总结---持更
myjf
1.自动化用例如何保持稳定性
https://www.jianshu.com/p/78163813f7a6
https://blog.csdn.net/wanglha/article/category/3069295
一、装饰器与出错重试机制保证稳定性
二、测试用例分层机制保证可维护性
三,等待
1.直接sleep
2.使用selenium webdriver提供的等待方法
driver.manage().timeouts().implicitlyWait(10,TimeUnit.Seconds);
3.使用webDriver提供的wait<T>接口
FluentWait<T> implements Wait<T>
Wait<WebDriver> wait = new FluentWait<WebDriver>(driver)
.withTimeout(30, SECONDS)
.pollingEvery(5, SECONDS)
.ignoring(NoSuchElementException.class);
WebElement element = wait.until(new Function<WebDriver, WebElement>() {
public WebElement apply(WebDriver driver) {
return driver.findElement(By.id("element"));
}
});
element.click();//something to do
此方法用于等待一个元素在页面上出现,超时时间为30S,每隔5S去请求一次,并且忽略掉until中抛出的NoSuchElementException。
单个校验每个元素,或者每个页面,减少依赖
2.jsf给予dubbo做的封装
3.hashmap在并发下是线程安全的吗
不是,hashtable是线程安全的
4.数据库主键
1.什么是主键
表中的每一行都应该具有可以唯一标识自己的一列(或一组列)。而这个承担标识作用的列称为主键。
如果没有主键,数据的管理将会十分混乱。比如会存在多条一模一样的记录,删除和修改特定行十分困难。
2.那些列可以作为主键:
任何列都可以作为主键,只要它满足以下条件:
• 任何两行都不具有相同的主键值。就是说这列的值都是互不相同的。
• 每个行都必须具有一个主键值。主键列不允许设置为NULL。
• 主键列的值不建议进行修改和更新。
5.设计接口测试用例,如何验证结果
6.对项目进度的把控
7.手工测试和自动化测试如何平衡
8.代码覆盖率
jacoco,emma,cobertura,clover
9.自动化用例做没做过多线程
10.jvm内存分区,gc
程序计数器 JVM支持多个线程同时运行,当每一个新线程被创建时,它都将得到它自己的pc寄存器(程序计数器)。
java栈(自动分配连续的空间,后进先出) 存放:局部变量
Java堆(不连续) 存放:new出的对象
方法区(也是堆)存放:类的信息(代码),static变量,常量池(字符串常量)等
本地方法栈:主要存放native的方法
gc(垃圾回收机制):
1.对象空间的分配:使用new关键字创建对象即可
2.对象空间的释放:将对象赋值null即可。垃圾回收器将负责回收所有“不可达”对象的内存空间
要点:程序员无权调用垃圾回收器
程序员可以通过system.gc(),通过gc运行,但是java规范并不能保证立即运行
finalize方法,是java提供给程序员用来释放对象或资源的方法,但尽量少用。
垃圾回收是编程时不需要考虑内存管理,可以有效的方式内存泄漏,有效的使用可以使用的内存。
垃圾回收器通常是作为一个单独的低级别的线程运行,不可预知的情况下对内存堆中已经死亡的或者长时间没有使用的对象进行清除和回收。
回收机制:Mark-Sweep(标记-清除)算法,Copying(复制)算法,Mark-Compact(标记-整理)算法,Generational Collection(分代收集)算法
11.a,b两个方法,a方法调用b的方法,b的注解没有生效的原因是什么?
使用Spring Aop注解的时候,如@Transactional, @Cacheable等注解一般需要在类方法第一个入口的地方加,不然不会生效。
https://segmentfault.com/a/1190000014346303?utm_source=tag-newest
b方法是在a内部调用的,调用a方法是,spring内部其实是代理类proxy的invoke,这个时候已经不再代理对象中操作了,由于b方法是在a方法内部调用的,所以这里实际调用的是method的真实对象,并不是代理对象,所以导致b的缓存注解没有生效。
https://blog.csdn.net/ZL_LSY/article/details/86542481
@Transactional 加于private方法, 无效
@Transactional 加于未加入接口的public方法, 再通过普通接口方法调用, 无效
@Transactional 加于接口方法, 无论下面调用的是private或public方法, 都有效
@Transactional 加于接口方法后, 被本类普通接口方法直接调用, 无效
@Transactional 加于接口方法后, 被本类普通接口方法通过接口调用, 有效
@Transactional 加于接口方法后, 被它类的接口方法调用, 有效
@Transactional 加于接口方法后, 被它类的私有方法调用后, 有效
12.hashmap是无序的,怎么校验结果的正确性?
linkedHashMap是有序的
13.契约测试
契约测试也叫消费者驱动测试。
两个角色:消费者(Consumer)和 生产者(Provider)
一个思想:需求驱动(消费者驱动)
契约文件:由Consumer端和Provider端共同定义的规范,包含API路径,输入,输出。通常由Consumber生成。
实现原理:Consumer 端提供一个类似“契约”的东西(如json 文件,约定好request和response)交给Provider 端,告诉Provider 有什么需求,然后Provider 根据这份“契约”去实现。
14.jmeter并发,测试数据准备,测试数据清除
15.mysql锁
https://www.cnblogs.com/leedaily/p/8378779.html
锁是计算机协调多个进程或线程并发访问某一资源的机制。
相对其他数据库而言,MySQL的锁机制比较简单,其最显著的特点是不同的存储引擎支持不同的锁机制。比如,
MyISAM和MEMORY存储引擎采用的是表级锁(table-level locking)。
InnoDB存储引擎既支持行级锁(row-level locking),也支持表级锁,但默认情况下是采用行级锁。
- 表级锁:每次操作锁住整张表。开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低;
- 行级锁:每次操作锁住一行数据。开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高;
- 页面锁:开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般。
16.mysql索引
mysql的索引分为单列索引(主键索引,唯索引,普通索引)和组合索引.
单列索引:一个索引只包含一个列,一个表可以有多个单列索引.
