一文读懂模型训练并行性:从5D 并行到ZeRO 优化器全解析
深度剖析训练并行性的基础概念
LLM 架构专栏
大模型架构专栏文章阅读指南
Agent系列
强化学习系列
欢迎加入大模型交流群:加群链接 https://docs.qq.com/doc/DS3VGS0NFVHNRR0Ru#
公众号【柏企阅文】
知乎【柏企】
个人网站:https://www.chenbaiqi.com
咱们每个人都疲于追赶大语言模型(LLM)研究领域的步伐。几乎每天都会冒出一个新的前沿模型,打破过往的基准成绩。要是你曾好奇,究竟是什么推动了这般迅猛的创新速度,答案就是研究人员得以进行超大规模的训练与验证,而这一切都多亏了并行技术。
“5D并行性”,这个术语最早是由Meta AI的论文《The Llama 3 Herd of Models》推广开来的。传统意义上,它指的是融合了数据并行、张量并行、上下文并行、流水线并行以及专家并行的技术。不过近来,一种名为ZeRO(零冗余优化器)的新范式横空出世,彻底改变了游戏规则。它通过削减分布式计算中的冗余来优化内存。每项技术都针对训练难题的不同方面,当它们协同发力时,就能处理含有数十亿(甚至数万亿)参数的模型。
本文聚焦于阐释模型操作的高级架构概念,并搭配PyTorch中的实例进行说明。这些并行技术的基本原理,是如今实现超大规模快速迭代和部署(想想数千万的日活跃用户规模)的关键驱动力。
1. 数据并行
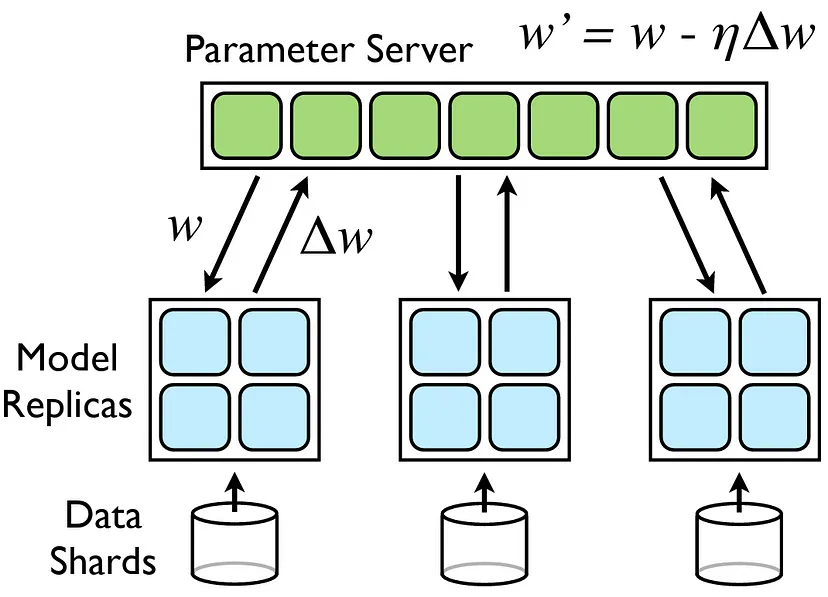
数据并行是最为直观且应用广泛的并行技术。它的原理是创建同一模型的多个副本,然后在不同的数据子集上分别训练这些副本。在本地完成梯度计算后,会将梯度进行聚合(通常借助全规约操作),进而用于更新模型的所有副本。
当模型本身能装入单个GPU的内存,然而数据集规模过大,无法按顺序处理时,这种方法就格外有效。
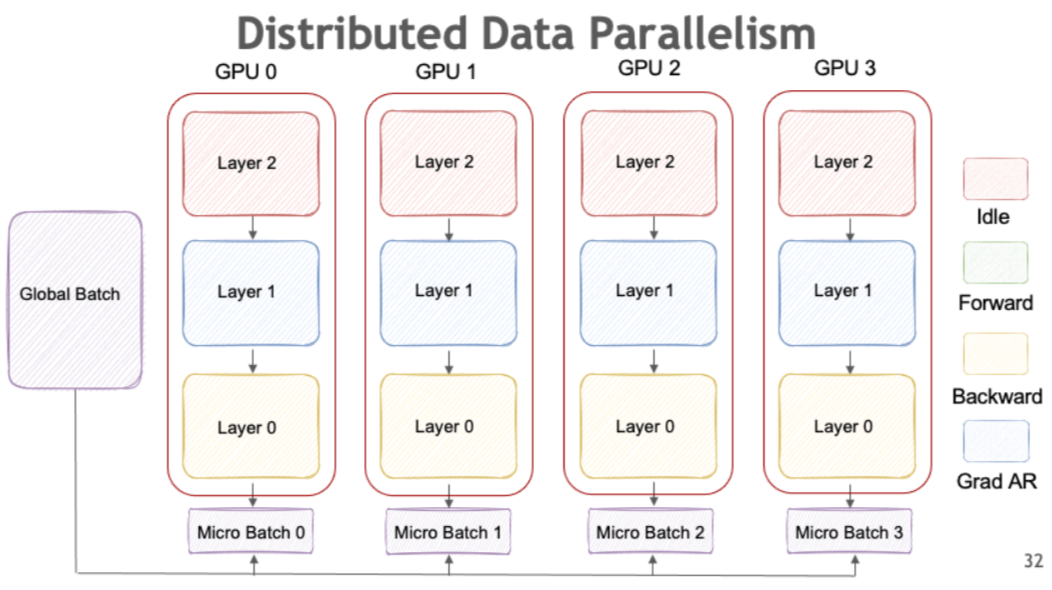
PyTorch通过torch.nn.DataParallel和torch.nn.parallel.DistributedDataParallel(DDP)模块,为数据并行提供了内置支持。在这两者之中,DDP更受青睐,因为它在多节点配置中具备更好的扩展性和更高的效率。NVIDIA的NeMo框架用下面这张图,非常生动地展示了其工作原理:
它的示例实现代码如下:
import torch
import torch.nn as nn
import torch.optim as optim
model = nn.Linear(10, 1)
model = nn.DataParallel(model)
model = model.cuda()
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
inputs = torch.randn(64, 10).cuda()
targets = torch.randn(64, 1).cuda()
outputs = model(inputs)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
关键要点
- 小模型/大数据集:此方法仅在模型能装入单个GPU内存,但数据集不行的情况下有效。
