从0到1再到N,探索亿级流量的IM架构演绎
从0到1再到N:探索亿级流量的IM架构演绎
说明: 本文仅作为个人学习记录,参考自《从0到1再到N,探索亿级流量的IM架构演绎》飞书云文档
目录
基础实现
最初方案
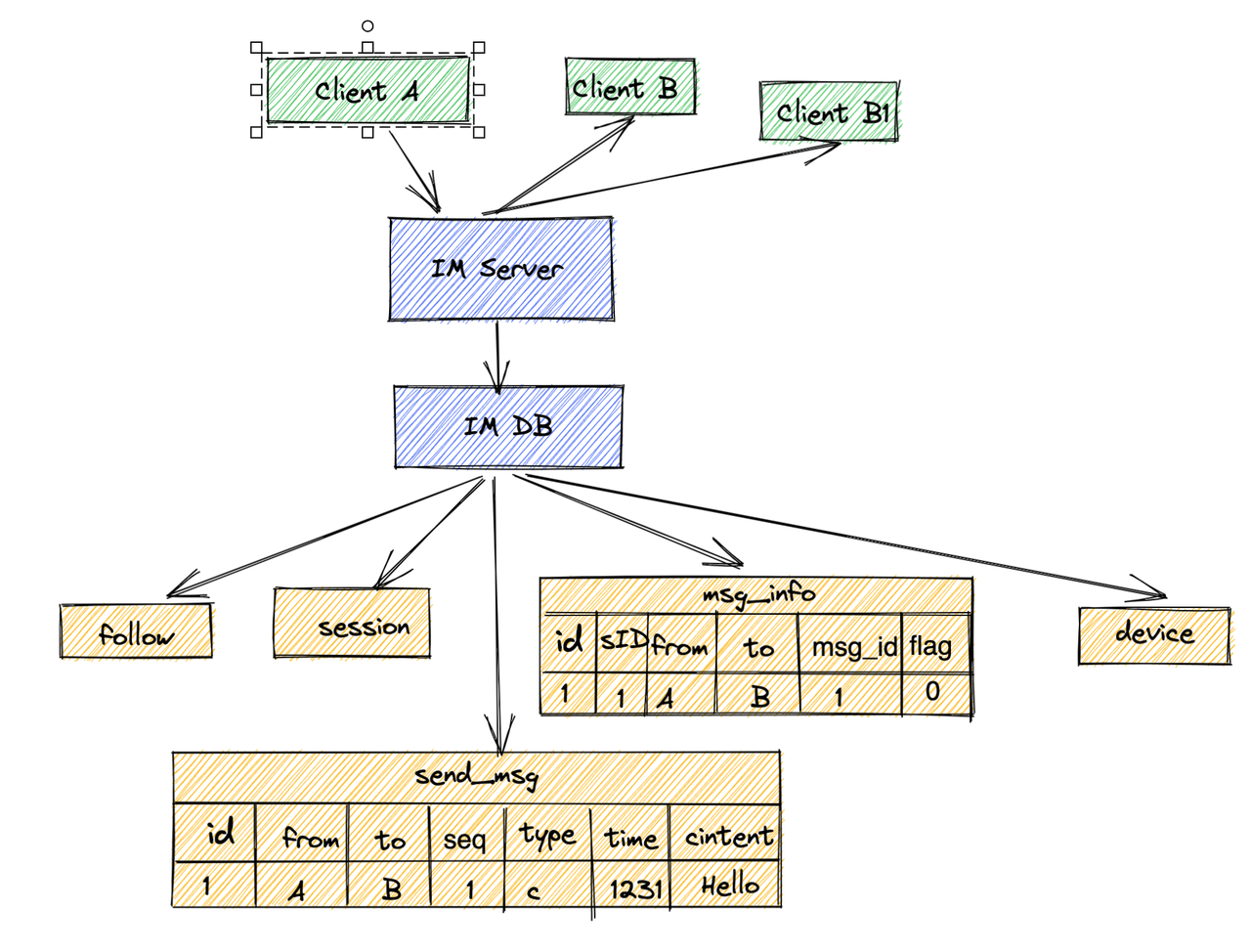
更优解
核心问题及解决方案
接入层设计
1. 实时性问题解决
问题: 轮询拉模式无法满足实时性要求,消息不能及时触达用户
解决方案: 使用TCP长连接push消息给用户
2. 长连接建立策略
问题: 客户端如何与服务端建立长连接?
