策略梯度AC算法 - CartPole环境, 使用RNN作为策略网络
参考资料:
- Vanila Policy Gradient with a Recurrent Neural Network Policy – Abhishek Mishra – Artificial Intelligence researcher
- 动手学强化学习-HandsOnRL,本文中展示的代码都是基于《动手学RL》的代码库。
- rlorigro/cartpole_policy_gradient: a simple 1st order PG solution to the openAI cart pole problem (adapted from @ts1839) and an RNN based PG variation on this
为什么使用RNN
对于一些简单的环境,只需要知道当前时刻的状态以及动作,就可以预测下一个时刻的状态 (即环境满足一元的马尔可夫假设)。比如说车杆环境:

但是:
- 对于一些复杂的环境,可能需要多个时刻的状态才足以预测下一时刻。
- 在部分可观测的环境,我们无从知道环境的真实状态。
在DQN玩雅达利游戏中,作者是将连续几帧的图像作为状态传入网络。一种可能更好的替代方法是使用RNN作为策略网络。
代码
基于动手学强化学习-HandsOnRL的ActorCritic代码进行修改。主要改动:
- 策略网络使用RNN.
- 每次
tack_action的时候就计算log_probs,并且记录下来,而不是最后在update时一起计算。记录log_probs时,应该使用Tensor,保留梯度。 - 每个episode开始的时候,应该清空隐状态
h.
导入包
import gym
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import matplotlib.pyplot as plt
import rl_utils
from tqdm import tqdm
值网络和RNN策略网络
class ValueNet(torch.nn.Module):
def __init__(self, state_dim, hidden_dim):
super(ValueNet, self).__init__()
self.fc1 = torch.nn.Linear(state_dim, hidden_dim)
self.fc2 = torch.nn.Linear(hidden_dim, 1)
def forward(self, x):
x = F.relu(self.fc1(x))
return self.fc2(x)
class RNNPolicy(torch.nn.Module):
def __init__(self, state_dim, hidden_dim, action_dim):
super(RNNPolicy, self).__init__()
self.rnn = nn.GRUCell(input_size=state_dim, hidden_size=hidden_dim)
self.fc = nn.Linear(hidden_dim, action_dim)
def forward(self, x, hidden_state=None): # 传入x和hidden_state
h = self.rnn(x, hidden_state)
x = F.leaky_relu(h)
return F.softmax(self.fc(x), dim=-1), h
ActorCritic-Agent
class RNN_ActorCritic:
def __init__(self, state_dim, hidden_dim, action_dim, actor_lr, critic_lr, gamma, device) -> None:
self.actor = RNNPolicy(state_dim, hidden_dim, action_dim)
self.critic = ValueNet(state_dim, hidden_dim)
self.actor_optimizer = torch.optim.Adam(self.actor.parameters(), lr=actor_lr)
self.critic_optimizer = torch.optim.Adam(self.critic.parameters(), lr=critic_lr)
self.gamma = gamma
self.device = device
def take_action(self, state, hidden_state=None):
state = torch.tensor([state], dtype=torch.float).to(self.device)
action_prob, hidden_state = self.actor(state, hidden_state)
action_dist = torch.distributions.Categorical(action_prob)
action = action_dist.sample()
log_prob = action_dist.log_prob(action)
return action.item(), hidden_state, log_prob # 返回action, 隐状态, log_prob
def update(self, transition_dict):
states = torch.tensor(transition_dict['states'],
dtype=torch.float).to(self.device)
rewards = torch.tensor(transition_dict['rewards'],
dtype=torch.float).view(-1, 1).to(self.device)
