第七周作业:
BAM: Bottleneck Attention Module
1.提出了一种可以结合到任何前向传播卷积神经网络中的注意力模块。
2.整体网络结构:作者将BAM模块加载了Resnet中的每个stage之间,用于消除低层次特征,聚焦于明确的目标。
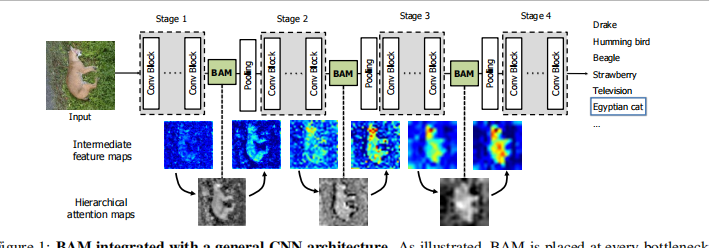
3.BAM块:
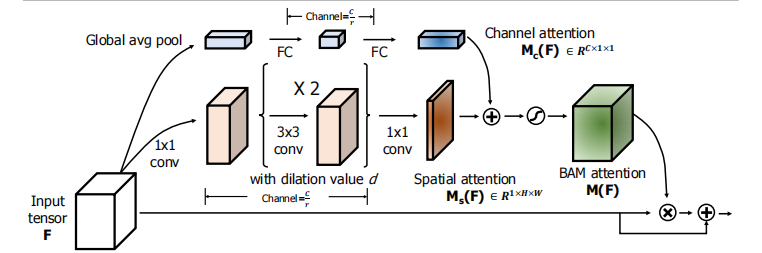
(1)Channel attention branch
为了整合通道信息,首先用了一个全局平均值池化,得到一个C*1*1的向量,之后为了整合不同通道间的信息,经过了一个含有一个隐藏层的MLP,最后结果经过一个BN。
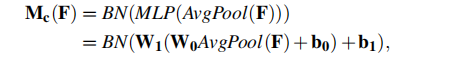
(2)Spatial attention branch
该部分是为了产生一个H*W的空间特征图用来表示不同空间位置的重要性,除此之外,为了增加感受野,这里采用了空洞卷积的方法。
具体的做法是:首先使用一个1*1卷积将通道数降到C/r,即得到一个C/r *H* W的输出,之后用两个3*3卷积来提取上下文信息最后再使用1*1卷积还原回去,最后经过一个BN层。
(3)Combine two attention branches
因为大小不同,所以在进行融合前,先扩张到相同的尺寸C*H*W,之后用元素求和的方法来进行融合。之后再通过一个sigmoid函数,得到一个0到1范围内的三维注意力图,最后再与原始输入结合,得到最后的特征图。