解决方案:
- 基础方案: 客户端通过公网IP,Socket TCP编程直接连接服务端
- 优化方案: 通过IPConf服务下发公网IP给客户端
- 返回IP列表给客户端,由客户端选择最优IP
- 客户端可缓存IP列表,失败时选择其他IP
- 减少IPConfig服务压力
- 映射建立: 建立长连接后,IM Server业务层获得FD与uid的映射
- 负载均衡: IPConf服务通过协调服务与IM Server做服务发现,根据机器负载状态进行负载均衡
3. 架构分离优化
问题: 长连接服务占用大量内存资源,IO密集度高,而IM Server操作数据库逻辑较重,整体性能受限
解决方案: 分离接入层与IM Server业务层
- 接入层: 负责维护状态、收发消息
- IM Server: 负责业务逻辑(网关服务)
4. 状态服务设计
问题: 长连接服务需要存储大量状态信息,频繁迭代导致有状态服务重启缓慢
解决方案:
- 长连接服务只做消息收发
- 长连接服务把消息指标报给状态服务
- 状态服务计算后同步给服务发现服务
- 支持多个长连接服务,能处理玩家重新登录
5. 消息路由方案对比
问题: 如何知道客户端B的长连接在哪个接入层服务器上,进行消息路由并保证消息可靠送达?
| 方案 | 实现方式 | 优点 | 缺点 |
|---|---|---|---|
| 广播方案 | IM server将消息扇出式发送给所有接入层服务,接入层服务只处理自己持有uid的连接 | • 实现简单 • 适合超大聊天室场景 |
• 消息风暴,造成系统瘫痪 • 单聊场景过多无效通信 |
| 一致性哈希 | • ipConf服务与IM Server使用同一种hash方式 • 按uid进行分片,直接计算用户连接位置 • 通过统一服务注册发现系统 • 水平扩展时利用虚拟节点特性迁移长连接 |
• 计算简单,消息路由无性能损耗 • 实现简单 |
• 重度依赖服务发现系统稳定性 • 水平扩展时需要连接迁移 • 受一致性hash算法均匀性限制 |