组合索引:一个组合索引包含两个或两个以上的列,
1.单列索引
1-1) 普通索引,这个是最基本的索引,
其sql格式是 CREATE INDEX IndexName ON `TableName`(`字段名`(length)) 或者 ALTER TABLE TableName ADD INDEX IndexName(`字段名`(length))
第一种方式 :
CREATE INDEX account_Index ON `award`(`account`);
第二种方式:
ALTER TABLE award ADD INDEX account_Index(`account`)
1-2) 唯一索引,与普通索引类似,但是不同的是唯一索引要求所有的类的值是唯一的,这一点和主键索引一样.但是他允许有空值,
其sql格式是 CREATE UNIQUE INDEX IndexName ON `TableName`(`字段名`(length)); 或者 ALTER TABLE TableName ADD UNIQUE (column_list)
CREATE UNIQUE INDEX account_UNIQUE_Index ON `award`(`account`);
1-3) 主键索引,不允许有空值,(在B+TREE中的InnoDB引擎中,主键索引起到了至关重要的地位)
主键索引建立的规则是 int优于varchar,一般在建表的时候创建,最好是与表的其他字段不相关的列或者是业务不相关的列.一般会设为 int 而且是 AUTO_INCREMENT自增类型的
2.组合索引
一个表中含有多个单列索引不代表是组合索引,通俗一点讲 组合索引是:包含多个字段但是只有索引名称
其sql格式是 CREATE INDEX IndexName On `TableName`(`字段名`(length),`字段名`(length),...);
CREATE INDEX nickname_account_createdTime_Index ON `award`(`nickname`, `account`, `created_time`);
(3)全文索引
文本字段上(text)如果建立的是普通索引,那么只有对文本的字段内容前面的字符进行索引,其字符大小根据索引建立索引时申明的大小来规定.
如果文本中出现多个一样的字符,而且需要查找的话,那么其条件只能是 where column lick '%xxxx%' 这样做会让索引失效
.这个时候全文索引就祈祷了作用了
ALTER TABLE tablename ADD FULLTEXT(column1, column2)
有了全文索引,就可以用SELECT查询命令去检索那些包含着一个或多个给定单词的数据记录了。
ELECT * FROM tablename WHERE MATCH(column1, column2) AGAINST(‘xxx′, ‘sss′, ‘ddd′)
这条命令将把column1和column2字段里有xxx、sss和ddd的数据记录全部查询出来。
(二)索引的删除
删除索引的mysql格式 :DORP INDEX IndexName ON `TableName`
17.spring ioc/aop
18.java内存
19.数组和链表有什么区别
数组是将元素在内存中连续存放,由于每个元素占用内存相同,可以通过下标迅速访问数组中任何元素。但是如果要在数组中增加一个元素,需要移动大量元素,在内存中空出一个元素的空间,然后将要增加的元素放在其中。同样的道理,如果想删除一个元素,同样需要移动大量元素去填掉被移动的元素。如果应用需要快速访问数据,很少插入和删除元素,就应该用数组。
链表中的元素在内存中不是顺序存储的,而是通过存在元素中的指针联系到一起,每个结点包括两个部分:一个是存储数据元素 的数据域,另一个是存储下一个结点地址的 指针。如果要访问链表中一个元素,需要从第一个元素始,一直找到需要的元素位置。但是增加和删除一个元素对于链表数据结构就非常简单了,只要修改元素中的指针就可以了。如果应用需要经常插入和删除元素你就需要用链表
区别:
(1)存储位置上:
数组逻辑上相邻的元素在物理存储位置上也相邻,而链表不一定;
(2)存储空间上:
链表存放的内存空间可以是连续的,也可以是不连续的,数组则是连续的一段内存空间。一般情况下存放相同多的数据数组占用较小的内存,而链表还需要存放其前驱和后继的空间。
(3)长度的可变性:
链表的长度是按实际需要可以伸缩的,而数组的长度是在定义时要给定的,如果存放的数据个数超过了数组的初始大小,则会出现溢出现象。
(4)按序号查找时,数组可以随机访问,时间复杂度为O(1),而链表不支持随机访问,平均需要O(n);
(5)按值查找时,若数组无序,数组和链表时间复杂度均为O(1),但是当数组有序时,可以采用折半查找将时间复杂度降为O(logn);
(6)插入和删除时,数组平均需要移动n/2个元素,而链表只需修改指针即可;
(7)空间分配方面:
数组在静态存储分配情形下,存储元素数量受限制,动态存储分配情形下,虽然存储空间可以扩充,但需要移动大量元素,导致操作效率降低,而且如果内存中没有更大块连续存储空间将导致分配失败; 即数组从栈中分配空间,,对于程序员方便快速,但自由度小。链表存储的节点空间只在需要的时候申请分配,只要内存中有空间就可以分配,操作比较灵活高效;即链表从堆中分配空间, 自由度大但申请管理比较麻烦。
20.selenium框架封装
21.性能测试
22.灰度测试
23.业务开关
aiqiyi
1.数组从高到低排序,去重
2.sql多表查询
3.selenium
4.单元测试,sonar发现什么问题
zhihu
1.数组,求字符串最长前缀
2.开发框架
sogou
1.给定机器数量,怎么计算出瓶颈
2.给一段代码,找错误
3,回文字符串
4.http接口 用代码实现请求 处理返回值
https://blog.csdn.net/u013310119/article/details/82705317
5.设计测试用例
6.nginx停启命令
查看进程号,ps -ef | grep nginx
杀死进程 kill -QUIT 2202 从容停止nginx
kill -TERM 2202 快速停止nginx
pkill -9 nginx 强制停止nginx
启动 nginx -c /usr/local/nginx/conf/nginx.conf
7.按端口号杀死进程
ps -ef | grep 进程名
kill -9 进程id
8.用例设计
9.性格分析
10.线段有n个点,起始点s,终点t,遍历点,从s到t,每个点访问一次,可以实现跳跃到1节点或者尾节点,问最少跳跃几次可以实现遍历?
