

20204323 太晓梅 《Python程序设计》 实验4报告
课程:《Python程序设计》
班级: 2043
姓名: 太晓梅
学号:20204323
实验教师:王志强
实验日期:2022年5月4日
必修/选修: 公选课
1.实验要求
Python综合应用:爬虫、数据处理、可视化、机器学习、神经网络、游戏、网络安全等。
课代表和各小组负责人收集作业(源代码、视频、综合实践报告)
注:在华为ECS服务器(OpenOuler系统)和物理机(Windows/Linux系统)上使用VIM、PDB、IDLE、Pycharm等工具编程实现。
批阅:注意本次实验不算做实验总分,前三个实验每个实验10分,累计30分。本次实践算入综合实践,打分为25分。
评分标准:
(1)程序能运行,功能丰富。(需求提交源代码,并建议录制程序运行的视频)10分
(2)综合实践报告,要体现实验分析、设计、实现过程、结果等信息,格式规范,逻辑清晰,结构合理。10分。
(3)在实践报告中,需要对全课进行总结,并写课程感想体会、意见和建议等。5分
(4)如果没有使用华为云服务(ECS或者MindSpore均可),本次实践扣10分。
2.思路设计
利用所学的爬虫爬取当下主流书籍交易网站“当当网”(http://category.dangdang.com/pg1-cp01.03.00.00.00.00.html)的书籍信息进行分析。并解析爬取的数据,通过可视化展现对爬取的信息进行分析。
本次采集当当网图书——“小说”的图书信息,爬取字段包括:书名、作者、价格、出版社、评论数量、时间、书籍信息简介。
首先实现单个网页数据的数据请求,然后将请求下来的数据进行解析提取所需字段的对应信息,接着通过循环请求解析多个网页的数据字段信息,为了方便后续分析研究将数据进行清洗(转换数据类型,便于后期作图法分析,部分字段在解析提取后仍存在不必要的“脏数据”需要进行剔除),清洗完成后的数据存储至csv文件中。根据爬取的书籍信息绘制“作者热销榜Top20”柱状图、书籍价格与评论关系的折线图、各大出版社所占比列扇形图、书籍简介词云图。
(1)当当网网络页面分析


(2)节点(标签)查找方法与遍历方法
通过BeautifulSoup将页面初始化解析,然后find_all方法查找class='con shoplist'的div标签,对查找出来的结果通过for循环进行遍历,将遍历结果再次通过find_all方法分别查找对应标签信息,标签节点树状图如下所示

3.实验步骤及代码
(详细代码讲解参见提交的视频:代码讲解+运行视频)
(1)1.爬取数据
点击查看代码
import requests
import pandas as pd
from bs4 import BeautifulSoup
pd.set_option('display.max_columns', None) # 显示所有列
pd.set_option('display.max_rows', None) # 显示所有行
pd.set_option('max_colwidth', 100) # 设置value的显示长度为100,默认为50
def get_url(num): # 实现翻页,获取每一页信息网址
urls = []
for i in range(1, num + 1):
url = "http://category.dangdang.com/pg{}-cp01.03.00.00.00.00.html".format(i)
urls.append(url)
return urls
def get_html(url): # 请求网页,返回网页数据
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'}
response = requests.get(url=url, headers=headers)
html = response.text ##获得网页的源代码
soup = BeautifulSoup(html, "html.parser") ##将网页转化成BeautifSoup对象
return soup
def get_data(html):
name_data = []
author_data = []
price_data = []
comments_data = []
time_data = []
place_data = []
info_data = []
aa = html.find_all('div', class_='con shoplist') ##查找class='con shoplist'的div标签
for i in aa[0].find_all('li'):
try:
name = i.a['title']
author = i.find_all('p', class_='search_book_author')[0].span.a.string
price = i.find_all('p', class_='price')[0].span.string
comments = i.find_all('p', class_='search_star_line')[0].a.string
time = i.find_all('p', class_='search_book_author')[0].find_all('span')[1].string
place = i.find_all('p', class_='search_book_author')[0].find_all('span')[2].a['title']
info = i.find_all('p', class_='detail')[0].string
name_data.append(name)
author_data.append(author)
price_data.append(price)
comments_data.append(comments)
time_data.append(time)
place_data.append(place)
info_data.append(info)
except:
pass
df = pd.DataFrame(
{"书名": name_data, "作者": author_data, "价格": price_data, "出版社": place_data, "评论": comments_data, "时间": time_data,
"简介": info_data})
return df
def write_info(info_data):
df = pd.concat(info_data, axis=0)
df = df.reset_index(drop=True)
df.to_csv('爬取数据集test.csv', encoding='utf-8', index=False)
print("共计获取以及写入{}条数据".format(len(df)))
if __name__ == '__main__':
info_data = []
num = eval(input("请输入爬取页数"))
for i in get_url(num):
html = get_html(i)
info_data.append(get_data(html))
write_info(info_data)