| 路由服务层 | • 构建路由服务,使用kv存储uid与接入机器映射关系 • 支持不同会话类型组织映射关系 • 接入层服务在线同步更新kv • 路由服务与IM Server间维护消息队列 • 任意路由服务消费MQ解析路由信息 • 根据接入层机器标识创建routeKey |
• 可靠性高 • 通过MQ解耦,应对流量峰值 • MQ保证消息可靠送达 • 路由服务无状态可水平扩展 |
• 实现较为复杂 • 需要独立维护路由层集群 • 依赖底层KV和MQ稳定性 |
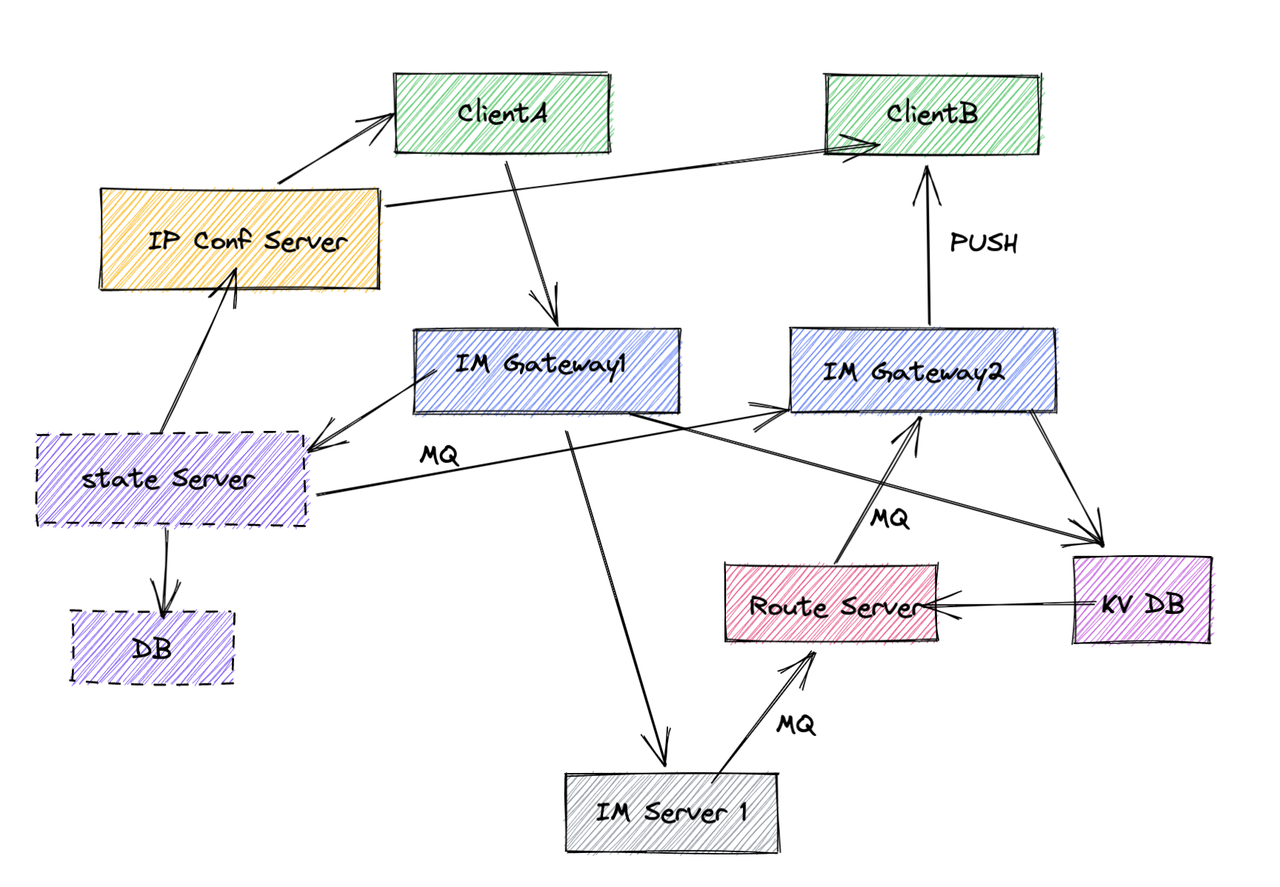
为什么采用MQ而不是RPC?
- RPC不能应对突发流量,无法消峰填谷
- 考虑push场景,MQ更合适
存储层设计
1. 超大群挑战
问题: 读写比1:9999,超大群每人发送一条消息要1亿分发量,如何控制超大群不将机器资源耗尽?
解决方案:
- 并发控制: 按群维度限制最大并发数,保证超大群收发消息不导致系统崩溃
- 消息合并: 达到并发限制后,将一段窗口内的消息合并压缩后下发
- 推拉结合: 通过信令对消息压缩,增加一步拉取的网络调用
- 信令聚合: 在时间窗口内聚合对同一用户的拉取信令,减少网络调用次数
2. 写放大问题
问题: 存储系统存在严重的写放大(扩散)问题,如何减少写入数据量,降低存储成本?
解决方案:
- 对超大群降级为读放大模式进行存储(消息只存一份)
- 消息仅同步写入收件箱
- 群状态信息、回执消息等写入HBase等存储中
3. 回执消息处理
问题: 如何保证万人群中的已读/未读列表与数量的一致性?
解决方案:
- 实时流处理: 接收者已读消息的下发要同步进行
- 异步落库: 接收者的消息已读可以异步落库
- 超大群降级: 群状态变更服务进行降级,不再发送信令通知
- 最终一致性: 异步写入通过重试保证最终一致性
4. 延迟优化
问题: 从DB直接取数无法满足延迟10ms以下,应该如何优化?