Dual Attention Network for Scene Segmentation
1.提出了一种能自适应集成本地特征和全局特征的注意力网络.
2.网络结构:
(1)OVerview:
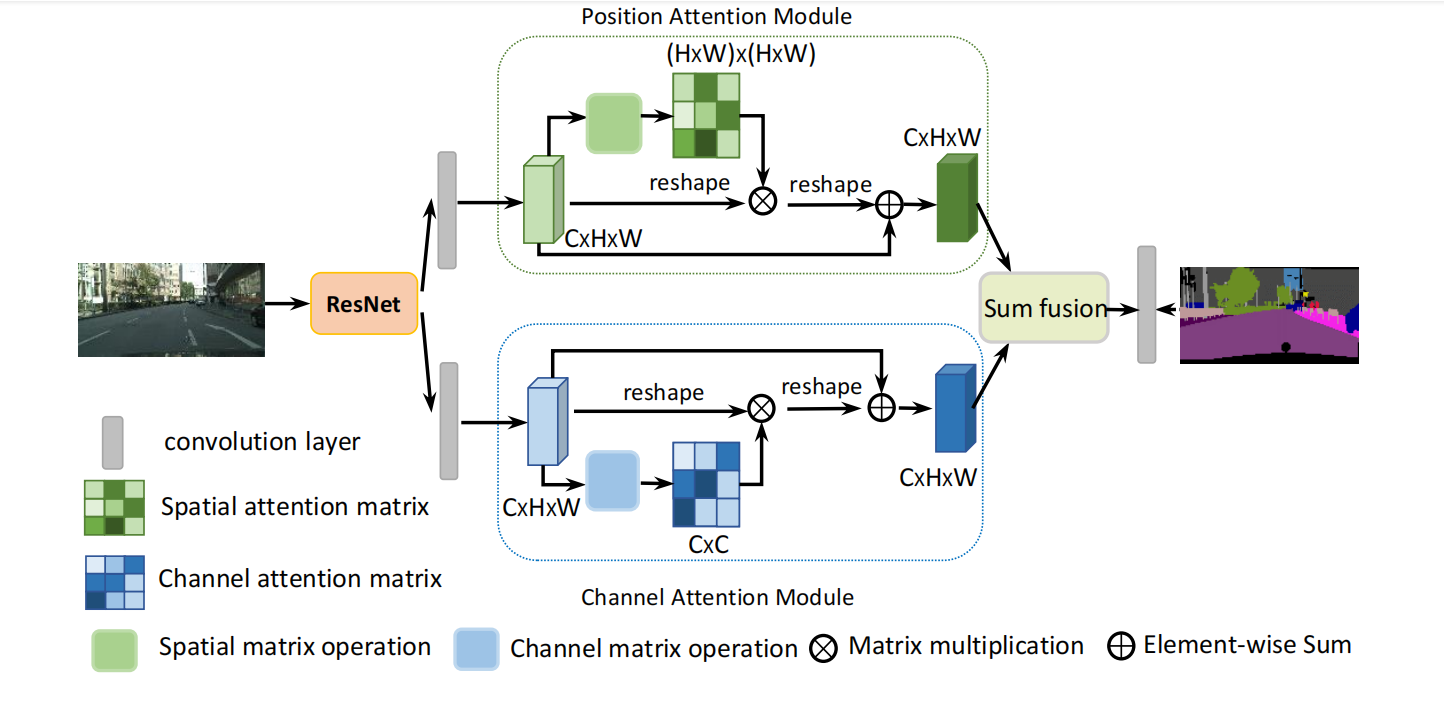
首先将输出的特征图通过卷积变为原本大小的1/8,之后通过两个并行的注意力模块分别得到空间和通道特征,最后将其融合。
(2)Position Attention Module
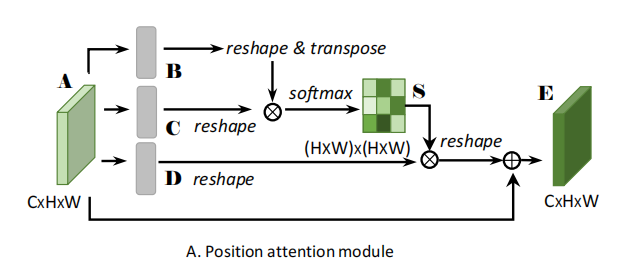
对于一个C*H*W的输入,首先将其输入卷积层,得到三个大小为C*H*W的输出,表示为B,C,D;之后将其reshape维C*N的输出(N=H*W);之后对B的转置与C相乘,经过一个softmax层得到一个N*N输出。这个输出就是spatial attention map ,接着,将S的转置与D矩阵乘后,将结果reshape到(CxHxW),乘以一个尺度因子后再加上原始输入图像得到最后的输出map 。
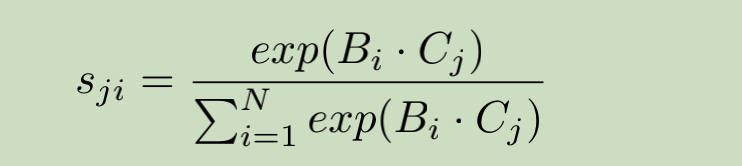
Sji表示表示位置i对j的影响。
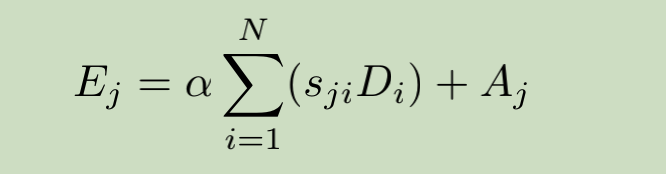
其中尺度因子a初始化为0,通过不断训练改变其权重。
(2)Channel Attention Module
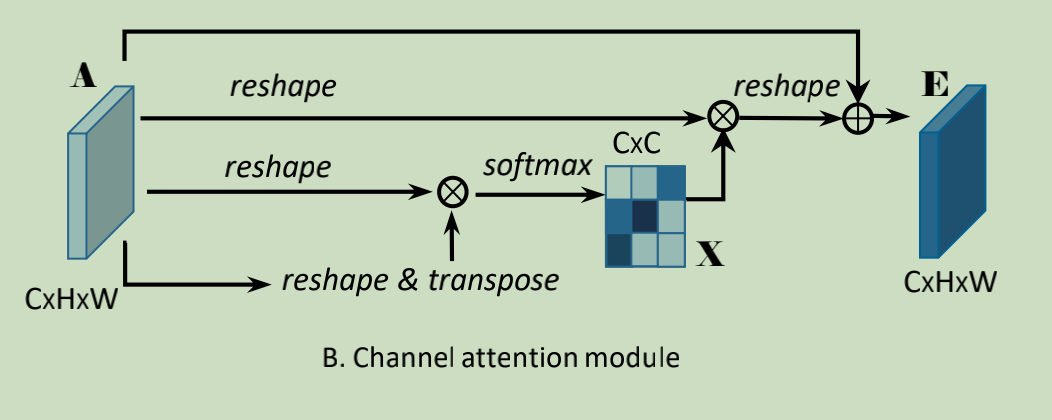
先对A进行reshape到(CxN),然后A与A的转置进行矩阵乘,经过softmax后得到通道间的map X(CxC),之后再乘以A(CxN),得到的输出乘以尺度因子β后与原图相加后获得最后的输出E。