(2)绘制词云图
点击查看代码
import re # 正则表达式库
import pandas as pd
import numpy as np
import collections # 词频统计库
import jieba # 结巴分词
import wordcloud
from PIL import Image # 图像处理库
import matplotlib.pyplot as plt # 绘制图像的模块
df = pd.read_csv('清洗完毕数据集.csv', encoding='utf-8-sig')
name_data = df['简介'].tolist()
name_data = [str(i) for i in name_data]
string_data = "".join(name_data)
pattern = re.compile('《|》|:|、|\t|\n|\.|-|:|;|\)|\(|\?|(|)|\|"|\u3000|,|。|?|“|”|是|和|在|与|他|了|的|') # 定义正则表达式匹配模式
string_data = re.sub(pattern, '', string_data) # 将符合模式的字符去除
cut_list = jieba.cut(string_data, cut_all=False) # 精确模式分词
word_counts = collections.Counter(cut_list) # 对分词做词频统计
word_counts_top50 = word_counts.most_common(200) # 获取前50最高频的词
dict_data = dict(word_counts_top50) # 输出结果转换字典
mask = np.array(Image.open('./tree.jpg')) # 定义词频背景
wc = wordcloud.WordCloud(scale=5,
font_path='C:/Windows/Fonts/simhei.ttf', # 设置字体格式
mask=mask, # 设置背景图
background_color="white", width=1000, height=880
)
wc.generate_from_frequencies(dict_data) # 从字典生成词云
plt.figure(figsize=[9, 6], dpi=300)
plt.imshow(wc) # 显示词云
plt.axis('off') # 关闭坐标轴
plt.savefig(r'./word.jpg', dpi=500)
plt.show() # 显示图像

(3)绘制出版社比例扇形图
点击查看代码
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
df = pd.read_csv('清洗完毕数据集.csv', encoding='utf-8-sig')
key_data = []
value_data = []
groupby_obj = df.groupby(by='出版社')
for i in groupby_obj:
key_data.append(i[0])
value_data.append(len(i[1]))
dict_data = dict(zip(key_data, value_data))
dict_info = sorted(dict_data.items(), key=lambda item: item[1], reverse=True)
dict_info = dict_info[0:10]
x_data = [i[1] for i in dict_info]
y_data = [i[0][0:7] for i in dict_info]
fig = plt.figure(dpi=300, figsize=(18, 9))
plt.pie(x_data, labels=y_data, autopct='%1.2f%%') # 画饼图(数据,数据对应的标签,百分数保留两位小数点)
plt.title("热销榜出版社所占比例")
plt.legend(
fontsize=12,
title="出版社",
loc="center left",
bbox_to_anchor=(0.8, 0.4, 0.3, 1))
plt.show()

(4)热销榜作者Top20柱状图
点击查看代码
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv('清洗完毕数据集.csv', encoding='utf-8-sig')
key_data = []
value_data = []
groupby_obj = df.groupby(by='作者')
for i in groupby_obj:
key_data.append(i[0])
value_data.append(len(i[1]))
dict_data = dict(zip(key_data, value_data))
dict_info = sorted(dict_data.items(), key=lambda item: item[1], reverse=True)
dict_info = dict_info[0:20]
x_data = [i[0][0:7] for i in dict_info]
y_data = [i[1] for i in dict_info]
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
fig, ax1 = plt.subplots(figsize=(18, 8))
plt.title('热销榜作者top20', size=18) # 画布标题
ax1.set_xlabel('作者名称', size=18) # 定义x轴名称
ax1.set_ylabel('销售榜单书籍数量', size=20) # 定义y轴名称
plt.xticks(size=15, rotation=45)
plt.yticks(size=15)
plt.bar(x_data, y_data)
plt.show()
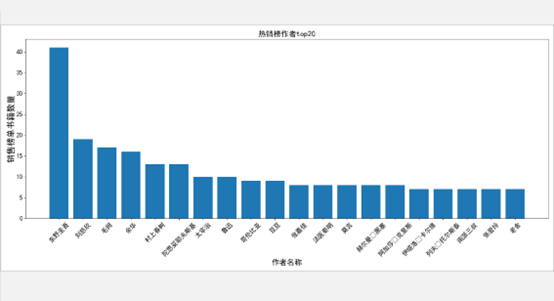
(5)书籍作者扇形图
点击查看代码
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False # 用来正常显示负号
df=pd.read_csv('清洗完毕数据集.csv',encoding='utf-8-sig')
key_data=[]
value_data=[]
groupby_obj=df.groupby(by='作者') #将df数据通过groupby()方法进行分组
for i in groupby_obj:
key_data.append(i[0])
value_data.append(len(i[1]))
dict_data=dict(zip(key_data,value_data))
dict_info=sorted(dict_data.items(), key=lambda item:item[1] ,reverse=True)
dict_info=dict_info[0:20]
x_data=[]
y_data=[]
for i in dict_info:
x_data.append(i[0][0:7])
for i in dict_info:
y_data.append(i[1])
fig = plt.figure(dpi=300,figsize=(18,9))
plt.pie(y_data,labels=x_data,autopct='%1.2f%%') #画饼图(数据,数据对应的标签,百分数保留两位小数点)
plt.title("热销书籍作者所占比例")
plt.legend(
fontsize=12,
title="出版社",
loc="center left",
bbox_to_anchor=(0.8, 0.4, 0.3, 1))
plt.show()