11.string+拼接问题,stringBuffer ,stringBuilder区别
string 字符串常量 string是不可变的对象,经常使用对系统性能有影响 适用于少量字符串操作情况
stringBuffer 字符串变量(线程安全) 适用于单线程下在字符缓冲区进行大量操作的情况
stringBuilder 字符串变量(非线程安全) 适用于多线程下大量字符缓冲区进行大量操作的情况
运行速度:stringBuilder>stringBuffer>string
12.cookie session
cookie 和session 的区别:
1、cookie数据存放在客户的浏览器上,session数据放在服务器上。
2、cookie不是很安全,别人可以分析存放在本地的COOKIE并进行COOKIE欺骗
考虑到安全应当使用session。
3、session会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能
考虑到减轻服务器性能方面,应当使用COOKIE。
4、单个cookie保存的数据不能超过4K,很多浏览器都限制一个站点最多保存20个cookie。
5、所以个人建议:
将登陆信息等重要信息存放为SESSION
其他信息如果需要保留,可以放在COOKIE中
.cookie/session的区别与联系
区别:
1.cookie存放在客户端,session存放在服务器端。
2.cookie只能存放4k的数据,而session理论上没有做限制
联系:
session虽说存放在服务器端,但是仔细看刚才的执行流程你会明白,session是依赖于cookie的
其他:
1.两个int变量不用第三个变量的情况下,怎么做数据交换
int a,b;
a = a+b;
b = a-b;
a = a-b;
yuanfudao
1.字符串,横版改成竖版输出
2.括号匹配
3.链表删除奇树节点
4.gc
5.项目中印象深的点
6.linux 命令
查询字符串重复次数
grep -o objstr filename | wc -l
grep -o 'objstr1 |\| objstr2' filename | wc -l
awk '{s+=gsub(/targetStr/,"女")}END{print s}' filename
yingshidaquan227
1.设计模式
单例模式
2.编写用例
3.spring mvc路由
4.网络协议
baidu
1.快排
2.1000万条信息,查找重复最多的前四条
方法1:可以用哈希表的方法对1千万条分成若干组进行边扫描边建散列表。第一次扫描,取首字节,尾字节,中间随便两字节作为Hash Code,插入到hash table中。并记录其地址和信息长度和重复次数,1千万条信息,记录这几个信息还放得下。同Hash Code且等长就疑似相同,比较一下。相同记录只加1次进hash table,但将重复次数加1。一次扫描以后,已经记录各自的重复次数,进行第二次hash table的处理。用线性时间选择可在O(n)的级别上完成前10条的寻找。分组后每份中的top10必须保证各不相同,可hash来保证,也可直接按hash值的大小来分类。
方法2:可以采用从小到大排序的方法,根据经验,除非是群发的过节短信,否则字数越少的短信出现重复的几率越高。建议从字数少的短信开始找起,比如一开始搜一个字的短信,找出重复出现的top10并分别记录出现次数,然后搜两个字的,依次类推。对于对相同字数的比较常的短信的搜索,除了hash之类的算法外,可以选择只抽取头、中和尾等几个位置的字符进行粗判,因为此种判断方式是为了加快查找速度但未能得到真正期望的top10,因此需要做标记;如此搜索一遍后,可以从各次top10结果中找到备选的top10,如果这top10中有刚才做过标记的,则对其对应字数的所有短信进行精确搜索以找到真正的top10并再次比较。
方法3:可以采用内存映射的办法,首先1千万条短信按现在的短信长度将不会超过1G空间,使用内存映射文件比较合适。可以一次映射(当然如果更大的数据量的话,可以采用分段映射),由于不需要频繁使用文件I/O和频繁分配小内存,这将大大提高数据的加载速度。其次,对每条短信的第i(i从0到70)个字母按ASCII嘛进行分组,其实也就是创建树。i是树的深度,也是短信第i个字母。
该问题主要是解决两方面的内容,一是内容加载,二是短信内容比较。采用文件内存映射技术可以解决内容加载的性能问题(不仅仅不需要调用文件I/O函数,而且也不需要每读出一条短信都分配一小块内存),而使用树技术可以有效减少比较的次数。
https://blog.csdn.net/u010601183/article/details/56481868/
3.自动化
yiqijiaoyu
1.ui框架了解多少?
2.接口测试怎么做的
3.短信验证码一小时失效,缓存,编写测试用例
4.post接口,编写接口测试用例
5.冒泡排序
6.开发测试工作占比,人数占比
7.你觉得什么工作是真正提效的?
58jinrong
1.list查a字符的数
2.hashmap遍历
public static void main(String[] args){
Map<String,String> map = new HashMap<String, String>();
map.put("1","a");
map.put("2","b");
map.put("3","c");
//最简洁,最通用的遍历方式
for (Map.Entry<String,String> entry : map.entrySet()){
System.out.println("key: " + entry.getKey() + "value: " + entry.getValue());
}
}
3.mapper动态 如果a ,b不为空查对应,如果a,b为空查所有
<select id="selectResult"> resultMap="testMap">
select * from table
where
<if a != null and b != null>
a=#{a} AND b=#{b}
</if>
</select>
4.提供了一个http接口
5.ui做到什么程度,写了多少条用例,有拖拽和滚动吗,有h5页面吗
6.接口写了多少用例
7.客户端有接触吗
8.post接口怎么测
9.跨域怎么实现
meiriyouxian
1.string stringBuffer stringBuilder 区别,具体拼接怎么做
2.string,求每个字符重复的次数,返货top3
3.单例模式有几种写法,哪种是线程安全的,哪种是线程不安全的
懒汉 线程不安全 饿汉 线程安全
4.new的时候是调了类的什么方法? 构造器方法
5.作用域及其范围
6.testNG before test ,before class,before method区别
junit before作用范围
