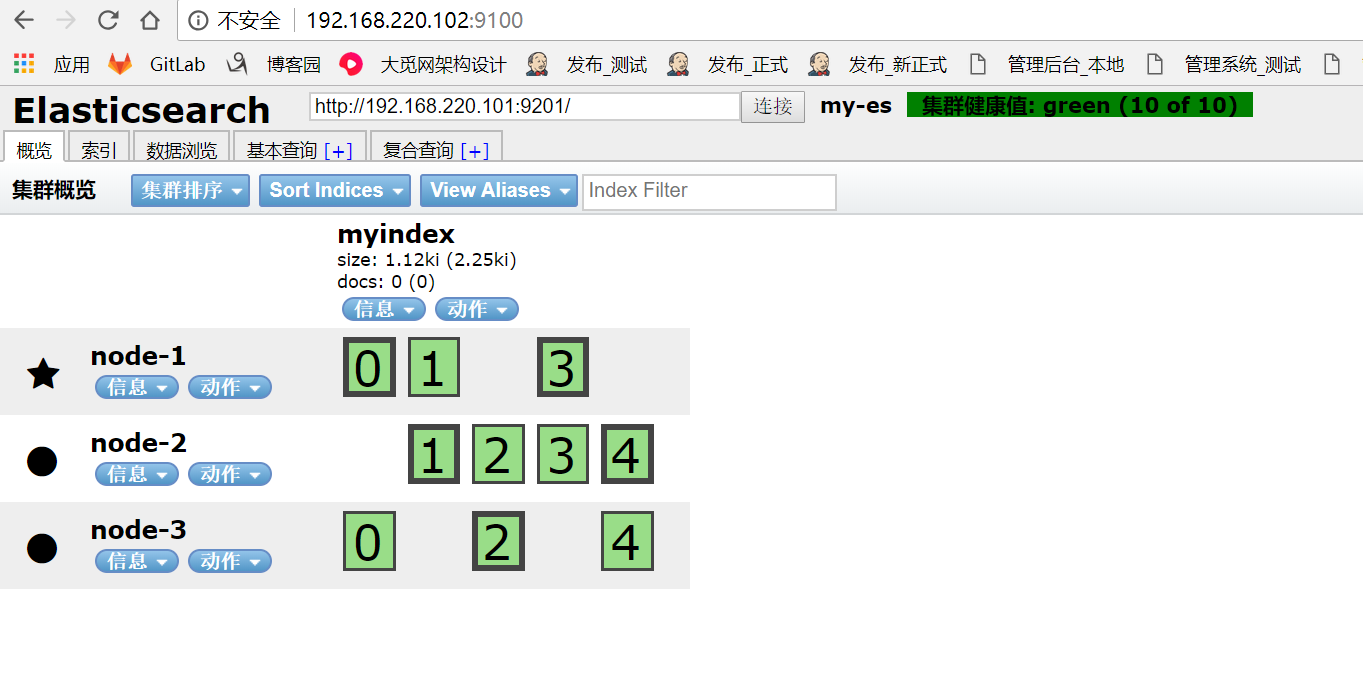
8.通过es-Head查看集群信息 http://192.168.220.102:9100/
部署elasticsearch-analysis-ik分词器
下载ik分词器,下载网址https://github.com/medcl/elasticsearch-analysis-ik/releases
1.找到对应es版本的ik,然后下载
wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.6.1/elasticsearch-analysis-ik-7.6.1.zip
2. 在es的plugins目录下先建个目录ik
mkdir elasticsearch-7.6.1_c1/plugins/ik
3. 解压下载的ik压缩包到上面新建的ik目录中
unzip elasticsearch-analysis-ik-7.6.1.zip -d elasticsearch-7.6.1_c1/plugins/ik
4.自定义分词词库
首先,进入plugins-->ik-->config目录,新建一个xxx.dic文件,比如my.dic的文件,并在这一个文件中写入词汇
修改config目录下IKAnalyzer.cfg.xml文件的内容。如下图所示,在<entry key="ext_dic>标签中写入自定义词库的路径,如<entry key="ext_dict">my.dic</entry>
自定义分词示例如下:
[root@localhost config]# pwd /usr/local/elasticsearch-7.6.1_c1/plugins/ik/config [root@localhost config]# cat my.dic 河南邓州 [root@localhost config]# cat IKAnalyzer.cfg.xml <?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>IK Analyzer 扩展配置</comment> <!--用户可以在这里配置自己的扩展字典 --> <entry key="ext_dict">my.dic</entry> <!--用户可以在这里配置自己的扩展停止词字典--> <entry key="ext_stopwords"></entry> <!--用户可以在这里配置远程扩展字典 --> <!-- <entry key="remote_ext_dict">words_location</entry> --> <!--用户可以在这里配置远程扩展停止词字典--> <!-- <entry key="remote_ext_stopwords">words_location</entry> --> </properties>
5.重启es
6.测试ik分词器及自定义词库
ik分词策略支持ik_max_word 和 ik_smart ,调用analyze接口测试, 如:
GET _analyze
{
"analyzer":"ik_max_word",
"text":"中国河南邓州解放军"
}
返回结果如下:
{
"tokens" : [
{
"token" : "中国",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "河南邓州",
"start_offset" : 2,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "河南",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "邓州",
"start_offset" : 4,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "解放军",
"start_offset" : 6,
"end_offset" : 9,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "解放",
"start_offset" : 6,
"end_offset" : 8,
"type" : "CN_WORD",
"position" : 5
},
{
"token" : "军",
"start_offset" : 8,
"end_offset" : 9,
"type" : "CN_CHAR",
"position" : 6
}
]
}
docker部署es集群,参考文章 https://blog.csdn.net/weixin_36550048/article/details/105895031
客户端要写入一个文档 PUT /my_index/_doc/1,其流程如下:
-
客户端将写请求发送到集群中的任何一个节点(该节点此时充当协调节点)。
-
协调节点根据文档ID计算出文档应该存储在哪个分片(例如
shard0)。 -
协调节点查看集群状态(由Master节点维护),找到
shard0的主分片位于哪个数据节点上,然后将请求转发给该数据节点。 -
该数据节点上的主分片负责执行写入操作。
-
写入成功后,主分片并行地将写入请求转发给其所有的副本分片。
-
主分片等待所有副本分片都报告成功(或达到最小成功副本数要求),然后向协调节点报告成功。
-
协调节点最终将成功结果返回给客户端。
重要原则:所有写操作都必须经过主分片,由主分片同步到副本。
读取(如 GET /my_index/_doc/1 或搜索请求)的流程
-
客户端将读请求发送到协调节点。
-
对于通过ID的查询 (GET by ID):
-
协调节点计算文档分片,然后从该分片的所有副本(包括主分片和副本分片)中选择一个(通常采用轮询负载均衡方式),将请求转发给它。
-
-
对于搜索请求 (Search):
-
协调节点将查询广播到所有相关分片(主分片或副本分片均可)所在的数据节点。
-
-
每个数据节点在本地执行查询,将结果返回给协调节点。
-
协调节点合并、排序所有分片的结果,然后将最终结果返回给客户端。
重要原则:读请求可以被主分片或副本分片处理,这提供了负载均衡和高可用性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号