


DeepSeek FlashMLA:用于Hopper GPU的高效MLA解码内核
一、开源承诺
上周,DeepSeek预告了要连续5天,开源一系列核心技术
上午 9 点,刚一上班(同时是硅谷即将下班的时候),DeepSeek 兑现了自己的诺言,开源了一款用于 Hopper GPU 的高效型 MLA 解码核:FlashMLA。发布五小时GitHub Star数冲上4600。
二、什么是FlashMLA
“FlashMLA is an efficient MLA decoding kernel for Hopper GPUs, optimized for variable-length sequences serving.”
FlashMLA指的是DeepSeek针对Hopper GPU的高效MLA解码内核,针对可变长度序列进行了优化,现已投入生产。目前已发布的内容包括:采用BF16,以及块大小为64的分页kvcache(键值缓存)。
几个参数:

经实测,FlashMLA在H800 SXM5平台上(CUDA 12.6),在内存受限配置下可达最高3000GB/s,在计算受限配置下可达峰值580 TFLOPS。简单点说,FlashMLA 是一个能让 LLM 模型在 H800 上跑得更快、更高效的优化方案,尤其适用于高性能 AI 任务。
三、FlashMLA核心技术
DeepSeek的成本涉及两项关键的技术:一个是MoE,一个就是MLA(多头潜注意力)。
其中,MLA的开发耗时数月,可将每个查询KV缓存量减少93.3%,显著减少了推理过程中的内存占用(在训练过程也是如此)。
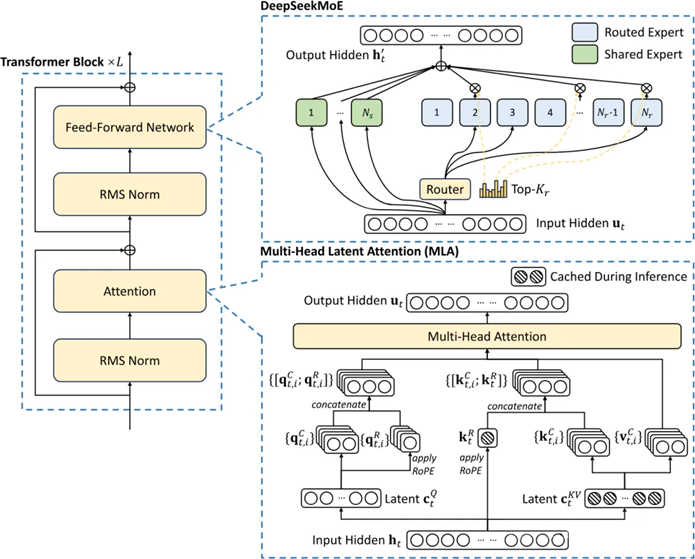
MLA架构需要一些巧妙的设计,因此实现的复杂性大大增加。而DeepSeek成功地将这些技术整合在一起,表明他们在高效语言模型训练方面走在了前沿
KV缓存是Transforme模型中的一种内存机制,用于存储表示对话上下文的数据,从而减少不必要的计算开销。
随着对话上下文的增长,KV缓存会不断扩大,从而造成显著的内存限制。
通过大幅减少每次查询所需的KV缓存量,可以相应减少每次查询所需的硬件资源,从而降低运营成本。
与标准注意力机制相比,MLA将每次查询所需的KV缓存减少了约93.3%。
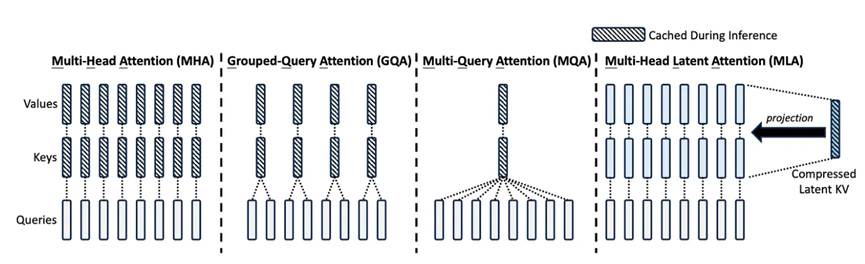
MLA这种全新多头潜注意力,可以将注意力机制的内存占用减少大约80%到90%,尤其有助于处理长上下文
此外,由于H20芯片比H100具有更高的内存带宽和容量,DeepSeek在推理工作负载方面获得了更多效率提升。
四、FlashMLA测试方式
首先,需要打开终端,输入下面代码安装setup.py文件:
这是一个基于Python的安装命令,用于编译和安装FlashMLA模块,确保其高效运行于特定硬件。