@BeforeSuite:注解的方法,将会在testng定义的xml根元素里面的所有执行之前运行
@BeforeClass:注解的方法将会在当前测试类的第一个测试方法执行之前运行。
@BeforeTest:注解的方法将会在一个元素定义的所有里面所有测试方法执行之前运行。
@BeforeMethod:注解的方法将每个测试方法之前运行。
junit:
- @Before – 表示在任意使用@Test注解标注的public void方法执行之前执行
- @BeforeClass – 表示在类中的任意public static void方法执行之前执行
- @Test – 使用该注解标注的public void方法会表示为一个测试方法
7.spring aop
8.过滤器和拦截器顺序
1、过滤器(Filter)
首先说一下Filter的使用地方,我们在配置web.xml时,总会配置下面一段设置字符编码,不然会导致乱码问题:
1)过滤器(Filter):它依赖于servlet容器。在实现上,基于函数回调,它可以对几乎所有请求进行过滤,但是缺点是一个过滤器实例只能在容器初始化时调用一次。使用过滤器的目的,是用来做一些过滤操作,获取我们想要获取的数据,比如:在Javaweb中,对传入的request、response提前过滤掉一些信息,或者提前设置一些参数,然后再传入servlet或者Controller进行业务逻辑操作。通常用的场景是:在过滤器中修改字符编码(CharacterEncodingFilter)、在过滤器中修改HttpServletRequest的一些参数(XSSFilter(自定义过滤器)),如:过滤低俗文字、危险字符等。
2、拦截器(Interceptor)
拦截器的配置一般在SpringMVC的配置文件中,使用Interceptors标签,具体配置如下:
(2)拦截器(Interceptor):它依赖于web框架,在SpringMVC中就是依赖于SpringMVC框架。在实现上,基于Java的反射机制,属于面向切面编程(AOP)的一种运用,就是在service或者一个方法前,调用一个方法,或者在方法后,调用一个方法,比如动态代理就是拦截器的简单实现,在调用方法前打印出字符串(或者做其它业务逻辑的操作),也可以在调用方法后打印出字符串,甚至在抛出异常的时候做业务逻辑的操作。由于拦截器是基于web框架的调用,因此可以使用Spring的依赖注入(DI)进行一些业务操作,同时一个拦截器实例在一个controller生命周期之内可以多次调用。但是缺点是只能对controller请求进行拦截,对其他的一些比如直接访问静态资源的请求则没办法进行拦截处理。
(1)、Filter需要在web.xml中配置,依赖于Servlet;
(2)、Interceptor需要在SpringMVC中配置,依赖于框架;
(3)、Filter的执行顺序在Interceptor之前,具体的流程见下图
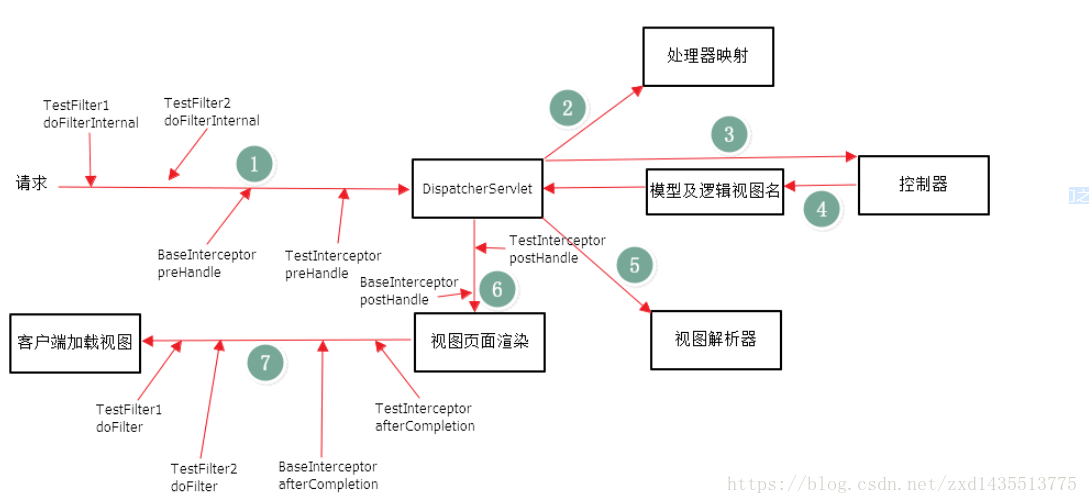
拦截器与过滤器的区别:
拦截器是基于java的反射机制的,而过滤器是基于函数回调。
拦截器不依赖与servlet容器,过滤器依赖与servlet容器。
拦截器只能对action请求起作用,而过滤器则可以对几乎所有的请求起作用。
拦截器可以访问action上下文、值栈里的对象,而过滤器不能访问。
在action的生命周期中,拦截器可以多次被调用,而过滤器只能在容器初始化时被调用一次
执行顺序:过滤前 – 拦截前 – Action处理 – 拦截后 – 过滤后。个人认为过滤是一个横向的过程,首先把客户端提交的内容进行过滤(例如未登录用户不能访问内部页面的处理);过滤通过后,拦截器将检查用户提交数据的验证,做一些前期的数据处理,接着把处理后的数据发给对应的Action;Action处理完成返回后,拦截器还可以做其他过程(还没想到要做啥),再向上返回到过滤器的后续操作。
9.接口能继承类和抽象类吗,抽象类能继承类吗
接口不能继承类 ,接口可以继承多个接口,类可以实现接口
抽象类可以继承实体类,抽象类可以实现接口
10.mock怎么做的
2.27 kuaishou
1.编程题:两个已排序的数组合并并排序
2.编程题:判断两个app版本哪个比较大
3.java四大特性
封装:
属性可用来描述同一类事物的特征,方法可描述一类事物可做的操作。封装就是把属于同一类事物的共性(包括属性与方法)归到一个类中,以方便使用。
概念:
封装也称为信息隐藏,是指利用抽象数据类型将数据和基于数据的操作封装在一起,使其构成一个不可分割的独立实体,数据被保护在抽象数据类型的内部,尽可能地隐藏内部的细节,只保留一些对外接口使之与外部发生联系。系统的其他部分只有通过包裹在数据外面的被授权的操作来与这个抽象数据类型交流与交互。也就是说,用户无需知道对象内部方法的实现细节,但可以根据对象提供的外部接口(对象名和参数)访问该对象。
好处:
(1)实现了专业的分工。将能实现某一特定功能的代码封装成一个独立的实体后,各程序员可以在需要的时候调用,从而实现了专业的分工。
(2)隐藏信息,实现细节。通过控制访问权限可以将可以将不想让客户端程序员看到的信息隐藏起来,如某客户的银行的密码需要保密,只能对该客户开发权限。
继承:
个性对共性的属性与方法的接受,并加入个性特有的属性与方法
继承后子类自动拥有了父类的属性和方法,但特别注意的是,父类的私有属性和构造方法并不能被继承。
另外子类可以写自己特有的属性和方法,目的是实现功能的扩展,子类也可以复写父类的方法即方法的重写。实际就是多态性
概念:
一个类继承另一个类,则称继承的类为子类,被继承的类为父类。
子类与父类的关系并不是日常生活中的父子关系,子类与父类而是一种特殊化与一般化的关系,是is-a的关系,子类是父类更加详细的分类。如class dog extends animal,就可以理解为dog is a animal.注意设计继承的时候,若要让某个类能继承,父类需适当开放访问权限,遵循里氏代换原则,即向修改关闭对扩展开放,也就是开-闭原则。
好处:
实现代码的复用。
什么是多态
- 面向对象的三大特性:封装、继承、多态。从一定角度来看,封装和继承几乎都是为多态而准备的。这是我们最后一个概念,也是最重要的知识点。
- 多态的定义:指允许不同类的对象对同一消息做出响应。即同一消息可以根据发送对象的不同而采用多种不同的行为方式。(发送消息就是函数调用)
- 实现多态的技术称为:动态绑定(dynamic binding),是指在执行期间判断所引用对象的实际类型,根据其实际的类型调用其相应的方法。
- 多态的作用:消除类型之间的耦合关系。
- 现实中,关于多态的例子不胜枚举。比方说按下 F1 键这个动作,如果当前在 Flash 界面下弹出的就是 AS 3 的帮助文档;如果当前在 Word 下弹出的就是 Word 帮助;在 Windows 下弹出的就是 Windows 帮助和支持。同一个事件发生在不同的对象上会产生不同的结果。
下面是多态存在的三个必要条件,要求大家做梦时都能背出来!