- 模型复制:每个GPU都持有一份相同的模型参数副本。
- 小批量拆分:输入数据会在多个GPU之间划分,保证每个设备处理独立的小批量数据。
- 梯度同步:在前向和反向传播之后,梯度会在GPU之间同步,以此维持一致性。
优点和注意事项
- 简单高效:易于实现,能直接融入现有代码库,对于大规模数据集的扩展性极佳。
- 通信开销:在大规模系统中,梯度同步过程中的通信开销可能会成为瓶颈。
2. 张量并行
数据并行侧重于拆分数据,而张量并行(也叫模型并行)则是将模型本身分布到多个设备上。这种方法会对大型权重矩阵和中间张量进行分区,让每个设备仅处理部分计算任务。与数据并行在每个GPU上复制整个模型不同,张量并行是把模型的层或张量分散到各个设备上。每个设备负责计算模型前向和反向传播的一部分。
对于训练那些单个GPU内存装不下的超大型模型(尤其是基于Transformer架构的模型),这项技术特别有用。
虽然PyTorch没有直接提供开箱即用的张量并行支持,但借助PyTorch灵活的张量操作和分布式通信原语,自定义实现并不困难。要是你想要更可靠的解决方案,像DeepSpeed和Megatron-LM这样的框架,在PyTorch的基础上进行了扩展,实现了张量并行功能。下面是一个简单的张量并行实现代码片段:
import torch
import torch.distributed as dist
def tensor_parallel_matmul(a, b, devices):
a_shard = a.chunk(len(devices), dim=0)
results = []
for i, dev in enumerate(devices):
a_device = a_shard[i].to(dev)
b_device = b.to(dev)
results.append(torch.matmul(a_device, b_device))
return torch.cat(results, dim=0)
a = torch.randn(1000, 512)
b = torch.randn(512, 256)
devices = ['cuda:0', 'cuda:1']
result = tensor_parallel_matmul(a, b, devices)
关键要点
- 大型模型适用:当模型无法装入单个GPU内存时,该方法效果显著。
- 分片权重:张量并行不是在每个设备上复制整个模型,而是对模型参数进行切片处理。
- 协同计算:前向和反向传播需要多个GPU协同完成,这就要求精心安排,以确保张量的各个部分都能正确计算。
- 自定义操作:通常会用到专门的CUDA内核或第三方库,来高效实现张量并行。
优点和注意事项
- 内存高效:通过拆分大型张量,可以训练超出单个设备内存容量的模型,还能显著降低矩阵运算的延迟。
- 复杂度高:设备之间的协作增加了实现的复杂度。当GPU数量超过两个时,开发者必须谨慎管理同步问题。手动分区可能导致负载不均衡,设备间通信不畅也会使GPU闲置,这些都是常见问题。
- 框架增强:像Megatron-LM这样的工具为张量并行设定了标准,许多此类框架能与PyTorch无缝集成,但集成过程并非总是一帆风顺。
3. 上下文并行
