01 Spark架构与运行流程
1. 阐述Hadoop生态系统中,HDFS, MapReduce, Yarn, Hbase及Spark的相互关系。
答:Hadoop分布式计算平台最核心的是:提供海量数据存储的HDFS,与提供海量数据计算的MapReduce,以及数据仓库工具Hive和分布式数据库Hbase。
hadoop三大组件包括:分布式文件系统HDFS —— 实现将文件分布式存储在很多的服务器上分布式运算编程框架,MapReduce——实现多台机器的分布式并行运算,分布式资源调度平台YARN —— 帮用户调度大量的mapreduce程序,并合理分配运算资源
Spark 是一个用来实现快速,而通用的集群计算的平台,Spark 扩展了广泛使用的 MapReduce计算模型,而且高效地支持更多计算模式,包括交互式查询和流处理。Spark 的一个主要特点就是能够在内存中进行计算,因而更快。不过即使是,必须在磁盘上进行的复杂计算,Spark 依然比MapReduce更加高效,总的来说spark吸取了hadoop的优点同时做出了一些改进,高效的同时还能适用于更多的场景。
2. Spark已打造出结构一体化、功能多样化的大数据生态系统,请简述Spark生态系统。
答:Spark 生态系统以Spark Core 为核心,能够读取传统文件(如文本文件)、HDFS、Amazon S3、Alluxio 和NoSQL 等数据源,利用Standalone、YARN 和Mesos 等资源调度管理,完成应用程序分析与处理。spark生态系统主要包括spark core、spark SQL、spark streaming、structured streaming、mllib、graphx等组件。spark core提供复杂的批量数据处理,spark SQL提供基于历史数据的交互式查询,spark streaming、structured streaming提供基于实时数据流的数据处理,mllib提供基于历史数据的数据挖掘,graphx提供图结构数据的处理
3. 用图文描述你所理解的Spark运行架构,运行流程。
答:Spark运行架构由四部分组成:
1.集群资源管理器(Cluster Manager):YARN或者Mesos等资源管理框架
2.运行作业任务的工作节点(Worker Node)
3.每个应用的任务控制节点(Driver Program/Driver)
4.每个工作节点上负责具体任务的执行进程(Executor)
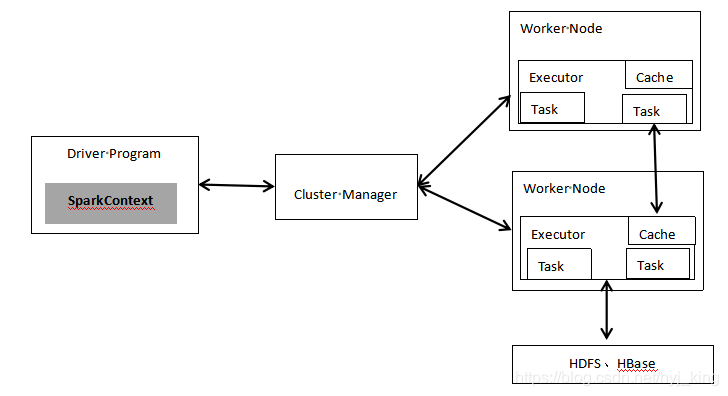
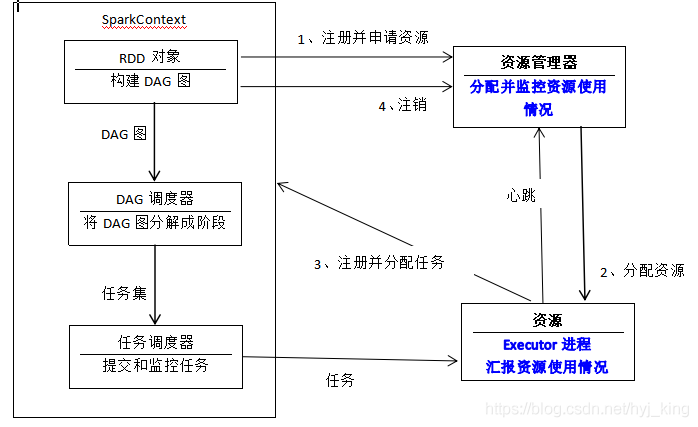
spark的运行基本流程 :1、当一个spark应用被提交时,首先需要为这个应用构建起基本的运行环境,即由任务控制节点(Driver)创建一个SparkContext对象,由Sparkcontext负责和资源管理器的通信以及进行资源的申请、任务的分配和监控等,SparkContext会向资源管理器注册并申请运行Executor的资源,SparkContext可以看成是应用程序连接集群的通道。
2、资源管理器为Executor分配资源,并启动Executor进程,Executor运行情况将随着"心跳"发送到资源管理器上。
3、SparkContext根据RDD的依赖关系构建DAG图,DAG图提交给DAG调度器进行解析,将DAG图分解成多个‘阶段’(每个阶段都是一个任务集),并且计算出各个阶段之间的依赖关系,然后把一个个“任务集”提交给底层的任务调度器进行处理;Executor向SparkContext申请任务,任务调度器将任务分发给Executor运行,同时,SparkContext将应用程序代码发放给Executor。
4、任务在Executor上运行,把执行结果反馈给任务调度器,然后反馈给DAG调度器,运行完毕后写入数据并释放所有资源。
参考文章:https://baijiahao.baidu.com/s?id=1684665476419300396&wfr=spider&for=pc
https://blog.csdn.net/hyj_king/article/details/100592603

 浙公网安备 33010602011771号
浙公网安备 33010602011771号