多态存在的三个必要条件
一、要有继承;
二、要有重写;
三、父类引用指向子类对象。
多态的好处:
1.可替换性(substitutability)。多态对已存在代码具有可替换性。例如,多态对圆Circle类工作,对其他任何圆形几何体,如圆环,也同样工作。
2.可扩充性(extensibility)。多态对代码具有可扩充性。增加新的子类不影响已存在类的多态性、继承性,以及其他特性的运行和操作。实际上新加子类更容易获得多态功能。例如,在实现了圆锥、半圆锥以及半球体的多态基础上,很容易增添球体类的多态性。
3.接口性(interface-ability)。多态是超类通过方法签名,向子类提供了一个共同接口,由子类来完善或者覆盖它而实现的。如图8.3 所示。图中超类Shape规定了两个实现多态的接口方法,computeArea()以及computeVolume()。子类,如Circle和Sphere为了实现多态,完善或者覆盖这两个接口方法。
4.灵活性(flexibility)。它在应用中体现了灵活多样的操作,提高了使用效率。
5.简化性(simplicity)。多态简化对应用软件的代码编写和修改过程,尤其在处理大量对象的运算和操作时,这个特点尤为突出和重要。
Java中多态的实现方式:接口实现,继承父类进行方法重写,同一个类中进行方法重载。
4.arraylist和linkedlist区别
ArrayList和LinkedList的大致区别:
1.ArrayList是实现了基于动态数组的数据结构,LinkedList是基于链表结构。
2.对于随机访问的get和set方法,ArrayList要优于LinkedList,因为LinkedList要移动指针。
3.对于新增和删除操作add和remove,LinkedList比较占优势,因为ArrayList要移动数据。
他们在性能上的有缺点:
1.对ArrayList和LinkedList而言,在列表末尾增加一个元素所花的开销都是固定的。对 ArrayList而言,主要是在内部数组中增加一项,指向所添加的元素,偶尔可能会导致对数组重新进行分配;而对LinkedList而言,这个开销是 统一的,分配一个内部Entry对象。
2.在ArrayList集合中添加或者删除一个元素时,当前的列表所所有的元素都会被移动。而LinkedList集合中添加或者删除一个元素的开销是固定的。
3.LinkedList集合不支持 高效的随机随机访问(RandomAccess),因为可能产生二次项的行为。
4.ArrayList的空间浪费主要体现在在list列表的结尾预留一定的容量空间,而LinkedList的空间花费则体现在它的每一个元素都需要消耗相当的空间
所以在我们进行对元素的增删查操作的时候,进行 查操作时用ArrayList,进行增删操作的时候最好用LinkedList。
5.selenium特性,selenium grid
Selenium特点:
对web 页面有良好的支持
简单(API 简单)、灵活(用开发语言驱动)
支持分布式测试用例执行
- 开源软件:源代码开放可以根据需要来增加工具的某些功能
- 跨平台:Linux,windows,mac
- 核心功能:就是可以在多个浏览器上进行自动化测试
- 多语言:java、python、c#、JS、ruby等
- 成熟稳定:目前已经被google、百度、腾讯等公司广泛使用
- 功能强大:能够实现类似商业工具的大部分功能,因为开原性,可实现定制化功能
一,selenium grid是什么?
selenium是一个用于UI自动化测试的工具。
selenium grid是selenium家族中的三大组件的一员。selenium grid有两个版本,grid1和grid2,。目前grid1已经基本被废弃了。grid2的出版要晚于selenium2,所以grid2支持selenium2的所有的功能。
二、为什么要用grid?
1,当我们在selenium webdriver中写好了各种脚本时,我们可能需要在不同的系统里,不同的浏览器下去运行。
2,我们的一个系统,可能有上万条用例需要执行。我们又不希望用例在回归时一条一条被执行,而是希望能够节省时间的批量执行用例。
基于以上两点,我们需要这个强大的组件grid。
三、grid可以做些什么?
1,selenium grid不是用来写脚本代码的,只负责运行。所以我们的脚本还是需要利用webdriver,在我们的开发环境中去写好。
2,selenium grid给我们提供了两个东西。一个叫hub,一个叫node。
3,hub被称为总控节点。他是你加载所有的测试机器,一个grid里面只有一个hub。打个比方:hub就像我们的交换机,他负责接通网线,把网络分发给后面的各种设备,不管我们是用手机上网,还是电脑上网,都是连着我们的交换机。grid中的hub,总管着的是脚本代码。
4,node称之为节点。他就好比我们的连接网络的各个终端设备,比如电脑,比如手机,iPad之类等等。所以grid中,可以有很多个node,node用于接收代码,且在不同的浏览器中运行代码。
6.jmeter特性
利用Jmeter做功能测试有以下优点:
Ø 不依赖于界面,如果服务正常启动,传递参数明确就可以添加测试用例,执行测试
Ø 测试脚本不需要编程,熟悉http请求,熟悉业务流程,就可以根据页面中input对象来编写测试用例。
Ø 测试脚本维护方便,可以将测试脚本复制,并且可以将某一部分单独保存。
Ø 可以跳过页面限制,向后台程序添加非法数据,这样可以测试后台程序的健壮性。
Ø 利用badboy录制测试脚本,可以快速的形成测试脚本
Ø Jmeter断言可以验证代码中是否有需要得到的值
Ø 使用参数化以及Jmeter提供的函数功能,可以快速完成测试数据的添加修改等
利用Jmeter做功能测试有以下缺点:
Ø 使用Jmeter无法验证JS程序,也无法验证页面,所以需要手工去验证。
Ø Jmeter的断言功能不是很强大
Ø 就算是jmeter脚本顺利执行,依旧无法确定程序是否正确执行,有时候需要进入程序查看,或者查看Jmeter的响应数据。
Ø Jmeter脚本的维护需要保存为本地文件,而每个脚本文件只能保存一个测试用例,不利于脚本的维护。
360hr电面:
1.get和post区别
比较 GET 与 POST
下面的表格比较了两种 HTTP 方法:GET 和 POST。
| GET | POST | |
|---|---|---|
| 后退按钮/刷新 | 无害 | 数据会被重新提交(浏览器应该告知用户数据会被重新提交)。 |
| 书签 | 可收藏为书签 | 不可收藏为书签 |
| 缓存 | 能被缓存 | 不能缓存 |
| 编码类型 | application/x-www-form-urlencoded | application/x-www-form-urlencoded 或 multipart/form-data。为二进制数据使用多重编码。 |
| 历史 | 参数保留在浏览器历史中。 | 参数不会保存在浏览器历史中。 |
| 对数据长度的限制 | 是的。当发送数据时,GET 方法向 URL 添加数据;URL 的长度是受限制的(URL 的最大长度是 2048 个字符)。 | 无限制。 |
| 对数据类型的限制 | 只允许 ASCII 字符。 | 没有限制。也允许二进制数据。 |
| 安全性 |
与 POST 相比,GET 的安全性较差,因为所发送的数据是 URL 的一部分。 在发送密码或其他敏感信息时绝不要使用 GET ! |
POST 比 GET 更安全,因为参数不会被保存在浏览器历史或 web 服务器日志中。 |
| 可见性 | 数据在 URL 中对所有人都是可见的。 | 数据不会显示在 URL 中。 |
2.数据库索引
3.session和cookie区别
存储数据量方面:session 能够存储任意的 java 对象,cookie 只能存储 String 类型的对象
一个在客户端一个在服务端。因Cookie在客户端所以可以编辑伪造,不是十分安全。
Session过多时会消耗服务器资源,大型网站会有专门Session服务器,Cookie存在客户端没问题。
域的支持范围不一样,比方说a.com的Cookie在a.com下都能用,而www.a.com的Session在api.a.com下都不能用,解决这个问题的办法是JSONP或者跨域资源共享。
4.纸杯测试。。。
5.不记得了
360电面
1.接口和类区别
接口与类的相同点:
二者都可能具有抽象方法
二者都不可以实例化
接口与类的区别:
抽象类:只能用以派生新类,不能用以创建对象
类的成员:1.属性 2.方法 3.构造器
java中接口的成员:1.静态常量 2.抽象方法
接口里面没有--变量、普通方法、构造器!
