
机器学习--苹果和西红柿分类
一、选题背景
苹果和西红柿有着相似的外表和颜色,一个属于蔬菜类,一个属于水果类。在果蔬加工厂中凭借工人的肉眼很难对苹果和西红柿做到又快又准的分类效果。所以,在效率上说,使用计算机对西红柿和苹果进行分类的分类机器能够有效的代替使用肉眼进行分类的工人,对于工厂来说,在节约了工人的劳动力的同时也降低了劳动成本;能够对果蔬进行分类的机器无论是对工人来说还是对工厂来说,都有着不可代替的价值和作用。
二、设计方案
1、 本题采用的机器学习案例的来源描述
本题所采用的案例数据集来源于kaggle的西红柿和苹果的分类项目。
2、 采用的机器学习框架描述
采用了tensorflow以及keras框架。Tensorflow框架是一个基于数据流编程的符号数学系统,被广泛应用于各类机器学习算法的编程实现中,tensorflow拥有多层级结构,可部署于各类服务器、PC终端和网页并支持GPU和TPU高性能的数值计算。keras框架是一个由Python编写的开源人工神经网络库,可以作tensorflow的高阶应用程序接口,进行深度学习模型的设计、调试、评估、应用以及可视化任务。
3、 涉及到的技术难点及解决思路
技术难点:如何找到数据集;使用什么技术实现苹果和西红柿的有效分类。
解决思路:借助kaggle的分类任务,找到苹果和西红柿分类的数据集;考虑到苹果与西红柿的分类属于二分类任务,使用tensorflow框架、keras框架来对两者进行分类。
三、实现步骤
获取数据集

(1)导入工具包
1 import os 2 import cv2 3 import time 4 import shutil 5 import itertools 6 import numpy as np 7 import pandas as pd 8 import seaborn as sns 9 import tensorflow as tf 10 sns.set_style('darkgrid') 11 from tensorflow import keras 12 import matplotlib.pyplot as plt 13 from keras import regularizers 14 from keras.optimizers import adam_v2 , Adamax 15 from sklearn.model_selection import train_test_split 16 from keras.metrics import categorical_crossentropy 17 from keras.models import Model, load_model, Sequential 18 from sklearn.metrics import confusion_matrix, classification_report 19 from keras.preprocessing.image import ImageDataGenerator 20 from keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Activation, Dropout, BatchNormalization 21 22 print ('modules loaded')
(2)数据处理函数
1 def define_paths(dir): 2 filepaths = [] 3 labels = [] 4 folds = os.listdir(dir) 5 for fold in folds: 6 foldpath = os.path.join(dir, fold) 7 filelist = os.listdir(foldpath) 8 for file in filelist: 9 fpath = os.path.join(foldpath, file) 10 filepaths.append(fpath) 11 labels.append(fold) 12 return filepaths, labels 13 14 def define_df(files, classes): 15 Fseries = pd.Series(files, name= 'filepaths') 16 Lseries = pd.Series(classes, name='labels') 17 return pd.concat([Fseries, Lseries], axis= 1) 18 19 def create_df(tr_dir, ts_dir): 20 # train dataframe 21 files, classes = define_paths(tr_dir) 22 train_df = define_df(files, classes) 23 24 # test dataframe 25 files, classes = define_paths(ts_dir) 26 test_df = define_df(files, classes) 27 return train_df, test_df
(3)读取数据
1 def create_gens(train_df, test_df, batch_size): 2 img_size = (224, 224) 3 channels = 3 4 img_shape = (img_size[0], img_size[1], channels) 5 ts_length = len(test_df) 6 test_batch_size = test_batch_size = max(sorted([ts_length // n for n in range(1, ts_length + 1) if ts_length%n == 0 and ts_length/n <= 80])) 7 test_steps = ts_length // test_batch_size 8 def scalar(img): 9 return img 10 tr_gen = ImageDataGenerator(preprocessing_function= scalar, horizontal_flip= True) 11 ts_gen = ImageDataGenerator(preprocessing_function= scalar) 12 train_gen = tr_gen.flow_from_dataframe( train_df, x_col= 'filepaths', y_col= 'labels', target_size= img_size, class_mode= 'categorical', 13 color_mode= 'rgb', shuffle= True, batch_size= batch_size) 14 15 test_gen = ts_gen.flow_from_dataframe( test_df, x_col= 'filepaths', y_col= 'labels', target_size= img_size, class_mode= 'categorical', 16 color_mode= 'rgb', shuffle= False, batch_size= test_batch_size) 17 return train_gen, test_gen