上下文并行另辟蹊径,针对输入数据的上下文维度进行处理,在基于序列的模型(如Transformer)中效果显著。其核心思路是划分长序列或上下文信息,使不同部分能同时处理。这样一来,模型就能处理更长的上下文,而不会过度消耗内存或计算资源。在需要同时训练多个任务的场景中,比如多任务自然语言处理模型,这种方法尤为实用。
和张量并行类似,PyTorch原生也不支持上下文并行。不过,通过巧妙地对数据进行重组,我们就能有效地处理长序列。想象一下,有个Transformer模型要处理长文本,就可以把序列拆分成小段,并行处理后再合并起来。
下面这个例子展示了在自定义Transformer模块中,如何拆分上下文。在这个例子里,模块会并行处理长序列的不同片段,之后将输出合并进行最终处理。
import torch
import torch.nn as nn
class ContextParallelTransformer(nn.Module):
def __init__(self, d_model, nhead, context_size):
super(ContextParallelTransformer, self).__init__()
self.context_size = context_size
self.transformer_layer = nn.TransformerEncoderLayer(
d_model=d_model, nhead=nhead)
def forward(self, x):
batch, seq_len, d_model = x.size()
assert seq_len % self.context_size == 0, "Sequence length must be divisible by context_size"
segments = x.view(batch, seq_len // self.context_size, self.context_size, d_model)
processed_segments = []
for i in range(segments.size(1)):
segment = segments[:, i, :, :]
processed_segment = self.transformer_layer(segment.transpose(0, 1))
processed_segments.append(processed_segment.transpose(0, 1))
return torch.cat(processed_segments, dim=1)
model = ContextParallelTransformer(d_model=512, nhead=8, context_size=16)
input_seq = torch.randn(32, 128, 512)
output = model(input_seq)
关键要点
- 序列划分:对序列或上下文维度进行分区,实现对数据不同片段的并行计算。
- 长序列扩展性:对于处理超长序列的模型来说,这种方法特别有用,因为一次性处理整个上下文既不现实又低效。
- 注意力机制:在Transformer中,将注意力计算分摊到各个片段,每个GPU就能处理部分序列及其相关的自注意力计算。
优点和注意事项