存储介质读写耗时对比
| 存储介质 | 读取耗时 | 写入耗时 |
|---|---|---|
| 内存 | 纳秒级 | 纳秒级 |
| SSD | 微秒级 | 毫秒级 |
| 机械硬盘 | 毫秒级 | 毫秒级 |
| 网络存储 | 毫秒级+ | 毫秒级+ |
优化方案对比
| 方案 | 实现方式 | 优点 | 缺点 |
|---|---|---|---|
| 分级存储 | • 按uid维度在memDB上维护可排序list • 超大群聊退化为读扩散模式 • 按群聊会话ID进行本地LRU缓存 • 使用protobuf序列化压缩 • 本地缓存使用HotRing算法测算热点 • 使用MQ广播消息状态变化 • 限制拉取会话消息切片范围 • 超过一定时间的数据压缩存储在文件系统 |
• 在线请求流量在MemDB终止 • 按读取热度分级处理 • 对离线消息同步等range操作支持良好 • 可较为简单地支持群聊推拉结合方案 |
• IM Server本地缓存预热较慢 • 大量使用内存,运维难度提升 • 需要维护多个缓存间的一致性 • 要关注缓存命中率、缓存穿透等问题 |
| 多元DB存储 | • 使用RocksDB等kv引擎存储离线消息拉链 • key为会话ID,value是序列化消息列表 • 消息列表过长则分列存储 • 按会话ID+分段seqID作为key • 支持对key的value append新字节数据 • 超过期限的消息存储在文件系统 • 使用消息ID作为key,用户id列表作为value • 使用NVMe SSD等新硬件特性 • 使用多种NoSQL数据库 |
• 基于磁盘的KV存储解决存储容量问题 • 便于运维 • 图数据库的使用提供更多策略优化 |
• RocksDB是单机数据库,需要自研分布式代理层 • 磁盘kv读写性能受影响,但吞吐有所提升 • RocksDB需要自行实现消息更新逻辑,实现复杂 |
| 图数据库 | • 用图数据库存储好友关系、会话消息列表等 • 存储用户关系与群组关系 • 运行实时的近线OLAP查询 • 快速识别热点群聊等有价值信息 • 利用信息的近实时快速更新 • 对热点群聊进行特殊处理 |
• 低延迟,提供丰富灵活的查询功能 • 可以挖掘极具价值的社交信息 • 存储层DB统一方便运维 |
• 技术生态不完善,缺乏大规模商用开源案例 • 运维成本高,出错后难以快速排查 • 提供更多功能导致性能不如纯粹的KV引擎 |
5. 存储层代理服务
设计目标: 增加存储代理服务层,屏蔽底层存储细节,使IM Server无感知
实现方式:
- 代理层基于key做hash分片
- 底层kvserver基于一致性协议进行复制
- 代理层进行分片与合并
- 对超大群聊做自旋Cache,减少下游DB重复工作负载
优势:
- 业务隔离,对底层存储细节屏蔽
- 代理层无状态可水平扩展
- 可以做各种策略,优化查询
- 消息列表缓存在代理层,减少IM Server内存负担
劣势:
- 增加了一层逻辑,复杂度增大
blob:https://nxwz51a5wp.feishu.cn/050c3c2f-317d-442f-8cb4-1eb574796111
消息时序一致性
问题根源
消息时序一致性问题的根源在于:
- 多发送方
- 多接收方
- 多线程
- 网络传输不确定性
1. 消息不丢失保障
上行消息:
- 客户端重试机制
- 服务端确认机制
下行消息:
- 服务端重试机制
- 接收方需要回复ACK,避免无限重试
2. 防止消息重复
UUID去重是否可行?
上行消息去重
- 客户端在会话内生成递增的cid
- 服务器存储当前会话接收到的max_cid
- 如果发送的消息不是max_cid+1,则将其丢弃
下行消息去重
- 服务端为每个发送的消息分配seqid
- 客户端维护接收到的最大max_seq_id
- 如果发送的消息不是max_seq_id+1,则将其丢弃
3. 消息有序性保障
排序机制: 按某个递增的消息ID排序
实现方式:
- 上行消息: 按cid为每个消息分配seqID
- 下行消息: 客户端按seqID进行排序
4. 递增消息ID生成策略
参考资料:

高可用方案
1. 长连接断线处理
心跳保活机制
为什么应用层还需要心跳?TCP的心跳不好用吗?
实现策略:
- 客户端周期性发送心跳给IM Gateway
- IM Gateway重置内部定时器
- 控制心跳包大小在0.5kb以下
心跳频率优化:
- 心跳过长: 服务端感知断线效率低,资源利用率低
- 心跳过短: 造成心跳潮汐,给网关造成流量压力(通过随机打撒解决)
适应性调整:
- 发送心跳会经过多个运营商网络
- 不同地区运营商对长连接的资源回收策略不同(GGSN)
- 自适应心跳包: 前台状态固定心跳,后台状态自适应测算NAT淘汰时间
断线重连策略
快速重连场景: 客户端由于网络原因断线(频繁切换网络、坐地铁)
重连策略:
- 断线后快速重连几次到原来的服务端
- 服务端发现连接断开后不立即删除用户状态信息,等待超时时间
- 在等待时间内,客户端快速建立新连接,服务端复用原有状态信息
雪崩处理: 服务端崩溃导致大规模客户端重连
解决方案:
- IPConf服务通过服务发现机制快速识别服务端节点故障
- 客户端断线后,通过随机策略打散重连请求时间
- 获取IPConf服务的新IP调度列表重新调度,原有服务器存在时优先选择
2. 心跳风暴解决
问题描述
- 心跳/消息超时计时器数量与连接数和push消息数成正比
- 长连接服务崩溃时,未送达的消息如何再次重发?