(4)定义训练过程中的函数
1 def plot_training(hist): 2 tr_acc = hist.history['accuracy'] 3 tr_loss = hist.history['loss'] 4 val_acc = hist.history['val_accuracy'] 5 val_loss = hist.history['val_loss'] 6 index_loss = np.argmin(val_loss) # get number of epoch with the lowest validation loss 7 val_lowest = val_loss[index_loss] # get the loss value of epoch with the lowest validation loss 8 index_acc = np.argmax(val_acc) # get number of epoch with the highest validation accuracy 9 acc_highest = val_acc[index_acc] # get the loss value of epoch with the highest validation accuracy 10 11 plt.figure(figsize= (20, 8)) 12 plt.style.use('fivethirtyeight') 13 Epochs = [i+1 for i in range(len(tr_acc))] # create x-axis by epochs count 14 loss_label = f'best epoch= {str(index_loss + 1)}' # label of lowest val_loss 15 acc_label = f'best epoch= {str(index_acc + 1)}' # label of highest val_accuracy 16 plt.subplot(1, 2, 1) 17 plt.plot(Epochs, tr_loss, 'r', label= 'Training loss') 18 plt.plot(Epochs, val_loss, 'g', label= 'Validation loss') 19 plt.scatter(index_loss + 1, val_lowest, s= 150, c= 'blue', label= loss_label) 20 plt.title('Training and Validation Loss') 21 plt.xlabel('Epochs') 22 plt.ylabel('Loss') 23 plt.legend() 24 plt.subplot(1, 2, 2) 25 plt.plot(Epochs, tr_acc, 'r', label= 'Training Accuracy') 26 plt.plot(Epochs, val_acc, 'g', label= 'Validation Accuracy') 27 plt.scatter(index_acc + 1 , acc_highest, s= 150, c= 'blue', label= acc_label) 28 plt.title('Training and Validation Accuracy') 29 plt.xlabel('Epochs') 30 plt.ylabel('Accuracy') 31 plt.legend() 32 plt.tight_layout 33 plt.show()
(5)设置路径并展示部分图片
1 # Get Dataframes 2 train_dir = r'train' 3 test_dir = r'test' 4 train_df, test_df = create_df(train_dir, test_dir) 5 6 # Get Generators 7 batch_size = 40 8 train_gen, test_gen = create_gens(train_df, test_df, batch_size) 9 10 show_images(train_gen)
Found 97 validated image filenames belonging to 2 classes.

1 img_size = (224, 224) 2 channels = 3 3 img_shape = (img_size[0], img_size[1], channels) 4 class_count = len(list(train_gen.class_indices.keys())) # to define number of classes in dense layer 5 6 # create pre-trained model 7 base_model = tf.keras.applications.efficientnet.EfficientNetB3(include_top= False, weights= "imagenet", input_shape= img_shape, pooling= 'max') 8 9 model = Sequential([ 10 base_model, 11 BatchNormalization(axis= -1, momentum= 0.99, epsilon= 0.001), 12 Dense(256, kernel_regularizer= regularizers.l2(l= 0.016), activity_regularizer= regularizers.l1(0.006), 13 bias_regularizer= regularizers.l1(0.006), activation= 'relu'), 14 Dropout(rate= 0.45, seed= 123), 15 Dense(class_count, activation= 'softmax') 16 ]) 17 18 model.compile(Adamax(learning_rate= 0.001), loss= 'categorical_crossentropy', metrics= ['accuracy']) 19 20 model.summary()
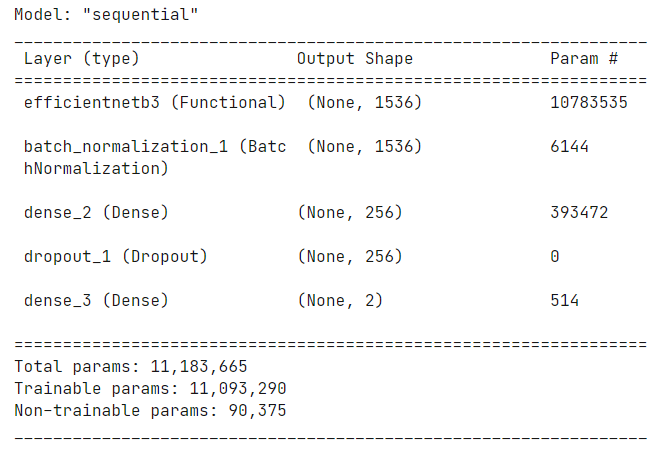
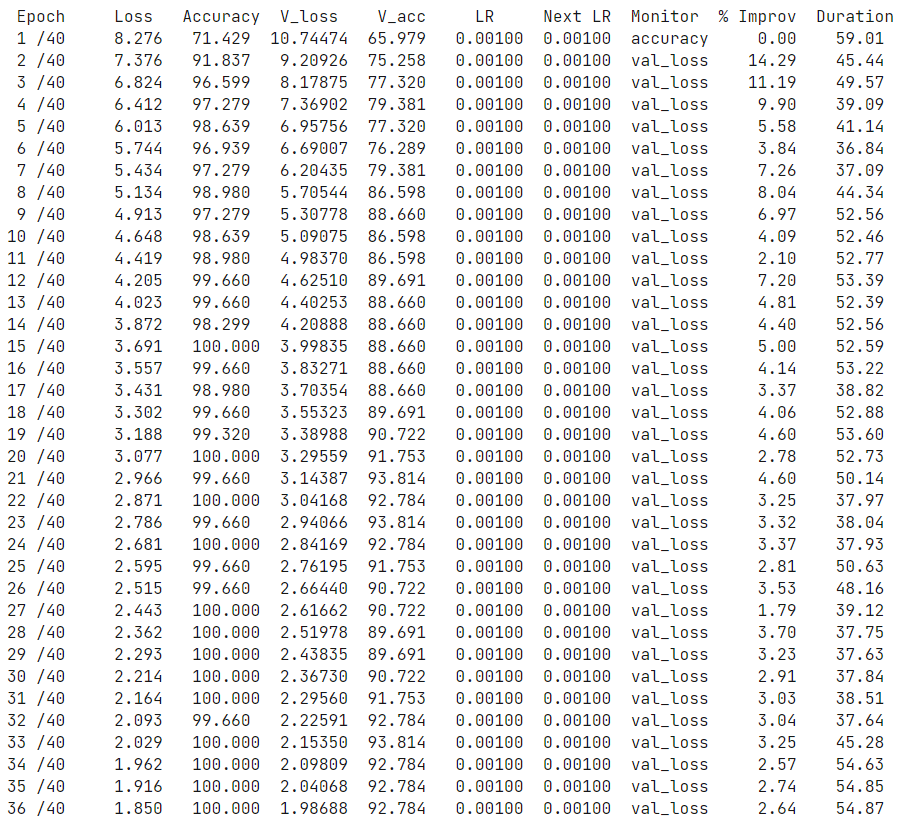
(7)训练模型,并把训练数据保存到history里