- 高效处理长序列:把长上下文划分为并行片段,模型就能在不耗尽内存资源的情况下处理长序列。
- 顺序依赖问题:必须特别留意跨越上下文片段边界的依赖关系。可能需要采用重叠片段或额外聚合步骤等技术来解决。
- 新兴领域:随着研究不断推进,预计会有更多标准化工具和库涌现,专门助力PyTorch实现上下文并行。
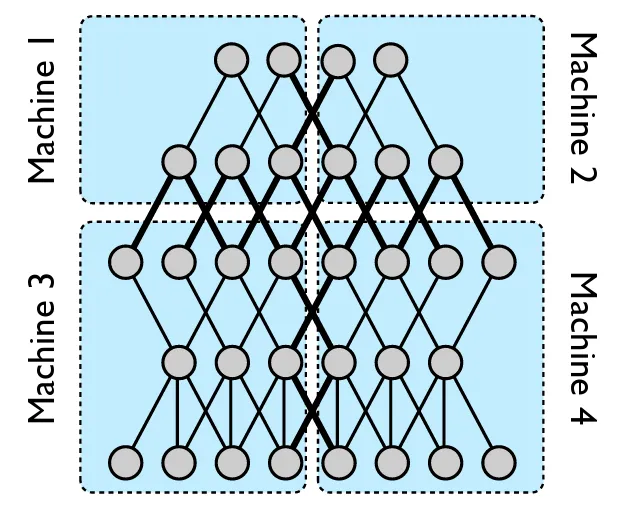
4. 管道并行

流水线并行引入了将神经网络划分为多个顺序阶段的概念,每个阶段在不同的GPU上处理。数据在网络中流动时,中间结果会从一个阶段传递到下一个阶段,就像装配线一样。这种交错执行的方式实现了计算和通信的重叠,提高了整体吞吐量。
好在PyTorch提供了一个现成的API来支持流水线并行,名为Pipe,借助它能轻松创建分段模型。该API会自动将顺序模型划分为微批次,在指定的GPU之间流动。
下面是使用这个API的简单示例:
import torch.nn as nn
from torch.distributed.pipeline.sync import Pipe
segment1 = nn.Sequential(
nn.Linear(1024, 2048),
nn.ReLU(),
nn.Linear(2048, 2048)
)
segment2 = nn.Sequential(
nn.Linear(2048, 2048),
nn.ReLU(),
nn.Linear(2048, 1024)
)
model = nn.Sequential(segment1, segment2)
model = Pipe(model, chunks=4)
inputs = torch.randn(16, 1024)
outputs = model(inputs)
import torch
import torch.nn as nn
from torch.distributed.pipeline.sync import Pipe
segment1 = nn.Sequential(
nn.Linear(1024, 2048),
nn.ReLU(),
nn.Linear(2048, 2048)
)
segment2 = nn.Sequential(
nn.Linear(2048, 2048),
nn.ReLU(),
nn.Linear(2048, 1024)
)
model = nn.Sequential(segment1, segment2)
model = Pipe(model, devices=['cuda:0', 'cuda:1'], chunks=4)
inputs = torch.randn(16, 1024).to('cuda:0')
outputs = model(inputs)
关键要点
- 分阶段计算:模型被划分为一系列阶段(即“流水线”),每个阶段分配到不同的GPU。
- 微批次处理:不是一次性将大批数据输入一个阶段,而是把批次拆分成微批次,持续在流水线中流动。
- 提高吞吐量:通过确保所有设备同时工作(即便处理的是不同微批次),流水线并行能大幅提升吞吐量。
优点和注意事项
- 资源利用率高:流水线并行通过重叠不同阶段的计算,提高了GPU的利用率。
- 延迟与吞吐量权衡:虽然吞吐量增加了,但由于引入了流水线延迟,延迟可能会略有增加。