next_states = torch.tensor(transition_dict['next_states'],
dtype=torch.float).to(self.device)
dones = torch.tensor(transition_dict['dones'],
dtype=torch.float).view(-1, 1).to(self.device)
# 使用torch.stack()将log_probs转换为tensor,可以保留梯度
log_probs = torch.stack(transition_dict['log_probs']).to(self.device)
td_target = rewards + self.gamma * self.critic(next_states) * (1 - dones)
td_delta = td_target - self.critic(states)
actor_loss = torch.mean(-log_probs * td_delta.detach())
critic_loss = torch.mean(
F.mse_loss(self.critic(states), td_target.detach()))
self.actor_optimizer.zero_grad()
self.critic_optimizer.zero_grad()
actor_loss.backward()
critic_loss.backward()
self.actor_optimizer.step()
self.critic_optimizer.step()
训练过程
def train_on_policy_agent(env, agent, num_episodes, render=False):
return_list = []
for i in range(10):
with tqdm(total=int(num_episodes/10), desc='Iteration %d' % i) as pbar:
for i_episode in range(int(num_episodes/10)):
episode_return = 0
transition_dict = {'states': [], 'next_states': [], 'rewards': [], 'dones': [], 'log_probs': []}
state = env.reset()
# 初始化hidden_state
hidden_state = None
done = False
while not done:
action, hidden_state, log_prob = agent.take_action(state, hidden_state)
next_state, reward, done, _ = env.step(action)
if render:
env.render()
transition_dict['states'].append(state)
transition_dict['next_states'].append(next_state)
transition_dict['rewards'].append(reward)
transition_dict['dones'].append(done)
# 无需记录action, 因为记录action是为了计算log_prob,而我们已经算好了log_prob
transition_dict['log_probs'].append(log_prob)
state = next_state
episode_return += reward
return_list.append(episode_return)
agent.update(transition_dict)
if (i_episode+1) % 10 == 0:
pbar.set_postfix({'episode': '%d' % (num_episodes/10 * i + i_episode+1), 'return': '%.3f' % np.mean(return_list[-10:])})
pbar.update(1)
return return_list
训练
actor_lr = 1e-3
critic_lr = 1e-2
num_episodes = 1000
hidden_dim = 128
gamma = 0.98
device = torch.device("cuda") if torch.cuda.is_available() else torch.device(
"cpu")
env_name = 'CartPole-v0'
env = gym.make(env_name)
env.seed(0)
torch.manual_seed(0)
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.n
agent = RNN_ActorCritic(state_dim, hidden_dim, action_dim, actor_lr, critic_lr,
gamma, device)
return_list = train_on_policy_agent(env, agent, num_episodes)
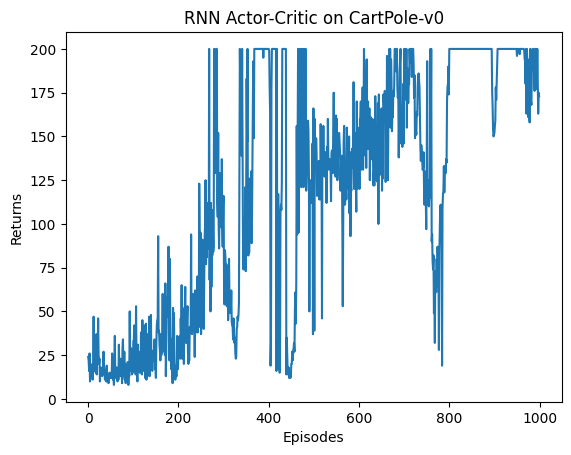
CartPole结果
这是使用RNN策略网络的结果:
这是使用普通MLP的结果 (Hands-On-RL原来的结果):
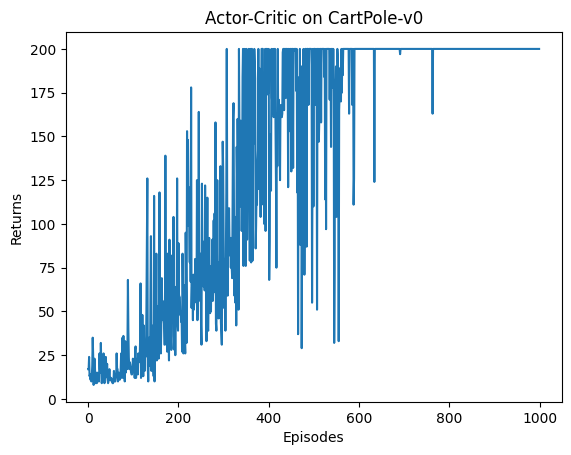
用RNN效果相对差的可能原因:
- 环境太简单。
- RNN要学习的参数更多,收敛速度更慢。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号