1 history = model.fit(x= train_gen, epochs= epochs, verbose= 0, callbacks= callbacks, 2 validation_data= test_gen, validation_steps= None, shuffle= False, 3 initial_epoch= 0)

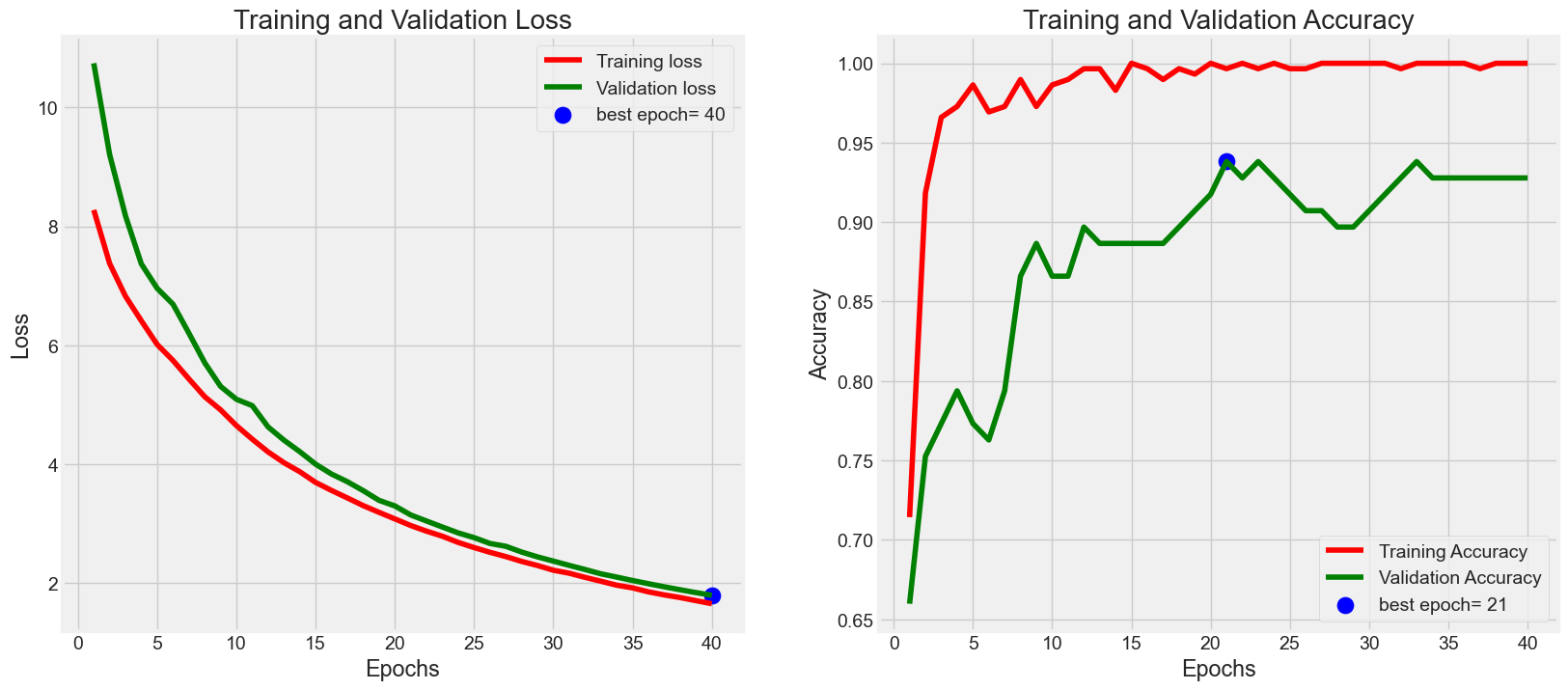
(8)展示训练过程中的损失值和准确率变化曲线
1 plot_training(history)
(9)计算测试集上的损失值和准确率
1 ts_length = len(test_df) 2 test_batch_size = test_batch_size = max(sorted([ts_length // n for n in range(1, ts_length + 1) if ts_length%n == 0 and ts_length/n <= 80])) 3 test_steps = ts_length // test_batch_size 4 train_score = model.evaluate(train_gen, steps= test_steps, verbose= 1) 5 test_score = model.evaluate(test_gen, steps= test_steps, verbose= 1) 6 7 print("Train Loss: ", train_score[0]) 8 print("Train Accuracy: ", train_score[1]) 9 print('-' * 20) 10 print("Test Loss: ", test_score[0]) 11 print("Test Accuracy: ", test_score[1])

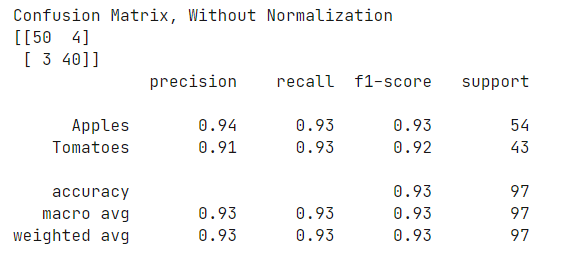
(10)绘制混淆矩阵
1 target_names = ['Apples', 'Tomatoes'] 2 # Confusion matrix 3 cm = confusion_matrix(test_gen.classes, y_pred) 4 plot_confusion_matrix(cm= cm, classes= target_names, title = 'Confusion Matrix') 5 # Classification report 6 print(classification_report(test_gen.classes, y_pred, target_names= target_names))


1 class_dict = train_gen.class_indices 2 save_path = '' 3 height = [] 4 width = [] 5 for _ in range(len(class_dict)): 6 height.append(img_size[0]) 7 width.append(img_size[1]) 8 9 Index_series = pd.Series(list(class_dict.values()), name= 'class_index') 10 Class_series = pd.Series(list(class_dict.keys()), name= 'class') 11 Height_series = pd.Series(height, name= 'height') 12 Width_series = pd.Series(width, name= 'width') 13 class_df = pd.concat([Index_series, Class_series, Height_series, Width_series], axis= 1) 14 subject = 'Apples-Tomatoes-Classification' 15 csv_name = f'{subject}-class_dict.csv' 16 csv_save_loc = os.path.join(save_path, csv_name) 17 class_df.to_csv(csv_save_loc, index= False) 18 print(f'class csv file was saved as {csv_save_loc}')
四、总结
(1) 机器学习就是按照人类的思维来进行一系列的取舍操作,这次的苹果和西红柿的分类使用的是机器学习中的监督学习,给定数据和标签对数据集进行训练学习,从而找到苹果和西红柿数据之间的不同点,能够让计算机去根据这些数据去识别出属于哪一类。通过这次机器学习过程的实现,我发现利用好机器学习的技术能够大大方便生活以及生产,对社会、经济以及各个方面都有着积极的作用。
(2) 通过这次的实现,我学习到了很多知识点,让我了解到了机器学习与深度学习之间的密切关系,同时还学习到了高效利用机器学习对人类社会的发展有着极其重要的作用。
以下附上完整代码
1 import os 2 import cv2 3 import time 4 import shutil 5 import itertools 6 import numpy as np 7 import pandas as pd 8 import seaborn as sns 9 import tensorflow as tf 10 sns.set_style('darkgrid') 11 from tensorflow import keras 12 import matplotlib.pyplot as plt 13 from keras import regularizers 14 from keras.optimizers import adam_v2 , Adamax 15 from sklearn.model_selection import train_test_split 16 from keras.metrics import categorical_crossentropy 17 from keras.models import Model, load_model, Sequential 18 from sklearn.metrics import confusion_matrix, classification_report 19 from keras.preprocessing.image import ImageDataGenerator 20 from keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Activation, Dropout, BatchNormalization 21 22 print ('modules loaded111') 23 24 25 def define_paths(dir): 26 filepaths = [] 27 labels = [] 28 folds = os.listdir(dir) 29 for fold in folds: 30 foldpath = os.path.join(dir, fold) 31 filelist = os.listdir(foldpath) 32 for file in filelist: 33 fpath = os.path.join(foldpath, file) 34 filepaths.append(fpath) 35 labels.append(fold) 36 return filepaths, labels 37 38 def define_df(files, classes): 39 Fseries = pd.Series(files, name= 'filepaths') 40 Lseries = pd.Series(classes, name='labels') 41 return pd.concat([Fseries, Lseries], axis= 1) 42 43 def create_df(tr_dir, ts_dir): 44 # train dataframe 45 files, classes = define_paths(tr_dir) 46 train_df = define_df(files, classes) 47 48 # test dataframe 49 files, classes = define_paths(ts_dir) 50 test_df = define_df(files, classes) 51 return train_df, test_df 52 53 54 def create_gens(train_df, test_df, batch_size): 55 img_size = (224, 224) 56 channels = 3 57 img_shape = (img_size[0], img_size[1], channels) 58 ts_length = len(test_df) 59 test_batch_size = test_batch_size = max(sorted([ts_length // n for n in range(1, ts_length + 1) if ts_length%n == 0 and ts_length/n <= 80])) 60 test_steps = ts_length // test_batch_size 61 def scalar(img): 62 return img 63 tr_gen = ImageDataGenerator(preprocessing_function= scalar, horizontal_flip= True) 64 ts_gen = ImageDataGenerator(preprocessing_function= scalar) 65 train_gen = tr_gen.flow_from_dataframe( train_df, x_col= 'filepaths', y_col= 'labels', target_size= img_size, class_mode= 'categorical', 66 color_mode= 'rgb', shuffle= True, batch_size= batch_size) 67 68 test_gen = ts_gen.flow_from_dataframe( test_df, x_col= 'filepaths', y_col= 'labels', target_size= img_size, class_mode= 'categorical', 69 color_mode= 'rgb', shuffle= False, batch_size= test_batch_size) 70 return train_gen, test_gen 71 72 73 def show_images(gen): 74 g_dict = gen.class_indices # defines dictionary {'class': index} 75 classes = list(g_dict.keys()) # defines list of dictionary's kays (classes) 76 images, labels = next(gen) # get a batch size samples from the generator 77 plt.figure(figsize= (20, 20)) 78 length = len(labels) # length of batch size 79 sample = min(length, 25) # check if sample less than 25 images 80 for i in range(sample): 81 plt.subplot(5, 5, i + 1) 82 image = images[i] / 255 # scales data to range (0 - 255) 83 plt.imshow(image) 84 index = np.argmax(labels[i]) # get image index 85 class_name = classes[index] # get class of image 86 plt.title(class_name, color= 'blue', fontsize= 12) 87 plt.axis('off') 88 plt.show() 89 90 91 92 ### Define a class for custom callback 93 class MyCallback(keras.callbacks.Callback): 94 def __init__(self, model, base_model, patience, stop_patience, threshold, factor, batches, initial_epoch, epochs): 95 super(MyCallback, self).__init__() 96 self.model = model 97 self.base_model = base_model 98 self.patience = patience # specifies how many epochs without improvement before learning rate is adjusted 99 self.stop_patience = stop_patience # specifies how many times to adjust lr without improvement to stop training 100 self.threshold = threshold # specifies training accuracy threshold when lr will be adjusted based on validation loss 101 self.factor = factor # factor by which to reduce