- 调度复杂:有效的微批次调度和负载均衡对于实现各阶段的最佳性能至关重要。
5. 专家并行
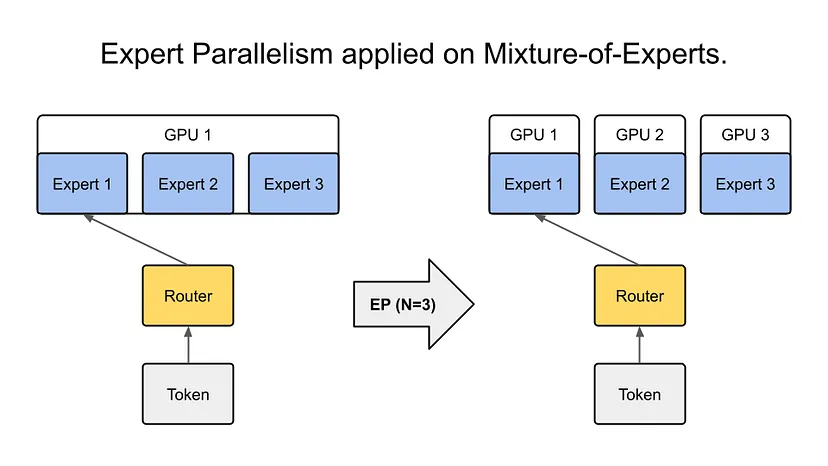
专家并行技术源自混合专家(Mixture-of-Experts,MoE)模型,旨在扩展模型容量的同时,控制计算成本。在这种范式下,模型由多个专门的“专家”组成,这些“专家”本质上是子网络,通过门控机制针对每个输入选择性激活。处理特定样本时,只会调用部分专家,这样在不增加太多计算开销的前提下,就能实现巨大的模型容量。
同样,PyTorch没有直接提供专家并行的现成解决方案,但它的模块化设计便于我们自定义实现。通常的做法是定义一组专家层,以及一个决定激活哪些专家的门控机制。
在实际应用中,专家并行常与其他并行策略结合使用。比如,你可以同时采用数据并行和专家并行,既处理大规模数据集,又管理海量模型参数,还能将计算任务精准分配给合适的专家。下面是一个简化的实现示例:
import torch
import torch.nn as nn
import torch.nn.functional as F
class Expert(nn.Module):
def __init__(self, input_dim, output_dim):
super(Expert, self).__init__()
self.fc = nn.Linear(input_dim, output_dim)
def forward(self, x):
return F.relu(self.fc(x))
class MoE(nn.Module):
def __init__(self, input_dim, output_dim, num_experts, k=2):
super(MoE, self).__init__()
self.num_experts = num_experts
self.k = k
self.experts = nn.ModuleList([Expert(input_dim, output_dim) for _ in range(num_experts)])
self.gate = nn.Linear(input_dim, num_experts)
def forward(self, x):
gate_scores = self.gate(x)
topk = torch.topk(gate_scores, self.k, dim=1)[1]
outputs = []
for i in range(x.size(0)):
expert_output = 0
for idx in topk[i]:
expert_output += self.experts[idx](x[i])
outputs.append(expert_output / self.k)
return torch.stack(outputs)
batch_size = 32
input_dim = 512
output_dim = 512
num_experts = 4
model = MoE(input_dim, output_dim, num_experts)
x = torch.randn(batch_size, input_dim)
