


一致性hash算法-consistent hashing
2012-08-14 11:15 coodoing 阅读(542) 评论(0) 收藏 举报0、应用场景
在做服务器负载均衡时候可供选择的负载均衡的算法有很多,包括: 轮循算法(Round Robin)、哈希算法(HASH)、最少连接算法(Least Connection)、响应速度算法(Response Time)、加权法(Weighted )等。其中哈希算法是最为常用的算法。
典型的应用场景是: 有N台服务器提供缓存服务,需要对服务器进行负载均衡,将请求平均分发到每台服务器上,每台机器负责1/N的服务。
常用的算法是对hash结果取余数 (hash() mod N):对机器编号从0到N-1,按照自定义的hash()算法,对每个请求的hash()值按N取模,得到余数i,然后将请求分发到编号为i的机器。但这样的算法方法存在致命问题,如果某一台机器宕机,那么应该落在该机器的请求就无法得到正确的处理,这时需要将当掉的服务器从算法从去除,此时候会有(N-1)/N的服务器的缓存数据需要重新进行计算;如果新增一台机器,会有N /(N+1)的服务器的缓存数据需要进行重新计算。对于系统而言,这通常是不可接受的颠簸(因为这意味着大量缓存的失效或者数据需要转移)。那么,如何设计一个负载均衡策略,使得受到影响的请求尽可能的少呢?
在Memcached、Key-Value Store、Bittorrent DHT、LVS中都采用了Consistent Hashing算法,可以说Consistent Hashing 是分布式系统负载均衡的首选算法。
1、Consistent Hashing算法描述
下面以Memcached中的Consisten Hashing算法为例说明。
由于hash算法结果一般为unsigned int型,因此对于hash函数的结果应该均匀分布在[0,232-1]间,如果我们把一个圆环用232 个点来进行均匀切割,首先按照hash(key)函数算出服务器(节点)的哈希值, 并将其分布到0~232的圆上。
用同样的hash(key)函数求出需要存储数据的键的哈希值,并映射到圆上。然后从数据映射到的位置开始顺时针查找,将数据保存到找到的第一个服务器(节点)上。

Consistent Hashing原理示意图
新增一个节点的时候,只有在圆环上新增节点逆时针方向的第一个节点的数据会受到影响。删除一个节点的时候,只有在圆环上原来删除节点顺时针方向的第一个节点的数据会受到影响,因此通过Consistent Hashing很好地解决了负载均衡中由于新增节点、删除节点引起的hash值颠簸问题。

Consistent Hashing添加服务器示意图
详细步骤可分为5步:
1 环形hash 空间
考虑通常的 hash 算法都是将 value 映射到一个 32 位的 key 值,也即是 0~2^32-1 次方的数值空间;我们可以将这个空间想象成一个首( 0 )尾( 2^32-1 )相接的圆环,如下面图 1 所示的那样。

图 1 环形 hash 空间
2 把对象映射到hash 空间
接下来考虑 4 个对象 object1~object4 ,通过 hash 函数计算出的 hash 值 key 在环上的分布如图 2 所示。
hash(object1) = key1;
… …
hash(object4) = key4;

图 2 4 个对象的 key 值分布
3 把cache 映射到hash 空间
Consistent hashing 的基本思想就是将对象和 cache 都映射到同一个 hash 数值空间中,并且使用相同的hash 算法。
假设当前有 A,B 和 C 共 3 台 cache ,那么其映射结果将如图 3 所示,他们在 hash 空间中,以对应的 hash值排列。
hash(cache A) = key A;
… …
hash(cache C) = key C;

图 3 cache 和对象的 key 值分布
说到这里,顺便提一下 cache 的 hash 计算,一般的方法可以使用 cache 机器的 IP 地址或者机器名作为hash 输入。
4 把对象映射到cache
现在 cache 和对象都已经通过同一个 hash 算法映射到 hash 数值空间中了,接下来要考虑的就是如何将对象映射到 cache 上面了。
在这个环形空间中,如果沿着顺时针方向从对象的 key 值出发,直到遇见一个 cache ,那么就将该对象存储在这个 cache 上,因为对象和 cache 的 hash 值是固定的,因此这个 cache 必然是唯一和确定的。这样不就找到了对象和 cache 的映射方法了吗?!
依然继续上面的例子(参见图 3 ),那么根据上面的方法,对象 object1 将被存储到 cache A 上; object2和 object3 对应到 cache C ; object4 对应到 cache B ;
5 考察cache 的变动
前面讲过,通过 hash 然后求余的方法带来的最大问题就在于不能满足单调性,当 cache 有所变动时,cache 会失效,进而对后台服务器造成巨大的冲击,现在就来分析分析 consistent hashing 算法。
5.1 移除 cache
考虑假设 cache B 挂掉了,根据上面讲到的映射方法,这时受影响的将仅是那些沿 cache B 逆时针遍历直到下一个 cache ( cache C )之间的对象,也即是本来映射到 cache B 上的那些对象。因此这里仅需要变动对象 object4 ,将其重新映射到 cache C 上即可;参见图 4 。