the learning rate 102 self.batches = batches # number of training batch to runn per epoch 103 self.initial_epoch = initial_epoch 104 self.epochs = epochs 105 # callback variables 106 self.count = 0 # how many times lr has been reduced without improvement 107 self.stop_count = 0 108 self.best_epoch = 1 # epoch with the lowest loss 109 self.initial_lr = float(tf.keras.backend.get_value(model.optimizer.lr)) # get the initial learning rate and save it 110 self.highest_tracc = 0.0 # set highest training accuracy to 0 initially 111 self.lowest_vloss = np.inf # set lowest validation loss to infinity initially 112 self.best_weights = self.model.get_weights() # set best weights to model's initial weights 113 self.initial_weights = self.model.get_weights() # save initial weights if they have to get restored 114 115 # Define a function that will run when train begins 116 def on_train_begin(self, logs= None): 117 msg = '{0:^8s}{1:^10s}{2:^9s}{3:^9s}{4:^9s}{5:^9s}{6:^9s}{7:^10s}{8:10s}{9:^8s}'.format('Epoch', 'Loss', 'Accuracy', 'V_loss', 'V_acc', 'LR', 'Next LR', 'Monitor','% Improv', 'Duration') 118 print(msg) 119 self.start_time = time.time() 120 121 def on_train_end(self, logs= None): 122 stop_time = time.time() 123 tr_duration = stop_time - self.start_time 124 hours = tr_duration // 3600 125 minutes = (tr_duration - (hours * 3600)) // 60 126 seconds = tr_duration - ((hours * 3600) + (minutes * 60)) 127 msg = f'training elapsed time was {str(hours)} hours, {minutes:4.1f} minutes, {seconds:4.2f} seconds)' 128 print(msg) 129 self.model.set_weights(self.best_weights) # set the weights of the model to the best weights 130 131 def on_train_batch_end(self, batch, logs= None): 132 acc = logs.get('accuracy') * 100 # get batch accuracy 133 loss = logs.get('loss') 134 msg = '{0:20s}processing batch {1:} of {2:5s}- accuracy= {3:5.3f} - loss: {4:8.5f}'.format(' ', str(batch), str(self.batches), acc, loss) 135 print(msg, '\r', end= '') # prints over on the same line to show running batch count 136 137 def on_epoch_begin(self, epoch, logs= None): 138 self.ep_start = time.time() 139 140 # Define method runs on the end of each epoch 141 def on_epoch_end(self, epoch, logs= None): 142 ep_end = time.time() 143 duration = ep_end - self.ep_start 144 145 lr = float(tf.keras.backend.get_value(self.model.optimizer.lr)) # get the current learning rate 146 current_lr = lr 147 acc = logs.get('accuracy') # get training accuracy 148 v_acc = logs.get('val_accuracy') # get validation accuracy 149 loss = logs.get('loss') # get training loss for this epoch 150 v_loss = logs.get('val_loss') # get the validation loss for this epoch 151 152 if acc < self.threshold: # if training accuracy is below threshold adjust lr based on training accuracy 153 monitor = 'accuracy' 154 if epoch == 0: 155 pimprov = 0.0 156 else: 157 pimprov = (acc - self.highest_tracc ) * 100 / self.highest_tracc # define improvement of model progres 158 159 if acc > self.highest_tracc: # training accuracy improved in the epoch 160 self.highest_tracc = acc # set new highest training accuracy 