该模块的重点是计算出map X,其每一行表示一个通道与其余通道间的依赖关系。
1.本文作者认为,SeNet中使用两个FC层进行降为对channel attention预测是不利的,因此本文提出了如下的网络构造:
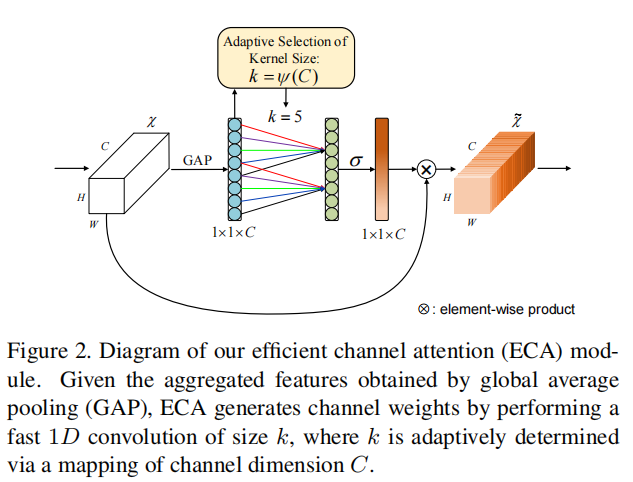
同时,该方法所带来的的参数量等的增加非常小。
SE block的结构由两部分组成:(1)global avg pooling产生1 ∗ 1 ∗ C 1*1*C1∗1∗C大小的feature maps;(2)两个fc层(中间有维度缩减)来产生每个channel的weight。
ECA-Net的结构:(1)global avg pooling产生1 ∗ 1 ∗ C 1*1*C1∗1∗C大小的feature maps;(2)计算得到自适应的kernel_size;(3)应用kernel_size于一维卷积中,得到每个channel的weight。
import torch from torch import nn from torch.nn.parameter import Parameter class eca_layer(nn.Module): def __init__(self, channel, k_size=3): super(eca_layer, self).