状态恢复策略
- 主动拉取: 连接建立后调用一次离线消息同步接口,避免网关侧状态丢失
- 状态外置: 将连接状态信息全部维护在state server中,与IM Gateway使用RPC或共享内存
- 持久化处理: State server可以做一定的持久化处理,使用快照&checkpoint机制
- 状态限制: 恢复的状态只能是其中一部分,与计时器相关的状态信息由于时效性无法恢复
定时器优化
传统问题:
- 大量定时器占用大量内存资源
- 定时任务触发使整个系统卡顿造成消息超时
性能瓶颈:
- 传统计时器采用二叉堆实现,存取定时任务时间复杂度为LogN
- 大量消息收发造成定时任务频繁插入与删除
优化方案:
- 使用时间轮算法可以常量级别进行任务插入与删除
- 但定时精度有所缺失
3. 弱网场景优化
快链路 - TCP连接优化
- 数据包大小: 限定传输数据包大小1400字节,避免超过MSS造成IP数据分片
- 拥塞控制: 放大TCP拥塞控制窗口,为有线网络设计的拥塞控制算法不适用于无线网络
- 缓冲区调整: 调整socket读写缓冲区,避免数据包溢出
- RTO优化: 调整RTO初始值设置为3s,避免重试造成的堵塞
- 算法禁用: 禁用Nagle算法延迟算法,避免小数据包被协议栈缓存
调度策略优化
- 赛马机制: 多个IP后台测速选择最快连接线路(服务端要对请求进行识别,避免资源浪费)
- 动态调度: 调度策略基于客户端上报数据进行计算,IPConf分发最佳IP进行调度
- 超时优化: 基于网络环境设置不同的超时时间,超时参数由IPConf服务动态下发
- 短链退化: 当长连接断线次数太多,重连过于频繁的极端弱网环境(如地铁),则退化为轮询模式收发消息
协议优化
- 协议切换: 弱网场景下切换QUIC协议
- 协议精简: 精简协议包,采用自定义二进制协议
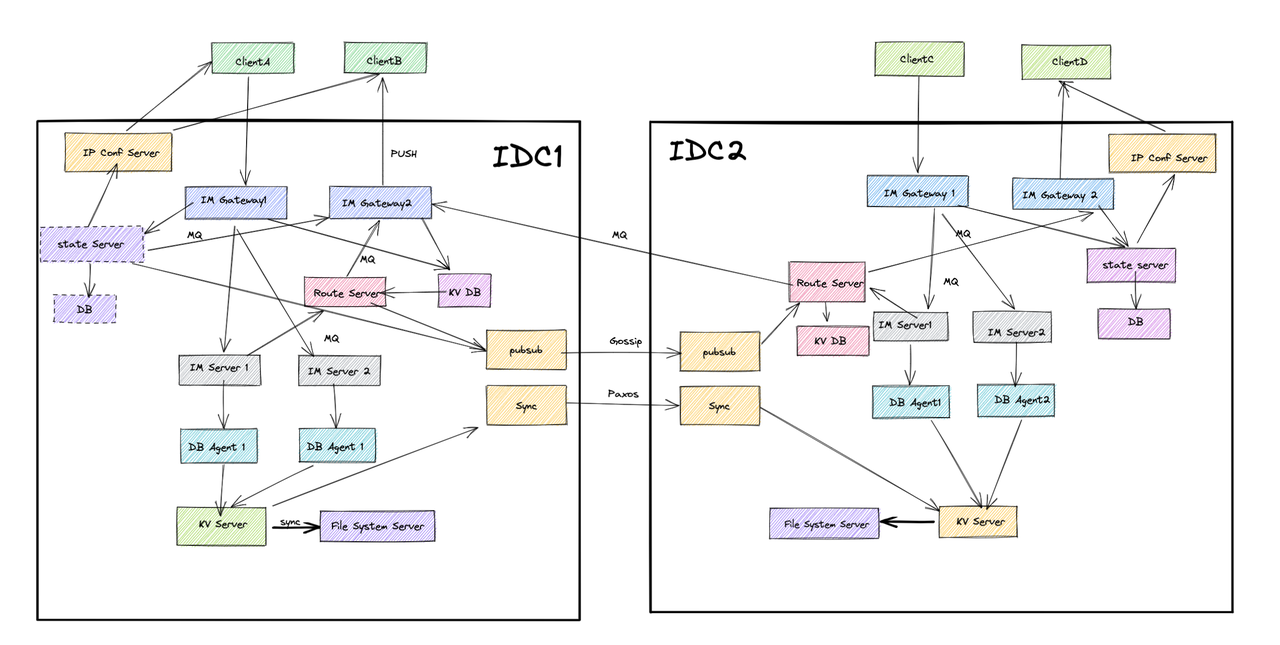
4. 异地多活方案
核心思想
尽量减少广域请求
实现架构
- 服务发现: 基于跨数据中心的服务发现系统
- 旁路调度: 通过IPConf进行旁路调度,IPConf跨数据中心感知到IM Gateway
- 流量分片: IPConf基于客户端IP位置信息进行IDC的流量分片
- 策略调度: 基于位置策略调度最优IDC中的最优IM Gateway Server
- 故障切换: 如果IDC不可用,IPConf服务自动切流量到可用的IDC上
- 数据同步: 每个IDC存储全量数据以应对机房级故障,基于底层同步组件同步数据
消息路由
- 跨IDC路由: IM Server通过跨IDC的Route Server服务发现IM Gateway并通过跨IDC的MQ发送消息