output = model(x)
关键要点
- 混合专家模式:每个训练样本仅使用部分专家,大幅减少了单个样本的计算量,同时保持了庞大的整体模型容量。
- 动态路由:门控函数动态决定每个输入令牌或数据片段应由哪些专家处理。
- 专家级并行:专家可以分布在多个设备上,实现并行计算,进一步减少瓶颈。
优点和注意事项
- 可扩展的模型容量:专家并行让你能够构建大容量模型,而且不会随着输入增加而线性增加计算量。
- 计算高效:每个输入仅处理选定的部分专家,计算效率很高。
- 路由复杂性:门控机制至关重要,设计不当的路由会导致负载不均衡和训练不稳定。
- 研究前沿:专家并行仍是活跃的研究领域,目前的研究致力于改进门控方法和专家间的同步机制。
6. ZeRO:零冗余优化器
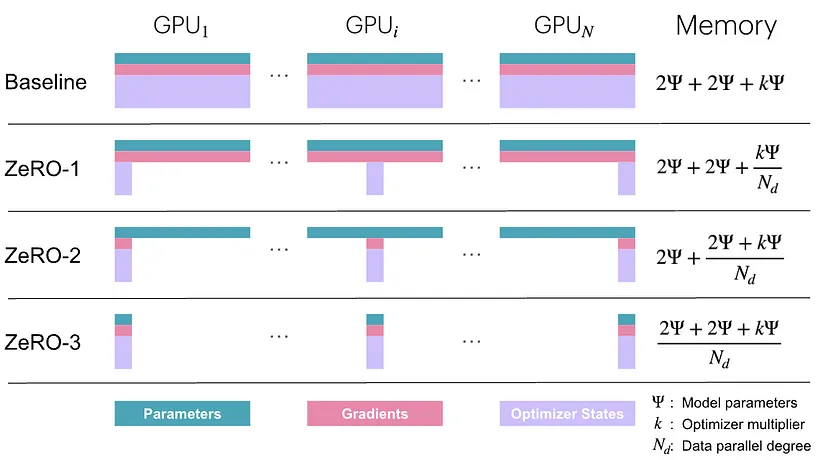
ZeRO,即零冗余优化器(Zero Redundancy Optimizer)的缩写,它是大规模训练内存优化领域的一项重大突破。ZeRO是作为DeepSpeed库的一部分开发的,通过对优化器状态、梯度和模型参数进行分区,来解决分布式训练中的内存限制问题。本质上,ZeRO消除了每个GPU都持有所有数据副本时产生的冗余,从而节省了大量内存。
它的运行方式是在所有参与设备之间划分优化器状态和梯度的存储,而不是进行复制。这种策略不仅减少了内存使用,还使得训练那些原本超出单个GPU内存容量的模型成为可能。ZeRO通常分三个不同阶段来实现,每个阶段都针对内存冗余的不同方面:
- ZeRO-1:优化器状态分区:在多个GPU之间对优化器状态(例如动量缓冲区)进行分区。每个GPU仅存储其负责的那部分参数的优化器状态。模型参数和梯度仍在所有GPU上进行复制。
- ZeRO-2:梯度分区:包含ZeRO-1的所有功能。额外对梯度在GPU之间进行分区。每个GPU仅计算和存储其负责参数部分的梯度。模型参数依旧在所有GPU上复制。
- ZeRO-3:参数分区:包含ZeRO-1和ZeRO-2的所有功能。额外对模型参数在GPU之间进行分区。每个GPU仅存储部分模型参数。在前向/反向传播时需要收集参数。
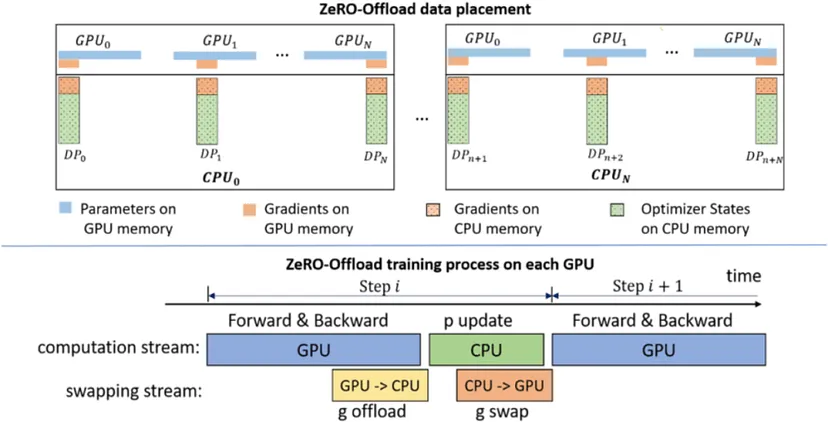
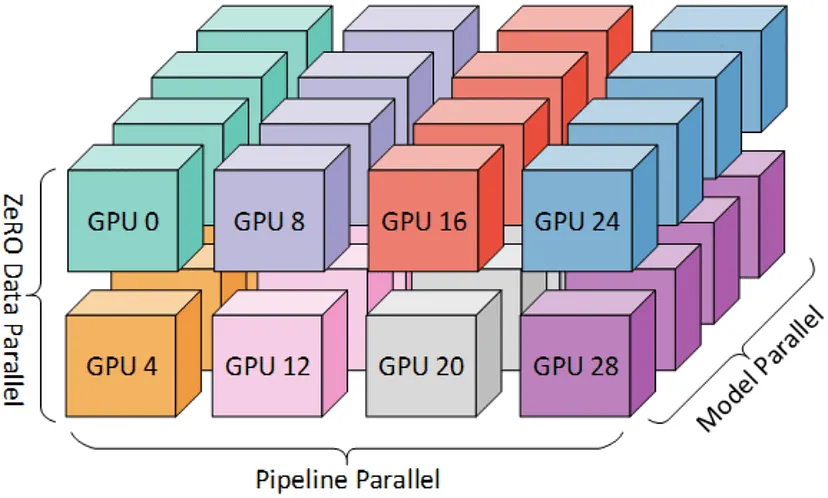
如上图所示,ZeRO结合了数据并行和模型并行的优势,提供了极大的灵活性。
尽管ZeRO是DeepSpeed的一个特性,但它与PyTorch的集成,使其成为训练优化工具库中的重要一员,有助于高效管理内存,让以往因硬件限制无法训练的超大模型变得可训练。下面是一个示例代码:
import torch
import torch.nn as nn
import deepspeed
class LargeModel(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
super(LargeModel, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
x = self.relu(self.fc1(x))
return self.fc2(x)
model = LargeModel(1024, 4096, 10)