__init__() self.avg_pool = nn.AdaptiveAvgPool2d(1) self.conv = nn.Conv1d(1, 1, kernel_size=k_size, padding=(k_size - 1) // 2, bias=False) self.sigmoid = nn.Sigmoid() def forward(self, x): # x: input features with shape [b, c, h, w] b, c, h, w = x.size() # feature descriptor on the global spatial information y = self.avg_pool(x) # Two different branches of ECA module y = self.conv(y.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1) # Multi-scale information fusion y = self.sigmoid(y) return x * y.expand_as(x)
4.Improving Convolutional Networks with Self-Calibrated Convolutions
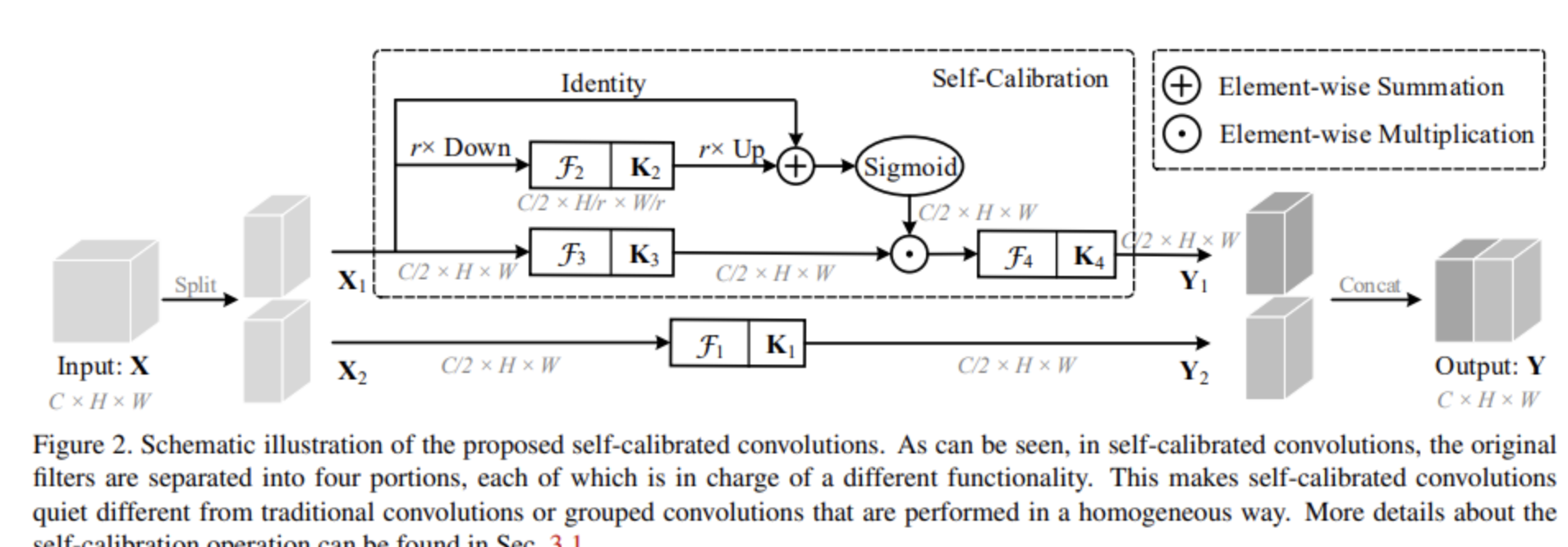
1.本文主要提出了一种自校准的卷积,该卷积通过内部通信显著扩展了每个卷积层的感受野,从而丰富了输出功能。特别是,与使用小卷积核(例如3 x 3)融合空间和通道方向信息的标准卷积不同,自校准卷积通过自我自适应地围绕每个空间位置建立了长距离空间和通道间依赖性的校准操作。
2.