- 路由广播: Route Server将自己IDC创建的kv对广播给其他IDC,便于进行路由转发
- 消息转发: IM Server转发消息给接收者所在的IDC的IM Gateway上,消息内携带此消息写入的IDC
- 并行拉取: 接收者根据push通知中携带的多个IDC信息,并行去多个IDC拉取消息
- 兜底机制: 为应对转发失败的情况,客户端可以在未收到任何push通知的一段时间后主动pull消息
可运维性
1. 可观测性建设
指标体系构建
目标: 展示能够暴露问题的指标
架构: 搭建云原生架构,构建指标观察平台
业务指标
- 热点识别: top活跃群聊/会话,热key等
- 核心指标: 最小单元的QPS、延迟、失败率三大指标
- 链路跟踪: 分布式链路跟踪
系统指标
- 应用服务监控
- 数据中心/集群监控
- Docker系统监控
- 物理机系统监控
运行日志
- 链路跟踪日志
- 关键词检索日志
- 异常、错误日志
2. 自动化运维
减少人工干预
目标: 减少人工运维的干预,在紧急情况下可人工快速介入
实现方式:
- 服务网格: 接入服务网格,进行流量治理
- 功能平台化: 超时/重试/鉴权/限流/断流/风控等功能平台化
- 热备集群: 提供热备集群
影响最小化
问题: 部署、重启、修改、异常处理如何能影响更少的用户?
解决方案:
- 热重启: 实现长连接服务的热重启
- 参考:MOSN源码解析 - 启动流程
- 参考:MOSN平滑升级原理
- 流程规范: 严格的代码发布流程,review机制等
扩展问题
安全性问题
端到端加密
作为IM系统,用户的聊天数据均是私密信息,在现有的协议上对用户的聊天内容进行加密存储,并在另一端用户的客户端进行解密,是一种最理想的状态。
多媒体消息
图片/视频/媒体上传
- 支持断点续传等功能
- 定义上传信令
- 通过局部敏感哈希识别重复数据
表情包管理
- 对表情包进行编码
- 信令交换编码
总结
本文从IM系统的基础实现开始,逐步深入探讨了亿级流量IM架构的各个关键环节:
- 接入层设计: 从轮询模式演进到长连接模式,解决了实时性、路由、负载均衡等关键问题
- 存储层优化: 针对超大群、写放大、延迟优化等挑战,提供了分级存储、多元DB、图数据库等多种解决方案
- 消息一致性: 通过递增ID、去重机制、有序性保障等手段确保消息的可靠性
- 高可用保障: 涵盖断线重连、心跳优化、弱网处理、异地多活等全方位的可用性方案
- 运维体系: 建立完善的监控、自动化运维体系,确保系统的稳定运行
整个架构演进过程体现了从简单到复杂、从单机到分布式、从功能实现到性能优化的渐进式发展思路,为构建大规模IM系统提供了宝贵的参考价值。
参考链接: 原博客地址

 浙公网安备 33010602011771号
浙公网安备 33010602011771号