接口中的变量 只能是静态常量 系统默认加上public static final
接口中的方法 默认都是public abstract修饰的
类和接口之间的关系:类实现接口 implements
类实现接口,类必须重写接口的抽象方法
接口和接口之间的关系:接口继承接口
java中规定:
类只能直接继承一个类(一个类只能有一个直接父类)
类可以同时实现多个接口
由于接口中的所有方法都是抽象方法,实现接口的非抽象类一定要实现接口中所有的抽象方法。
定义接口可以通过interface关键字,接口的定义与类的定义类似,
也是分为接口的声明和接口体两部分。
其中,接口体由静态常量定义和抽象方法定义两部分组成
1)在类实现接口时,被重写的方法的名字、参数列表必须与接口中的完全一致,
权限修饰符只能是public的
2)一个非抽象类实现接口时,必须实现接口中所有的方法
3)Java中的类不支持多继承,要想实现多继承,可以通过实现接口来进行
4)类实现接口可以通过关键字implements
2.不记得了。。。
xiaomi
1.编程题 台阶n 一次只能迈一节或两节,n输入一个数,输出需要迈几次,有几种解决方法?
2.一个类里有两个方法,定义了string和char两个变量,调方法问输出结果,
3.如何说服业务接受这个促销方案
场景:移动端电影票1000个用户可以以20%价格购买,一个用户限制下一单
4.sql查询
时间转成时间戳
5.socket
https://www.cnblogs.com/mq0036/p/3812755.html
socket是在应用层和传输层之间的一个抽象层,它把TCP/IP层复杂的操作抽象为几个简单的接口供应用层调用已实现进程在网络中通信。
socket屏蔽了各个协议的通信细节,使得程序员无需关注协议本身,直接使用socket提供的接口来进行互联的不同主机间的进程的通信。这就好比操作系统给我们提供了使用底层硬件功能的系统调用,通过系统调用我们可以方便的使用磁盘(文件操作),使用内存,而无需自己去进行磁盘读写,内存管理。socket其实也是一样的东西,就是提供了tcp/ip协议的抽象,对外提供了一套接口,同过这个接口就可以统一、方便的使用tcp/ip协议的功能了。
头条
1.hashmap基本结构
简单来说,HashMap由数组+链表组成的,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的,如果定位到的数组位置不含链表(当前entry的next指向null),那么对于查找,添加等操作很快,仅需一次寻址即可;如果定位到的数组包含链表,对于添加操作,其时间复杂度依然为O(1),因为最新的Entry会插入链表头部,仅需简单改变引用链即可,而对于查找操作来讲,此时就需要遍历链表,然后通过key对象的equals方法逐一比对查找。所以,性能考虑,HashMap中的链表出现越少,性能才会越好。
HashMap底层实现还是数组,只是数组的每一项都是一条链
默认初始容量 (16) 和默认加载因子 (0.75)
2.hashmap hashcode冲突在jdk1.8怎么解决的
在Java 8 之前,HashMap和其他基于map的类都是通过链地址法解决冲突,它们使用单向链表来存储相同索引值的元素。在最坏的情况下,这种方式会将HashMap的get方法的性能从O(1)降低到O(n)。为了解决在频繁冲突时hashmap性能降低的问题,
Java 8中使用平衡树来替代链表存储冲突的元素。这意味着我们可以将最坏情况下的性能从O(n)提高到O(logn)。
在Java 8中使用常量TREEIFY_THRESHOLD来控制是否切换到平衡树来存储。目前,这个常量值是8,这意味着当有超过8个元素的索引一样时,HashMap会使用树来存储它们。
什么时候会产生冲突
HashMap中调用hashCode()方法来计算hashCode。
由于在Java中两个不同的对象可能有一样的hashCode,所以不同的键可能有一样hashCode,从而导致冲突的产生。
3.concurrenthashmap 中丟数遇到过吗
4.springboot注解实现
https://www.cnblogs.com/3xmq/p/springboot.html
5.单体应用和微服务优缺点,测试优缺点
“单体应用(monolith application)”就是将应用程序的所有功能都打包成一个独立的单元,可以是 JAR、WAR、EAR 或其它归档格式。单体应用有如下优点:
- 为人所熟知:现有的大部分工具、应用服务器、框架和脚本都是这种应用程序;
- IDE友好:像 NetBeans、Eclipse、IntelliJ 这些开发环境都是针对开发、部署、调试这样的单个应用而设计的;
- 便于共享:单个归档文件包含所有功能,便于在团队之间以及不同的部署阶段之间共享;
- 易于测试:单体应用一旦部署,所有的服务或特性就都可以使用了,这简化了测试过程,因为没有额外的依赖,每项测试都可以在部署完成后立刻开始;
- 容易部署:只需将单个归档文件复制到单个目录下。
单体应用的一些不足:
- 不够灵活:对应用程序做任何细微的修改都需要将整个应用程序重新构建、重新部署。开发人员需要等到整个应用程序部署完成后才能看到变化。如果多个开发人员共同开发一个应用程序,那么还要等待其他开发人员完成了各自的开发。这降低了团队的灵活性和功能交付频率;
- 妨碍持续交付:单体应用可能会比较大,构建和部署时间也相应地比较长,不利于频繁部署,阻碍持续交付。在移动应用开发中,这个问题会显得尤为严重;
- 受技术栈限制:对于这类应用,技术是在开发之前经过慎重评估后选定的,每个团队成员都必须使用相同的开发语言、持久化存储及消息系统,而且要使用类似的工具,无法根据具体的场景做出其它选择;
- 技术债务:“不坏不修(Not broken,don’t fix)”,这在软件开发中非常常见,单体应用尤其如此。系统设计或写好的代码难以修改,因为应用程序的其它部分可能会以意料之外的方式使用它。随着时间推移、人员更迭,这必然会增加应用程序的技术债务。
服务就是一种可以满足这种需求的软件架构风格。单体应用被分解成多个更小的服务,每个服务有自己的归档文件,单独部署,然后共同组成一个应用程序。这里的“微”不是针对代码行数而言,而是说服务的范围限定到单个功能。微服务有如下特点:
- 领域驱动设计:应用程序功能分解可以通过 Eric Evans 在《领域驱动设计》中明确定义的规则实现;每个团队负责与一个领域或业务功能相关的全部开发;团队拥有全系列的开发人员,具备用户界面、业务逻辑和持久化存储等方面的开发技能;
- 单一职责原则:每个服务应该负责该功能的一个单独的部分,这是SOLID原则之一;
- 明确发布接口:每个服务都会发布一个定义明确的接口,而且保持不变;服务消费者只关心接口,而对于被消费的服务没有任何运行依赖;
- 独立部署、升级、扩展和替换:每个服务都可以单独部署及重新部署而不影响整个系统。这使得服务很容易升级,每个服务都可以沿着《Art of Scalability》一书定义的 X 轴和 Z 轴进行扩展;