161 self.best_weights = self.model.get_weights() # training accuracy improved so save the weights 162 self.count = 0 # set count to 0 since training accuracy improved 163 self.stop_count = 0 # set stop counter to 0 164 if v_loss < self.lowest_vloss: 165 self.lowest_vloss = v_loss 166 self.best_epoch = epoch + 1 # set the value of best epoch for this epoch 167 168 else: 169 # training accuracy did not improve check if this has happened for patience number of epochs 170 # if so adjust learning rate 171 if self.count >= self.patience - 1: # lr should be adjusted 172 lr = lr * self.factor # adjust the learning by factor 173 tf.keras.backend.set_value(self.model.optimizer.lr, lr) # set the learning rate in the optimizer 174 self.count = 0 # reset the count to 0 175 self.stop_count = self.stop_count + 1 # count the number of consecutive lr adjustments 176 self.count = 0 # reset counter 177 if v_loss < self.lowest_vloss: 178 self.lowest_vloss = v_loss 179 else: 180 self.count = self.count + 1 # increment patience counter 181 182 else: # training accuracy is above threshold so adjust learning rate based on validation loss 183 monitor = 'val_loss' 184 if epoch == 0: 185 pimprov = 0.0 186 else: 187 pimprov = (self.lowest_vloss - v_loss ) * 100 / self.lowest_vloss 188 if v_loss < self.lowest_vloss: # check if the validation loss improved 189 self.lowest_vloss = v_loss # replace lowest validation loss with new validation loss 190 self.best_weights = self.model.get_weights() # validation loss improved so save the weights 191 self.count = 0 # reset count since validation loss improved 192 self.stop_count = 0 193 self.best_epoch = epoch + 1 # set the value of the best epoch to this epoch 194 else: # validation loss did not improve 195 if self.count >= self.patience - 1: # need to adjust lr 196 lr = lr * self.factor # adjust the learning rate 197 self.stop_count = self.stop_count + 1 # increment stop counter because lr was adjusted 198 self.count = 0 # reset counter 199 tf.keras.backend.set_value(self.model.optimizer.lr, lr) # set the learning rate in the optimizer 200 else: 201 self.count = self.count + 1 # increment the patience counter 202 if acc > self.highest_tracc: 203 self.highest_tracc = acc 204 205 msg = f'{str(epoch + 1):^3s}/{str(self.epochs):4s} {loss:^9.3f}{acc * 100:^9.3f}{v_loss:^9.5f}{v_acc * 100:^9.3f}{current_lr:^9.5f}{lr:^9.5f}{monitor:^11s}{pimprov:^10.2f}{duration:^8.2f}' 206 print(msg) 207 208 if self.stop_count > self.stop_patience - 1: # check if learning rate has been adjusted stop_count times with no improvement 209 msg = f' training has been halted at epoch {epoch + 1} after {self.stop_patience} adjustments of learning rate with no improvement' 210 print(msg) 211 self.model.stop_training = True # stop training 212 213 214 def plot_training(hist): 215 tr_acc = hist.history['accuracy'] 216 tr_loss = hist.history['loss'] 217 val_acc = hist.history['val_accuracy'] 218 val_loss = hist.history['val_loss'] 219 index_loss = np.argmin(val_loss) # get number of epoch with the lowest validation loss 220 val_lowest = val_loss[index_loss] # get the loss value of epoch with the lowest validation loss 221 index_acc = np.argmax(val_acc) # get number of epoch with the highest validation accuracy 222 acc_highest = val_acc[index_acc] # get the loss value of epoch with the highest validation accuracy 223 224 plt.figure(figsize= (20, 8)) 225 plt.style.use('fivethirtyeight') 226 Epochs = [i+1 for i in range(len(tr_acc))] # create x-axis by epochs count 227 loss_label = f'best epoch= {str(index_loss + 1)}' # label of lowest val_loss 228 acc_label = f'best epoch= {str(index_acc + 1)}' # label of highest val_accuracy 229 plt.subplot(1, 2, 1) 230 plt.plot(Epochs, tr_loss, 'r', label= 'Training loss') 231 plt.plot(Epochs, val_loss, 'g', label= 'Validation loss') 232 plt.scatter(index_loss + 1, val_lowest, s= 150, c= 'blue', label= loss_label) 233 plt.title('Training and Validation Loss') 234 plt.xlabel('Epochs') 235 plt.ylabel('Loss') 236 plt.legend() 237 plt.subplot(1, 2, 2) 238 plt.plot(Epochs, tr_acc, 'r', label= 'Training Accuracy') 239 plt.plot(Epochs, val_acc, 'g', label= 'Validation Accuracy') 240 plt.scatter(index_acc + 1 , acc_highest, s= 150, c= 'blue', label= acc_label) 241 plt.title('Training and Validation Accuracy') 242 plt.xlabel('Epochs') 243 plt.ylabel('Accuracy') 244 plt.legend() 245 plt.tight_layout 246 plt.show() 247 248 249 250 def plot_confusion_matrix(cm, classes, normalize= False, title= 'Confusion Matrix', cmap= plt.cm.Blues): 251 plt.figure(figsize= (10, 10)) 252 plt.imshow(cm, interpolation= 'nearest', cmap= cmap) 253 plt.title(title) 254 plt.colorbar() 255 tick_marks = np.arange(len(classes)) 256 plt.xticks(tick_marks, classes, rotation= 45) 257 plt.yticks(tick_marks, classes) 258 if normalize: 259 cm = cm.astype('float') / cm.sum(axis= 1)[:, np.newaxis] 260 print('Normalized Confusion Matrix') 261 else: 262 print('Confusion Matrix, Without Normalization') 263 print(cm) 264 thresh = cm.max() / 2. 265 for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])): 266 plt.text(j, i, cm[i, j], horizontalalignment= 'center', color= 'white' if cm[i, j] > thresh else 'black') 267 plt.tight_layout() 268 plt.ylabel('True Label') 269 plt.xlabel('Predicted Label') 270 271 272 # Get Dataframes 273 train_dir = r'train' 274 test_dir = r'test' 275 train_df, test_df = create_df(train_dir, test_dir) 276 277 # Get Generators 278 batch_size = 40 279 train_gen, test_gen = create_gens(train_df, test_df, batch_size) 280 281 show_images(train_gen) 282 283 # Create Model Structure 284 img_size = (224, 224) 285 channels = 3 286 img_shape = (img_size[0], img_size[1], channels) 287 class_count = len(list(train_gen.class_indices.keys())) # to define number of classes in dense layer 288 289 # create pre-trained model 290 base_model = tf.keras.applications.efficientnet.EfficientNetB3(include_top= False, weights= "imagenet", input_shape= img_shape, pooling= 'max') 291 292 model = Sequential([ 293 base_model, 294 BatchNormalization(axis= -1, momentum= 0.99, epsilon= 0.001), 295 Dense(256, kernel_regularizer= regularizers.l2(l= 