
原创:协同过滤之ALS
推荐系统的算法,在上个世纪90年代成型,最早应用于UserCF,基于用户的协同过滤算法,标志着推荐系统的形成。首先,要明白以下几个理论:①长尾理论②评判推荐系统的指标。之所以需要推荐系统,是要挖掘冷门物品,增加利润,这是根本目的。一般的,评判一个推荐系统的好坏,需要以下几个指标:
搜索推荐,主要有以下几种形式:一、根据人口统计学推荐:此推荐方式需要建立用户模型,并且需要获取用户的具体信息,然后根据矩阵运算,计算相似度,此方式最大缺陷是获取用户的隐私,应用不多;
二、基于内容的推荐:根据产品的属性,推荐出相似的产品。缺点是需要建立item model,比较费时。
三、基于协同过滤,是目前搜索推荐中应用最广泛的,不需要建立item model,省事,效果比较好。协同过滤的本质,可以概括为"物以类聚,人以群分",分别指基于物品的协同过滤和基于user的协同过滤。还有基于机器学习的协同过滤,总共这三种形式。第一种的优点是没有冷启动问题,基于用户历史行为的推荐,有冷启动问题。
亚马逊是搜索推荐的鼻祖,把搜索推荐运用到了极致。主要有以下形式:一,基于内容的推荐,主要有:①每日新产品的推荐;②热门物品;二,基于协同过滤的推荐:①计算用户相似度,推荐其他用户群喜欢的产品(去重)②根据FP-Growth model进行相关度挖掘,捆绑销售③基于ALS算法,推荐产品。关于ALS算法,有一篇经典的博文,是spark MLlib的源码贡献者之一写的,很深入。地址:http://www.csdn.net/article/2015-05-07/2824641 认真研究几遍,会有很多收获。