将输入划分为了两个分支,一半进行自校准操作得到Y1,另一半进行正常卷积操作得到𝑌2。最终将Y1和Y2拼接得到Y。
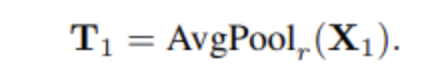
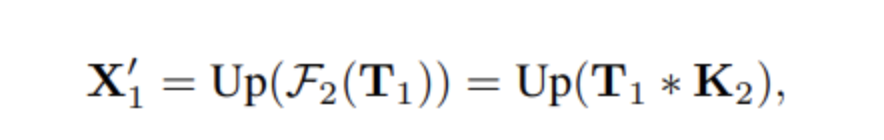
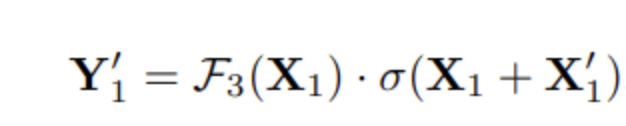
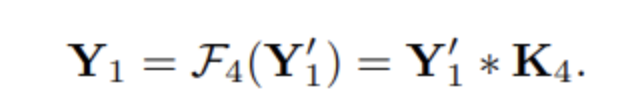
其中UP是双线性插值,下采样比例r默认为4。
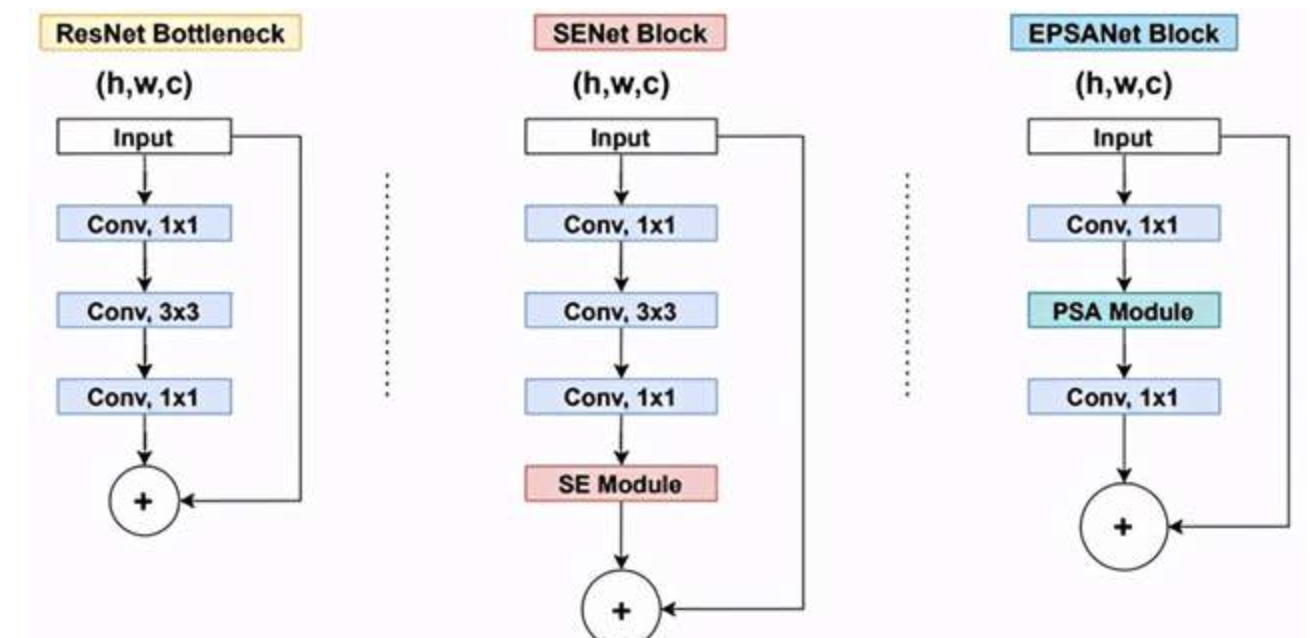
5.EPSANet: An Efficient Pyramid Split Attention Block on Convolutional Neural Network
1.Pyramid Split Attention (PSA)在SENet的基础上提出多尺度特征图提取策略,整体结构图如下所示。
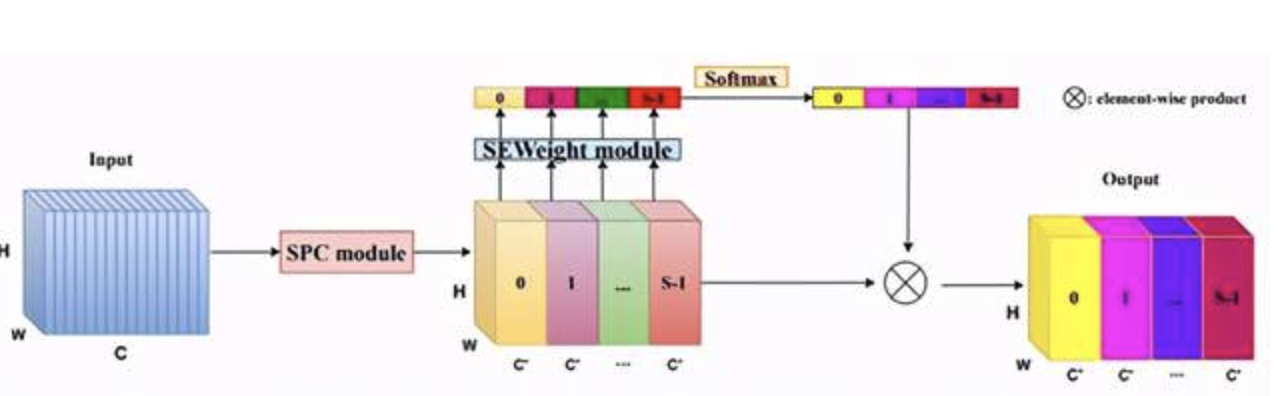