测试:
这段代码是一个测试脚本,用于验证FlashMLA的功能和性能,并与PyTorch的基准实现进行对比。

使用方法:
这是一段使用的示例代码。
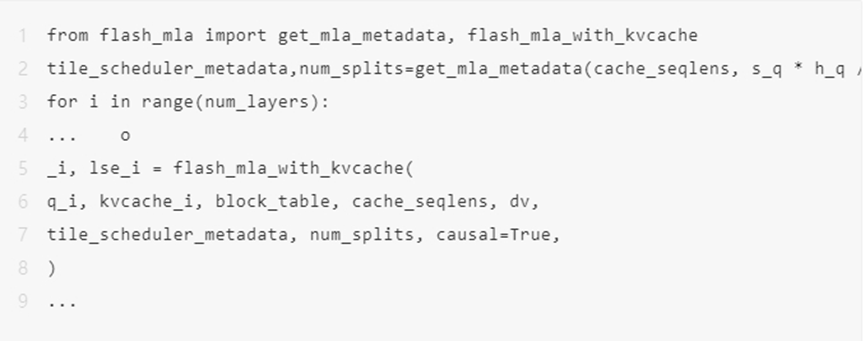
环境要求:
- Hopper GPU
- CUDA 12.3 及以上版本
- PyTorch 2.0 及以上版本
五、FlashMLA的意义
首先来说FlashMLA 是一个专门为 NVIDIA的 Hopper GPU(如 H800)优化的内核,旨在提升大型语言模型(LLMs)和其他AI应用在高性能硬件上的计算效率。
根据国外的论坛讨论,可以总结为以下几点的优化:
1.针对Hopper GPU优化的性能:FlashMLA 利用了 Hopper GPU 的高级 Tensor Cores 和Transformer Engines,实现了3000 GB/s的内存带宽和580 TFLOPS的计算性能,确保快速的数据访问和高效的计算能力。
2.支持变长序列:这个特性对于自然语言处理任务至关重要,因为它允许处理长度不一的输入数据,比如句子或文档,非常适合实际应用中的聊天机器人、翻译系统等。
3.高效的内存管理:通过使用分页的KV缓存机制,FlashMLA 提高了内存效率并减少了延迟,特别适合大规模模型,解决了内存瓶颈问题。
4. BF16精度支持:支持 BF16 精度格式,这种格式在保持足够准确度的同时,减少了内存使用并加快了计算速度,特别适合资源受限的硬件。
5.支持更大规模的AI模型:通过优化数据传输,FlashMLA 可以有效地进行超出GPU DRAM容量的大规模语言模型的推理,极大地提高了运行速度。
6.开源可用性:作为开源项目发布在GitHub上,促进了全球开发者和研究人员的创新和技术整合。
7.生产就绪技术:FlashMLA 已经被用于实际生产中,表明它是一个成熟且经过测试的解决方案。
8.在AI开发中的竞争优势:基于DeepSeek的成功开源项目,FlashMLA 成为了高效AI推理领域的领导者之一,能够与市场上其他先进的内核竞争。
简单来说,FlashMLA 是一种专门设计来让 AI计算更快更有效的工具,特别适合用在最新的NVIDIA Hopper GPU 上。它有几个很厉害的功能:
它能让电脑处理信息的速度超级快,不管是读取数据还是做复杂的计算都不在话下。
能够轻松应对不同长度的文字内容,像处理长短不一的文章或者对话都没问题,非常适合用来做聊天机器人或者翻译软件。
使用了一种聪明的方法来节省内存空间,这样即使是很庞大的AI模型也能流畅运行。
支持一种叫做 BF16 的精简数据格式,既能保证准确性又能提高速度,特别适合那些对硬件要求高的情况。
还能帮助运行比以前大得多的AI模型,而不需要升级昂贵的硬件设备。
更重要的是,它是开源的,任何人都可以免费使用和修改,这对推动AI技术的发展非常有帮助。
本文来自博客园,作者:方倍工作室,转载请注明原文链接:https://www.cnblogs.com/txw1958/p/18734283/DeepSeek-FlashMLA

 浙公网安备 33010602011771号
浙公网安备 33010602011771号