图 4 Cache B 被移除后的 cache 映射
5.2 添加 cache
再考虑添加一台新的 cache D 的情况,假设在这个环形 hash 空间中, cache D 被映射在对象 object2 和object3 之间。这时受影响的将仅是那些沿 cache D 逆时针遍历直到下一个 cache ( cache B )之间的对象(它们是也本来映射到 cache C 上对象的一部分),将这些对象重新映射到 cache D 上即可。因此这里仅需要变动对象 object2 ,将其重新映射到 cache D 上;参见图 5 。

图 5 添加 cache D 后的映射关系
2 虚拟节点
考量 Hash 算法的另一个指标是平衡性 (Balance) ,定义如下:
平衡性
平衡性是指哈希的结果能够尽可能分布到所有的缓冲中去,这样可以使得所有的缓冲空间都得到利用。hash 算法并不是保证绝对的平衡,如果 cache 较少的话,对象并不能被均匀的映射到 cache 上,比如在上面的例子中,仅部署 cache A 和 cache C 的情况下,在 4 个对象中, cache A 仅存储了 object1 ,而 cache C 则存储了 object2 、 object3 和 object4 ;分布是很不均衡的。为了解决这种情况, consistent hashing 引入了“虚拟节点”的概念,它可以如下定义:
“虚拟节点”( virtual node )是实际节点在 hash 空间的复制品( replica ),一实际个节点对应了若干个“虚拟节点”,这个对应个数也成为“复制个数”,“虚拟节点”在 hash 空间中以 hash 值排列。仍以仅部署 cache A 和 cache C 的情况为例,在图 4 中我们已经看到, cache 分布并不均匀。现在我们引入虚拟节点,并设置“复制个数”为 2 ,这就意味着一共会存在 4 个“虚拟节点”, cache A1, cache A2 代表了 cache A ; cache C1, cache C2 代表了 cache C ;假设一种比较理想的情况,参见图 6 。

图 6 引入“虚拟节点”后的映射关系
此时,对象到“虚拟节点”的映射关系为:
objec1->cache A2 ; objec2->cache A1 ; objec3->cache C1 ; objec4->cache C2 ;
因此对象 object1 和 object2 都被映射到了 cache A 上,而 object3 和 object4 映射到了 cache C 上;平衡性有了很大提高。在进行负载均衡时候,落到虚拟节点的哈希值实际就落到了实际的节点上。由于所有的实际节点是按照相同的比例复制成虚拟节点的,因此解决了节点数较少的情况下哈希值在圆环上均匀分布的问题。
引入“虚拟节点”后,映射关系就从 { 对象 -> 节点 } 转换到了 { 对象 -> 虚拟节点 } 。查询物体所在 cache时的映射关系如图 7 所示。
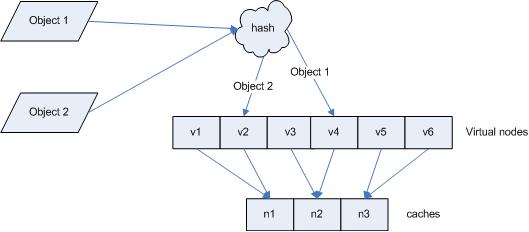
图 7 查询对象所在 cache
“虚拟节点”的 hash 计算可以采用对应节点的 IP 地址加数字后缀的方式。例如假设 cache A 的 IP 地址为202.168.14.241 。
引入“虚拟节点”前,计算 cache A 的 hash 值:
Hash(“202.168.14.241”);
引入“虚拟节点”后,计算“虚拟节”点 cache A1 和 cache A2 的 hash 值:
Hash(“202.168.14.241#1”); // cache A1
Hash(“202.168.14.241#2”); // cache A2
附:
应用场景第3段中有这些文字:“但这样的算法方法存在致命问题,如果某一台机器宕机,那么应该落在该机器的请求就无法得到正确的处理,这时需要将当掉的服务器从算法从去除,此时候会有(N-1)/N的服务器的缓存数据需要重新进行计算;”
为何是 (N-1)/N 呢?解释如下:
比如有 3 台机器,hash值 1-6 在这3台上的分布就是:
host 1: 1 4
host 2: 2 5
host 3: 3 6
如果挂掉一台,只剩两台,模数取 2 ,那么分布情况就变成:
host 1: 1 3 5
host 2: 2 4 6
可以看到,还在数据位置不变的只有2个: 1,2,位置发生改变的有4个,占共6个数据的比率是 4/6 = 2/3。这样的话,受影响的数据太多了,势必太多的数据需要重新从 DB 加载到 cache 中,严重影响性能。
上面提到的 hash 取模,模数取的比较小,一般是负载的数量,而 consistent hashing 的本质是将模数取的比较大,为 2的32次方减1,即一个最大的 32 位整数。
参考资料:
http://blog.csdn.net/21aspnet/article/details/5780831

 浙公网安备 33010602011771号
浙公网安备 33010602011771号