
垃圾邮件过滤的算法与技术:深入解析贝叶斯过滤与机器学习模型
垃圾邮件(spam email)是电子邮件系统中长期存在的问题,不仅占用用户的收件箱空间,降低工作效率,还可能隐藏恶意软件或钓鱼攻击的风险。为了应对这一挑战,现代邮件系统依赖先进的算法和技术来识别和过滤垃圾邮件。其中,贝叶斯过滤和机器学习模型是两种核心方法。本文将深入探讨它们的理论基础、工作原理以及技术细节,旨在为技术爱好者和邮件系统从业者提供清晰且详尽的参考。
为什么需要垃圾邮件过滤?
在深入技术之前,我们先明确垃圾邮件过滤的重要性。每天,用户可能会收到大量无关的广告邮件,甚至是伪装成合法通信的欺诈邮件。这些邮件不仅干扰正常使用,还可能带来安全隐患。垃圾邮件过滤的目标是通过自动化、智能化的方式,将这些邮件与正常邮件(ham)区分开来,确保用户的邮箱安全和高效。
贝叶斯过滤:概率驱动的分类方法
理论基础:贝叶斯定理
贝叶斯过滤基于贝叶斯定理,这是一个统计学中的经典公式,用于计算条件概率。在垃圾邮件过滤中,它回答的问题是:“给定邮件中出现某些词语,这封邮件是垃圾邮件的概率有多大?”
贝叶斯定理的数学表达如下:
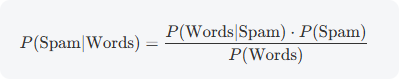
- P(Spam∣Words):后验概率,即在邮件包含特定词的情况下,它是垃圾邮件的概率。
- P(Words∣Spam):似然概率,即这些词在垃圾邮件中出现的概率。
- P(Spam):先验概率,即任何邮件是垃圾邮件的总体概率。
- P(Words):归一化常数,即这些词在所有邮件中出现的概率。
在实际应用中,过滤器通常假设词语之间是独立的(称为朴素贝叶斯假设),这简化了计算,尽管现实中词语可能存在关联。
工作原理与实现细节
贝叶斯过滤的运行分为以下几个关键步骤:
-
训练数据准备
需要一个已标记的邮件数据集,包括垃圾邮件(spam)和正常邮件(ham)。通过统计分析,计算每个词在两种邮件类别中的条件概率。例如,“免费”可能在垃圾邮件中出现频率为 80%,而在正常邮件中仅为 10%。 -
词频统计与概率估计
对训练集中的每封邮件进行分词,统计每个词的出现次数,并计算其在 spam 和 ham 中的概率。通常还会加入平滑技术(如拉普拉斯平滑),以避免因某个词未出现在训练集中而导致概率为零的情况。平滑公式如下:
![局部截取_20250731_150638]()
其中 ∣V∣是词汇表的大小。 -
新邮件分类
对于一封新邮件,提取其词语集合,查询训练数据中的概率,然后结合贝叶斯公式计算整封邮件是垃圾邮件的概率。由于直接计算 P(Words) 较复杂,通常比较 P(Spam∣Words)和 P(Ham∣Words)的相对大小。 -
动态更新
随着用户标记更多邮件(例如将误判的邮件更正为 spam 或 ham),过滤器会更新词语的概率分布,使其逐渐适应特定用户的邮件模式。
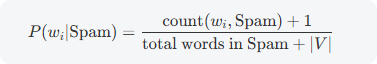
示例解析
假设一封邮件包含词语“免费”和“优惠”,训练数据如下:
- P(Spam)=0.4,P(Ham)=0.6(总体分布)。
- “免费”:P(免费∣Spam)=0.8,P(免费∣Ham)=0.1。
- “优惠”:P(优惠∣Spam)=0.7,P(优惠∣Ham)=0.2。
根据朴素贝叶斯假设,联合概率为:
- P(免费, 优惠∣Spam)=0.8⋅0.7=0.56
- P(免费, 优惠∣Ham)=0.1⋅0.2=0.02
结合先验概率:
- P(Spam∣免费, 优惠)∝0.56⋅0.4=0.224
- P(Ham∣免费, 优惠)∝0.02⋅0.6=0.012
由于 0.224 远大于 0.012,这封邮件很可能是垃圾邮件。
- 挑战与局限
- 词语独立性假设:现实中,词语之间可能存在上下文关联,朴素贝叶斯忽略这一点可能降低准确性。
- 新颖垃圾邮件:如果垃圾邮件使用拼写错误(如“fr33”代替“free”)或图片替代文本,过滤器可能失效。
- 训练数据依赖:需要足够多的标记数据,否则概率估计可能不准确。
机器学习模型:复杂模式的智能识别
理论基础
机器学习(ML)通过从数据中学习模式来分类邮件。与贝叶斯过滤的概率方法不同,ML 模型可以捕捉更复杂的特征关系,例如词语组合、邮件结构甚至发送行为。它们的目标是通过优化一个损失函数,找到区分 spam 和 ham 的最佳决策边界。
