




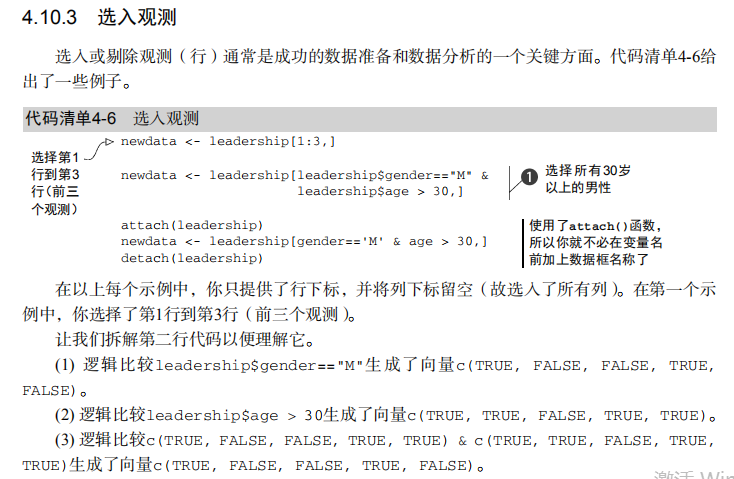




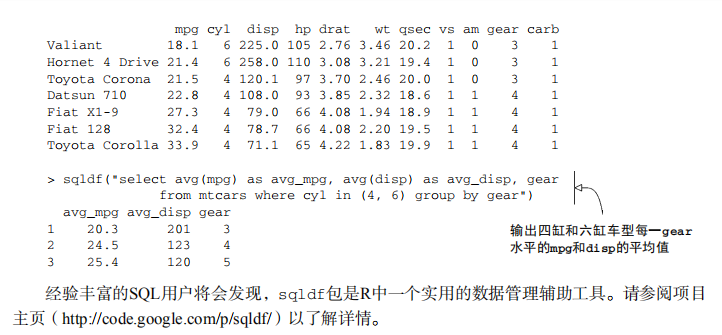

#---------------------------------------------------------# # R in Action (2nd ed): Chapter 4 # # Basic data management # # requires that the reshape2 and sqldf packages have # # been installed # # install.packages(c('reshape2', 'sqldf')) # #---------------------------------------------------------# # leadership dataset manager <- c(1,2,3,4,5) date <- c("10/24/08","10/28/08","10/1/08","10/12/08","5/1/09") gender <- c("M","F","F","M","F") age <- c(32,45,25,39,99) q1 <- c(5,3,3,3,2) q2 <- c(4,5,5,3,2) q3 <- c(5,2,5,4,1) q4 <- c(5,5,5,NA,2) q5 <- c(5,5,2,NA,1) leadership <- data.frame(manager,date,gender,age,q1,q2,q3,q4,q5, stringsAsFactors=FALSE) # Listing 4.2 - Creating new variables mydata<-data.frame(x1 = c(2, 2, 6, 4), x2 = c(3, 4, 2, 8)) mydata$sumx <- mydata$x1 + mydata$x2 mydata$meanx <- (mydata$x1 + mydata$x2)/2 attach(mydata) mydata$sumx <- x1 + x2 mydata$meanx <- (x1 + x2)/2 detach(mydata) mydata <- transform(mydata, sumx = x1 + x2, meanx = (x1 + x2)/2) # Recoding variables leadership$agecat[leadership$age > 75] <- "Elder" leadership$agecat[leadership$age >= 55 & leadership$age <= 75] <- "Middle Aged" leadership$agecat[leadership$age < 55] <- "Young" leadership <- within(leadership,{ agecat <- NA agecat[age > 75] <- "Elder" agecat[age >= 55 & age <= 75] <- "Middle Aged" agecat[age < 55] <- "Young" }) # Renaming variables with the plyr package names(leadership) names(leadership)[2] <- "testDate" leadership library(plyr) leadership <- rename(leadership, c(manager="managerID", date="testDate")) # Applying the is.na() function is.na(leadership[, 6:10]) # Recode 99 to missing for the variable age leadership[age == 99, "age"] <- NA leadership # Excluding missing values from analyses x <- c(1, 2, NA, 3) y <- x[1] + x[2] + x[3] + x[4] z <- sum(x) x <- c(1, 2, NA, 3) y <- sum(x, na.rm=TRUE) # Listing 4.4 - Using na.omit() to delete incomplete observations leadership newdata <- na.omit(leadership) newdata # Converting character values to dates mydates <- as.Date(c("2007-06-22", "2004-02-13")) strDates <- c("01/05/1965", "08/16/1975") dates <- as.Date(strDates, "%m/%d/%Y") # Woring with formats today <- Sys.Date() format(today, format="%B %d %Y") format(today, format="%A") # Calculations with with dates startdate <- as.Date("2004-02-13") enddate <- as.Date("2009-06-22") enddate - startdate # Date functions and formatted printing today <- Sys.Date() dob <- as.Date("1956-10-12") difftime(today, dob, units="weeks") # Listing 4.5 - Converting from one data type to another a <- c(1,2,3) a is.numeric(a) is.vector(a) a <- as.character(a) a is.numeric(a) is.vector(a) is.character(a) # Sorting a dataset newdata <- leadership[order(leadership$age),] attach(leadership) newdata <- leadership[order(gender, age),] detach(leadership) attach(leadership) newdata <-leadership[order(gender, -age),] detach(leadership) # Selecting variables newdata <- leadership[, c(6:10)] myvars <- c("q1", "q2", "q3", "q4", "q5") newdata <-leadership[myvars] myvars <- paste("q", 1:5, sep="") newdata <- leadership[myvars] # Dropping variables myvars <- names(leadership) %in% c("q3", "q4") leadership[!myvars] # Listing 4.6 - Selecting observations newdata <- leadership[1:3,] newdata <- leadership[leadership$gender=="M" & leadership$age > 30,] attach(leadership) newdata <- leadership[gender=='M' & age > 30,] detach(leadership) # Selecting observations based on dates startdate <- as.Date("2009-01-01") enddate <- as.Date("2009-10-31") newdata <- leadership[which(leadership$date >= startdate & leadership$date <= enddate),] # Using the subset() function newdata <- subset(leadership, age >= 35 | age < 24, select=c(q1, q2, q3, q4)) newdata <- subset(leadership, gender=="M" & age > 25, select=gender:q4) # Listing 4.7 - Using SQL statements to manipulate data frames library(sqldf) newdf <- sqldf("select * from mtcars where carb=1 order by mpg", row.names=TRUE) newdf sqldf("select avg(mpg) as avg_mpg, avg(disp) as avg_disp, gear from mtcars where cyl in (4, 6) group by gear")