- 可以异构 / 采用多种语言:每个服务的实现细节都与其它服务无关,这使得服务之间能够解耦,团队可以针对每个服务选择最合适的开发语言、持久化存储、工具和方法;
- 轻量级通信:服务通信使用轻量级的通信协议,例如,同步的 REST,异步的 AMQP、STOMP、MQTT 等。
相应地,微服务具有如下优点:
- 易于开发、理解和维护;
- 比单体应用启动快;
- 局部修改很容易部署,有利于持续集成和持续交付;
- 故障隔离,一个服务出现问题不会影响整个应用;
- 不会受限于任何技术栈。
6.es的基本组成成分,怎么使用,使用过程中遇到了那些问题
Elasticsearch是面向文档型数据库,一条数据在这里就是一个文档,用JSON作为文档序列化的格式
1、Elasticsearch和MongoDB/Redis/Memcache一样,是非关系型数据库。是一个接近实时的搜索平台,从索引这个文档到这个文档能够被搜索到只有一个轻微的延迟,企业应用定位:采用Restful API标准的可扩展和高可用的实时数据分析的全文搜索工具。
2、可拓展:支持一主多从且扩容简易,只要cluster.name一致且在同一个网络中就能自动加入当前集群;本身就是开源软件,也支持很多开源的第三方插件。
3、高可用:在一个集群的多个节点中进行分布式存储,索引支持shards和复制,即使部分节点down掉,也能自动进行数据恢复和主从切换。
3、采用RestfulAPI标准:通过http接口使用JSON格式进行操作数据。
4、数据存储的最小单位是文档,本质上是一个JSON 文本:

7.redis常用类型用途
适用场景:
-
数据高并发的读写
-
海量数据的读写
-
对扩展性要求高的数
redis存储数据的基本类型有:string(字符串类型)、hash(散列类型)、list(列表类型)、set(集合类型)、zset(有序集合类型)。
https://www.cnblogs.com/shoren/p/redis-types.html
1、String
String 数据结构是简单的key-value类型,value其实不仅是String,也可以是数字。
常用命令:get、set、整数递增:incr、整数递减:decr、获取多个键值:mget等。
2、Hash
常用命令:读取单个:hget,hset,读取全部:hgetall 等。
3、List
常用命令:lpush,rpush,移除左边第一个元素:lpop,rpop,获取列表片段:lrange等。
4、Set
常用命令:
添加元素sadd,spop,获取全部元素:smembers,并运算:sunion 等。
5、有序集合类型 zset(sorted set:有序集合)
常用命令:
添加集合元素:zadd,元素小到大:zrange,zrem,zcard等
https://blog.csdn.net/inhumming/article/details/78833096
8.public @interface SpringBootApplication
9.编程:输入abb,egg输出true,输入title ,返回false
输入的字符串数组中,所有单词都有叠字返回true,否则返回false
10.get和post区别
11.给定一个n*m矩阵,求从左上角格子到右下角格子总共存在多少条路径,每次只能向右走或者向下走
12.25匹马,5个赛道,最少比赛几次找出前三名
7次
13.给一堆字符串,找出他们前面相同的字符串出来
14.找出字符串中字符个数大于字符串长度一半的字符
15.堆栈
16.hashmap实现
在JDK1.6,JDK1.7中,HashMap采用位桶+链表实现,即使用链表处理冲突,同一hash值的链表都存储在一个链表里。但是当位于一个桶中的元素较多,即hash值相等的元素较多时,通过key值依次查找的效率较低。而JDK1.8中,HashMap采用位桶+链表+红黑树实现,当链表长度超过阈值(8)时,将链表转换为红黑树,这样大大减少了查找时间。
简单说下HashMap的实现原理:
首先有一个每个元素都是链表(可能表述不准确)的数组,当添加一个元素(key-value)时,就首先计算元素key的hash值,以此确定插入数组中的位置,但是可能存在同一hash值的元素已经被放在数组同一位置了,这时就添加到同一hash值的元素的后面,他们在数组的同一位置,但是形成了链表,同一各链表上的Hash值是相同的,所以说数组存放的是链表。而当链表长度太长时,链表就转换为红黑树,这样大大提高了查找的效率。
当链表数组的容量超过初始容量的0.75时,再散列将链表数组扩大2倍,把原链表数组的搬移到新的数组中
17.sql索引
18,算法题 一个迭代查找相似的url
19.nginx405错误
同事给了一个json请求,在HTTP接口测试工具中post请求结果返回405状态,get请求则返回数据。搜了一番发现返回405是因为Apache、IIS、Nginx等绝大多数web服务器,都不允许静态文件响应POST请求。
HTTP 状态码
1.信息代码:1xx,
2.成功代码:2xx,
3.重定向:3xx,
4.客户端错误:4xx,
5.服务器错误:5xx
200:正确的请求返回正确的结果,如果不想细分正确的请求结果都可以直接返回200。
201:表示资源被正确的创建。比如说,我们 POST 用户名、密码正确创建了一个用户就可以返回 201。
202:请求是正确的,但是结果正在处理中,这时候客户端可以通过轮询等机制继续请求。
203:请求的代理服务器修改了源服务器返回的 200 中的内容,我们通过代理服务器向服务器 A 请求用户信息,服务器 A 正常响应,但代理服务器命中了缓存并返回了自己的缓存内容,这时候它返回 203 告诉我们这部分信息不一定是最新的,我们可以自行判断并处理。
300:请求成功,但结果有多种选择。
301:请求成功,但是资源被永久转移。比如说,我们下载的东西不在这个地址需要去到新的地址。
303:使用 GET 来访问新的地址来获取资源。
304:请求的资源并没有被修改过。
308:使用原有的地址请求方式来通过新地址获取资源。
400:请求出现错误,比如请求头不对等。
401:没有提供认证信息。请求的时候没有带上 Token 等。
402:为以后需要所保留的状态码。
403:请求的资源不允许访问。就是说没有权限。
404:请求的内容不存在。
406:请求的资源并不符合要求。
408:客户端请求超时。
413:请求体过大。
415:类型不正确。
416:请求的区间无效。
500:服务器错误。
501:请求还没有被实现。
502:网关错误。
503:服务暂时不可用。服务器正好在更新代码重启。
505:请求的 HTTP 版本不支持。
巧达数据
1.画界面
2.画流程
3.自动化怎么做的
4.性能怎么做的
5.读取txt取出type为hidden的name的值
小米
1.python输出
2.java输出
3.http协议方法
HTTP1.0定义了三种请求方法: GET, POST 和 HEAD方法。
HTTP1.1新增了五种请求方法:OPTIONS, PUT, DELETE, TRACE 和 CONNECT 方法。
4.drw-r--r--码为多少?