常用模型及其原理
- 决策树
- 原理:通过一系列条件分支(如“邮件是否含链接?”)构建一棵树,最终到达分类结果(spam 或 ham)。
- 细节:使用信息增益或基尼指数选择最佳特征进行分裂,深度越深,模型越复杂。
- 适用性:直观且易解释,适合特征较少的情况。
- 支持向量机(SVM)
- 原理:在高维特征空间中找到一个超平面,将 spam 和 ham 分开,最大化两类之间的间隔。
- 细节:通过核函数(如线性核或径向基函数 RBF)处理非线性数据,优化目标是最小化分类错误并最大化边界。
- 适用性:对高维数据表现优异,但计算成本较高。
- 神经网络
- 原理:由多层节点组成,模拟人脑处理信息,通过前向传播和反向传播学习特征间的复杂关系。
- 细节:输入层接收邮件特征(如词向量),隐藏层提取模式,输出层给出 spam 或 ham 的概率。训练时使用梯度下降优化损失函数(如交叉熵)。
- 适用性:适合大规模数据和复杂模式,但需要大量计算资源。
实现细节
- 数据准备与特征提取
- 收集大量已标记邮件(spam 和 ham)。
- 提取特征:不仅限于词频,还包括元数据(如发件人 IP)、结构信息(如链接数量)和语义特征(如词嵌入)。
- 将特征转化为数值向量,供模型处理。
- 模型训练
- 监督学习:使用标记数据,通过迭代优化调整模型参数。例如,神经网络通过反向传播更新权重,SVM 通过二次规划求解超平面。
- 超参数调优:调整学习率、树深度或正则化参数,防止过拟合。
- 预测过程
- 对新邮件提取特征,输入训练好的模型,输出分类结果(通常是概率值)。
- 可设置阈值(如 0.5)决定最终类别。
示例解析
假设训练一个 SVM,特征包括“词频”“发件人域名可疑度”“链接数量”。训练数据表明:
- 垃圾邮件:高词频广告词、可疑域名、多个链接。
- 正常邮件:普通词频、合法域名、少量链接。
SVM 在特征空间中找到一个超平面,将两类分开。新邮件输入后,模型根据其特征向量位置判断类别。
挑战与局限
- 数据需求:需要大量高质量的标记数据,数据不足可能导致模型泛化能力差。
- 过拟合风险:模型过于复杂时,可能过度拟合训练数据,对新邮件表现不佳。
- 计算成本:神经网络等模型训练和预测耗时较长,需权衡性能与资源。
特征工程:提升过滤效果的关键
特征提取的深度解析
特征是邮件的“指纹”,直接影响过滤器的性能。常见特征包括:
- 文本特征:词频、n-gram(词组)、TF-IDF(词频-逆文档频率)。
- 元数据特征:发件人地址、邮件服务器 IP、发送时间。
- 结构特征:邮件长度、HTML 标签数量、附件类型。
高级方法如词嵌入(Word2Vec 或 BERT)可捕捉语义关系,例如“免费”和“赠送”的相似性。
数据预处理技术
- 文本清洗
- 去除标点、数字、停用词(如“的”“是”)。
- 统一大小写,避免“Free”和“free”被视为不同词。
- 词形还原与词干提取
- 将“running”“ran”还原为“run”,减少词汇冗余。
- 使用工具如 NLTK 或 spaCy 实现。
- 向量化
- 将文本转为数值形式,例如 one-hot 编码、词袋模型或词嵌入。
- 降维
- 使用 PCA 或 t-SNE 减少特征维度,降低计算复杂度。
良好的特征工程能显著提升模型准确性,尤其对机器学习方法至关重要。
技术挑战与未来展望
- 对抗性攻击:垃圾邮件发送者可能故意改变邮件模式(如加密文本、使用图片),挑战现有算法。
- 实时性:随着邮件量增加,过滤器需在毫秒级完成分类。
- 隐私问题:分析邮件内容可能涉及用户隐私,需在算法设计中平衡效果与合规性。
未来,这些技术可能结合深度学习(如 Transformer 模型)和在线学习,进一步提升性能。
结论
贝叶斯过滤和机器学习模型是垃圾邮件过滤的核心技术。贝叶斯过滤通过概率统计提供简单高效的解决方案,而机器学习模型凭借强大的模式识别能力应对复杂场景。两者都依赖高质量的特征工程和数据预处理来实现最佳效果。尽管面临诸多挑战,这些技术在维护邮件系统安全和可用性方面发挥着不可替代的作用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号