(6)出版时间分布图
点击查看代码
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False # 用来正常显示负号
df=pd.read_csv('清洗完毕数据集.csv',encoding='utf-8-sig')
time_list = [] #存放时间列表
for i in df['时间']: #循环df结构中的时间,并且对时间进行处理
time=i[1:5]+'年' #去掉月份以及日期,并且加上年份
time_list.append(time) #将时间年份添加到time_list列表中
time_dic={} #用字典统计列表中的元素
for i in time_list: #循环列表
if i in time_dic: #如果元素在存在中,则该元素的值加1,不存在的话
time_dic[i]+=1 #就将元素添加到字典中,并且将对应的值设置为1
else:
time_dic[i]=1
# 通过自定义函数对字典进行排序
dict_info=sorted(time_dic.items(), key=lambda item:item[1] ,reverse=True)
x_data=[] #存放年份
y_data=[] #存放年份对应的数据数量
for i in dict_info:
x_data.append(i[0])
for i in dict_info:
y_data.append(i[1])
x_data=x_data[:-15]
y_data=y_data[:-15]
fig = plt.figure(dpi=300,figsize=(18,9))
plt.pie(y_data,labels=x_data,autopct='%1.2f%%') #画饼图(数据,数据对应的标签,百分数保留两位小数点)
plt.title("热销书籍年份所占比例")
plt.legend(
fontsize=12,
title="年份",
loc="center left",
bbox_to_anchor=(0.8, 0.4, 0.3, 1))
plt.show()
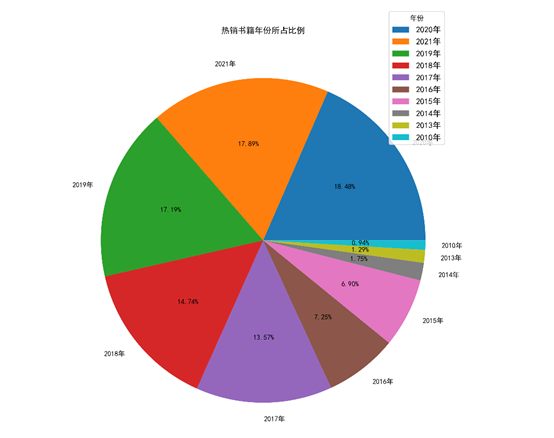
4.华为云运行
将代码通过winSCP上传至新建的文件test4,在putty上登录服务器进行运行。

5.实验感悟
本次实验利用爬虫爬取了“当当网的信息”,又学习了可视化相关知识进行可视化分析展示,难度较大,也花了大量时间,但完成后很有成就感。
本次实验中最让我感到头疼的部分是在华为云上运行代码,最开始运行时,出现错误Non-ASCII character ‘\xe7‘ in file,上网查阅后是由于编码问题,在查阅资料后按照提示,在源码的头部添加# coding=utf-8,该问题得到解决。
其次是关于可视化在华为云上运行的问题,由于时间有限,现在暂时未解决,但会在提交实验报告后继续解决该问题,在最后的代码运行视频中展示在华为云上实现完整的运行。
6.结课感悟
本学期的python课带给我较大的感受是理论和实践的差距较大。理论课学习的知识好像听懂了,但是运用到实践中是完全不同的两个概念,也感受到了在编程的学习过程中实践占有较重要的地位,编程学习中实践中所学到和感受到的要远大于理论学习。
其次就是本次课中我收获最大的就是学会利用网络知识进行自主学习,因为之前的编程课中,我可以依赖我的同学们帮助我一起解决问题,但是这个学期,周围的人只有我一个人选了这门课。在做实验遇到问题时我只能通过自己学习去解决,这也是最大的一个收获。
最后就是感觉教学的内容比较充实,时间比较紧迫,相对于其他课程来说实验报告偏多,比较累。但是可以理解,毕竟编程学习很需要实践,而且最后也蛮有收获的。
参考资料
【编写python时出现Non-ASCII character ‘\xe7‘ in file错误】
https://blog.csdn.net/zsxbd/article/details/120799386
【python爬虫 完整代码】
https://blog.csdn.net/CCGJason/article/details/120246567?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522165395390016782391814397%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=165395390016782391814397&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2alltop_positive~default-2-120246567-null-null.142v11pc_search_result_control_group,157v12control&utm_term=python%E7%88%AC%E8%99%AB&spm=1018.2226.3001.4187
【Python大作业——爬虫+可视化+数据分析+数据库(数据分析篇)】
https://blog.csdn.net/CCGJason/article/details/120246567?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522165395390016782391814397%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=165395390016782391814397&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2alltop_positive~default-2-120246567-null-null.142v11pc_search_result_control_group,157v12control&utm_term=python%E7%88%AC%E8%99%AB&spm=1018.2226.3001.4187