r4 w2 r1
5.linux查看磁盘空间 df -lh
查看内存占用情况 top free
查看RAM使用情况 cat /proc/meminfo
(查询指定目录磁盘的使用情况) du -h
先查看进程pid
ps -ef | grep 进程名
通过pid查看占用端口
netstat -nap | grep 进程pid
linux通过端口查看进程:
netstat -nap | grep 端口号
6.sql三条查询
6.台阶问题
7.设计用例,电影票活动,原票价的20%1000张,
360
1.selenium浏览器兼容怎么做的
2.接口并发怎么做的
3.codereview 的sql注入怎么做的
4.没时间编写用例怎么测试
字节跳动
1.画项目的流程图
怎么测试的
异常校验
2.微信发朋友圈编写用例
3。1分钟介绍自己,亮点
4.java 数据类型
基本类型
1)四种整数类型(byte、short、int、long)
2)两种浮点数类型(float、double)
3)一种字符类型(char)
4)一种布尔类型(boolean)
引用类型
5.java 弱引用和强引用
Java四种引用包括强引用,软引用,弱引用,虚引用
强引用:
只要引用存在,垃圾回收器永远不会回收
Object obj = new Object();
//可直接通过obj取得对应的对象 如obj.equels(new Object());
而这样 obj对象对后面new Object的一个强引用,只有当obj这个引用被释放之后,对象才会被释放掉,这也是我们经常所用到的编码形式。
软引用:
非必须引用,内存溢出之前进行回收,可以通过以下代码实现
Object obj = new Object();
SoftReference<Object> sf = new SoftReference<Object>(obj);
obj = null;
sf.get();//有时候会返回null
这时候sf是对obj的一个软引用,通过sf.get()方法可以取到这个对象,当然,当这个对象被标记为需要回收的对象时,则返回null;
软引用主要用户实现类似缓存的功能,在内存足够的情况下直接通过软引用取值,无需从繁忙的真实来源查询数据,提升速度;当内存不足时,自动删除这部分缓存数据,从真正的来源查询这些数据。
弱引用:
第二次垃圾回收时回收,可以通过如下代码实现
Object obj = new Object();
WeakReference<Object> wf = new WeakReference<Object>(obj);
obj = null;
wf.get();//有时候会返回null
wf.isEnQueued();//返回是否被垃圾回收器标记为即将回收的垃圾
弱引用是在第二次垃圾回收时回收,短时间内通过弱引用取对应的数据,可以取到,当执行过第二次垃圾回收时,将返回null。
弱引用主要用于监控对象是否已经被垃圾回收器标记为即将回收的垃圾,可以通过弱引用的isEnQueued方法返回对象是否被垃圾回收器标记。
虚引用:
垃圾回收时回收,无法通过引用取到对象值,可以通过如下代码实现
Object obj = new Object();
PhantomReference<Object> pf = new PhantomReference<Object>(obj);
obj=null;
pf.get();//永远返回null
pf.isEnQueued();//返回是否从内存中已经删除
虚引用是每次垃圾回收的时候都会被回收,通过虚引用的get方法永远获取到的数据为null,因此也被成为幽灵引用。
虚引用主要用于检测对象是否已经从内存中删除。
⑴强引用(StrongReference)
强引用是使用最普遍的引用。如果一个对象具有强引用,那垃圾回收器绝不会回收它。当内存空间不足,Java虚拟机宁愿抛出OutOfMemoryError错误,使程序异常终止,也不会靠随意回收具有强引用的对象来解决内存不足的问题。 ps:强引用其实也就是我们平时A a = new A()这个意思。
⑵软引用(SoftReference)
如果一个对象只具有软引用,则内存空间足够,垃圾回收器就不会回收它;如果内存空间不足了,就会回收这些对象的内存。只要垃圾回收器没有回收它,该对象就可以被程序使用。软引用可用来实现内存敏感的高速缓存(下文给出示例)。
软引用可以和一个引用队列(ReferenceQueue)联合使用,如果软引用所引用的对象被垃圾回收器回收,Java虚拟机就会把这个软引用加入到与之关联的引用队列中。
⑶弱引用(WeakReference)
弱引用与软引用的区别在于:只具有弱引用的对象拥有更短暂的生命周期。在垃圾回收器线程扫描它所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。不过,由于垃圾回收器是一个优先级很低的线程,因此不一定会很快发现那些只具有弱引用的对象。
弱引用可以和一个引用队列(ReferenceQueue)联合使用,如果弱引用所引用的对象被垃圾回收,Java虚拟机就会把这个弱引用加入到与之关联的引用队列中。
⑷虚引用(PhantomReference)
“虚引用”顾名思义,就是形同虚设,与其他几种引用都不同,虚引用并不会决定对象的生命周期。如果一个对象仅持有虚引用,那么它就和没有任何引用一样,在任何时候都可能被垃圾回收器回收。
虚引用主要用来跟踪对象被垃圾回收器回收的活动。虚引用与软引用和弱引用的一个区别在于:虚引用必须和引用队列 (ReferenceQueue)联合使用。当垃圾回收器准备回收一个对象时,如果发现它还有虚引用,就会在回收对象的内存之前,把这个虚引用加入到与之 关联的引用队列中。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号