0.016), activity_regularizer= regularizers.l1(0.006), 296 bias_regularizer= regularizers.l1(0.006), activation= 'relu'), 297 Dropout(rate= 0.45, seed= 123), 298 Dense(class_count, activation= 'softmax') 299 ]) 300 301 model.compile(Adamax(learning_rate= 0.001), loss= 'categorical_crossentropy', metrics= ['accuracy']) 302 303 model.summary() 304 305 306 batch_size = 40 307 epochs = 40 308 patience = 1 # number of epochs to wait to adjust lr if monitored value does not improve 309 stop_patience = 3 # number of epochs to wait before stopping training if monitored value does not improve 310 threshold = 0.9 # if train accuracy is < threshold adjust monitor accuracy, else monitor validation loss 311 factor = 0.5 # factor to reduce lr by 312 freeze = False # if true free weights of the base model 313 batches = int(np.ceil(len(train_gen.labels) / batch_size)) 314 315 callbacks = [MyCallback(model= model, base_model= base_model, patience= patience, 316 stop_patience= stop_patience, threshold= threshold, factor= factor, 317 batches= batches, initial_epoch= 0, epochs= epochs)] 318 319 320 321 history = model.fit(x= train_gen, epochs= epochs, verbose= 0, callbacks= callbacks, 322 validation_data= test_gen, validation_steps= None, shuffle= False, 323 initial_epoch= 0) 324 325 326 plot_training(history) 327 328 329 ts_length = len(test_df) 330 test_batch_size = test_batch_size = max(sorted([ts_length // n for n in range(1, ts_length + 1) if ts_length%n == 0 and ts_length/n <= 80])) 331 test_steps = ts_length // test_batch_size 332 train_score = model.evaluate(train_gen, steps= test_steps, verbose= 1) 333 test_score = model.evaluate(test_gen, steps= test_steps, verbose= 1) 334 335 print("Train Loss: ", train_score[0]) 336 print("Train Accuracy: ", train_score[1]) 337 print('-' * 20) 338 print("Test Loss: ", test_score[0]) 339 print("Test Accuracy: ", test_score[1]) 340 341 342 preds = model.predict_generator(test_gen) 343 y_pred = np.argmax(preds, axis=1) 344 345 346 target_names = ['Apples', 'Tomatoes'] 347 # Confusion matrix 348 cm = confusion_matrix(test_gen.classes, y_pred) 349 plot_confusion_matrix(cm= cm, classes= target_names, title = 'Confusion Matrix') 350 # Classification report 351 print(classification_report(test_gen.classes, y_pred, target_names= target_names)) 352 353 354 class_dict = train_gen.class_indices 355 save_path = '' 356 height = [] 357 width = [] 358 for _ in range(len(class_dict)): 359 height.append(img_size[0]) 360 width.append(img_size[1]) 361 362 Index_series = pd.Series(list(class_dict.values()), name= 'class_index') 363 Class_series = pd.Series(list(class_dict.keys()), name= 'class') 364 Height_series = pd.Series(height, name= 'height') 365 Width_series = pd.Series(width, name= 'width') 366 class_df = pd.concat([Index_series, Class_series, Height_series, Width_series], axis= 1) 367 subject = 'Apples-Tomatoes-Classification' 368 csv_name = f'{subject}-class_dict.csv' 369 csv_save_loc = os.path.join(save_path, csv_name) 370 class_df.to_csv(csv_save_loc, index= False) 371 print(f'class csv file was saved as {csv_save_loc}')