ds_config = {
"train_batch_size": 32,
"optimizer": {
"type": "Adam",
"params": {
"lr": 0.001
}
},
"zero_optimization": {
"stage": 2,
"allgather_partitions": True,
"reduce_scatter": True,
"allgather_bucket_size": 2e8,
"overlap_comm": True
}
}
model_engine, optimizer, _, _ = deepspeed.initialize(model=model, config=ds_config)
inputs = torch.randn(32, 1024).to(model_engine.local_rank)
outputs = model_engine(inputs)
loss = outputs.mean()
model_engine.backward(loss)
model_engine.step()
关键要点
- 阶段选择:ZeRO通常分多个阶段实现,每个阶段在内存节省和通信开销之间提供不同的平衡。根据模型大小、网络能力和可接受的通信开销水平选择合适的阶段至关重要。
- 与其他技术的集成:它可以无缝融入一个生态系统,这个生态系统可能还包括上述的并行策略。
优点和注意事项
- 通信开销:这种策略固有的挑战在于,减少内存冗余通常会增加GPU之间交换的数据量。因此,高效利用高速互连(如NVLink或InfiniBand)变得更加关键。
- 配置复杂性:与更传统的优化器相比,ZeRO引入了额外的配置参数。这些设置需要仔细进行实验和性能分析,以匹配硬件的优势,确保优化器高效运行。设置包括但不限于用于梯度聚合的合适桶大小,以及针对各种状态(优化器状态、梯度、参数)的分区策略。
- 强大的监控:调试启用ZeRO的训练过程中的问题可能非常具有挑战性。因此,提供有关GPU内存使用情况、网络延迟和整体吞吐量洞察的监控工具就变得至关重要。
融合所有技术
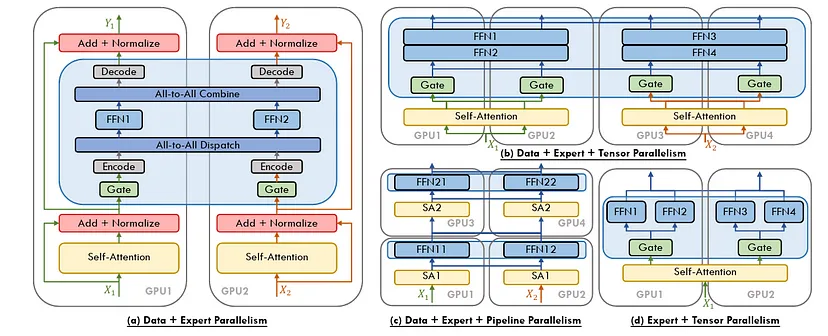
大规模训练深度学习模型通常需要采用混合方法,一般是结合上述多种技术。例如,一个前沿的大语言模型(LLM)可能会使用数据并行在节点间分发批次数据,使用张量并行拆分大规模权重矩阵,使用上下文并行处理长序列,使用流水线并行连接顺序模型阶段,使用专家并行动态分配计算资源,最后使用ZeRO优化内存使用。这种协同作用确保即使是具有天文数字般参数数量的模型,也能保持可训练性和高效性。
推荐阅读
1. DeepSeek-R1的顿悟时刻是如何出现的? 背后的数学原理
2. 微调 DeepSeek LLM:使用监督微调(SFT)与 Hugging Face 数据
3. 使用 DeepSeek-R1 等推理模型将 RAG 转换为 RAT
4. DeepSeek R1:了解GRPO和多阶段训练
5. 深度探索:DeepSeek-R1 如何从零开始训练
6. DeepSeek 发布 Janus Pro 7B 多模态模型,免费又强大!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号