本文主要讲ALS应用,所以会比较简单。在讲ALS应用前,有必要详细论述以下UserCF和Item CF。先讲长尾分布,因为推荐系统的目的,就是挖掘长尾物品,同时消除热门物品的影响(需要加入惩罚因子)。以下内容,全部来自《推荐系统实战》一书。

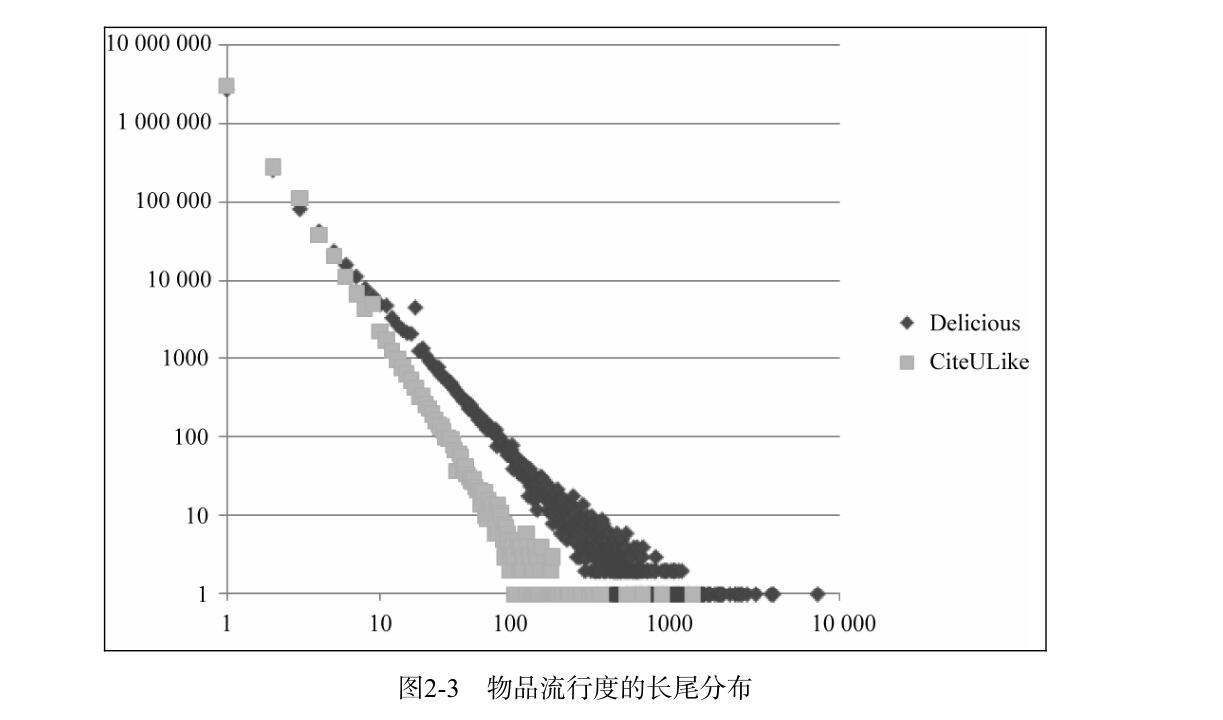
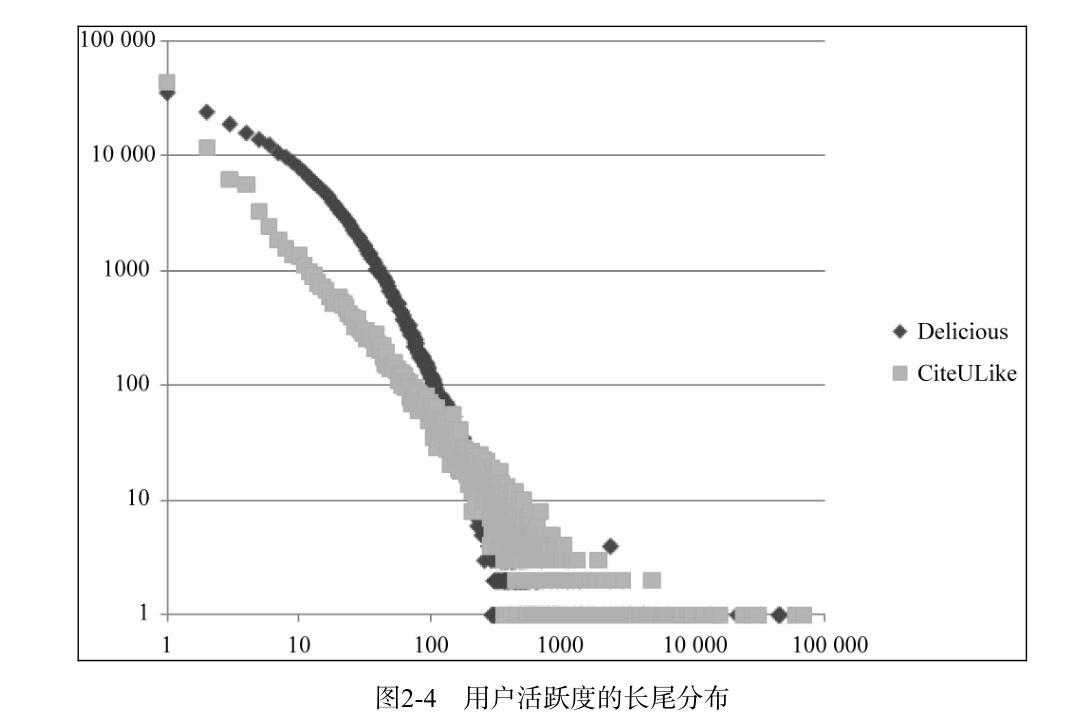
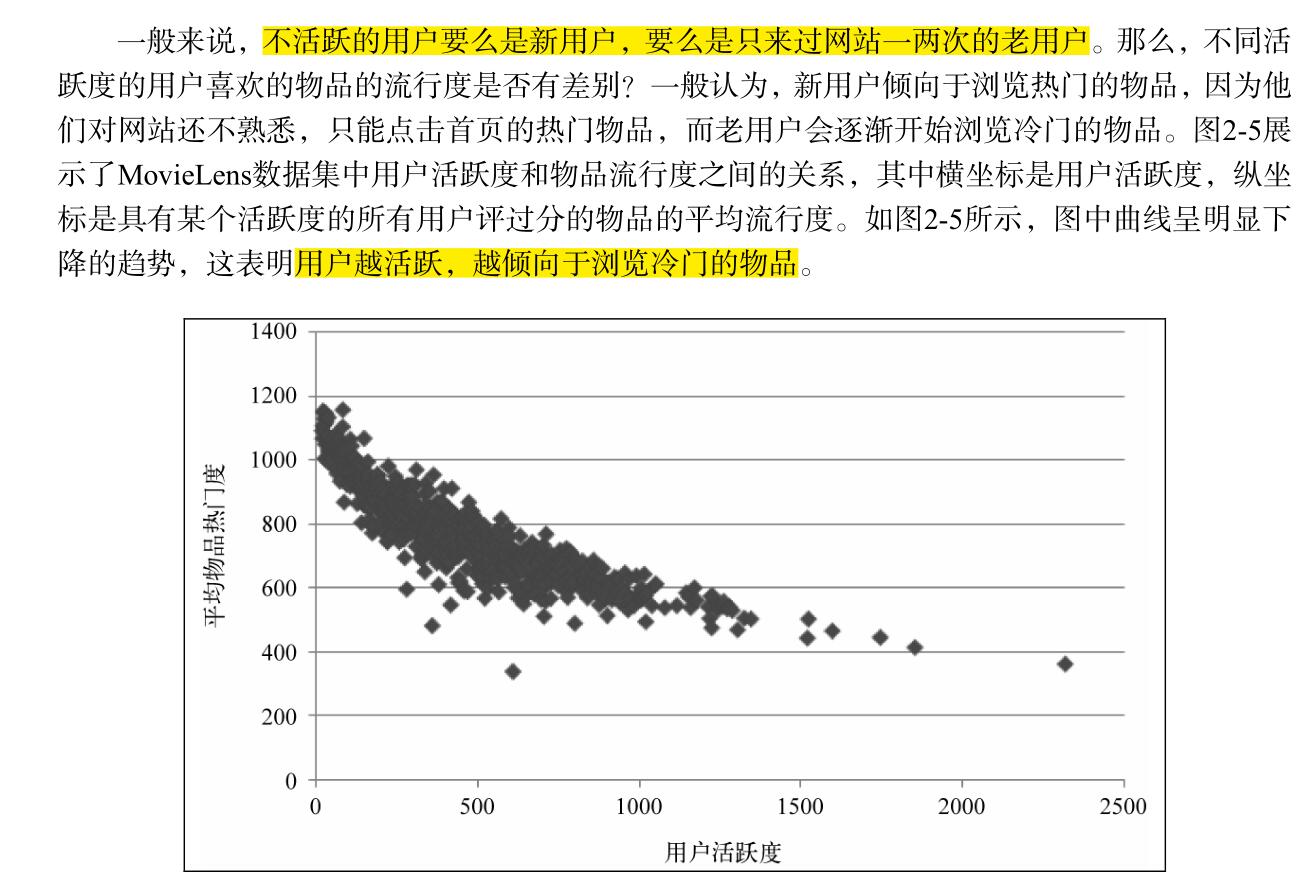

基于用户的协同过滤算法,需要找出和自己兴趣形似的群体,然后推荐别人喜欢的物品给自己,可以用准确率,召回率,覆盖率和流行度来衡量。影响user CF的一个重要的因素是K,即找出多少个与自己兴趣相似的用户。K值越大,准确率和召回率越高,但是,覆盖率不一定高。因为K值越大,推荐的物品,越倾向于热门物品,效果反而不好,不能很好地挖掘长尾物品,所以,在用余弦相似度公式时,需要引入惩罚因子,来消除热门物品的影响。ItemCF的原理,和spark中的FP-Growth树的相关度挖掘,是一致的,即根据用户的历史兴趣,把两个物品关联起来(物以类聚).



所以说,在购物网站或者电子商务领域,当用户刚刚登陆系统时,可以利用ALS矩阵分解,对用户进行推荐(排除冷启动的情况下),比如,猜你喜欢:xxxx。当用户购买之后,可以在列表下方,使用ItemCF对用户推荐,并且说明推荐理由:比如,我买了一本《推荐系统实战》之后,可以在下方,帮我推荐《web数据挖掘》这本书,说明:购买这本书的用户还购买了《web数据挖掘》一书,或者说浏览这本书的用户,还购买了xxx……。下面,举一个例子,来使用ALS:
package com.txq.spark.test
import java.io.File
import org.apache.log4j.{Level, Logger}
import org.apache.spark.mllib.recommendation.{ALS, MatrixFactorizationModel, Rating}
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
import org.apache.spark.{SparkConf, SparkContext}
import scala.io.Source
/**
* ALS矩阵分解搜索推荐:
* 三个数据源:①rating.dat ----->userid itemid rate
* ②items.dat----itemid->item(Map)
* ③users.dat---预测用户列表
* 思路:1.实现数据的partitions,数据格式为(key,value)形式,key为时间戳,对10求余数,根据余数分区,提高计算的
* 并行度;
* 2.取上述数据的values部分,训练出一个最优的model出来,使用"三折交叉验证",评判标准为RMSE;
* 3.根据最优model对特定用户推荐产品,注意去除该用户已经评分过的产品.