注意分为四个模块:
- Split and Concat (SPC)模块用于获得空间级多尺度特征图;
- SEWeight(SENet中的模块)被用于获得空间级视觉注意力向量来抽取多尺度响应图的目标特征;
- 使用Softmax函数用于再分配特征图权重向量;
- 元素相乘操作用于权重向量与原始特征图来获得最终结果响应图
Split and Concat Moudle
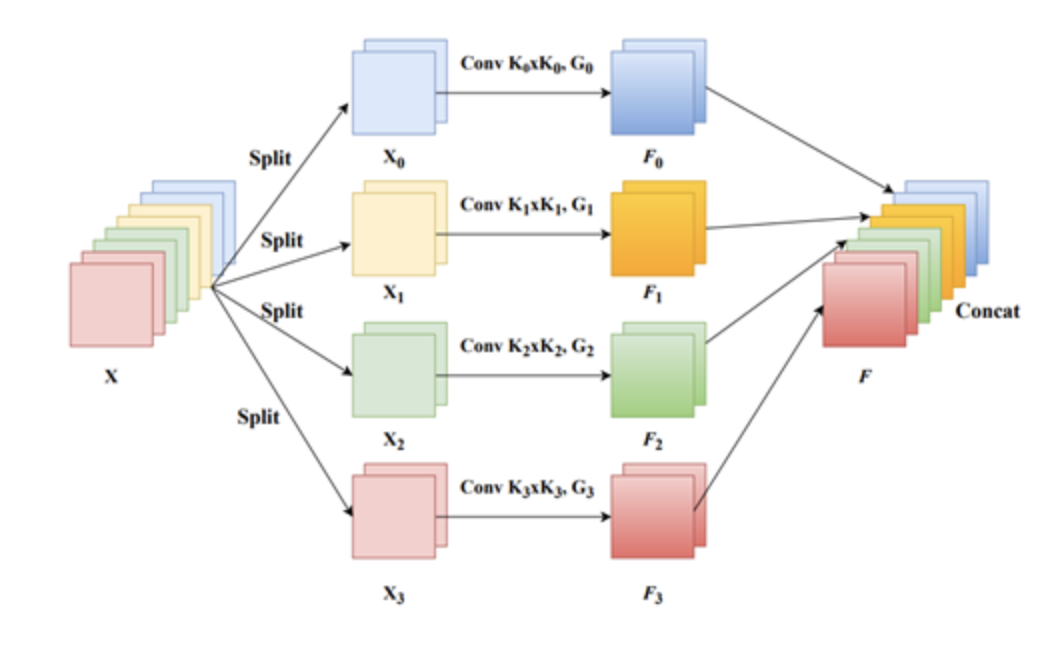
如上图所示,k0、k1、k2和k3是不同卷积核参数(以ESPANet-small为例,论文取3,5,7和9),G0、G1、G2和G3是分组卷积的参数(以ESPANet-small为例,论文默认取1,4,8和16)。整体可看做是模型采用不同卷积核提取多尺度目标特征,并采取Concat操作结合不同感受野下的多尺度特征。
整体结构:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号