*/
object MovieLensALS {
System.setProperty("hadoop.home.dir", "D://hadoop-2.6.2")
def main(args: Array[String]): Unit = {
//屏蔽不必要的日志显示在终端上
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)
if(args.length != 2){
println("Usage:/path/to/spark/bin/spark-submit --driver-memory 2g --class " +
"week6.MovieLensALS" + "target/scala-*/movielens-als-ssembly-*.jar movieLensHomeDir personalRatingsFile")
sys.exit(1)
}
//设置运行环境
val conf = new SparkConf().setAppName("MovieLensALS")
val sc = new SparkContext(conf)
//装载用户评分,该评分由评分器生成
val myRatings = loadRatings(args(1))
val myRatingsRDD = sc.parallelize(myRatings,1)
//样本数据目录
val movieLensHomeDir = args(0)
//装载样本评分数据,其中最后一列Timestamp取除10的余数作为key,Rating为值,即(Int,Rating)
val ratings = sc.textFile(new File(movieLensHomeDir,"ratings.dat").toString).map{ line =>
val fields = line.split("::")
(fields(3).toLong % 10,Rating(fields(0).toInt,fields(1).toInt,fields(2).toDouble))
}
//装载电影目录对照表(电影ID->电影标题)
val movies = sc.textFile(new File(movieLensHomeDir,"movies.dat").toString).map{line =>
val fields = line.split("::")
(fields(0).toInt,fields(1))
}
val numRatings = ratings.count()
val numUsers = ratings.map(_._2.user).distinct().count()
val numMovies = ratings.map(_._2.product).distinct().count()
println("Got " + numRatings + " ratings from " + numUsers + " users on" + numMovies + " movies.")
//将样本评分表以key值切分成3个部分,分别用于训练(60%,并加入用户评分),校验(20%),测试(20%)
//该数据在计算过程中要多次应用到,所以cache到内存
val numPartitions = 4
val training = ratings.filter(_._1 < 6).values.union(myRatingsRDD).repartition(numPartitions).cache()
val test = ratings.filter(_._1 >= 8).values.repartition(numPartitions).cache()
val validation = ratings.filter(x => x._1>= 6 && x._1 < 8).values.repartition(numPartitions).cache()
val numTraining = training.count()
val numValidation = validation.count()
val numTest = test.count()
println("Training: "+ numTraining + ",validation: " + numValidation + ",test: " + numTest)
//训练不同参数下的模型,并在校验集中校验,获取最佳参数下的模型
val ranks = List(8,9)
val lambdas = List(0.1,10.0)
val numIters = List(10,20)
var bestModel:Option[MatrixFactorizationModel] = None
var bestValidationRmse = Double.MaxValue
var bestRank = 0
var bestLambda = -1.0
var bestNumIter = -1
for(rank <- ranks;lambda <- lambdas;numIter <- numIters){
val model = ALS.train(training,rank,numIter,lambda)
val validationRmse = computeRmse(model,validation)
println("RMSE(validation) = " + validationRmse + " for the model trained with rank = " + rank + " with lambda = " + lambda + " with numIterations = " + numIter)
if(validationRmse < bestValidationRmse){
bestModel = Some(model)
bestValidationRmse = validationRmse
bestRank = rank
bestLambda = lambda
bestNumIter = numIter
}
}
//用最佳模型预测测试集的评分,并计算和实际评分之间的均方根误差
val testRmse = computeRmse(bestModel.get,test)
println("The best model was trained with rank = " + bestRank + " with lambda = " + bestLambda + " with best NumIterations = " + bestNumIter)
//用基准偏差衡量最佳模型在测试数据上的预测精度(产生的RMSE越接近基准偏差,精度越高)
val meanRating = training.union(validation).map(_.rating).mean()
val baselineRmse = math.sqrt(test.map(x => math.pow(meanRating - x.rating,2)).mean())
val improvement =(testRmse-baselineRmse) / baselineRmse * 100
println("The best model improves the base line by " + "%1.2f".format(improvement + "%."))
//推荐前十部最感兴趣的电影,注意要剔除用户已经评分的电影
val myRatedMovieIds = myRatings.map(_.product).toSet
val userId:Int = myRatings.map(_.user).distinct(0)//被推荐用户的id
val candidates = movies.map(_._1).filter(!myRatedMovieIds.contains(_))
val recommendations = bestModel.get.predict(candidates.map((userId,_))).sortBy(-_.rating).take(10)//按降序排列
var i = 1
val products = movies.collect().toMap
println("Movies recommended for you: ")
recommendations.foreach{ r =>
println("%2d".format(i) + ": " + products.get(r.product))
i += 1
}
sc.stop()
}
/**装载用户评分文件 **/
def loadRatings(path:String):Seq[Rating] = {
val lines = Source.fromFile(path).getLines()
val ratings = lines.map{line =>
val fields = line.split("::")
Rating(fields(0).toInt,fields(1).toInt,fields(2).toDouble)
}.filter(_.rating > 0.0)
if(ratings.isEmpty){
sys.error("No ratings provided.")
} else {
ratings.toSeq
}
}
/**
* 计算RMSE,应该尽量减少shuffle操作,提高效率
* @param model ALS模型
* @param data validation数据
* @return
*/
def computeRmse(model:MatrixFactorizationModel,data:RDD[Rating]):Double = {
val precisionAndReal = data.map{ x =>
val precision = model.predict(x.user,x.product)
(x.rating,precision)
}
math.sqrt(precisionAndReal.map(x => math.pow(x._1 - x._2,2)).mean())
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号